ios序列化与反序列化,本地化
你是用什么方法来持久保存数据的?这是在几乎每一次关于iOS技术的交流或讨论都会被提到的问题,而且大家对这个问题的热情持续高涨。本文主要从概念上把“数据存储”这个问题进行剖析,并且结合各自特点和适用场景给大家提供一个选择的思路,并不详细介绍某一种方式的技术细节。
谈到数据储存,首先要明确区分两个概念,数据结构和储存方式。所谓数据结构就是数据存在的形式。除了基本的NSDictionary、NSArray和NSSet这些对象,还有更复杂的如:关系模型、对象图和属性列表多种结构。而存储方式则简单的分为两种:内存与闪存。内存存储是临时的,运行时有效的,但效率高,而闪存则是一种持久化存储,但产生I/O消耗,效率相对低。把内存数据转移到闪存中进行持久化的操作称成为归档。
二者结合起来才是完整的数据存储方案,我们最常谈起的那些:SQLite、CoreData、NSUserDefaults等都是数据存储方案。当然在这些框架提供的方案之外,我们自己也可以按照个性化需求订制方案。这些存储方案侧重不同,支持的形式和方式也各不相同,在不同的使用场景下表现也是各有优劣。但万变不离其宗,无论什么方案都可以用下图来解释。
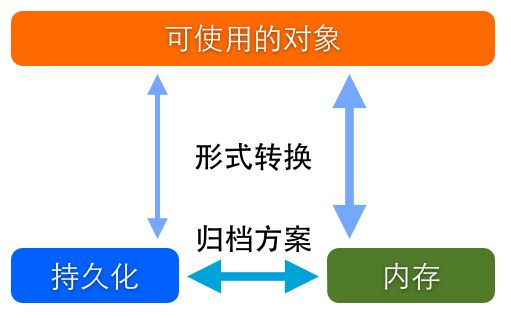
图1,存储方案示意图
以下将对四种存储方式进行详细的介绍:
NSUserDefaults,用于存储配置信息
SQLite,用于存储查询需求较多的数据
CoreData,用于规划应用中的对象
使用基本对象类型定制的个性化缓存方案
用NSUserDefaults存储配置信息
NSUserDefaults被设计用来存储设备和应用的配置信息,它通过一个工厂方法返回默认的、也是最常用到的实例对象。这个对象中储存了系统中用户的配置信息,开发者可以通过这个实例对象对这些已有的信息进行修改,也可以按照自己的需求创建新的配置项。
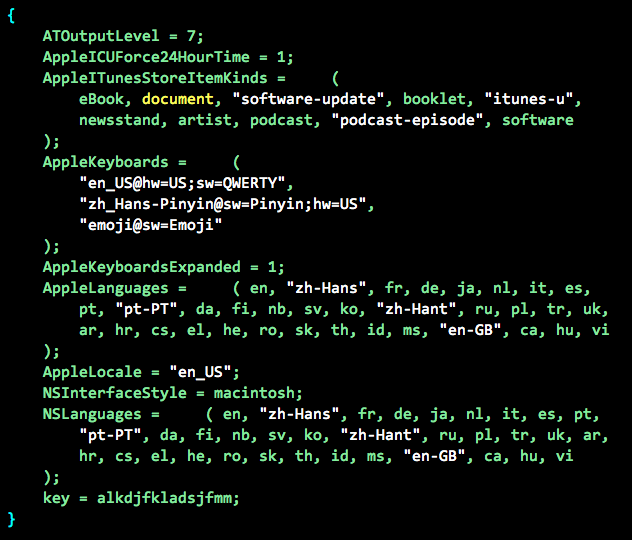
图2,笔者手机中[NSUserDefaults standardUserDefaults]内容
NSUserDefaults把配置信息以字典的形式组织起来,支持字典的项包括:字符串或者是数组,除此之外还支持数字等基本格式。一句话概括就是:基础类型的小数据的字典。操作方法几乎与NSDictionary的操作方法无异,另外还可以通过指定返回类型的方法获取到指定类型的返回值。
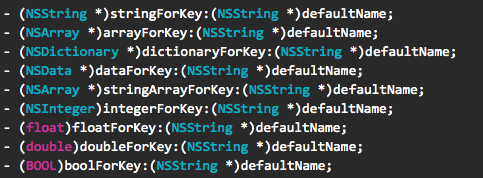
图3,NSUserDefaults提供的指定返回类型的方法列表
NSUserDefaults的所有数据都放在内存里,因此操作速度很快,并还提供一个归档方法:+ (void)synchronize。开发者自定义的配置项(如图2中的最后一项 key:alkdjfkladsjfmm)会以plist格式的文件归档在相应应用目录的/Library/Preferences/[App_Bundle_Identifier].plist文件。再次初始化获得实例对象后,框架会把用户自定义的这个配置和系统配置合并得到完整数据。
用SQLite存储查询需求较多的数据
iOS的SDK里预置了SQLite的库,开发者可以自建SQLite数据库。SQLite每次写入数据都会产生IO消耗,把数据归档到相应的文件。
SQLite擅长处理的数据类型其实与NSUserDefaults差不多,也是基础类型的小数据,只是从组织形式上不同。开发者可以以关系型数据库的方式组织数据,使用SQL DML来管理数据。 一般来说应用中的格式化的文本类数据可以存放在数据库中,尤其是类似聊天记录、Timeline等这些具有条件查询和排序需求的数据。
每一个数据库的句柄都会在内存中都会被分配一段缓存,用于提高查询效率。另一个方面,由于查询缓存,当产生大量句柄或数据量较大时,会出现缓存过大,造成内存浪费。
