Python标准库学习笔记7:数据持久存储与交换
0. 概述
要持久存储数据以供长期使用,这包括两个方面:在对象的内存中表示和存储格式之间来回转换数据,以及处理转换后数据的存储区。
1. pickle----对象串行化
作用:对象串行化
pickle模块实现了一个算法可以将一个任意的Python对象转换为一系列字节。这个过程也称为串行化对象。表示对象的字节流可以传输或存储,然后重新构造来创建相同性质的新对象。
cPickle用C实现的同样算法,比pickle快数倍。
1. 导入
由于cPickle快于pickle,所以通常存在cPickle,就导入它并改其别名为“pickle”,否则导入pickle.
try: import cPickle as pickle except: import pickle
2. 编码和解码字符串数据
使用dumps()将一个数据结构编码为一个字符串,然后把这个字符串打印到控制台。它使用了一个完全由内置类型构成的数据结构。任何类的实例都可以pickle:
try:
import cPickle as pickle
except:
import pickle
import pprint
data = [{'a' : 'A', 'b' : 2, 'c' : 3.0}]
print 'DATA:'
pprint.pprint(data)
data_string = pickle.dumps(data)
print 'PICKLE: %r' % data_string 默认情况下,pickle只包含ASCII字符。解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
DATA:
[{'a': 'A', 'b': 2, 'c': 3.0}]
PICKLE: "(lp1\n(dp2\nS'a'\nS'A'\nsS'c'\nF3\nsS'b'\nI2\nsa."
数据串行化后,可以写到一个文件,套接字或者管道等等。之后可以读取这个文件,将数据解除pickle,用同样的值构造一个新的对象:
try:
import cPickle as pickle
except:
import pickle
import pprint
data1 = [{'a' : 'A', 'b' : 2, 'c' : 3.0}]
print 'BEFORE:'
pprint.pprint(data1)
data_string = pickle.dumps(data1)
print 'PICKLE: %r' % data_string
data2 = pickle.loads(data_string)
print 'AFTER:'
pprint.pprint(data2)
print 'SAME?:', (data1 is data2)
print 'EQUAL?:', (data1 == data2) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
BEFORE:
[{'a': 'A', 'b': 2, 'c': 3.0}]
PICKLE: "(lp1\n(dp2\nS'a'\nS'A'\nsS'c'\nF3\nsS'b'\nI2\nsa."
AFTER:
[{'a': 'A', 'b': 2, 'c': 3.0}]
SAME?: False
EQUAL?: True
新构造的对象等于原来的对象,但并不是同一个对象。
3. 处理流
使用pickle可以向一个流写多个对象,然后从流读取这些对象,而无须事先知道要写多少个对象或者这些对象有多大。
try:
import cPickle as pickle
except:
import pickle
import pprint
from StringIO import StringIO
class SimpleObject(object):
def __init__(self, name):
self.name = name
self.name_backwards = name[::-1]
return
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('cPickle'))
data.append(SimpleObject('last'))
#Simulate a file with StringIO
out_s = StringIO()
#Write to the stream
for o in data:
print 'WRITING: %s (%s)' % (o.name, o.name_backwards)
pickle.dump(o, out_s)
out_s.flush()
#Set up a read-able stream
in_s = StringIO(out_s.getvalue())
#Read the data
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print 'READ :%s (%s)' % (o.name, o.name_backwards)
这个例子使用了两个StringIO缓冲区来模拟流。第一个缓冲区接收pickle的对象,将其值传入到第二个缓冲区,load()将读取这个缓冲区。解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py WRITING: pickle (elkcip) WRITING: cPickle (elkciPc) WRITING: last (tsal) READ :pickle (elkcip) READ :cPickle (elkciPc) READ :last (tsal)除了存储数据,pickle对于进程间通信也很方便。例如,os.fork()和os.pipe()可以用来建立工作进程,从一个管道读取作业指令,并把结果写至另一个管道。管理工作线程池以及发送作业和接收响应的核心代码可以重用,因为作业和响应对象不必基于一个特定的类。使用管道或套接字时,在转储各个对象之后不要忘记刷新输出,将数据通过连接推至另一端。
4. 重构对象的问题
处理定制类时,pickle类必须出现在读取pickle的进程所在的命名空间。所以解除pickle的数据时候,需要导入关联此pickle的一切对象。以下实例将数据写入到一个文件中:
