开源框架面试题
1.01在Java阵形里,为什么有这么多的框架?框架的作用是什么?
1)使组件耦合程度更低,组件依赖可配置
2)提供一些通用的服务
比如:事务、安全 i18n(Internationalization)
表单重复提交 文件上传下载
3)简化java EE的编程
1.02 Statement,PreparedStatement,CallableStatement区别
1.PreparedStatement是预编译的,并支持批处理,对于批量处理可以大大提高效率. 也叫JDBC存储过程;可以传参数,在得到PreparedStatement对象时确定sql.
2.使用 Statement 对象。在对数据库只执行一次性存取的时侯,用 Statement 对象进行处理。
statement用于执行静态 SQL 语句并返回它所生成结果的对象,在执行时确定sql。
3.CallableStatement用于执行 SQL 存储过程的接口。如果有输出参数要注册说明是输出参数。
1.03 JDBC与Hibernate区别
(1)、hibernate是封装了jdbc的一个面向关系映射(ORM)的数据库连接方式;而JDBC是一个关系型数据库连接方式;
(2)、JDBC与hibernate连接数据库的方式大致相同,但hibernate将配置信息写在XML中;
(3)、hibernate用HQL查询,结果返回的是List<Object>,而JDBC用SQL查询,结果返回的是ResultSet,要通过bean方式封装到对象中;
(4)、hibernate的 HQL语句有专门的Dao层,而JDBC没有,这样当数据库修改时,hibernate只需要修改Dao层即可,而JDBC修改的代码量就多很多;
(5)、当处理同样的SQL语句时,hibernate不会重复处理,而JDBC每一次都要进行处理,这样hibernate的效率就远远高于JDBC;
(6)、JDBC在性能上,灵活性比hibernate要好,当对多表或者复杂的数据库进行操作时,用JDBC好;
(7)、“精心编写”的JDBC一定是性能最好的。再级联关系较多的时候,用hibernate应该比jdbc强,
(8)、用hibernate大大减少了代码量的编写;
1.04 Struts+Spring+Hibernate开发框架中各取什么作用 ?
1.struts是控制页面跳转;struts是控制层和视图层,负责JSP页面的展示和交互。
2.hibernate负责和数据库的连接与操作;hibernate 是持久化层,负责数据的存储和检索。
3.Spring 减 少耦合,功能完成的层次分的很清楚;Spring是业务逻辑层,负责具体业务逻辑的实现,核心是IOC 和面向AOP 编程,spring与struts和hibernate整合后,作为一个IoC容器,因此可以对struts和hibernate实施监控;可以做安全, 日志等一系列AOP的工作。
1.05 Struts2工作机理
1 客户端初始化一个指向Servlet容器(例如Tomcat)的请求
2 这 个请求经过一系列的过滤器(Filter),FilterDispatcher被调用,FilterDispatcher询问ActionMapper来 决定这个请是否需要调用某个Action,ActionServlet类是关键的控制器部件,所有的Action都继承自 org.apache.struts.ation.Action类;
3 如果ActionMapper决定需要调用某个Action,FilterDispatcher把请求的处理交给Action执行,执行完毕, struts.xml中的配置找到对应的返回结果。