SQLite的使用起来要比NSUserDefaults复杂的多,因此建议开发者使用SQLite要搭配一个操作控件使用,可以简化操作。笔者开发的SQLight是一款对SQLite操作的封装,把相对复杂的SQLite命令封装成对象和方法,可以供大家参考。大家可以在Github上获取这个工程的代码进一步了解。
用CoreData规划应用中对象
官方给出的定义是,一个支持持久化的,对象图和生命周期的自动化管理方案。严格意义上说CoreData是一个管理方案,他的持久化可以通过SQLite、XML或二进制文件储存。如官方定义所说,CoreData的作用远远不止储存数据这么简单,它可以把整个应用中的对象建模并进行自动化的管理。
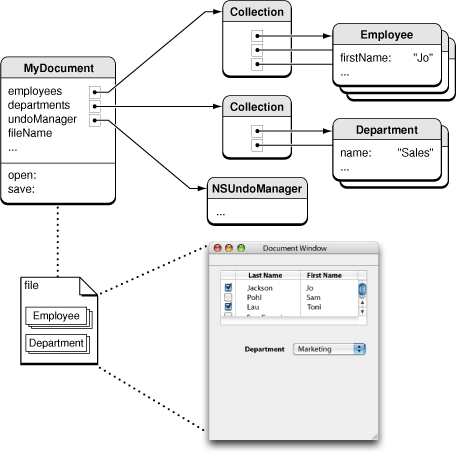
图4,官方文档中解释CoreData给出的对象图示例
正如上图所示,MyDocument是一个对象实例,有两个Collection:Employee和Department,存放各自的对象列表。MyDocument、Employee和Department三个对象以及他们之间的关系都通过CoreData建模,并可以通过save方法进行持久化。
从归档文件还原模型时CoreData并不是一次性把整个模型中的所有数据都载入内存,而是根据运行时状态,把被调用到的对象实例载入内存。框架会自动控制这个过程,从而达到控制内存消耗,避免浪费。
无论从设计原理还是使用方法上看,CoreData都比较复杂。因此,如果仅仅是考虑缓存数据这个需求,CoreData绝对不是一个优选方案。CoreData的使用场景在于:整个应用使用CoreData规划,把应用内的数据通过CoreData建模,完全基于CoreData架构应用。
苹果官方给出的一个示例代码,结构相对简单,可以帮助大家入门CoreData。
obj-c中有一类对象:NSArray,NSDictionary,NSString,NSNumber,NSDate,NSData以及它们的可变版本(指NSMutableArray,NSMutableDictionary...这一类) ,都可以方便的将自身的数据以某种格式(比如xml格式)序列化后保存成本地文件。
示例代码:NSArrayTest.h
#import <Foundation/Foundation.h>
#define FILE_NAME @"/tmp/data.txt"
@interface NSArrayTest : NSObject {
}
-(void) Test;
@end
#import "NSArrayTest.h"
@implementation NSArrayTest
-(void) Test
{
NSArray *arr = [NSArray arrayWithObjects:@"one",@"two",@"three",nil]; //注:最后一个要以nil结尾
[arr writeToFile:FILE_NAME atomically:YES]; //(序列化为xml格式后)保存文件
NSArray *arr2 = [NSArray arrayWithContentsOfFile:FILE_NAME]; //read file
NSLog(@"%@",arr2);
}
@end
运行结果:NSArrayTest.m
2011-03-03 14:20:01.501 pList[1246:a0f] (
one,
two,
three
)
如果查看/tmp/data.txt,能看到下面的内容:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <array> <string>one</string> <string>two</string> <string>three</string> </array> </plist>
即NSArray默认是以xml格式来序列化对象的.