try:
import cPickle as pickle
except:
import pickle
import sys
class SimpleObject(object):
def __init__(self, name):
self.name = name
l = list(name)
l.reverse()
self.name_backwards = ''.join(l)
return
if __name__ == '__main__':
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('cPickle'))
data.append(SimpleObject('last'))
filename = sys.argv[1]
with open(filename, 'wb') as out_s:
for o in data:
print 'WRITING: %s (%s)' % (o.name, o.name_backwards)
pickle.dump(o, out_s) 运行此脚本,我们将数据写入到一个文件中:
leichaojian@leichaojian-ThinkPad-T430:~$ python pickle_to_file_1.py test.dat WRITING: pickle (elkcip) WRITING: cPickle (elkciPc) WRITING: last (tsal) leichaojian@leichaojian-ThinkPad-T430:~$ ll test.dat -rw-rw-r-- 1 leichaojian leichaojian 451 3月 9 10:06 test.dat当我们读取数据的时候,需要加载SimpleObject类的对象,否则会解析出错:
try: import cPickle as pickle except: import pickle import pprint from StringIO import StringIO import sys from pickle_to_file_1 import SimpleObject filename = sys.argv[1] with open(filename, 'rb') as in_s: while True: try: o = pickle.load(in_s) except EOFError: break else: print 'READ: %s (%s)' % (o.name, o.name_backwards)解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py test.dat READ: pickle (elkcip) READ: cPickle (elkciPc) READ: last (tsal)
5. 不可pickle的对象
并不是所有对象都是可pickle的。套接字,文件句柄,数据库连接以及其他运行时状态依赖于操作系统或其他进程的对象可能无法用一种有意义的方式保存。如果对象包含不可pickle的属性,可以定义__getstate__()和__setstate__()来返回可pickle实例状态的一个子集。
6. 循环引用
pickle协议会自动处理对象之间的循环引用,所以复杂数据结构不需要任何特殊的处理。考虑如下循环引用:

import pickle
class Node(object):
"""A simple digraph"""
def __init__(self, name):
self.name = name
self.connections = []
def add_edge(self, node):
"""Create an edge between this node and the other"""
self.connections.append(node)
def __iter__(self):
return iter(self.connections)
def preorder_traversal(root, seen=None, parent=None):
"""Generator function to yield the edges in a graph."""
if seen is None:
seen = set()
yield (parent, root)
if root in seen:
return
seen.add(root)
for node in root:
for parent, subnode in preorder_traversal(node, seen, root):
yield (parent, subnode)
def show_edges(root):
for parent, child in preorder_traversal(root):
if not parent:
continue
print '%5s -> %2s (%s)' % (parent.name, child.name, id(child))
# set up the nodes
root = Node('root')
a = Node('a')
b = Node('b')
c = Node('c')
#Add edges between them
root.add_edge(a)
root.add_edge(b)
a.add_edge(b)
b.add_edge(a)
b.add_edge(c)
a.add_edge(a)
print 'ORIGINAL GRAPH:'
show_edges(root)
#pickle and unpickle the graph to create
#a new set of nodes
dumped = pickle.dumps(root)
reloaded = pickle.loads(dumped)
print '\nRELOADED GRAPH:'
show_edges(reloaded) 重新加载的节点并不是同一个对象,不过节点之间的关系得到了维护,而且如果对象有多个引用,那么只会重新加载它的一个副本。解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
