JDK5.0中JVM堆模型、GC垃圾收集详细解析
前段时间在一个项目的性能测试中又发生了一次OOM(Out of swap sapce),情形和以前网店版的那次差不多,比上次更奇怪的是,此次搞了几天之后啥都没调整系统就自动好了,死活没法再重现之前的OOM了!问题虽然蹊 跷,但也趁此机会再次对JVM堆模型、GC垃圾算法等进行了一次系统梳理;
基本概念
堆/Heap
JVM管理的内存叫堆;在32Bit操作系统上有4G的限制,一般来说Windows下为2G,而Linux下为3G;64Bit的就没有这个限 制。
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64但小于1G。
JVM最大分配的内存由-Xmx指定,默认是物理内存的 1/4但小于1G。
默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制,可以由-XX:MinHeapFreeRatio=指 定。
默认空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制,可以由-XX:MaxHeapFreeRatio=指定。
服 务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆的大小,所以上面的两个参数没啥用。
分代/堆模型
分代是Java垃圾收集的一大亮点,根据对象的生命周期长短,把堆分为3个代:Young,Old和Permanent,根据不同代的特点采用不同 的收集算法,可以扬长避短。可参考如下的模型图:
Young(Nursery):年轻代
研究表明大部分对象都是朝生暮死,随生随灭的。所以对于年轻代在GC时都采取复制收集算法,具体算法参考下面的描述;
Young的默认值为 4M,随堆内存增大,约为1/15,JVM会根据情况动态管理其大小变化。
Young里面又分为3个区域,一个Eden,所有新建对象都会存在于 该区,两个Survivor区,用来实施复制算法。
-XX:NewRatio= 参数可以设置Young与Old的大小比例,-server时默认为1:2,但实际上young启动时远低于这个比率?如果信不过JVM,也可以用 -Xmn硬性规定其大小,有文档推荐设为Heap总大小的1/4。
-XX:SurvivorRatio= 参数可以设置Eden与Survivor的比例,默认为32。Survivio大了会浪费,小了的话,会使一些年轻对象潜逃到老人区,引起老人区的不安, 但这个参数对性能并不太重要。
Old(Tenured):年老代
年轻代的对象如果能够挺过数次收集,就会进入老人区。老人区使用标记整理算法。因为老人区的对象都没那么容易死的,采用复制算法就要反复的复制对 象,很不合算,只好采用标记清理算法,但标记清理算法其实也不轻松,每次都要遍历区域内所有对象,所以还是没有免费的午餐啊。
-XX:MaxTenuringThreshold= 设置熬过年轻代多少次收集后移入老人区,CMS中默认为0,熬过第一次GC就转入,可以用-XX:+PrintTenuringDistribution 查看。
Permanent:持久代
