Introduction
This is part 3 of a 4 part blog explaining how the BPM engine functions under the covers when “faults” occur, be they unhandled technical faults or failures at the engine level.
Part 1 can be foundhere.
Part 3: Understanding BPM Messages Rollback
Now that we’ve seen how the important SOAINFRA tables are used by the engine we can look at how unhandled exceptions are rolled back by the engine to the last dehydration point. Remember, using appropriate fault policies and catch activities with BPM should avoid the vast majority of rollbacks but as mentioned previously, these can still occur.
Pattern 1 – Async – Async
We can assume here that no fault policy framework exists and that no process level fault handling exists either. Given that this scenario is completely asynchronous we are not going to be able to generate any timeouts, we’ll have to simulate a failure at the engine level by introducing a failing script activity (map string to number) into the process….
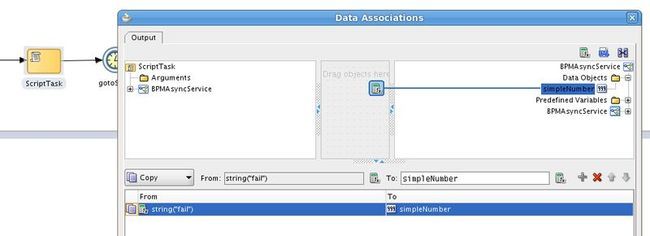
…now running the test we have a failure….

Remember we haven’t caught this anywhere, how can we recover this instance ? Let’s take a look at the relevant tables….
DLV_MESSAGE
…i.e. an INVOKE message for the “start” activities in the client process of “STATE_HANDLED” and an INVOKE message for the “start” activity of the called process in state “STATE_UNRESOLVED”
WORK_ITEM
…i.e. a WORK_ITEM for the “Receive” activity in the client process of state “open_pending_complete
DLV_SUBSCRIPTION
![]()
…i.e. a subscription of state UNRESOLVED for the called service.
So we can infer from the DLV_MESSAGE table that the instance has been rolled back to the last dehydration point, i.e. the “start” activity in the called service so we should be able to “recover” from here….
Pattern 2 – Async – Sync
For this scenario we will force an EJB timeout by setting the value of the DBAdapter timeout to 400 seconds (greater than the EJB timeout of 300 seconds)….

…and we’ll set the stored procedure to run for 500 seconds.
When we run the test we see the following in the flow trace….
… here we see that there has been a “TransactionRolledBackLocalException”, that the BPM process “TestDBTimeout” faulted after around 300 seconds (EJB timeout) and the DBAdapter itself timed out over a minute later.
So where does this leave the underlying tables ?
DLV_MESSAGE
![]()
…i.e. an INVOKE message for the “start” activity in the client process of “STATE_UNRESOLVED”.
We can infer from the DLV_MESSAGE table that the instance has been rolled back to the last dehydration point, i.e. the “start” activity in the client process so we should be able to “recover” from here….

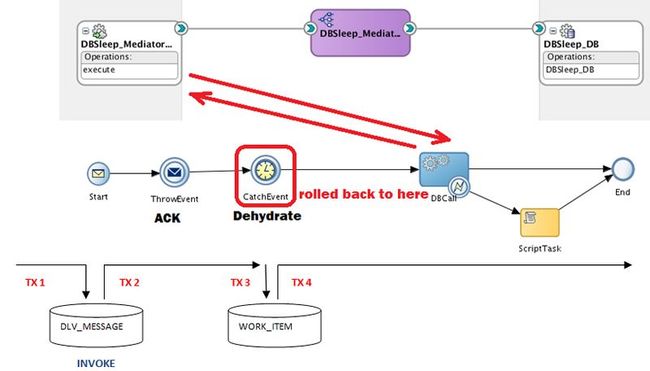
Pattern 3 – Async with Acknowledgement – Sync
Again we will force an EJB timeout by setting the value of the DBAdapter timeout to 400 seconds (greater than the EJB timeout of 300 seconds)….

…the results are pretty similar to the previous pattern except this time the calling process remains in a “Running” state.
So where does this leave the underlying tables ?
DLV_MESSAGE
![]()
…i.e. an INVOKE message for the “start” activity in the client process of “STATE_HANDLED”.
WORK_ITEM
![]()
…i.e. a WORK_ITEM for the “CatchEvent” timer activity in the client process of state “open_pending_complete
We can infer from the above tables that the instance has been rolled back to the timer activity in the client process…
Summary
In the third part in the series we have looked at what happens when a process instances rolls back & what we see in the appropriate SOAINFRA tables. In thenext partwe will look at how we can recover these rolled back process instances.
All site content is the property of Oracle Corp. Redistribution not allowed without written permission