如果你用来存放数据的类是自己定义的,并不是上面这些预置的对象,那么就要借助正式协议NSCoding来实现序列化和反序列化。
比如,我们有一个自己的类Sample.h
#import <Foundation/Foundation.h>
@interface Sample : NSObject<NSCoding> {
NSString* name;
int magicNumber;
float shoeSize;
NSMutableArray *subThingies;
}
@property(copy) NSString* name;
@property int magicNumber;
@property float shoeSize;
@property (retain) NSMutableArray *subThingies;
-(id) initWithName:(NSString *)n magicNumber:(int)m shoeSize:(float) ss;
@end
这里我们定义几个不同类型的属性,有字符串,有整数,有浮点数,还有一个可变长的数组对象
Sample.m
#import "Sample.h"
@implementation Sample
@synthesize name;
@synthesize magicNumber;
@synthesize shoeSize;
@synthesize subThingies;
-(id) initWithName:(NSString *)n magicNumber:(int)m shoeSize:(float)ss
{
if (self=[super init])
{
self.name = n;
self.magicNumber = m;
self.shoeSize = ss;
self.subThingies = [NSMutableArray array];
}
return (self);
}
-(void) dealloc
{
[name release];
[subThingies release];
[super dealloc];
}
//将对象编码(即:序列化)
-(void) encodeWithCoder:(NSCoder *)aCoder
{
[aCoder encodeObject:name forKey:@"name"];
[aCoder encodeInt:magicNumber forKey:@"magicNumber"];
[aCoder encodeFloat:shoeSize forKey:@"shoeSize"];
[aCoder encodeObject:subThingies forKey:@"subThingies"];
}
//将对象解码(反序列化)
-(id) initWithCoder:(NSCoder *)aDecoder
{
if (self=[super init])
{
self.name = [aDecoder decodeObjectForKey:@"name"];
self.magicNumber = [aDecoder decodeIntForKey:@"magicNumber"];
self.shoeSize = [aDecoder decodeFloatForKey:@"shoeSize"];
self.subThingies = [aDecoder decodeObjectForKey:@"subThingies"];
}
return (self);
}
-(NSString*) description
{
NSString *description = [NSString stringWithFormat:@"%@:%d/%.1f %@",name,magicNumber,shoeSize,subThingies];
return (description);
}
@end
注意其中的:encodeWithCoder与initWithCoder,这是NSCoding协议中定义的二个方法,用来实现对象的编码与解码。其实现也不复杂,利用的是key-value的经典哈希结构。当然一般在编码中,对于key的名字字符串,建议用define以常量方式事先定义好,以避免开发人员字符串键入错误。
测试一下:
#import <Foundation/Foundation.h>
#import "Sample.h"
int main (int argc, const char * argv[]) {
NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init];
Sample *s1 = [[Sample alloc] initWithName:@"thing1" magicNumber:42 shoeSize:10.5];
[s1.subThingies addObject:@"1"];
[s1.subThingies addObject:@"2"];
NSLog(@"%@",s1);
NSData *data1 = [NSKeyedArchiver archivedDataWithRootObject:s1];//将s1序列化后,保存到NSData中
[s1 release];
[data1 writeToFile:@"/tmp/data.txt" atomically:YES];//持久化保存成物理文件
NSData *data2 = [NSData dataWithContentsOfFile:@"/tmp/data.txt"];//读取文件
Sample *s2 = [NSKeyedUnarchiver unarchiveObjectWithData:data2];//反序列化
NSLog(@"%@",s2);
[pool drain];
return 0;
}
运行结果:
2011-03-03 14:36:48.540 pList[1322:a0f] thing1:42/10.5 (
1,
2
)
2011-03-03 14:36:48.548 pList[1322:a0f] thing1:42/10.5 (
1,
2
)
查看/tmp/data.txt,能看到以下内容:
由于经过了编码,里面的内容没有象前面的NSArray那样可读性强。
有关序列化和反序列化内容转自如下地址:
http://www.cnblogs.com/yjmyzz/archive/2011/03/03/1969859.html