装载Class信息等基础数据,默认64M,如果是类很多很多的服务程序,需要加大其设置-XX:MaxPermSize=,否则它满了之后会引起 fullgc()或Out of Memory。 注意Spring,Hibernate这类喜欢AOP动态生成类的框架需要更多的持久代内存。一般情况下,持久代是不会进行GC的,除非通过 -XX:+CMSClassUnloadingEnabled -XX:+CMSPermGenSweepingEnabled进行强制设置。
GC的类型
当每个代满了之后都会自动促发collection,各收集器触发的条件不一样,当然也可以通过一些参数进行强制设定。主要分为两种类型:
- Minor Collection:GC用较高的频率对young进行扫描和回收,采用复制算法。
- Major Collection:同时对Young和Old进行内存收集,也叫Full GC;因为成本关系对Old的检查回收频率要比Young低很多,采用标记清除/标记整理算法。可以通过调用代码System.gc()引发major collection,使用-XX:+DisableExplicitGC禁止它,或设为CMS并发 -XX:+ExplicitGCInvokesConcurrent。
更为具体的阐述如下:
由于年轻代进进出出的人多而频繁,所以年轻代的GC也就频繁一点,但涉及范围也就年轻代这点弹丸之地内的对象,其特点 就是少量,多次,但快速,称之为Minor Collection。当年轻代的内存使用达到一定的阀值时,Minor Collection就被触发,Eden及某一Survior space(from space)之内存活的的对象被移到另一个空的Survior space(to space)中,然后from space和to space角色对调。当一个对象在两个survivor space之间移动过一定次数(达到预设的阀值)时,它就足够old了,够资格呆在年老代了。当然,如果survivor space比较小不足以容下所有live objects时,部分live objects也会直接晋升到年老代。
Survior spaces可以看作是Eden和年老代之间的缓冲,通过该缓冲可以检验一个对象生命周期是否足够的长,因为某些对象虽然逃过了一次Minor Collection,并不能说明其生命周期足够长,说不定在下一次Minor Collection之前就挂了。这样一定程度上确保了进入年老代的对象是货真价实的,减少了年老代空间使用的增长速度,也就降低年老代GC的频率。
当 年老代或者永久代的内存使用达到一定阀值时,一次基于所有代的GC就触发了,其特定是涉及范围广(量大),耗费的时间相对较长(较慢),但是频率比较低 (次数少),称之为Major Collection(Full Collection)。通常,首先使用针对年轻代的GC算法进行年轻代的GC,然后使用针对年老代的GC算法对年老代和永久代进行GC。
基本GC收集算法
- 复制 (copying):将堆内分成两个相同空间,从根(ThreadLocal的对象,静态对象)开始访问 每一个关联的活跃对象,将空间A的活跃对象全部复制到空间B,然后一次性回收整个空间A。
因为只访问活跃对象,将所有活动对象复制走之后就清空整 个空间,不用去访问死对象,所以遍历空间的成本较小,但需要巨大的复制成本和较多的内存。可参考如下的示例图: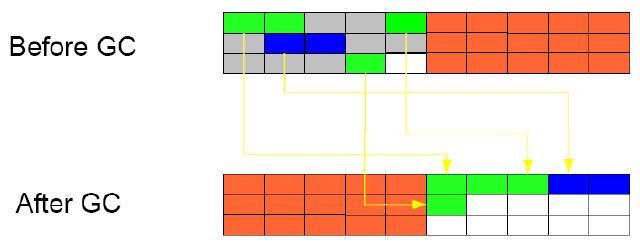
- 标记清除 (mark-sweep):收集器先从根开始访问所有活跃对象,标记为活跃对象。然后再遍历一次整个 内存区域,把所有没有标记活跃的对象进行回收处理。该算法遍历整个空间的成本较大暂停时间随空间大小线性增大,而且整理后堆里的碎片很多。可参考如下的示 例图:
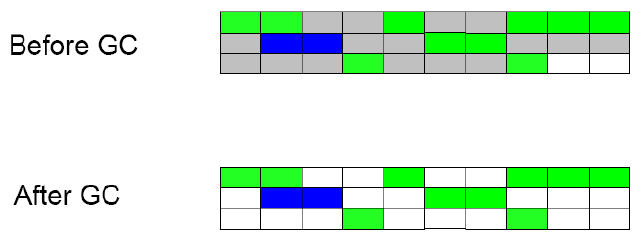
- 标记整理 (mark-sweep-compact):综合了上述两者的做法和优点,先标记活跃对象,然后将其 合并成较大的内存块。可参考如下的示例图:
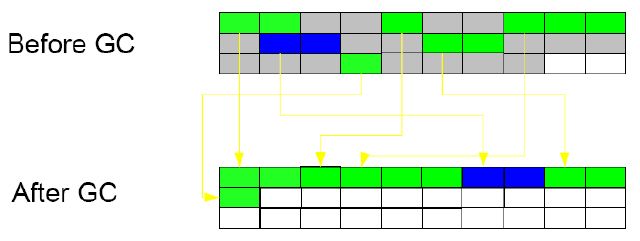
GC收集器类型
- 古老的串行收集器 (Serial Collector)
-XX:+UseSerialGC:策略为年 轻代串行复制,年老代串行标记整理。可参考如下的示例图:
- 吞吐量优先的并行收集器 (Throughput Collector)
-XX:+UseParallelGC: 这是JDK5 -server的默认值。策略为:
年轻代:暂停应用程序,多个垃圾收集线程并行的复制收集,线程数默认为CPU个数,CPU很多 时,可用-XX:ParallelGCThreads= 设定线程数。
年老代:暂停应用程序,与串行收集器一样,单垃圾收集线程标记整理。
如 上可知该收集器需要2+的CPU时才会优于串行收集器,适用于后台处理,科学计算。
可以使用-XX:MaxGCPauseMillis= 和 -XX:GCTimeRatio 来调整GC的时间。可参考如下的示例图:
- 暂停时间优先的并发收集器 (Concurrent Low Pause Collector-CMS)
-XX:+UseConcMarkSweepGC: 这是以上两种策略的升级版,策略为:
年轻代:同样是暂停应用程序,多个垃圾收集线程并行的复制收集。
年老代:则只有两次短暂停,其他时间 应用程序与收集线程并发的清除。
若要采用标记整理算法,则可以通过设置参数实现;可参考如下的示例图:
- 增量并发收集器 (Incremental Concurrent-Mark-Sweep/i-CMS):虽然CMS收集算法在最为耗时的内存区域遍历时采用多线程并发操作,但对于服务器CPU资源 不够的情况下,其实对性能是没有提升的,反而会导致系统吞吐量的下降,为了尽量避免这种情况的出现,就有了增量CMS收集算法,就是在并发标记、清理的时 候让GC线程、用户线程交叉运行,尽量减少GC线程的全程独占式执行;可参考如下的示例图:
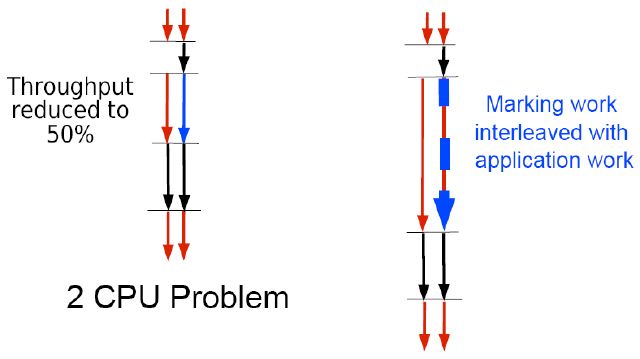
对于以上的GC收集器的详细设置参数,可以参考JVM选项的超完整收集《A Collection of JVM Options 》,这里就不一一详述了。
并行、并发的区别
并行(Parallel)与并发(Concurrent)仅一字之差,但体现的意思却完全不同,这可能也是很多同学非常困惑的地方,要想深刻体会这 其中的差别,可以多揣摩下上面关于GC收集器的示例图;
- 并行:指多条垃圾收集线程并行,此时用户线程是没有运行的;
- 并发:指用户线程与垃圾收集线程并发执行,程序在继续运行,而垃圾收集程序运行于另一个个CPU上。
并发收集一开始会很短暂的停止一次所有线程来开始初始标记根对象,然后标记线程与应用线程一起并发运行,最后又很短的暂停一次,多线程并行的重新标 记之前可能因为并发而漏掉的对象,然后就开始与应用程序并发的清除过程。可见,最长的两个遍历过程都是与应用程序并发执行的,比以前的串行算法改进太多太 多了!!!