ORIGINAL GRAPH:
root -> a (140676705940048)
a -> b (140676705940112)
b -> a (140676705940048)
b -> c (140676705940176)
a -> a (140676705940048)
root -> b (140676705940112)
RELOADED GRAPH:
root -> a (140676705940304)
a -> b (140676705940368)
b -> a (140676705940304)
b -> c (140676705940496)
a -> a (140676705940304)
root -> b (140676705940368)
2. shelve---对象持久存储
作用:shelve模块使用一种类字典的API,可以持久存储可pickle的任意Python对象。
不需要关系数据库时,shelve模块可以用作Python对象的一个简单的持久存储选择。类似于字典,shelf要按键来访问。值将被pickle并写至anydbm创建和管理的数据库。
1. 创建一个新shelf
使用shelve最简单的方法就是通过DbfilenameShelf类。它使用anydbm存储数据。这个类可以直接使用,也可以通过调用shelve.open()来使用:
import shelve
from contextlib import closing
with closing(shelve.open('test_shelf.db')) as s:
s['key1'] = {'int': 10, 'float': 9.5, 'string': 'Sample data'}
with closing(shelve.open('test_shelf.db')) as s:
existing = s['key1']
print existing 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
{'int': 10, 'float': 9.5, 'string': 'Sample data'}
2. 写回
默认情况下,shelf不会跟踪对可变对象的修改。这说明,如果存储在shelf中的一个元素内容有变化,shelf必须通过再次存储整个元素来显式更新。
对于shelf中存储的可变对象,为了自动捕获其修改,打开shelf时可以启用写回(writeback)。写回标志使得shelf使用内存中缓存记住从数据库取得所有对象。shelf关闭时每个缓存对象也写回到数据库。
import shelve
import pprint
from contextlib import closing
with closing(shelve.open('test_shelf.db', writeback=True)) as s:
print 'Initial data:'
pprint.pprint(s['key1'])
s['key1']['new_value'] = 'this was not here before'
print '\nModified:'
pprint.pprint(s['key1'])
with closing(shelve.open('test_shelf.db', writeback=True)) as s:
print '\nPreserved:'
pprint.pprint(s['key1']) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
Initial data:
{'float': 9.5, 'int': 10, 'string': 'Sample data'}
Modified:
{'float': 9.5,
'int': 10,
'new_value': 'this was not here before',
'string': 'Sample data'}
Preserved:
{'float': 9.5,
'int': 10,
'new_value': 'this was not here before',
'string': 'Sample data'}
尽管这会减少程序员犯错的机会,并且能使对象持久存储更透明,但是并非所有情况都有必要使用写回模式。打开shelf时缓存会消耗额外的内存,它关闭时会暂停将各个缓存对象写回到数据库,这会使应用的速度减慢。所有缓存的对象都要写回数据库,因为无法区分它们是否修改。如果应用读取的数据多于写的数据,写回会影响性能而且没有太大意义。
3. anydbm---DBM数据库
作用:anydbm为以字符串为键的DBM数据库提供了一个通用的类字典接口
anydbm是面向DBM数据库的一个前端,DBM数据库使用简单的字符串值作为键来访问包含字符串的记录。anydbm使用whichdb标识数据库,然后用适当的模块打开这些数据库。它还用作为shelve的一个后端,shelve使用pickle将对象存储在一个DBM数据库中。
1. 数据库类型
Python提供了很多模块来访问DBM数据库。具体选择哪个实现取决于当前系统上可用的库以及编译Python时使用的选项。
dbhash:
dbhash模块是anydbm的主要后端。它使用bsddb库来管理数据库文本.
gdbm:
gdbm是GNU项目dbm库的一个更新版本。对open()支持的标识有些修改:
除了标准'r','w','c'和'n'标志,gdbm.open()还支持以下标志:
‘f’以快速模式打开数据库。在快速模式下,对数据库的写并不同步
‘s’以同步模式打开数据库。对数据库做出修改时,这些改变要写至文件,而不是延迟到数据库关闭或显式同步时才写至文件。
‘u’不加锁的打开数据库。
dbm:
dbm模块为dbm格式的某个C实现提供了一个接口。
dumbdbm:
dumbdbm模块是没有其他实现可用时DBM API的一个可移植的后背实现。使用dumbdbm不要求依赖任何外部库,不过它比大多数其他实现速度都慢。
2. 创建一个新数据库
会按顺序查找以下各个模块来选择新数据库的存储格式:dbhash, gdbm, db, dumbdbm.
