ZooKeeper服务端单机版 ZooKeeperServer初始化源码分析
一.初始化ZooKeeperServer

1. ServerStats:统计服务器运行数据

2. FileTxnSnapLog
用于对服务器日志和数据进行操作。从配置文件读取,并初始化存储位置。
默认日志存储路径和数据一样。
3. ZKDatabase
用于存储数据,日志,sessionId,树结构DataTree
4.tickTime
public static final int DEFAULT_TICK_TIME = 3000;
protected int tickTime = DEFAULT_TICK_TIME;
默认是3秒,这里初始化的是配置文件的tickTime。
用处:
1)用于计算seesion最大,最小超时时间
protected int minSessionTimeout = -1;
protected int maxSessionTimeout = -1;
如果配置文件没设置,则最大超时时间为tickTime20倍,最小超时时间为tickTime 2倍
2)用于计算initLimit, syncLimit
initLimit* tickTime,syncLimit* tickTime
二.运行simple zookeeper server
在NIOServerCnxnFactory执行startup时,会对zookeeper server进行初始化

初始化数据:
public void startdata()
throws
IOException, InterruptedException {
//check to see if zkDb is not null
//如果zkDb为空,则初始化
if
(
zkDb
==
null
) {
zkDb
=
new
ZKDatabase(
this
.
txnLogFactory
);
}
//如果zkDb未加载完成,设置 zxid,杀死session,保存数据至disk(即清空snapshot)
if
(!
zkDb
.isInitialized()) {
loadData();
}
}
初始化一些基本配置:
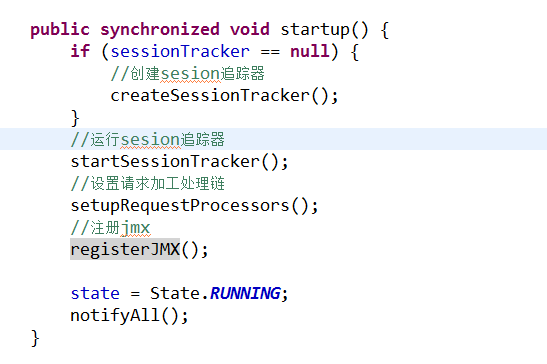
1创建session追踪器