串行标记清除是等年老代满了再开始收集的,而并发收集因为要与应用程序一起运行,如果满了才收集,应用程序就无内存可用,所以系统默认 68%满的时候就开始收集。内存已设得较大,吃内存又没有这么快的时候,可以用-XX:CMSInitiatingOccupancyFraction= 恰当增大该比率。
年轻代的痛
由于对年轻代的复制收集,依然必须停止所有应用程序线程,原理如此,只能靠多CPU,多收集线程并发来提高收集速度,但除非你的Server独占整 台服务器,否则如果服务器上本身还有很多其他线程时,切换起来速度就..... 所以,搞到最后,暂停时间的瓶颈就落在了年轻代的复制算法上。
因 此Young的大小设置挺重要的 ,大点就不用频繁GC,而且增大GC的间隔后,可以让多点对象自己死掉而不用复制了。 但Young增大时,GC造成的停顿时间攀升得非常恐怖,据某人的测试结果显示:默认8M的Young,只需要几毫秒的时间,64M就升到90毫秒,而升 到256M时,就要到300毫秒了,峰值还会攀到恐怖的800ms。谁叫复制算法,要等Young满了才开始收集,开始收集就要停止所有线程呢。
参考资料
主要参考:JDK5.0 垃圾收集优化之--Don't Pause
官方指南:Tuning Garbage Collection with the 5.0 Java Virtual Machine
前段时间在一个项目的性能测试中又发生了一次OOM(Out of swap sapce),情形和以前网店版的那次差不多,比上次更奇怪的是,此次搞了几天之后啥都没调整系统就自动好了,死活没法再重现之前的OOM了!问题虽然蹊 跷,但也趁此机会再次对JVM堆模型、GC垃圾算法等进行了一次系统梳理;
基本概念
堆/Heap
JVM管理的内存叫堆;在32Bit操作系统上有4G的限制,一般来说Windows下为2G,而Linux下为3G;64Bit的就没有这个限 制。
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64但小于1G。
JVM最大分配的内存由-Xmx指定,默认是物理内存的 1/4但小于1G。
默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制,可以由-XX:MinHeapFreeRatio=指 定。
默认空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制,可以由-XX:MaxHeapFreeRatio=指定。
服 务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆的大小,所以上面的两个参数没啥用。
分代/堆模型
分代是Java垃圾收集的一大亮点,根据对象的生命周期长短,把堆分为3个代:Young,Old和Permanent,根据不同代的特点采用不同 的收集算法,可以扬长避短。可参考如下的模型图:
Young(Nursery):年轻代
研究表明大部分对象都是朝生暮死,随生随灭的。所以对于年轻代在GC时都采取复制收集算法,具体算法参考下面的描述;
Young的默认值为 4M,随堆内存增大,约为1/15,JVM会根据情况动态管理其大小变化。
Young里面又分为3个区域,一个Eden,所有新建对象都会存在于 该区,两个Survivor区,用来实施复制算法。
-XX:NewRatio= 参数可以设置Young与Old的大小比例,-server时默认为1:2,但实际上young启动时远低于这个比率?如果信不过JVM,也可以用 -Xmn硬性规定其大小,有文档推荐设为Heap总大小的1/4。
-XX:SurvivorRatio= 参数可以设置Eden与Survivor的比例,默认为32。Survivio大了会浪费,小了的话,会使一些年轻对象潜逃到老人区,引起老人区的不安, 但这个参数对性能并不太重要。
Old(Tenured):年老代
年轻代的对象如果能够挺过数次收集,就会进入老人区。老人区使用标记整理算法。因为老人区的对象都没那么容易死的,采用复制算法就要反复的复制对 象,很不合算,只好采用标记清理算法,但标记清理算法其实也不轻松,每次都要遍历区域内所有对象,所以还是没有免费的午餐啊。
