基于关系数据库的数据仓库星形模式下维使用原则的研究与探索
<wbr><wbr><wbr><wbr><wbr> 本文发表于中文核心刊物《计算机工程与设计》2005年1期。</wbr></wbr></wbr></wbr></wbr>
<wbr></wbr>
<wbr></wbr>
基于关系数据库的数据仓库星形模式下维使用原则的研究与探索
马根峰<wbr><wbr></wbr></wbr>
(广东电信公用电话管理中心<wbr> 广州 510635)</wbr>
摘要<wbr><wbr><wbr> 星形模式是基于关系数据库的数据仓库中的一个著名概念,由于星形连接模式的设计思想能够满足人们从不同观察角度(维)分析数据的需求,所以在基于关系数据库的数据仓库的设计中广泛地使用了星形模式。在使用数据仓库来回答综合性问题的场合,通常可以使用OLAP工具实现记录不多的较高粒度表的维度旋转来满足不同分析的需要;而在数据仓库中较高粒度表中记录非常多或者还要经常回答细节问题的场合,则还必须对数据仓库中记录非常多的较高粒度的表或者细节级表进行维度转换。但通常的OLAP工具难以处理几十万条记录数据表的维度旋转,针对这种应用场合,笔者提出了一种”有选择地使用维的星形模式”,在事实表中避开使用要旋转的维,用存贮过程编写程序高效地实现OLAP工具相应的功能,对星形模式下维的使用原则做出了一定的探索。</wbr></wbr></wbr>
关键词<wbr><wbr><wbr> 数据仓库;星形模式;维度 ;OLAP</wbr></wbr></wbr>
<wbr></wbr>
<wbr></wbr>
the research of the restricted use of Dimensionality in Star Schema in Data Warehousing based on RDS
MA Gen-feng<wbr><wbr><wbr><wbr><wbr></wbr></wbr></wbr></wbr></wbr>
<wbr><wbr><wbr><wbr><wbr><wbr><wbr><wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr></wbr> (Public Payphone Center, Guangdong Telecom Corporation, Guangzhou 510635)
ABSTRACT:<wbr></wbr> Star Schema is a famous conception in Data Warehousing based on RDS. It’s widely used in Data Warehousing based on RDS for its convenience for people to analyze data from different angle. In the situation for people using Data Warehousing to answer the all-around question, OLAP tools is usually used to circumrotate the Dimensionality of high granularity tables with a few records for the requirement of analyse. If there is a great deal records in high granularity tables or In the situation for people using Data Warehousing to answer the detail question, it’s necessary to circumrotate the Dimensionality of those high granularity tables or the detail tables in Data Warehousing. While it’s very difficult for OLAP tools to circumrotate the dimensionality of tables with more than ten thousands records, I issue a new Star Schema with restricted using of dimensionality. In this Star Schema the fact tables without the dimensionality to be circumrotated is designed, then I develop a program using stored procedure to implement the corresponding function of OLAP tools in high efficiency. In this process definite research is done about the rule of using dimensionality in Star Schema in RDS.