1.06 Struts1与Struts2差别?
1) 在 Action实现类方面的对比:Struts 1要求Action类继承一个抽象基类; Struts 2 Action类可以实现一个Action接口,也可以实现其他接口,使可选和定制的服务成为可能。Struts 2提供一个ActionSupport基类去实现常用的接口。即使Action接口不是必须实现的,只有一个包含execute方法的POJO类都可以用 作Struts 2的Action。
2) 线程模式方面的对比:Struts 1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts 1 Action能做的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的;Struts 2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。
3) Servlet依赖方面的对比:Struts 1 Action依赖于Servlet API,因为Struts 1 Action的execute方法中有HttpServletRequest和HttpServletResponse方法。Struts 2 Action不再依赖于Servlet API,从而允许Action脱离Web容器运行,从而降低了测试Action的难度。 当然,如果Action需要直接访问HttpServletRequest和HttpServletResponse参数,Struts 2 Action仍然可以访问它们。大部分时候Action都无需直接访问HttpServetRequest和HttpServletResponse,从 而给开发者更多灵活的选择。
4) 封装请求参数的对比:Struts 1使用ActionForm对象封装用户的请求参数,所有的ActionForm必须继承一个基类:ActionForm。普通的JavaBean不能用 作ActionForm,因此,开发者必须创建大量的ActionForm类封装用户请求参数。虽然Struts 1提供了动态ActionForm来简化ActionForm的开发,但依然需要在配置文件中定义ActionForm;Struts 2直接使用Action属性来封装用户请求属性,避免了开发者需要大量开发ActionForm类的烦琐, Struts 2提供了Model Driven模式,可以让开发者使用单独的Model对象来封装用户请求参数,但该Model对象无需继承任何Struts 2基类,是一个POJO,从而降低了代码污染。
5) 表达式语言方面的对比:Struts 1整合了JSTL,因此可以使用JSTL表达式语言。这种表达式语言有基本对象图遍历,但在对集合和索引属性的支持上则功能不强;Struts 2可以使用JSTL,但它整合了一种更强大和灵活的表达式语言:OGNL,因此Struts 2下的表达式语言功能更加强大。
6) 类型转换的对比:Struts 1 ActionForm 属性通常都是String类型。Struts 1使用Commons-Beanutils进行类型转换,每个类一个转换器,转换器是不可配置的;Struts 2使用OGNL进行类型转换,支持基本数据类型和常用对象之间的转换。
7) Action执行控制的对比:Struts 1支持每一个模块对应一个请求处理,但是模块中的所有Action必须共享相同的生命周期。Struts 2支持通过拦截器堆栈(Interceptor Stacks)为每一个Action创建不同的生命周期。开发者可以根据需要创建相应堆栈,从而和不同的Action一起使用。
1.07 Struts 2 Action对象为每一个请求都实例化对象,这样会不会影响程序运行速度?
创建action对象资源浪费不是特别大,只要在设计的时候注意不要把一些比较重的资源放到全局变量和构造方法里面就好了。另外容器里有很好的垃圾回收机制,只要有一个action实例不用,就会马上回收处理。所以服务器是完全抗的住的。
1.08 Hibernate3与 MyBatis3.1的比较
两者相同点
Hibernate与 MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由 SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。其中 SessionFactoryBuider,SessionFactory,Session的生命周期都是差不多的。
Hibernate和MyBatis都支持JDBC和JTA事务处理。
Mybatis优势
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
MyBatis容易掌握,而Hibernate门槛较高。
Hibernate优势
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
Hibernate有更好的二级缓存机制。Hibernate缓存分为:
一级缓存:session共享(save、update、saveOrupdate、load、get、list) 用于处理当前的单元操作.
二级缓存:sessionFactory共享.(经常读很少被修改,如果使用二级缓存可以提高性能.)
MyBatis本 身提供的缓存机制不佳。MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地配置和定制。默认情况下是没有开启缓存的,除了局部 的 session 缓存,可以增强变现而且处理循环 依赖也是必须的。要开启二级缓存,你需要在你的 SQL 映射文件中添加一行: <cache/>
hibernate中session打开和关闭由sessionFactory的getSession()来管理session的打开和关闭。
第三方缓存实现:cache、Map等;
1.09 Spring实例化bean的三个方式是甚么?
(1)无参构造方法:<bean id=”” class=””></bean>
(2)有参构造方法:
<bean id=”” class=”” init-method=”init”>
<property name=”” value=””/>
</bean>
(3)工厂方法
Calendar.getInstance();
<bean id=”cal” class=”java.util.Calendar”