-XX:MaxTenuringThreshold= 设置熬过年轻代多少次收集后移入老人区,CMS中默认为0,熬过第一次GC就转入,可以用-XX:+PrintTenuringDistribution 查看。
Permanent:持久代
装载Class信息等基础数据,默认64M,如果是类很多很多的服务程序,需要加大其设置-XX:MaxPermSize=,否则它满了之后会引起 fullgc()或Out of Memory。 注意Spring,Hibernate这类喜欢AOP动态生成类的框架需要更多的持久代内存。一般情况下,持久代是不会进行GC的,除非通过 -XX:+CMSClassUnloadingEnabled -XX:+CMSPermGenSweepingEnabled进行强制设置。
GC的类型
当每个代满了之后都会自动促发collection,各收集器触发的条件不一样,当然也可以通过一些参数进行强制设定。主要分为两种类型:
- Minor Collection:GC用较高的频率对young进行扫描和回收,采用复制算法。
- Major Collection:同时对Young和Old进行内存收集,也叫Full GC;因为成本关系对Old的检查回收频率要比Young低很多,采用标记清除/标记整理算法。可以通过调用代码System.gc()引发major collection,使用-XX:+DisableExplicitGC禁止它,或设为CMS并发 -XX:+ExplicitGCInvokesConcurrent。
更为具体的阐述如下:
由于年轻代进进出出的人多而频繁,所以年轻代的GC也就频繁一点,但涉及范围也就年轻代这点弹丸之地内的对象,其特点 就是少量,多次,但快速,称之为Minor Collection。当年轻代的内存使用达到一定的阀值时,Minor Collection就被触发,Eden及某一Survior space(from space)之内存活的的对象被移到另一个空的Survior space(to space)中,然后from space和to space角色对调。当一个对象在两个survivor space之间移动过一定次数(达到预设的阀值)时,它就足够old了,够资格呆在年老代了。当然,如果survivor space比较小不足以容下所有live objects时,部分live objects也会直接晋升到年老代。
Survior spaces可以看作是Eden和年老代之间的缓冲,通过该缓冲可以检验一个对象生命周期是否足够的长,因为某些对象虽然逃过了一次Minor Collection,并不能说明其生命周期足够长,说不定在下一次Minor Collection之前就挂了。这样一定程度上确保了进入年老代的对象是货真价实的,减少了年老代空间使用的增长速度,也就降低年老代GC的频率。
当 年老代或者永久代的内存使用达到一定阀值时,一次基于所有代的GC就触发了,其特定是涉及范围广(量大),耗费的时间相对较长(较慢),但是频率比较低 (次数少),称之为Major Collection(Full Collection)。通常,首先使用针对年轻代的GC算法进行年轻代的GC,然后使用针对年老代的GC算法对年老代和永久代进行GC。
基本GC收集算法
- 复制 (copying):将堆内分成两个相同空间,从根(ThreadLocal的对象,静态对象)开始访问 每一个关联的活跃对象,将空间A的活跃对象全部复制到空间B,然后一次性回收整个空间A。
因为只访问活跃对象,将所有活动对象复制走之后就清空整 个空间,不用去访问死对象,所以遍历空间的成本较小,但需要巨大的复制成本和较多的内存。可参考如下的示例图: - 标记清除 (mark-sweep):收集器先从根开始访问所有活跃对象,标记为活跃对象。然后再遍历一次整个 内存区域,把所有没有标记活跃的对象进行回收处理。该算法遍历整个空间的成本较大暂停时间随空间大小线性增大,而且整理后堆里的碎片很多。可参考如下的示 例图:
- 标记整理 (mark-sweep-compact):综合了上述两者的做法和优点,先标记活跃对象,然后将其 合并成较大的内存块。可参考如下的示例图:
