pyparsing语法解析心得
开发起始,花了一定的时间调研寻找一个好的语法解析器,因为在表格安全性检查过程中需要解析各种形式灵活的检查规则,所以需要一个类似lex/yacc这样具有强大语言解析功能,但语法规则又可以轻量级配置的解析器,最后选择了一种近似上下文无关CFG(context-free-grammar)的语言PEG(parsing-expression-grammar),作为我们编写检查规则的基础文法。
- PEG文法
V = {a, b},
有限递归级联合并规则就是
S <-- ab
S <-- aSb
这两条规则产生的语言S 就等于{a nb n, n >= 1}。而语言{a nb n c n, n >= 1}虽然也具备有限的确定元素集合,但不能由递归级联合并规则所产生,所以其不属于上下文无关语言。
然而上下文无关文法(CFG)却因为其规则的灵活性和语法解析的多样性,在工程运用上存在着障碍。CFG文法属于一种可以自顶向下解析的语言,如果一个字符串属于一种CFG语言,那么可以将这个字符串自顶向下逆向推导出构建的过程,产生一个语法解析树,而对于大多数CFG语言来说,其合法字符串可以被解析成多个不同结构的语法树,譬如如下的CFG语言(例子2)S <-- a
S <-- S+S
解析字符串a+a+a就会得到两种不同的语法解析树,如下所示:
S/ | \
/ | \
/ | \
S + S
| / | \
| / | \
a S + S
| |
a a
S
/ | \
/ | \
/ | \
S + S
/ | \ |
/ | \ |
S + S a
| |
a a
正是为了消除 CFG 语言在语义上的歧义性,工程中引入了 PEG 这种也可以自顶向下解析的语言。 PEG 在尽量保持 CFG 语言解析能力的同时,还可以保证语法解析树的唯一性,计算理论对 PEG 与 CFG 之间的差异进行了详细的阐述。就个人理解而言, PEG 的本质就是对 CFG 语言的级联 规则做了相应的限制,使 PEG 在解析语言的时候有了一定的顺序性 (ordering) ,从而保证了语法解析树的唯一性。
相比灵活的 CFG 语法级联规则, PEG 只支持以下的几种级联操作:
• Sequence: e 1 e 2
• Ordered choice: e 1 | e 2
• Zero-or-more: e*
• One-or-more: e+
• Optional: e?
对于上面提到的 CFG 语法(例子 2 ),只需将对应的规则进行稍稍的修改就可以转化成 PEG 文法(例子 3 ):
S1 <-- a
S2 <-- S3
S3 <-- (S1 | S2 ) + ZeroOrMore( ‘ + ’ + (S1 | S2))
对于 a+a+a,就只能解析成为如下语法解析树:
S3
/ \
/ \
S1 ZeroOrMore(+ (S2 | S1)
| / \
| / \
a + S2
|
|
S3
/ \
/ \
S1 ZeroOrMore(+ (S2 | S1)
| / \
| / \
a + S1
|
|
a
由于PEG语言本身对级联规则的限制性,消除了语法解析过程中的歧义性,而且理论上可以保证绝大多数CFG语言,只要稍加修改相应的语法规则都可以转换成相应的PEG语言(对于存在左递归的CFG语言无法用PEG语法来解析),并且可以保证解析过程的唯一性,这样就为工程的应用提供了便利性。
- pyparsing 分析
现在已经有很多用不同程序语言开发的开源库来支持解析peg语言,由于项目本身的原因,我们选择使用了python实现的开源库pyparsing(1.5.6)。pyparsing的架构主要有两大部分组成,分别为用来表示解析结果的ParseResults和表示解析规则和解析算法的ParserElement,前者表示语法解析过程中所操作的数据结构,后者表示具体的语法解析流程。
1. 数据结构
ParseResults是算法所操作的基本数据结构,用来表示解析字符串后所得到语法解析树。单个Parseresults的数据结构用来表示一棵树的某个节点,内部还可以包含相应子节点ParseResults结构。一个节点ParseResults的子节点序列用一个list来表示,可以通过访问序号来获取;同时为了快速的定位子树中一些有用的子节点,还可以将ParseResults按照dict来操作,通过字符串key快速定位。对于以某个ParseResults节点(PS)为根的解析树,所有该层子节点可以通过链表的形式得到,如PS[0],PS[1],…;对于在语法表达式中用setResultsName(‘xxx’)定义的token,都可以用字典以key为索引的方式得到,如PS[‘xxx’]
ParseResults结构如下所示:
class ParseResults: member: __toklist member: __tokdict member: __accumNames member: __parent
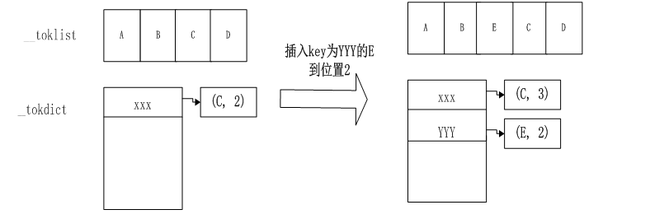
