执行计划
--查看执行计划
explain plan for select * from table_name where 1=1;
select * from table(dbms_xplan.display);
--阅读执行计划
表访问方式
1.Full Table Scan (FTS) 全表扫描
2.Index Lookup 索引扫描
index unique scan --索引唯一扫描
index range scan --索引局部扫描
index full scan --索引全局扫描
index fast full scan --索引快速全局扫描,不带order by情况下常发生
index skip scan --索引跳跃扫描,where条件列是非索引的前导列情况下常发生
3.Rowid 物理ID扫描
表连接方式
1.Sort Merge Join (SMJ) --由于sort是非常耗资源的,所以这种连接方式要避免
2.Nested Loops (NL) --比较高效的一种连接方式
3.Hash Join --最为高效的一种连接方式
运算符
1.sort --排序,很消耗资源
2.filter --过滤,如not in、min函数等容易产生
3.view --视图,大都由内联视图产生
4.partition view --分区视图
那么,作为开发人员,怎么样比较简单的利用执行计划评估SQL语句的性能呢?总结如下步骤供大家参考:
1、 打开熟悉的查看工具:PL/SQL Developer。
在PL/SQL Developer中写好一段SQL代码后,按F5,PL/SQL Developer会自动打开执行计划窗口,显示该SQL的执行计划。
2、 查看总COST,获得资源耗费的总体印象
一般而言,执行计划第一行所对应的COST(即成本耗费)值,反应了运行这段SQL的总体估计成本,单看这个总成本没有实际意义,但可以拿它与相同逻辑不同执行计划的SQL的总体COST进行比较,通常COST低的执行计划要好一些。
3、 按照从左至右,从上至下的方法,了解执行计划的执行步骤
执行计划按照层次逐步缩进,从左至右看,缩进最多的那一步,最先执行,如果缩进量相同,则按照从上而下的方法判断执行顺序,可粗略认为上面的步骤优先执行。每一个执行步骤都有对应的COST,可从单步COST的高低,以及单步的估计结果集(对应ROWS/基数),来分析表的访问方式,连接顺序以及连接方式是否合理。
4、 分析表的访问方式
表的访问方式主要是两种:全表扫描(TABLE ACCESS FULL)和索引扫描(INDEX SCAN),如果表上存在选择性很好的索引,却走了全表扫描,而且是大表的全表扫描,就说明表的访问方式可能存在问题;若大表上没有合适的索引而走了全表扫描,就需要分析能否建立索引,或者是否能选择更合适的表连接方式和连接顺序以提高效率。
5、 分析表的连接方式和连接顺序
表的连接顺序:就是以哪张表作为驱动表来连接其他表的先后访问顺序。
表的连接方式:简单来讲,就是两个表获得满足条件的数据时的连接过程。主要有三种表连接方式,嵌套循环(NESTED LOOPS)、哈希连接(HASH JOIN)和排序-合并连接(SORT MERGE JOIN)。我们常见得是嵌套循环和哈希连接。
嵌套循环:最适用也是最简单的连接方式。类似于用两层循环处理两个游标,外层游标称作驱动表,Oracle检索驱动表的数据,一条一条的代入内层游标,查找满足WHERE条件的所有数据,因此内层游标表中可用索引的选择性越好,嵌套循环连接的性能就越高。
哈希连接:先将驱动表的数据按照条件字段以散列的方式放入内存,然后在内存中匹配满足条件的行。哈希连接需要有合适的内存,而且必须在CBO优化模式下,连接两表的WHERE条件有等号的情况下才可以使用。哈希连接在表的数据量较大,表中没有合适的索引可用时比嵌套循环的效率要高。
附I:实例分析
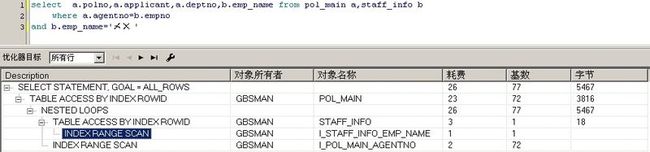
以上SQL的执行计划,按照上述步骤分析:
首先:总体COST 26 ,暂时没有其他的执行计划可以比较,有个总体印象即可。
其次:执行顺序:
最里面的缩进位倒数第二行, INDEX_RANGE_SCAN 是表的访问方式,说明通过索引I_STAFF_INFO_EMP_NAME访问STAFF_INFO表,该步骤的COST(耗费) 为 1,类似于select rowid from staff_info where emp_name=’xx’;估计返回的行数为1(通过基数/rows可以看出);
