数据结构复习之【图】
一、基本术语
图:由有穷、非空点集和边集合组成,简写成G(V,E);
Vertex:图中的顶点;
无向图:图中每条边都没有方向;
有向图:图中每条边都有方向;
无向边:边是没有方向的,写为(a,b)
有向边:边是有方向的,写为<a,b>
有向边也成为弧;开始顶点称为弧尾,结束顶点称为弧头;
简单图:不存在指向自己的边、不存在两条重复的边的图;
无向完全图:每个顶点之间都有一条边的无向图;
有向完全图:每个顶点之间都有两条互为相反的边的无向图;
稀疏图:边相对于顶点来说很少的图;
稠密图:边很多的图;
权重:图中的边可能会带有一个权重,为了区分边的长短;
网:带有权重的图;
度:与特定顶点相连接的边数;
出度、入度:对于有向图的概念,出度表示此顶点为起点的边的数目,入度表示此顶点为终点的边的数目;
环:第一个顶点和最后一个顶点相同的路径;
简单环:除去第一个顶点和最后一个顶点后没有重复顶点的环;
连通图:任意两个顶点都相互连通的图;
极大连通子图:包含竟可能多的顶点(必须是连通的),即找不到另外一个顶点,使得此顶点能够连接到此极大连通子图的任意一个顶点;
连通分量:极大连通子图的数量;
强连通图:此为有向图的概念,表示任意两个顶点a,b,使得a能够连接到b,b也能连接到a 的图;
生成树:n个顶点,n-1条边,并且保证n个顶点相互连通(不存在环);
最小生成树:此生成树的边的权重之和是所有生成树中最小的;
AOV网:结点表示活动的网;
AOE网:边表示活动的持续时间的网;
二、图的存储结构
1.邻接矩阵
维持一个二维数组,arr[i][j]表示i到j的边,如果两顶点之间存在边,则为1,否则为0;
维持一个一维数组,存储顶点信息,比如顶点的名字;
下图为一般的有向图:

注意:如果我们要看vi节点邻接的点,则只需要遍历arr[i]即可;
下图为带有权重的图的邻接矩阵表示法:
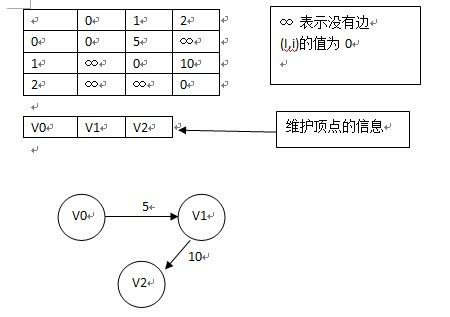
缺点:邻接矩阵表示法对于稀疏图来说不合理,因为太浪费空间;
2.邻接表
如果图示一般的图,则如下图:

如果是网,即边带有权值,则如下图:
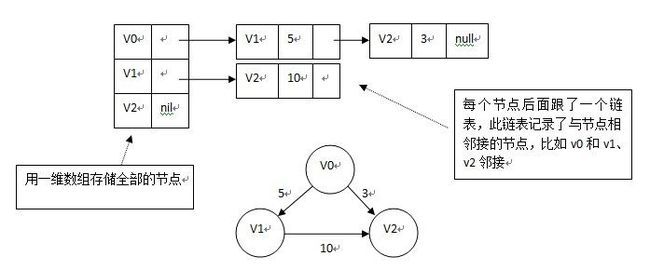
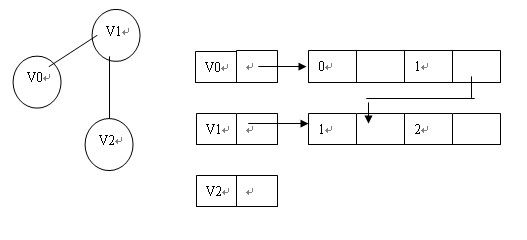
3.十字链表
只针对有向图;,适用于计算出度和入度;
顶点结点:
边结点:

好处:创建的时间复杂度和邻接链表相同,但是能够同时计算入度和出度;
4.邻接多重表
针对无向图; 如果我们只是单纯对节点进行操作,则邻接表是一个很好的选择,但是如果我们要在邻接表中删除一条边,则需要删除四个顶点(因为无向图);
在邻接多重表中,只需要删除一个节点,即可完成边的删除,因此比较方便;
因此邻接多重表适用于对边进行删除的操作;
顶点节点和邻接表没区别,边表节点如下图:
比如:
5.边集数组
适合依次对边进行操作;
存储边的信息,如下图:
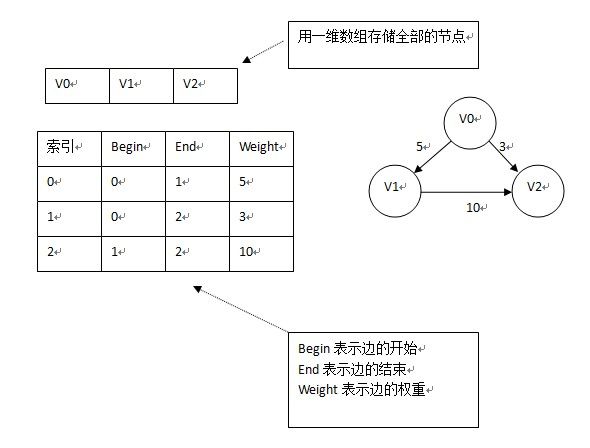
三、图的遍历
DFS
思想:往深里遍历,如果不能深入,则回朔;
比如:
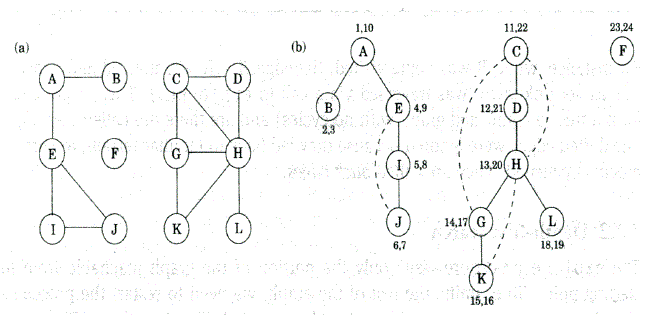
BFS
思想:对所有邻接节点遍历;
四、最小生成树
prim
krustral
五、最短路径
dijkstra算法
Floyd
六、拓扑排序
使用数据结构:
(1)栈:用来存放入度为0的节点;
(2)变种邻接列表:作为图的存储结构;此邻接列表的顶点节点还需要存放入度属性;