sessionsById: key:sessionId value:session
sessionsWithTimeout: key:sessionId value:过期时间
该属性会再每次addSession时改变
sessionExpryQueue: 时间整点的session队列,用于session过期检查
nextSessionId:下次createSession时sessionId为该数值+1
2.启动session追踪器:
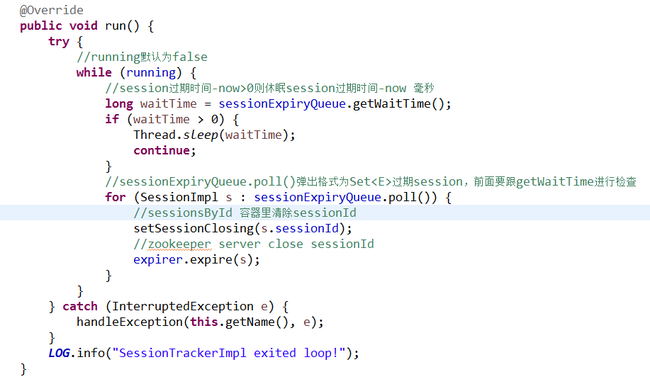
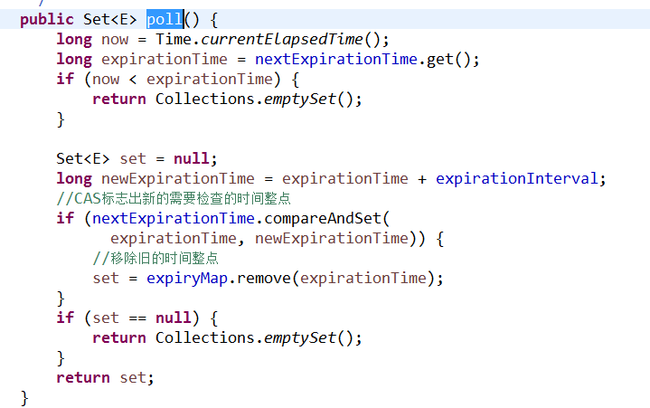
下面是sessionExpiryQueue.poll()的代码
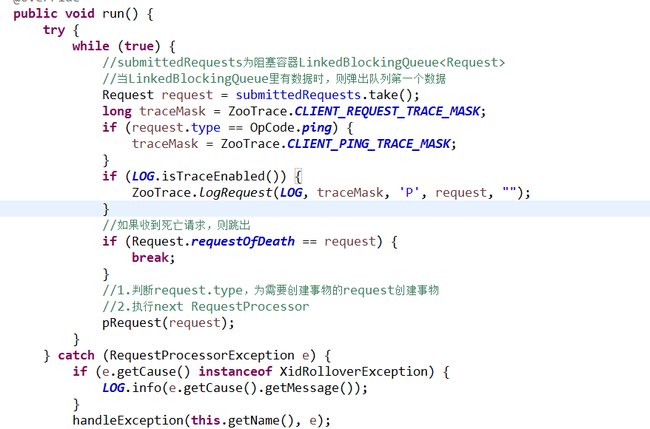
3. setupRequestProcessors()创建请求加工链
PrepRequestProcessor——> SyncRequestProcessor——>FinalRequestProcessor
PrepRequestProcessor:是一个阻塞自旋线程,对需要创建事物的请求创建事物,同时对session一些检查,run代码如下
SyncRequestProcessor: 自旋线程, 主要对事务请求进行日志记录,同时事务请求达到一定次数(超过 snapCount /2- snapCount之间的某一个值 )后,就会执行一次快照 。 代码如下
@Override
public
void
run() {
try
{
int
logCount
= 0;
// we do this in an attempt to ensure that not all of the servers
// in the ensemble take a snapshot at the same time
int
randRoll
=
r
.nextInt(
snapCount
/2);
while
(
true
) {
Request
si
=
null
;
//要输出数据为空则等待
if
(
toFlush
.isEmpty()) {
//processRequest(Request request) 时queuedRequests.add(request);
//单机版这儿为PrepRequestProcessor发送过来的request
si
=
queuedRequests
.take();
}
else
{
//poll()算法为非阻塞算法,立即返回或等待一会再返回
si
=
queuedRequests
.poll();
//当期没有请求进来时
if
(
si
==
null
) {
//提交所有遗留的request的日志,执行next.processRequest
flush(
toFlush
);
continue
;
}
}
if
(
si
==
requestOfDeath
) {
break
;
}
if
(
si
!=
null
) {
// track the number of records written to the log
//记录写入日志记录写入日志的记录数,如果成功记录
//据说这步是区分是事物还是非事物,非事物返回false
if
(
zks
.getZKDatabase().append(
si
)) {
logCount
++;
//logCount>snapCount/2+(0-snapCount/2)
//这么做是为了所有服务器不再同一时间采用快照
if
(
logCount
> (
snapCount
/ 2 +
randRoll
)) {
randRoll
=
r
.nextInt(
snapCount
/2);
// roll the log
zks
.getZKDatabase().rollLog();
// take a snapshot
if
(
snapInProcess
!=
null
&&
snapInProcess
.isAlive()) {
LOG
.warn(
"Too busy to snap, skipping"
);
}
else
{
//保存数据
snapInProcess
=
new
ZooKeeperThread(
"Snapshot Thread"
) {
public
void
run() {
try
{
zks
.takeSnapshot();
}
catch
(Exception
e
) {
LOG
.warn(
"Unexpected exception"
,
e
);
}
}
};
snapInProcess
.start();
}
logCount
= 0;
}
}
else
if
(
toFlush
.isEmpty()) {
//之前没有遗留请求,则执行下一个请求加工处理器
// optimization for read heavy workloads
// iff this is a read, and there are no pending
// flushes (writes), then just pass this to the next
// processor
if
(
nextProcessor
!=
null
) {
nextProcessor
.processRequest(
si
);
if
(
nextProcessor
instanceof
Flushable) {
((Flushable)
nextProcessor
).flush();
}
}
continue
;
}
toFlush
.add(
si
);
//遗留请求超过1000时,对遗留请求进行处理,还有一个处理是,再上面开头
//上面开头。当前没有请求进来时,对遗留请求进行处理
if
(
toFlush
.size() > 1000) {
//提交所有遗留的request日志,执行next.processRequest
flush(
toFlush
);
}
}
}
}
catch
(Throwable
t
) {
handleException(
this
.getName(),
t
);
}
finally
{
running
=
false
;
}
LOG
.info(
"SyncRequestProcessor exited!"
);
}
主要操作:
1.自旋操作
2.判断未写入日志请求
toFlush
是否为空 ,若为空,则阻塞等待新的请求,若不为空,则非阻塞获取请求,若无请求可获取,则写入日志
3.收到死亡请求跳出自旋
4.如果是事物请求,zkdatabase添加日志,并判断日志数量
logCount是否达到snapCount(发生几次snapCount,就会执行一次快照)/2+0到snapCount/2 次数,若达到,生成数据快照
为什么会有个区间,是为了避免,所有服务器同一时间写入日志
5.如果非事物,若
toFlush为空,则执行下一个请求加工处理器。
6.若都不是,则把request添加至
toFlush,等待写入日志
FinalRequestProcessor主要操作:
1.增删改DataTree
2.新增或关闭session
3.
移除
List<ChangeRecord>outstandingChanges, zxid<
当前
zxid
的
ChangeRecord
数据,同时移除相对应
outstandingChangesForPath
4.如果是集群:
zks
.getZKDatabase(). addCommittedProposal(
request
)
5.
如果
request.type
为
closeSession,
关闭
ServerCnxnFactory
里对应的
seesionId,return.
6.
根据不同
request.type,
准备返回值
response
代码太行。。就不贴了。