其中__toklist主要维护了子节点的链表结构,__tokdict维护了字典结构,__accumNames保存了__tokdict中非modal形式(多个相同key的value只取当前最后一个)的key值集合,__parent指向了父节点。其中__toklist中的元素可以是string或者作为子节点ParseResults结构;__tokdict的key为string,value是ParseResultsWithOffset的数据结构,ParseResultsWithOffset是一个包含有两个元素的pair tuple,tuple[0]为__toklist中的元素,tuple[1]为该元素在__toklist中的index,这样该元素即可以通过PS[index]来提取,也可以通过PS[key]来提取。下图表示在一个ParseResults中在index为2的位置插入key为’YYY’的节点E:
ParseResults主要通过重载python中的__getitem__,__setitem_,__delitem__,__iadd__这三个方法来统一实现了list和dict相应操作。
# 重载[]操作
def __getitem__( self, i ):
if isinstance( i, (int,slice) ):
# 如果i是整数或者slice,则当作链表操作
return self._toklist[i]
else:
# 如果传入的i是str类型的key,则当作字典操作
if i not in self._accumNames:
# 当parseresult在创建时,参数modal为True时,则返回values中的最后一个
return self._tokdict[i][-1][0]
else:
#非modal形式,则将所有values按照一个list返回
return ParseResults([ v[0] for v in self._tokdict[i] ])
# 重载[]操作
def __setitem__( self, k, v, isinstance=isinstance ):
if isinstance(v,_ParseResultsWithOffset):
#字典操作非modal模式下,放在所有values的末尾
self._tokdict[k] = self._tokdict.get(k,list()) + [v]
sub = v[0]
elif isinstance(k,int):
# 如果key为int就表明链表操作,直接取代原来的value
self._toklist[k] = v
sub = v
else:
# 组装ParseResultsWithOffset作为value
self._tokdict[k] = self._tokdict.get(k,list()) + [_ParseResultsWithOffset(v,0)]
sub = v
if isinstance(sub,ParseResults):
# 申明父节点
sub._parent = wkref(self)
# 重载+=操作,其中 + 操作也是由+=来实现
def __iadd__( self, other ):
if other._tokdict:
# 合并dict的操作
offset = len(self._toklist)
addoffset = ( lambda a: (a<0 and offset) or (a+offset) )
otheritems = other._tokdict.items()
otherdictitems = [(k, _ParseResultsWithOffset(v[0],addoffset(v[1])) )
for (k,vlist) in otheritems for v in vlist]
for k,v in otherdictitems:
self[k] = v
if isinstance(v[0],ParseResults):
v[0]._parent = wkref(self)
# 合并list的操作
self._toklist += other._toklist
# 更新key的集合
self._accumNames.update( other._accumNames )
return self
def __delitem__( self, i )在当前版本中的实现是错误的,当以dict的方式进行删除时,即传入的i不为int的情况,只简单地删除dict中的值,而没有更新列表中剩余的elements的序号,即index值,好在peg的解析过程并不涉及dict删除情况。
为了更好的阐述ParseResults数据结构,对上面的语法(例子3)稍作改变,添加了对括号对称检查的语法解析(例子4):
S1 <-- Literal('a')
S2 <-- Literal('(') + S3 + Literal(')')
S3 <-- (S2 | S1 ) + ZeroOrMore(Group(Literal('+') + (S2 | S1)).setResultsName(‘right token'))
则字符串(a + a) + a解析的结果为
__tokdict : {'right token': [((['+', 'a'], {}), 2), ((['+', 'a'], {}), 4)]}
__toklist : ['(', 'a', ['+', 'a'], ')', ['+', 'a']]
图示如下: 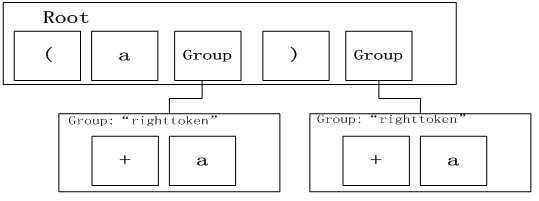
2. 算法流程:
ParserElement是解析peg语法的基本组成元素,由有限确定集合(token)和相应的限制级联规则如 Zero-or-more,One-or-more,Forward等所组成,可以将这类级联规则看成例子4里面的语法规则。ParserElement的大致架构图如下:
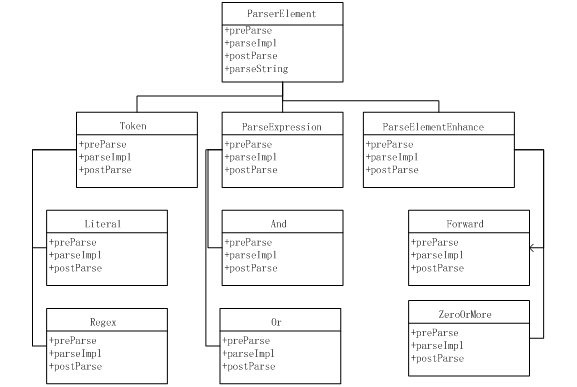
图中Token表示有限确定集合和简单的级联规则如Sequence等, ParseExpression表示单元或者双元级联规则如And和Or,ParseElementEnhance表示具有递归性的级联规则如Forward,正是由于ParseElementEnhance这类语法的引入,才增强了PEG的解析能力,将其与正则表达式的解析区分开来。
ParserElement的每个继承类型都实现了相应的匹配规则,匹配规则的实现都是由函数parseImpl来定义的:
def parseImpl( self, instring, loc, doActions=True )
其中instring表示需要匹配的字符串,loc表示开始匹配的字符串位置,doActions表示在匹配成功之后执行操作函数,一般有用户提供,并且这些操作的定义将直接影响到后续语法解析过程能否进行优化,这将在后面说明。函数将返回匹配终止时指针所在的index和表示相应匹配结果的ParseResults。
Token中的各个匹配规则相对比较简单,包括简单的字符串匹配(Literal,Keyword),正则表达式匹配(Reg)等,以Keyword为例,算法只要求两个字符串相同:
def parseImpl( self, instring, loc, doActions=True ):
if self.caseless:
# 如果忽略大小写
if ( (instring[ loc:loc+self.matchLen ].upper() == self.caselessmatch) and
(loc >= len(instring)-self.matchLen or instring[loc+self.matchLen].upper() not in self.identChars) and
(loc == 0 or instring[loc-1].upper() not in self.identChars) ):
return loc+self.matchLen, self.match
else:
if (instring[loc] == self.firstMatchChar and
# 真正的匹配过程,第一个字符相等(优化),字符串匹配startswith
(self.matchLen==1 or instring.startswith(self.match,loc)) and
(loc >= len(instring)-self.matchLen or instring[loc+self.matchLen] not in self.identChars) and
(loc == 0 or instring[loc-1] not in self.identChars) ):
return loc+self.matchLen, self.match
#~ raise ParseException( instring, loc, self.errmsg )
# 匹配失败的情况
exc = self.myException
exc.loc = loc
exc.pstr = instring
raise exc
增强型级联规则的引入特别是Forward等递归类型的引入,增强了peg语言的解析能力,我们都知道CFG的语言表达性要强于正则表达式,是因为CFG中引入了一种递归级联的能力,而Forward正是为PEG注入了这种递归能力,我们就以Forward为例来看一下递归匹配规则:
def parseImpl( self, instring, loc, doActions=True ):
if self.expr is not None:
# 递归调用包含规则
return self.expr._parse( instring, loc, doActions, callPreParse=False )
else:
raise ParseException("",loc,self.errmsg,self)
Forward的parseImpl继承于ParseElementEnhance,只是递归地调用了子表达式expr的匹配规则,但其真正的亮点是它重载了python中的<<操作符
def __lshift__( self, other ):
if isinstance( other, basestring ):
other = Literal(other)
# 通过这个赋值,实现了递归语法定义,可以在other中包含自己的表达式,但不能出现左递归,否则程序将陷入死循环,这也是peg语言唯一的限制条件
self.expr = other
…
return None
分析了ParserElement的组成元素和相应的匹配规则,下面来讲讲PEG的解析算法。PEG的解析算法是一个简单递归深度优先解析过程,递归穷举所有匹配过程,如果匹配就继续深入解析,如果穷举完所有可能匹配规则后失败,则回溯深度尝试其他匹配可能。
