hadoop经典系列(五)1.x的mapreduce过程图解
官方shuffle的架构图
从全局宏观上,解释了数据的走向和原理

细化架构图
从jobtracker和tasker解释了map/reduce的细节
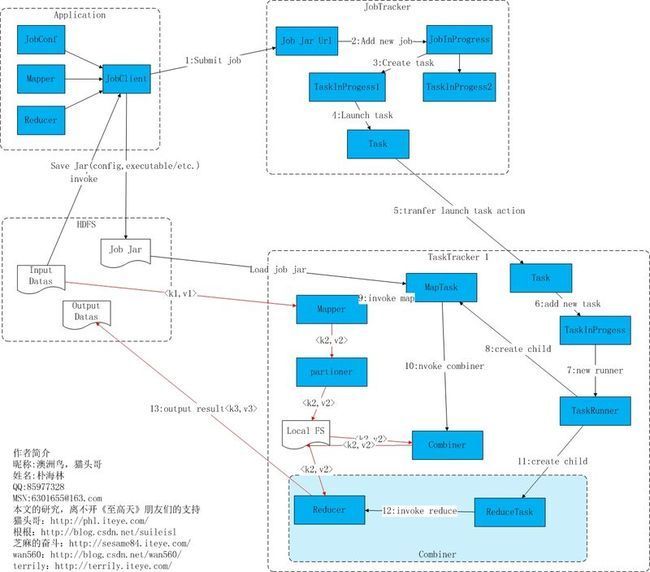
从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路:
1 首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
2 TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
3 TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
1 JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
2 JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
3 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
4 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
5 源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
6 从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
作者简介
昵称:澳洲鸟,猫头哥
姓名:朴海林
QQ:85977328
MSN:[email protected]
本文的研究,离不开《至高天》朋友们的支持
猫头哥:http://phl.iteye.com/
根根:http://blog.csdn.net/suileisl
芝麻的奋斗:http://sesame84.iteye.com/
wan560:http://blog.csdn.net/wan560/
terrily:http://terrily.iteye.com/
从全局宏观上,解释了数据的走向和原理
细化架构图
从jobtracker和tasker解释了map/reduce的细节
从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路:
1 首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
2 TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
3 TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
1 JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
2 JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
3 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
4 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
5 源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
6 从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
作者简介
昵称:澳洲鸟,猫头哥
姓名:朴海林
QQ:85977328
MSN:[email protected]
本文的研究,离不开《至高天》朋友们的支持
猫头哥:http://phl.iteye.com/
根根:http://blog.csdn.net/suileisl
芝麻的奋斗:http://sesame84.iteye.com/
wan560:http://blog.csdn.net/wan560/
terrily:http://terrily.iteye.com/