cdh3u3 hadoop 0.20.2 MultipleOutputs 多输出文件初探
一般来说Map/Reduce都是输出一组文件,但是有些情况下需要我们输出多组文件,好比不同学校分成不同组,有些时候数据不整齐,还要把不符合格式要求的数据单独输出。划分多个输出文件主要有2个类实现,MultipleOutputFormat和MultipleOutputs。权威指南和实战的都给了例子,可是JobConf过时了是个头疼的事,有个大侠很勇敢的自己写了,http://www.cnblogs.com/flying5/archive/2011/05/04/2078407.html 我没那个水平就翻了翻API,发现hadoop 官方API上MultipleOutputs是属于org.apache.hadoop.mapred.lib 但是我用的cdh3u3的API中有2个,一个是这个包中的还有一个在org.apache.hadoop.mapreduce.lib.output 而这个包下的类有一个write方法,尝试了一下发现可以用。
1.新建一个multest.txt文件
11111,username,password,22,河北师范大学,软件学院,2008 11112,username,password,22,河北师范大学,计算机学院,2008 11113,username,password,22,xx大学,软件学院,2008 11114,username,password,22,xxx大学,计算机学院,2008 11115,username,password,23,2008
2.在hdfs上新建一个目录,hadoop dfs -mkdir multest
3.将新建到文本文件上传到multest目录下:hadoop dfs -put /home/wjk/hadoop/multest.txt multest
4.新建Map/Reduce工程,将格式不符合(7位)到保存到dirtydata中,将河北师范大学软件学院以外到数据保存到otherschool中,将河北师范大学软件学院到数据保存到默认文件中。
public class Multest {
public static class MultestMapper extends
Mapper<Object, Text, Text, NullWritable> {
private Text outkey = new Text("");
private MultipleOutputs<Text, NullWritable> mos;
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String details[] = line.split(",");
if (details.length != 7) {
outkey.set(line);
mos.write("dirtydata", outkey, NullWritable.get());
} else {
String school = details[4];
String college = details[5];
if (school.equals("河北师范大学") && college.equals("软件学院")) {
outkey.set(line);
context.write(outkey, NullWritable.get());
} else {
outkey.set(line);
mos.write("otherschool", outkey, NullWritable.get());
}
}
}
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
mos = new MultipleOutputs<Text, NullWritable>(context);
super.setup(context);
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
mos.close();
super.cleanup(context);
}
}
public static class MultestReducer extends
Reducer<Text, NullWritable, Text, NullWritable> {
protected void reduce(Text key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "multest");
job.setJarByClass(Multest.class);
job.setMapperClass(MultestMapper.class);
job.setReducerClass(MultestReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
MultipleOutputs.addNamedOutput(job, "dirtydata",
TextOutputFormat.class, Text.class, NullWritable.class);
MultipleOutputs.addNamedOutput(job, "otherschool",
TextOutputFormat.class, Text.class, NullWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
5.编译,导出jar,运行:hadoop jar ./../multest.jar com.wjk.test.Multest multest multestout
6.运行截图
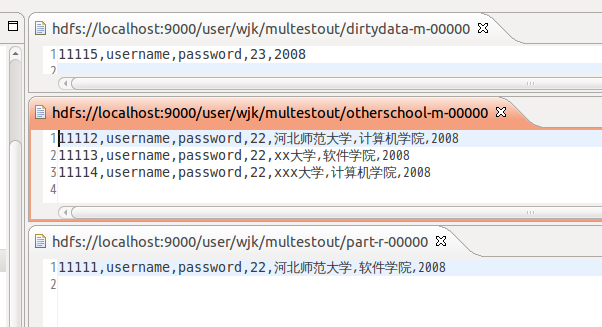
=======注意==========================
缺陷:集群上运行会有多个分散的文件
2014-08-21补充:按上述的写法产生的文件很多,合并很难,可以执行输出目录,合并的话按目录getmerge就容易了。主要修改点在mos.write上,参考官方代码,很简单,自行领悟吧。
public <K, V> void write(String namedOutput, K key, V value) throws IOException, InterruptedException {
write(namedOutput, key, value, namedOutput);
}
public <K, V> void write(String namedOutput, K key, V value,String baseOutputPath) throws IOException, InterruptedException {
checkNamedOutputName(this.context, namedOutput, false);
checkBaseOutputPath(baseOutputPath);
if (!(this.namedOutputs.contains(namedOutput))) {
throw new IllegalArgumentException("Undefined named output '" + namedOutput + "'");
}
TaskAttemptContext taskContext = getContext(namedOutput);
getRecordWriter(taskContext, baseOutputPath).write(key, value);
}