TABLE ACCESS BY INDEX ROWID和最下面的INDEX RANGE SCAN的缩进量相同,
说明他们是同一层次执行的,可认为TABLE ACCESS BY INDEX ROWID先执行,该步骤从上面获得的rowid访问STAFF_INFO表,获得EMPNO的结果集。该步骤COST为3;估计返回的行数为1;
最下面的INDEX RANGE SCAN,获取数据的方式可以理解为select rowid from pol_main
where agentno=:empno,这时使用到索引I_POL_MAIN_AGENTNO, 花费的COST为2;估计返回的行数为72;
再次:表的访问方式:
很显然,两表都采用了索引扫描的方法,这两张表索引的选择性都很好,说明都有合适的索引可用,采用索引扫描的方式是没有问题的。
接下来:表的连接顺序和连接方式:
这里的顺数第三行为NESTED LOOPS,说明表的连接方式为嵌套循环,那么,
连接顺序呢?根据上面的执行顺序可以看出,该执行计划首先利用从STAFF_INFO表的where emp_name=’xx’这个条件获得EMPNO结果子集,这个结果子集成为嵌套循环的外层游标(作为驱动表),一条一条的循环执行select rowid from pol_main
where agentno=:empno,直到获得最终需要的所有数据。即:连接顺序是STAFF_INFOàPOL_MIAN表,连接方式是嵌套循环。我们从实际的数据量以及获得测试SQL运行结果的速度来看,这样的执行计划是可行的,应该不会有效率问题
对比一下该SQL其他两种连接方式的执行计划

这里的总COST远远大于嵌套循环,该执行计划将STAFF_INFO或者的结果子集作为驱动表,散列内存中,然后逐条和POL_MAIN表全扫描获得的数据进行匹配,通过执行速度测试和COST总体比较分析可知,这种执行计划是可能有问题的,COST可能存在问题的地方,就是POL_MAIN的全表扫描,该步骤的COST为6731。如果要优化,就要考虑改变这里的访问方式。
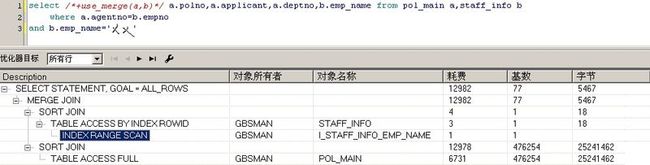
这里的COST就更远远大于嵌套循环了,排序合并的连接方式,不存在驱动表的概念,它将两张表的数据都读入内存,然后分别排序,最后将合并数据,获得满足条件的最终结果集,由于多了排序这个耗费资源的过程,一般来讲,排序合并连接方式的效率比哈希连接要差,只有存在排序要求的情况下,排序合并连接方式的效率才肯能比哈希连接要好,此外,哈希连接不能够用在非等值连接中,而排序合并连接可以使用。
总结两点:
1、这里看到的执行计划,只是SQL运行前可能的执行方式,实际运行时可能因为软硬件环境的不同,而有所改变,而且cost高的执行计划,不一定在实际运行起来,速度就一定差,我们平时需要结合执行计划,和实际测试的运行时间,来确定一个执行计划的好坏。
2、对于表的连接顺序,多数情况下使用的是嵌套循环,尤其是在索引可用性好的情况下,使用嵌套循环式最好的,但当ORACLE发现需要访问的数据表较大,索引的成本较高或者没有合适的索引可用时,会考虑使用哈希连接,以提高效率。排序合并连接的性能最差,但在存在排序需求,或者存在非等值连接无法使用哈希连接的情况下,排序合并的效率,也可能比哈希连接或嵌套循环要好。
附II:几种主要表连接的比较
| 类别 |
嵌套循环连接 |
排序合并连接 |
哈希连接 |
| 优化器提示 |
USE_NL |
USE_MERGE |
USE_HASH |
| 使用的条件 |
任何连接 |
主要用于不等价连接,如<、 <=、 >、 >=; 但是不包括 <> |
仅用于等价连接 |
| 相关资源 |
CPU、磁盘I/O |
内存、临时空间 |
内存、临时空间 |
| 特点 |
当有高选择性索引或进行限制性搜索时效率比较高,能够快速返回第一次的搜索结果。 |
当缺乏索引或者索引条件模糊时,排序合并连接比嵌套循环有效。 |
当缺乏索引或者索引条件模糊时,哈希连接连接比嵌套循环有效。通常比排序合并连接快。 在数据仓库环境下,如果表的纪录数多,效率高。 |
| 缺点 |
当索引丢失或者查询条件限制不够时,效率很低; 当表的纪录数多时,效率低。 |
所有的表都需要排序。它为最优化的吞吐量而设计,并且在结果没有全部找到前不返回数据。 |
为建立哈希表,需要大量内存。第一次的结果返回较慢。 |