factory-method=”getInstance”/>
1.10 Spring的IOC的作用是甚么?
IoC意味着将你设计好的类交给系统去控制,而不是在你的类内部控制。
1.11 Spring的AOP是如何实现的?
1.代理的两种方式:
静态代理:
◆针对每个具体类分别编写代理类;
◆针对一个接口编写一个代理类;
动态代理:
针对一个方面编写一个InvocationHandler,然后借用JDK反射包中的Proxy类为各种接口动态生成相应的代理类
2.AOP的主要原理:动态代理
AOP 让开发人员可以创建非行为性的关注点,称为横切关注点,并将它们插入到应用程序代码中。使用 AOP 后,公共服务(比如日志、持久性、事务等)就可以分解成方面并应用到域对象上,同时不会增加域对象的对象模型的复杂性。
1.12 SSH与MVC对应
mvc是一种设计模式,ssh是一种框架组合,若非要拉上关系,Web层又分成MVC,Struts 属于Web层; hibernate是实现持久层的。spring是整合struts和hibernate的,以及声明事务等等用的。
1.13 spring的事务管理有几种方式实现,如何实现
Spring+Hibernate的实质:
就是把Hibernate用到的数据源Datasource,Hibernate的SessionFactory实例,事务管理器HibernateTransactionManager,都交给Spring管理。
实现方式共有两种:编码方式;声明式事务管理方式。
基于AOP技术实现的声明式事务管理,实质就是:在方法执行前后进行拦截,然后在目标方法开始之前创建并加入事务,执行完目标方法后根据执行情况提交或回滚事务。
1.14 Spring MVC和Struts2的区别
1. 机制:spring mvc的入口是servlet,而struts2是filter,这样就导致了二者的机制不同。
2. 性能:spring会稍微比struts快。spring mvc是基于方法的设计,而sturts是基于类,每次发一次请求都会实例一个action,每个action都会被注入属性,而spring基于方法, 粒度更细,但要小心把握像在servlet控制数据一样。
3. 设计思想上:struts更加符合oop的编程思想, spring就比较谨慎,在servlet上扩展。
4. intercepter(拦截器)的实现机制:struts有以自己的interceptor机制,spring mvc用的是独立的AOP方式。这样导致struts的配置文件量还是比spring mvc大
5.spring3 mvc的验证也是一个亮点,支持JSR303,处理ajax的请求更是方便,只需一个注解@ResponseBody ,然后直接返回响应文本即可。
1.15用hibernate处理批量表记录为什么特别慢?加快方法
因为二级缓存维护的问题,hibernate查询数据后要进行持久化对象;比如查询每一行都进行ORMapping,速度是会比较慢的;
加快方法:使用延迟加载:lazy=true;或者创建索引加快查询速度;或者减少查询字段;
解决方法:如果底层数据库(如Oracle)支持存储过程,也可以通过存储过程来执行批量更新。存储过程直接在数据库中运行,速度更加快。
1.16 hibernate的自增长配置在哪儿?
hibernate.cfg.xml文件主要配置session-factory的数据源配置,而自增长配置在hbm.xml文件里面的每个表中id部分里面的generate上;
1.17 Hibernate工作原理及为什么要用?
工作原理
前提:在hibernate.cfg.xml文件中配置数据库连接;其次写domain.hbm.xml配置文件;
(1)、启动服务器,读取配置信息,创建sessionFactory;
(2)、Configuration conf = new Configuration().configure("hibernate.cfg.xml"); //实例化configuration对象;
(3)、SessionFactory sessionFactory = conf.buildSessionFactory(); //创建一个SessionFactory对象;
(4)、Session session = sessionFactory.openSession(); //创建session对象,打开一个Session;
(5)、Transaction tx = session.beginTransaction().begin(); //开启事务;
(6)、添加要对数据库进行操作信息;
(7)、session.save(user);//保存信息;
(8)、tx.commit();//提交;
为什么要用
1.对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2.Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
3.hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4.hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
1.18 Hibernate是如何延迟加载?
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
1.19 hibernate5种核心技术?
