In order to use custom chinese tokenizer(eg. jcseg). Following the next steps
1. download carrot2 souce code and import it to eclipse
#git clone git://github.com/carrot2/carrot2.git
#cd carrot2
#ant -p
#ant eclipse
2. import jecseg to eclipse and reference it to carrot2-util-text subproject.
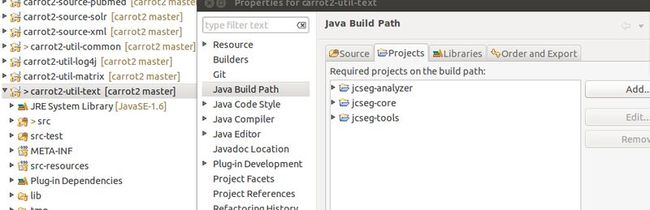
3. modify org.carrot2.text.linguistic.DefaultTokenizerFactory.java
private static EnumMap<LanguageCode, IFactory<ITokenizer>> createDefaultTokenizers() {
EnumMap<LanguageCode, IFactory<ITokenizer>> map = Maps
.newEnumMap(LanguageCode.class);
// By default, we use our own tokenizer for all languages.
IFactory<ITokenizer> whitespaceTokenizerFactory = new NewClassInstanceFactory<ITokenizer>(
ExtendedWhitespaceTokenizer.class);
IFactory<ITokenizer> chineseTokenizerFactory = new NewClassInstanceFactory<ITokenizer>(
InokChineseTokenizerAdapter.class);
for (LanguageCode lc : LanguageCode.values()) {
map.put(lc, whitespaceTokenizerFactory);
}
// Chinese and Thai are exceptions, we use adapters around tokenizers
// from Lucene.
map.put(LanguageCode.CHINESE_SIMPLIFIED, chineseTokenizerFactory);
.....
}
4. create new class org.carrot2.text.linguistic.lucene.InokChineseTokenizerAdapter.java
package org.carrot2.text.linguistic.lucene;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
import java.util.regex.Pattern;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.carrot2.text.analysis.ITokenizer;
import org.carrot2.text.util.MutableCharArray;
import org.lionsoul.jcseg.analyzer.JcsegFilter;
import org.lionsoul.jcseg.analyzer.JcsegTokenizer;
import org.lionsoul.jcseg.core.ADictionary;
import org.lionsoul.jcseg.core.DictionaryFactory;
import org.lionsoul.jcseg.core.ISegment;
import org.lionsoul.jcseg.core.IWord;
import org.lionsoul.jcseg.core.JcsegException;
import org.lionsoul.jcseg.core.JcsegTaskConfig;
import org.lionsoul.jcseg.core.SegmentFactory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class InokChineseTokenizerAdapter extends Tokenizer implements
ITokenizer {
private final static Logger logger = LoggerFactory
.getLogger(InokChineseTokenizerAdapter.class);
private ISegment segmentor;
private OffsetAttribute offsetAtt;
private CharTermAttribute termAtt = null;
private final MutableCharArray tempCharSequence;
public InokChineseTokenizerAdapter() throws JcsegException, IOException {
super(new StringReader(""));
JcsegTaskConfig config = new JcsegTaskConfig();
ADictionary dic = DictionaryFactory.createDefaultDictionary(config);
this.tempCharSequence = new MutableCharArray(new char[0]);
segmentor = SegmentFactory.createJcseg(1, new Object[] { config, dic });
segmentor.reset(input);
termAtt = addAttribute(CharTermAttribute.class);
offsetAtt = addAttribute(OffsetAttribute.class);
}
@Override
public void reset(Reader reader) throws IOException {
super.reset();
segmentor.reset(reader);
}
@Override
public short nextToken() throws IOException {
final boolean hasNextToken = incrementToken();
if (hasNextToken) {
short flags = 0;
final char[] image = termAtt.buffer();
final int length = termAtt.length();
tempCharSequence.reset(image, 0, length);
if (length == 1) {
flags = ITokenizer.TT_PUNCTUATION;
} else {
flags = ITokenizer.TT_TERM;
}
return flags;
}
return ITokenizer.TT_EOF;
}
@Override
public void setTermBuffer(MutableCharArray array) {
// TODO Auto-generated method stub
array.reset(termAtt.buffer(), 0, termAtt.length());
}
@Override
public boolean incrementToken() throws IOException {
clearAttributes();
IWord word = segmentor.next();
if (word != null) {
termAtt.append(word.getValue());
termAtt.setLength(word.getLength());
offsetAtt.setOffset(word.getPosition(),
word.getPosition() + word.getLength());
return true;
} else {
end();
return false;
}
}
}
5. recompile and build jars in carrot2
#cd carrot2
a. modify build.xml to add jcseg jars
<patternset id="lib.test">
<include name="core/**/*.jar" />
<include name="lib/**/*.jar" />
<include name="lib/jcseg-*.jar" />
<exclude name="lib/org.slf4j/slf4j-nop*" />
<include name="applications/carrot2-dcs/**/*.jar" />
<include name="applications/carrot2-webapp/lib/*.jar" />
<include name="applications/carrot2-benchmarks/lib/*.jar" />
</patternset>
<patternset id="lib.core">
<include name="lib/**/*.jar" />
<include name="core/carrot2-util-matrix/lib/*.jar" />
<include name="lib/jcseg-*.jar" />
<patternset refid="lib.core.excludes" />
</patternset>
<patternset id="lib.core.mini">
<include name="lib/**/mahout-*.jar" />
<include name="lib/jcseg-*.jar" />
<include name="lib/**/mahout.LICENSE" />
<include name="lib/**/colt.LICENSE" />
<include name="lib/**/commons-lang*" />
<include name="lib/**/guava*" />
<include name="lib/**/jackson*" />
<include name="lib/**/lucene-snowball*" />
<include name="lib/**/lucene.LICENSE" />
<include name="lib/**/hppc-*.jar" />
<include name="lib/**/hppc*.LICENSE" />
<include name="lib/**/slf4j-api*.jar" />
<include name="lib/**/slf4j-nop*.jar" />
<include name="lib/**/slf4j.LICENSE" />
<include name="lib/**/attributes-binder-*.jar" />
</patternset>
Note: lib/jcseg-*.jar
b. cp jcseg-analyzer-1.9.5.jar and jcseg-core-1.9.5.jar to carrot2/lib/
c.run recompile and build jar
#ant jar
d. cp tmp/jar/carrot2-core-3.10.0-SNAPSHOT.jar to solr/WEB-INF/lib/ '
Note: you should copy jars in contrib/clustering/lib/ , jcesg jars, lexcion dir and jcseg.properties file to solr/WEB-INF/lib/.
Warning: the most important configure in solrconfig.xml is to define tokenizerFactory attribute
<str name="PreprocessingPipeline.tokenizerFactory">org.carrot2.text.linguistic.DefaultTokenizerFactory</str>
<searchComponent name="clustering"
enable="true"
class="solr.clustering.ClusteringComponent" >
<lst name="engine">
<str name="name">lingo</str>
<str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str>
<str name="carrot.resourcesDir">clustering/carrot2</str>
<str name="MultilingualClustering.defaultLanguage">CHINESE_SIMPLIFIED</str>
<str name="PreprocessingPipeline.tokenizerFactory">org.carrot2.text.linguistic.DefaultTokenizerFactory</str>
</lst>
</searchComponent>