Python自学笔记之基础内容回顾
语法
Python的语法比比较简单,采用缩进方式。
缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的惯例,应该始终坚持使用4个空格的缩进。
缩进的另一个好处就是强迫你写出缩进较少的代码,你会倾向于把一段很长的代码拆分成若干函数,从而得到缩进较少的代码。
缩进的坏处就是“复制-粘贴”功能失效了。当你重构代码的时候,粘贴过去的代码必须重新检查缩进是否正确。此外,IDE很难像格式化Java代码那样格式化Python代码。
代码中以#开头的语句是注释,解释器会忽略掉注释。其他每一行为一个语句,当语句以“:”结尾时,缩进的语句视为代码块。
Python程序是大小写敏感的,如果写错大小写,程序会报错。
数据类型
Python中能够直接处理的数据类型有以下几种:
整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样。
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是相等的。对于很大的浮点数,必须用科学记数法表示的,把10用e替代,1.23x109就是1.23e9或者12.3e8,0.00012可以写成1.2e-4等等。
整数和浮点数在计算机内部存储方式是不同的,整数运算永远是精确的(除法也是!),而浮点数运算则可能会有四舍五入的误差。
字符串
字符串是以‘’或者“”括起来的任意文本,比如‘abc’,“xyz”等。请注意,‘’或“”本身只是一种表示方式,不是字符串的一部分,因此,字符串‘abc’只有a,b,c这三个字符。如果‘本身也是一个字符,那就可以用“”括起来,比如“I'm ok”包含的字符就是I,’,m,空格,o,k这六个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:' I\'m \"OK\"!' 表示的字符串内容是:I'm "OK"!
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\。
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义。而如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,可以尝试:
>>> print '''line1 ... line2 ... line2''' line1 line2 line3
上面是交互式命令行内输入,换行时自动生成...,写程序时无需添加。多行字符串'''...'''还可以在前面加上r使用。
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来。
布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True;
or运算是或运算,只要其中有一个为True,or运算结果就是True;
not运算是非运算,它是一个单目运算符,把True变成False,False变成True。
布尔值经常用在条件判断中。
空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、紫癜等多种数据类型,还允许创建自定义数据类型,可参见其它笔记。
变量
变量的概念基本上和初中代数方程变量是一致的,只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。变量在程序中就是用一个变量名表示,变量名必须是大小写英文、数字和_的组合,且不能用数字开头。
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下:
int a = 123; // a是整型变量 a = "ABC"; // 错误:不能把字符串赋给整型变量
和静态语言相比,动态语言更灵活,就是这个原因。
最后,理解变量在计算机内存中的表示也非常重要。当我们写:a = 'ABC' 时,Python解释器干了两件事:
在内存中创建了一个'ABC'的字符串;
在内存中创建了一个名为a的变量,并把它指向'ABC'。
也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如:
a = 'ABC' b = a a = 'XYZ' print b
最后一行打印出变量b的内容到底是'ABC'还是'XYZ'?如果从数字意义上理解,就会错误地得出b和a相同,也应该是'XYZ',但实际上b的值是'ABC',让我们一行一行地执行代码,就可以看到到底发生了什么:
执行 a = 'ABC',解释器创建了字符串'ABC'和变量a,并把a指向'ABC':

执行 b = a,解释器创建了变量b,并把b指向a指向的字符串'ABC':

执行a = 'XYZ', 解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:

所以,最后打印变量b的结果自然是'ABC'了。
常量
所谓常量就是不能变的变量,比如常用的数学常数pi就是一个常量。在Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示变量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
最后解释一下为什么整数的除法也是精确的,
>>> 10 / 3 3
整数除法得到的结果永远是整数,即使除不尽。要做精确的除法,只需把其中一个整数换成浮点数座除法就可以:
>>> 10.0 / 3 3.3333333333333335
因为整数除法只取结果的整数部分,所以Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 3 1
无论整数做除法还是取余数,结果永远是整数,所以,整数运算结果永远是精确的。
字符串和编码
字符编码
字符串作为一种数据类型,比较特殊的是编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换成数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
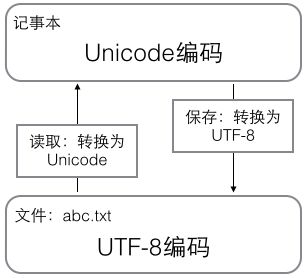
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题,我们再来研究Python对Unicode的支持。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。Python提供了ord()和chr()函数,可以把字母和对应的数字相互转换:
>>> ord('A')
65
>>> chr(65)
'A'
Python后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
>>> print u '中文' 中文 >>> u '中' u'\u4e2d'
写u'中'和u'\u4e2d'是一样的,\u后面是十六进制的Unicode码。因此,u'A'和u'\u0041'也是一样的。
两种字符串如何转换?字符串'xxx'虽然是ASCII编码,但也可以看成是UTF-8编码,而u'xxx'则只能是Unicode编码。
把u'xxx'转换成UTF-8编码的'xxx'用encode('utf-8')方法:
>>> u'ABC'.encode('utf-8')
'ABC'
>>> u'中文'.encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
英文字符转换后表示的UTF-8的值和Unicode值相等(但占用的存储空间不同),而中文字符转换后1个Unicode字符将变为3个UTF-8字符,你看到的\xe4就是其中一个字节,因为它的值是228,没有对应的字母可以显示,所以以十六进制显示字节的数值。len()函数可以返回字符串的长度:
>>> len(u'ABC')
3
>>> len('ABC')
3
>>> len(u'中文')
2
>>> len('\xe4\xb8\xad\xe6\x96\x87')
6
反过来,把UTF-8编码表示的字符串'xxx'转换为Unicode字符串u'xxx'用decode('utf-8')方法:
>>> 'abc'.decode('utf-8')
u'abc'
>>> '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
u'\u4e2d\u6587'
>>> print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
中文
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python # -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
如果你使用Notepad++进行编辑,除了要加上# -*- coding: utf-8 -*-外,中文字符串必须是Unicode字符串。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保Notepad++正在使用UTF-8 without BOM编码(该选项在Encoding下拉菜单中可找到)。
如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中。
总之,由于历史遗留问题,Python2.x版本仍然支持Unicode,但在语法上需要'xxx'和u'xxx'两种字符串表示方式。
Python当然也支持其他编码方式,比如把Unicode编码成GB2312:
>>> u'中文'.encode('gb2312')
'\xd6\xd0\xce\xc4'
但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅适用Unicode和UTF-8这两种编码方式。
在Python3.x版本中,把'xxx'和u'xxx'统一成Unicode编码,即写不写前缀u都是一样,而以自己形式表示的字符串则必须加上b前缀:b'xxx'。
格式化
另一个常见问题是如何输出格式化的字符串。我们经常会输出类似‘亲爱的xxx你好!你xx月的话费是xx,余额是xx’之类的字符串,而xxx的内容是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
在Python中,采用的格式化方式和C语言是一致的,用%实现,如:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
%d 整数
%f 浮点数
%s 字符串
%x 十六进制整数
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3,1) ' 3-01' >>> '%.2f' % 3.1415926 '3.14'
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True) 'Age: 25. Gender: True'
对于Unicode字符串,用法完全一样,但最好确保替换的字符串也是Unicode字符串:
>>> u'Hi, %s' % u'Michael' u'Hi, Michael'
有些时候,字符串里面的%是一个普通的字符,就需要用%%进行转义,来表示一个%:
>>> 'growth rate: %d %%' % 7 'growth rate: 7 %'
使用list和tuple
list
Python内置的一个数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> classmates = ['Mike', 'Bob', 'Tracy'] >>> classmates ['Mike', 'Bob', 'Tracy']
变量classmates就是一个list。用len()函数可以获得list元素的个数:
>>> len(classmates) 3
用索引来访问list中每一个位置的元素,索引是从0开始的:
>>> classmates[0] 'Mike' >>> classmates[3] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
当索引超出范围时,Python会报一个IndexError错误,所以要确保索引不越界,即最后一个元素的索引是 len(classmates) - 1
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1] 'Tracy'
以此类推,可以获取倒数第二个、倒数第三个:
>>> classmates[-2] 'Bob' >>> classmates[-3] 'Mike' >>> classmates[-4] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
当然,倒数第四个就越界了。
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Mike', 'Bob', 'Tracy', 'Adam']
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack') >>> classmates ['Mike', 'Jack', 'Bob', 'Tracy', 'Adam']
要删除list末尾的元素,用pop()方法:
>>> classmates.pop() 'Adam' >>> classmates ['Mike', 'Jack', 'Bob', 'Tracy']
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1) 'Jack' >>> classmates ['Mike', 'Bob', 'Tracy']
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah' >>> classmates ['Mike', 'Sarah', 'Tracy']
list里面的元素的数据类型也可以是不同的:
>>> L = ['Apple', 123, True] list元素也可以是另一个list: >>> s = ['python', 'java', ['asp', 'php'], 'scheme'] >>> len(s) 4
要拿到'php'可以写s[2][1],因此s可以看成是一个二位数足,类似的还有三维、四维......数组,不过很少用到。
如果一个list中一个元素也没有,就是一个空的list,它的长度是0。
tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Mike', 'Bob', 'Tracy')
现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmatesp[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple的意义在于代码的安全性。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
>>> t = (1, 2) >>> t (1,2)
如果要定义一个空的tuple,可以写成():
>>> t = () >>> t ()
但是要定义一个只有1这一个元素的tuple,如果你这么定义:
>>> t = (1) >>> t 1
定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1这个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,) >>> t (1,)
Python在显示只有1这个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
最后来看一个“可变的“tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
表面上看,tuple的元素确实变了,但其实变得不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的”不变“是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!