答:session/sessionFactory/configuration/transcation/query
1.20 hibernate查询方案?
HQL、SQL、Criteria;
1.21 Hibernate继承映射三种方式?
第一种方式:Hibernate继承关系树的每个具体类对应一个表:关系数据模型完全不支持域模型中的继承关系和多态。
第二种方式:Hibernate继承关系树的根类对应一个表:对关系数据模型进行非常规设计,在数据库表中加入额外的区分子类型的字段。通过这种方式,可以使关系数据模型支持继承关系和多态。
第三种方式:Hibernate继承关系树的每个类对应一个表:在关系数据模型中用外键参照关系来表示继承关系。
1.22 hibernate主要解决了什么问题?
答:主要解决数据持久化的问题
1.23 Hibernate 的缓存体系
一级缓存:
Session 有一个内置的缓存,其中存放了被当前工作单元加载的对象。
每个Session 都有自己独立的缓存,且只能被当前工作单元访问。
二级缓存:
SessionFactory的外置的可插拔的缓存插件。其中的数据可被多个Session共享访问。
SessionFactory的内置缓存:存放了映射元数据,预定义的Sql语句。
1.24 Hibernate 中Java对象的状态
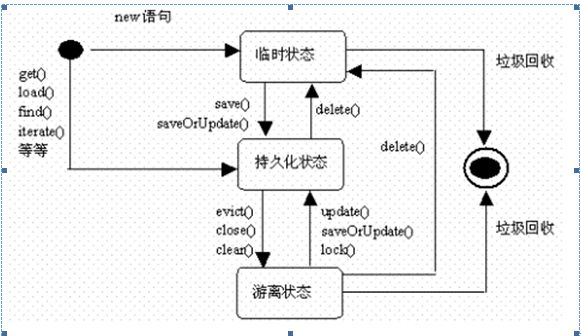
(1).临时状态 (transient)又叫暂态:刚用new创建,没被持久化,没在session缓存中;
特征:
1】不处于Session 缓存中
2】数据库中没有对象记录
Java如何进入临时状态
1】通过new语句刚创建一个对象时
2】当调用Session 的delete()方法,持久化状态à临时
(2).持久化状态(persisted):被持久化,加入到session缓存中;
特征:
1】处于Session 缓存中
2】持久化对象数据库中没有对象记录
3】Session 在特定时刻会保持二者同步
Java如何进入持久化状态
1】Session 的save() 临时à持久化状态
2】Session 的load(),get()方法返回的对象 临时à持久化状态
3】Session 的find()返回的list集合中存放的对象 临时à持久化状态
4】Session 的update(),saveOrUpdate() 游离à持久化
(3).游离状态(detached):被持久化,没在session缓存中;
特征:
1】不再位于Session 缓存中
2】游离对象由持久化状态转变而来,数据库中可能还有对应记录。
Java如何进入 持久化状态à游离状态
1】Session 的close()方法
2】Session 的evict()方法,从缓存中删除一个对象。提高性能。少用。
1.25 Hibernate中的单向关系和双向关系映射的区别,什么时候使用单向,什么时候使用双向?
一对多关系分为单向一对多关系和双向一对多关系。
单向一对多关系只能通过主控方对被动方进行级联更新。
双向一对多关系实际上是“一对多”与“多对一”关联的组合,也就是说我们必须在主控方配置单向一对多关系的基础上,在被控方配置与其对应的多对一关系。
双向一对多的关系除了避免约束违例和提高性能的好处之外,还带来另外一个优点,由于建立了双向关联,我们可以在关联双方中任意一方,访问关联的另一方。
1.26 O/R Mapping是什么?在J2EE中的具体应用?
答:ORM是面向对象关系映射的意思;
应用:主要是开发人员就可以把对数据库的操作转化为对这些对象的操作;
1.27 hibernate的锁:
(1)、悲观锁:在整个数据处理过程中,数据处于锁定状态,外界无法修改;
实现:query.setLockMode( " user " ,LockMode.UPGRADE); // 加锁
(2)、乐观锁:更改数据库表后,将为数据表增加一个版本标识;大大提高并发效率;
实现:为TUser的class描述符添加optimistic-lock属性:
< hibernate - mapping >
< class
name = " org.hibernate.sample.TUser "
table = " t_user "
dynamic - update = " true "
dynamic - insert = " true "
optimistic - lock = " version "
>
……
</ class >
</ hibernate - mapping >
1.28 Hibernate的配置文件中lazy, inverse, cascade和fetch
答:lazy,就是延时加载。
以最简单的parent和child为例子:一个parent可以有多个child,一个child只有一个parent。
当parent类的child属性的lazy为true,那么当select parent的时候,他的child不会马上被select,一直延迟到他的child需要被读写的时候再去select。
当parent类的child属性的lazy为false,那么select parent的时候,他的child会马上被select。
inverse,用于外键维护的控制。
当inverse为false,则在插入表数据之后,会再插入外键维护的记录。
当inverse为true,则在插入表数据的同时,插入外键维护的记录。
在非多对多的表关系中:
还是以parent和child为例子。假设1个parent有3个child,那么:
当inverse为false,则先insert 1 条 parent,再insert 3 条 child,再insert 3 个child的parent ID,一共7次insert。
当inverse为true,则先insert 1 条 parent,再insert 3 条 child,当然这3次insert是同时完成插入parent ID的,所以一共4次insert。
总结:在非多对多的表关系中,inverse永远为ture。
在多对多的表关系中:
中间表的外键维护通常由一方进行维护。
所以2个多方,1个inverse为ture,1个inverse为false。中间表会由inverse为false的一方维护。
总结:选择数据比较多的一方维护中间表的效率会比较高。
cascade,表的级联。
如果你熟悉数据库,表级联可以设置在数据库上。
如果你选择设置在配置文件中,则相应的你的系统会更方便的在各个数据库之间进行移植。
级联具体情况就看业务需求了。关于级联,不明白的可查阅数据库基础理论。没什么好多说的。
fetch,就是加载子表信息所采用的方式,select或者join
以下是我个人对这个属性的理解:
xml配置文件中可以不配置,采用默认的。而他真正的作用在于:
1). 通常情况为了保证效率,lazy的配置都是true的。比如有个页面需要显示parent列表,只需要parent的name属性和create time属性,因为不涉及子表信息,lazy为false的配置将大大影响效率。这样,我们就拥有了hibernate的高性能。
2). 特殊情况下,我们又希望lazy为false,即当编辑某一个parent的时候,立刻获得parent的子表,乃至子表的信息(例如当我们采用分层结构 时,当信息到视图层时,hibernate的session已经断开了,所以要在逻辑层完成所有信息的载入)。我们就可以在HQL中写 left/right outer/inner join fetch实现此功能。这样,我们又获得了临时的灵活性。
1.29 缓存的作用:
(1).减少访问数据库的频率。
(2).保证缓存中的对象与数据库中的相关记录保持同步。
(3).保证不出现访问对象图的死循环,以及由死循环引起的JVM堆栈溢出异常。清理缓存时,会顺序执行一些SQL语句。
1.30 Java框架Struts2的拦截器和过滤器有什么区别?
拦截器与过滤器的区别:
拦截器是基于java的反射机制的,而过滤器是基于函数回调。
拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次
执行顺序:过滤前 - 拦截前 - Action处理 - 拦截后 -
过滤后。个人认为过滤是一个横向的过程,首先把客户端提交的内容进行过滤(例如未登录用户不能访问内部页面的处理);过滤通过后,拦截器将检查用户提交数据的验证,做一些前期的数据处理,接着把处理后的数据发给对应的Action;