KEY WORDS: Data Warehousing; Star Schema; Dimensionality; OLAP
<wbr></wbr>
<wbr></wbr>
<wbr></wbr>
1 引言
<wbr></wbr>
星形模式是基于关系数据库的数据仓库中的一个著名概念,由于星形连接模式的设计思想能够满足人们从不同观察角度(维)分析数据的需求,加上数据仓库通常用来回答综合性的问题,并且通常的OLAP工具可以很轻松地实现记录不多的较高粒度表的维度旋转来满足不同分析的需要,所以在基于关系数据库的数据仓库的设计中广泛地使用了星形模式,如电信运营商中普遍进行的话务总体分析。在这种总体分析中,主要分析某一计费月各地区的总体话费及其在不同计费月期间的变化。
<wbr></wbr>
而在数据仓库中较高粒度表中记录非常多或者还要经常回答细节问题的场合,则还必须对数据仓库中记录非常多的较高粒度的表或者细节级表进行维度转换。如在目前电信市场尤其是公话市场竞争激烈的今天,广东电信公用电话管理中心的经营分析人员迫切进行的公话终端(首先是一百多万部200专用话机)话费的动态分析。在这种话费的动态分析中,不仅要分析分析各地区、各市县、各支局、各用户类型以及它们不同组合情况下的200专用话机在某一计费月的总体话费及其在不同计费月的变化,而且还要从细节上分析带来这些变化的一百万多万部200专用话机在某一计费月的话费在不同计费月期间的变化。因为只有这样才能了解200专用话机总体话费及其变化的原因或找出其中的规律,为管理者决策提供依据。但通常的OLAP工具难以处理几十万条记录数据表的维度旋转,更不用说是对每个月都有一百多万条话费记录的200专用话机话费细节表在时间维度上的旋转了。笔者在”基于数据仓库和维度转换的广东电信公用电话200专用话机话务的动态分析系统”的研究与开发过程中,在数据仓库星形模式设计时有选择地使用维,在星形模式中各粒度200专用话机话费表中避开使用时间维,然后用存贮过程编写维度转换程序代替OLAP工具来旋转操作型环境下话费表中的时间维,在PC机上每一次只需要一个小时就完成了一个月一百多万条记录的操作型环境下话费表的维度转换并生成了数据仓库中各粒度表的数据,轻松地实现了一百多万部200专用话机话费的动态分析,对数据仓库星形模式下维的使用原则做出了一定的探索。
<wbr></wbr>
<wbr></wbr>
<wbr></wbr>
2<wbr> 只回答综合性问题场合下的星形模式及OLAP处理</wbr>
<wbr></wbr>
<wbr><strong><wbr>2.1 星形模式设计</wbr></strong></wbr>
在只回答综合性问题的场合,也是绝大多数应用数据仓库的场合,由于OLAP只涉及数据仓库中记录不多的较高粒度的表,所以在这种场合,数据仓库中各粒度表都使用尽可能多维的星形模式。如下面电信运营商为了进行总体话费分析所采取的星形模式,在这种星形模式下,事实表中包含着用于分析的指标(话费)和联接众多维表的主键。
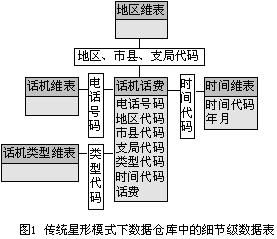
 <wbr></wbr>
<wbr></wbr>
......
<wbr></wbr>
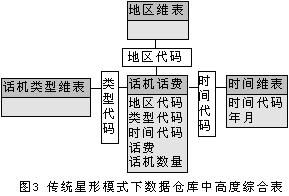
<wbr><wbr><wbr></wbr></wbr></wbr>
<wbr></wbr>
2.2<wbr> 使用OLAP工具进行话费总体分析</wbr>
对于图2中的高度综合表,由于广东电信下属22个分公司,公用电话话机有20种类型,所以10年内表中的记录数为52800条记录,所以完全可以用OLAP工具对高度综合表进行维度转换,将时间维从事实表中去掉来完成几个月来各地区、各话机类型或者各地区的各种类型话机话费的总体变化,完成总体话费的分析。
<wbr></wbr>
<wbr></wbr>
<wbr></wbr>
3 有选择地使用维的星形模式及话费动态分析的实现
<wbr></wbr>