匹配算法入口是:def parseString( self, instring, parseAll=False ): # 重置匹配cache,为parse rat所有 ParserElement.resetCache() if not self.streamlined: self.streamline() #~ self.saveAsList = True for e in self.ignoreExprs: e.streamline() if not self.keepTabs: instring = instring.expandtabs() try: # 递归调用各个子ParserElement相应的匹配规则 loc, tokens = self._parse( instring, 0 ) if parseAll: # 要整个字符串完全匹配的情况 se = Empty() + StringEnd() se._parse( instring, loc ) except ParseBaseException: if ParserElement.verbose_stacktrace: raise else: # catch and re-raise exception from here, clears out pyparsing internal stack trace exc = sys.exc_info()[1] raise exc else: return tokens
其中_parse函数就是我们刚才分析的各个组成元素的parseImpl函数。如果这个element是ParseElementEnhance,则会在相应的parseImpl函数中递归调用各个子规则的parseImpl函数。
由于深度优先解析算法通过向前(look ahead)和回溯(look backward)尝试所有匹配可能,所以在最差的情况下会呈指数级时间复杂度。工程上为了优化解析的效率,引入了packrat parser算法,其本质是缓存所有的中间解析结果,节省了重复解析的时间,在最好的情况下可以达到线性的时间复杂度。在pyparsing中可以通过设置标志位
_packratEnabled = True
来激活packrat parser算法,这样各个ParserElement的parseImpl匹配规则被封装,如下所示:
# this method gets repeatedly called during backtracking with the same arguments -
# we can cache these arguments and save ourselves the trouble of re-parsing the contained expression
def _parseCache( self, instring, loc, doActions=True, callPreParse=True ):
lookup = (self,instring,loc,callPreParse,doActions)
if lookup in ParserElement._exprArgCache:
# 尝试着从cache中找匹配结果
value = ParserElement._exprArgCache[ lookup ]
if isinstance(value, Exception):
raise value
return (value[0],value[1].copy())
else:
try:
#在没有找到的情况下,才真正做解析流程
value = self._parseNoCache( instring, loc, doActions, callPreParse )
ParserElement._exprArgCache[ lookup ] = (value[0],value[1].copy())
return value
except ParseBaseException:
pe = sys.exc_info()[1]
ParserElement._exprArgCache[ lookup ] = pe
Raise
packrat parser算法虽然提高了解析算法的效率,但也对解析算法做了一定的限制,其要求在解析过程中所有匹配成功后用户所定义的动作函数(通过
setParseAction来定义)不能修改原始的字符串,否则
cache将会出错。同时
packrat parser算法是一个空间换时间的算法,过程中
cache将消耗很多内存,为此
pyparsing也做了一定的优化,对于每一个
ParseResults都重载了
__new__函数
,限制产生ParseResults实体的个数,代码如下:
def __new__(cls, toklist, name=None, asList=True, modal=True ): if isinstance(toklist, cls): # 空间优化,如果是解析的中间结果,将不产生新的parserresults,只是重用和修改原有的instance return toklist retobj = object.__new__(cls) retobj.__doinit = True return retobjpyparsing大概就分析到这里,其实之后还有很多的工作花在如何用好PEG这个语言,发挥其强大的解析功能用于导表的安全性检查中,当然这就是另外一个话题了。