K-means Algorithm
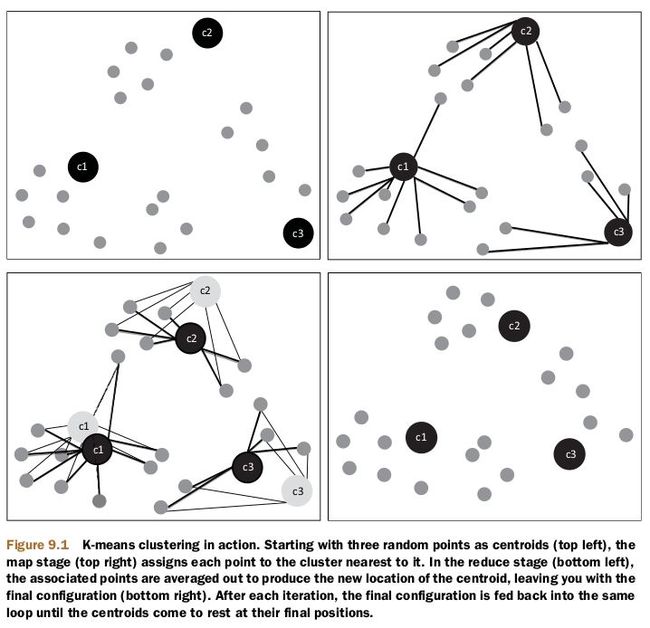
The k-means algorithm will start with an initial set of k centroid points. The algorithm does multiple rounds of processing and refines the centroid locations until the iteration max-limit criterion is reached or until the centroids converge to a fixed point from which they don’t move very much.
K-generation
-
centroids are randomly generated using RandomSeedGenerator
For good quality clustering using k-means, you’ll need to estimate a value for k. An approximate way of estimating k is to figure it out based on the data you have and the size of clusters you need. In the preceding example, where we have about a million news articles, if there are an average of 500 news articles published about every unique story, you should start your clustering with a k value of about 2,000 (1,000,000/500).
-
Finding the perfect k using canopy clustering
Canopy clustering’s strength lies in its ability to create clusters extremely quickly—it can do this with a single pass over the data. But its strength is also its weakness. This algorithm may not give accurate and precise clusters. But it can give the optimal number of clusters without even specifying the number of clusters, k, as required by k-means.
The algorithm uses a fast distance measure and two distance thresholds, T1 and T2, with T1 > T2. It begins with a data set of points and an empty list of canopies, and then iterates over the data set, creating canopies in the process. During each iteration, it removes a point from the data set and adds a canopy to the list with that point as the center. It loops through the rest of the points one by one. For each one, it calculates the distances to all the canopy centers in the list. If the distance between the point and any canopy center is within T1, it’s added into that canopy. If the distance is within T2, it’s removed from the list and thereby prevented from forming a new canopy in the subsequent loops. It repeats this process until the list is empty.
This approach prevents all points close to an already existing canopy (distance < T2) from being the center of a new canopy. It’s detrimental to form another redundant canopy in close proximity to an existing one.

mahout canopy -i reuters-vectors/tfidf-vectors \ -o reuters-canopy-centroids \ -dm org.apache.mahout.common.distance.EuclideanDistanceMeasure \ -t1 1500 -t2 2000
mahout kmeans -i mahout/reuters-vectors/tfidf-vectors -o mahout/reuters-kmeans-clusters -dm org.apache.mahout.common.distance.TanimotoDistanceMeasure -c mahout/reuters-canopy-centroids/clusters-0-final -cd 0.1 -ow -x 20 -cl
mahout clusterdump -i mahout/reuters-kmeans-clusters/clusters-1-final -o mahout/reuters-kmeans-clusters-dump -dt sequencefile -d mahout/reuters-vectors/dictionary.file-* -p mahout/reuter-kmeans-clusters/clusteredPoints -b 10 -n 10
mahout clusterdump usage
Note: you must add -cl in kmean command otherwise there has no clusteredPoints dir. See
http://lucene.472066.n3.nabble.com/where-are-the-points-in-each-cluster-kmeans-clusterdump-tc838683.html#none