在图1至图3中,如果要进行各地区、各市县、各支局不同类型话机话费的动态分析,则还必须对图2中的轻度综合级表进行维度转换,而广东电信现有1400多个支局,那么一年内轻度综合级表中的记录就达到30多万条,在这种情况下用OLAP工具来分析几年间话费的变化就难以实现,更不用说对一年内就达1200多万条记录的200专用话机话费细节表进行200专用话机进行话费的动态分析了。笔者曾经使用OLAP工具BrioQuery在PC机上实现200万条记录的话费细节表在时间维度上的转换,运行135个小时也没有转换成功。在电信市场尤其是公话市场竞争日益激烈的今天,为了实现经营分析人员所迫切进行的200专用话机话费的动态分析,必须对上面的星形模式进行特殊的处理,笔者所采用的方法是在事实表中有选择地使用维,将事实表200专用话机话务中的时间维去掉,在事实表中增加各个时间维成员作为事实表的字段,使用存贮过程编写维度转换程序来代替OLAP的操作。
<wbr></wbr>
<wbr><wbr><wbr><strong>3.1有选择地使用维的星形模式</strong></wbr></wbr></wbr>
<wbr></wbr><wbr><wbr><wbr><wbr></wbr></wbr></wbr></wbr>
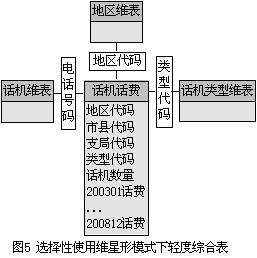
…<wbr><wbr><wbr><wbr><wbr></wbr></wbr></wbr></wbr></wbr>
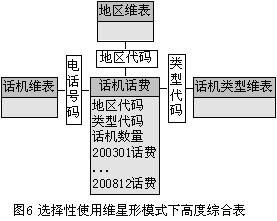
<wbr></wbr>
对于关系模式的这种设计,大家可能会一方面质疑它的扩展性,即它能进行其它时期话费的动态分析吗?另一方面可能会质疑如果它可以扩展来进行其它时期话机话费的动态分析,那最多进行多少年话机话费的动态分析?在笔者开发的200专用话机话费的动态分析系统中,只要在选择性使用维的星形模式中各级话费表中增加几个月份的金额字段,在我编写的维度转换程序中增加几个变量及几条赋值语句,就可以统计分析许多年的话费数据;两者,MS SQL SERVER7.0最多支持1024列的表,这可以用来统计分析80多年的数据。
<wbr></wbr>
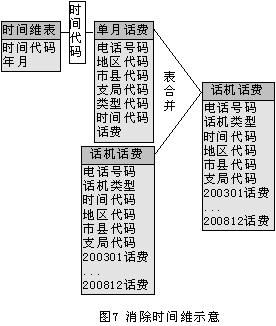
3.2 话务表中时间维的旋转
在笔者开发的200专用话机话费的动态分析系统中,笔者采用的方法是每个月对该月的话机话务表和图4中的细节表进行合并,这样做的优点一是每次只需要处理一个月一百多万条200专用话机话费记录,而不是像OLAP工具那样处理n个月的话费数据;二是经过查询优化,在PC机上每一个月200专用话机话费表的合并操作只需要一个小时的处理时间。具体合并过程如下图所示:
<wbr></wbr>
<wbr></wbr>
4 结束语
<wbr></wbr>
对于使用数据仓库来回答综合性问题的场合,星形连接模式可以满足决策者从不同的维来观察数据的需求,并且通常的OLAP工具可以实现记录不多的综合级表的维度旋转。笔者曾在PC机上使用某一OLAP工具来实现两个月200多万条话费记录的维度转换时,运行了xx小时也没有完成时间维的转换操作。而在数据仓库中较高粒度表中记录非常多或者还要经常回答细节问题的场合,则还必须对数据仓库中记录非常多的较高粒度的表或者细节级表进行维度转换。如分析电信运营商中几十万、几百万乃至于几千万部话机在时间维不同维成员的话费变化时,通常的OLAP工具却难以完成这样的操作。笔者在”广东电信公用电话200专用话机话务的动态分析系统”的研究与开发过程中,在数据仓库设计时有选择地使用维,在星形模式中各粒度200专用话机话费表中避开使用时间维,然后用存贮过程编写维度转换程序代替OLAP工具来旋转操作型环境下话费表中的时间维,在PC机上每一次只需要一个小时就完成了一个月一百多万条记录的话费表的维度转换并生成了数据仓库中各粒度表的数据,轻松地实现了一百多万部200专用话机话费的动态分析,对数据仓库星形模式下维的使用原则做出了一定的探索。
<wbr></wbr>
<wbr></wbr>
参考文献:
[1]<wbr> 王珊 · 数据仓库技术与联机分析处理 · 北京:科学出版社,1998.6</wbr>
[2]<wbr> Michael Corey(美),Michael Abbey(美) · SQL SERVER 7 Data Warehousing · 北京:希望电子出版社,2000.1</wbr>
[3]<wbr> 袁鹏飞 · SQL Server 7.0数据库系统管理与应用开发 · 北京:人民邮电出版社,1999.5</wbr>