GC收集器类型
- 古老的串行收集器 (Serial Collector)
-XX:+UseSerialGC:策略为年 轻代串行复制,年老代串行标记整理。可参考如下的示例图: - 吞吐量优先的并行收集器 (Throughput Collector)
-XX:+UseParallelGC: 这是JDK5 -server的默认值。策略为:
年轻代:暂停应用程序,多个垃圾收集线程并行的复制收集,线程数默认为CPU个数,CPU很多 时,可用-XX:ParallelGCThreads= 设定线程数。
年老代:暂停应用程序,与串行收集器一样,单垃圾收集线程标记整理。
如 上可知该收集器需要2+的CPU时才会优于串行收集器,适用于后台处理,科学计算。
可以使用-XX:MaxGCPauseMillis= 和 -XX:GCTimeRatio 来调整GC的时间。可参考如下的示例图: - 暂停时间优先的并发收集器 (Concurrent Low Pause Collector-CMS)
-XX:+UseConcMarkSweepGC: 这是以上两种策略的升级版,策略为:
年轻代:同样是暂停应用程序,多个垃圾收集线程并行的复制收集。
年老代:则只有两次短暂停,其他时间 应用程序与收集线程并发的清除。
若要采用标记整理算法,则可以通过设置参数实现;可参考如下的示例图: - 增量并发收集器 (Incremental Concurrent-Mark-Sweep/i-CMS):虽然CMS收集算法在最为耗时的内存区域遍历时采用多线程并发操作,但对于服务器CPU资源 不够的情况下,其实对性能是没有提升的,反而会导致系统吞吐量的下降,为了尽量避免这种情况的出现,就有了增量CMS收集算法,就是在并发标记、清理的时 候让GC线程、用户线程交叉运行,尽量减少GC线程的全程独占式执行;可参考如下的示例图:
对于以上的GC收集器的详细设置参数,可以参考JVM选项的超完整收集《A Collection of JVM Options 》,这里就不一一详述了。
并行、并发的区别
并行(Parallel)与并发(Concurrent)仅一字之差,但体现的意思却完全不同,这可能也是很多同学非常困惑的地方,要想深刻体会这 其中的差别,可以多揣摩下上面关于GC收集器的示例图;
- 并行:指多条垃圾收集线程并行,此时用户线程是没有运行的;
- 并发:指用户线程与垃圾收集线程并发执行,程序在继续运行,而垃圾收集程序运行于另一个个CPU上。
并发收集一开始会很短暂的停止一次所有线程来开始初始标记根对象,然后标记线程与应用线程一起并发运行,最后又很短的暂停一次,多线程并行的重新标 记之前可能因为并发而漏掉的对象,然后就开始与应用程序并发的清除过程。可见,最长的两个遍历过程都是与应用程序并发执行的,比以前的串行算法改进太多太 多了!!!
串行标记清除是等年老代满了再开始收集的,而并发收集因为要与应用程序一起运行,如果满了才收集,应用程序就无内存可用,所以系统默认 68%满的时候就开始收集。内存已设得较大,吃内存又没有这么快的时候,可以用-XX:CMSInitiatingOccupancyFraction= 恰当增大该比率。
年轻代的痛
由于对年轻代的复制收集,依然必须停止所有应用程序线程,原理如此,只能靠多CPU,多收集线程并发来提高收集速度,但除非你的Server独占整 台服务器,否则如果服务器上本身还有很多其他线程时,切换起来速度就..... 所以,搞到最后,暂停时间的瓶颈就落在了年轻代的复制算法上。
因 此Young的大小设置挺重要的 ,大点就不用频繁GC,而且增大GC的间隔后,可以让多点对象自己死掉而不用复制了。 但Young增大时,GC造成的停顿时间攀升得非常恐怖,据某人的测试结果显示:默认8M的Young,只需要几毫秒的时间,64M就升到90毫秒,而升 到256M时,就要到300毫秒了,峰值还会攀到恐怖的800ms。谁叫复制算法,要等Young满了才开始收集,开始收集就要停止所有线程呢。
参考资料
主要参考:JDK5.0 垃圾收集优化之--Don't Pause
官方指南:Tuning Garbage Collection with the 5.0 Java Virtual Machine