open()函数可以接收一些标志来控制如何管理数据库文件。必要时,要创建一个新的数据库,可以使用'c'。使用'n'则总会创建一个新数据库而覆盖现有的文件:
import anydbm
db = anydbm.open('/tmp/example.db', 'n')
db['key'] = 'value'
db['today'] = 'Sunday'
db['author'] = 'Doug'
db.close() 运行完以后,我们可以通过以下指令来查看数据库的类型:
>>> import whichdb
>>> print whichdb.whichdb('/tmp/example.db')
dbhash
3. 打开一个现有数据库
要打开一个现有数据库,可以使用标志‘r’(只读)或‘w’(读写)。会把现有的数据库自动提供给whichdb来识别,所以只要一个文件可以识别,就会使用一个适当的模块来打开这个文件。
import anydbm
db = anydbm.open('/tmp/example.db', 'r')
try:
print 'keys():', db.keys()
for k, v in db.iteritems():
print 'iterating:', k, v
finally:
db.close() 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py keys(): ['author', 'key', 'today'] iterating: author Doug iterating: key value iterating: today Sunday
4. 错误情况
数据库的键必须是字符串,而且值必须是字符串或None:
import anydbm
db = anydbm.open('/tmp/example.db', 'w')
try:
db[1] = 'one'
except TypeError, err:
print '%s: %s' % (err.__class__.__name__, err)
finally:
db.close()
db = anydbm.open('/tmp/example.db', 'w')
try:
db['one'] = 1
except TypeError, err:
print '%s: %s' % (err.__class__.__name__, err)
finally:
db.close() 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py TypeError: Integer keys only allowed for Recno and Queue DB's TypeError: Data values must be of type string or None.
4. sqlite3---嵌入式关系数据库
作用: 实现一个嵌入式关系数据库,并提供SQL支持
1. 创建数据库
SQLite数据库作为一个文件存储在文件系统中。这个库管理对文件的访问,包括加锁来防止书写器使用它时造成破坏。数据库在第一次访问文件时创建,不过应用要负责管理数据库中的数据库表定义,即模式。
我们需要创建如下的数据库表:
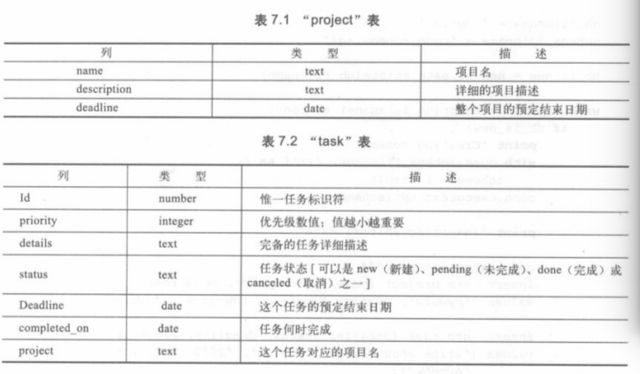
而具体的SQL语句存储在脚本todo_schema.sql中:
-- Schema for to-do application examples. -- Projects are high-level activities made up of tasks create table project ( name text primary key, description text, deadline date ); create table task ( id integer primary key autoincrement not null, priority integer default 1, details text, status text, deadline date, completed_on date, project text not null references project(name) );我们可以通过sqlite3.connect来创建数据库,通过executescript来执行脚本:
import os
import sqlite3
db_filename = 'todo.db'
schema_filename = 'todo_schema.sql'
db_is_new = not os.path.exists(db_filename)
with sqlite3.connect(db_filename) as conn:
if db_is_new:
print 'Creating schema'
with open(schema_filename, 'rt') as f:
schema = f.read()
conn.executescript(schema)
print 'Inserting initial data'
conn.executescript("""
insert into project (name, description, deadline) values ('pymotw', 'Python MOdule of the Week', '2010-11-01');
insert into task (details, status, deadline, project) values ('write about select', 'done', '2010-10-03', 'pymotw');
insert into task (details, status, deadline, project) values ('write about random', 'waiting', '2010-10-03', 'pymotw');
insert into task (details, status, deadline, project) values ('write about sqlite3', 'active', '2010-10-03', 'pymotw');
""")
else:
print 'Database exists, assume schema does, too.' 解释器运行如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Creating schema Inserting initial data leichaojian@leichaojian-ThinkPad-T430:~$ sqlite3 todo.db 'select * from task' 1|1|write about select|done|2010-10-03||pymotw 2|1|write about random|waiting|2010-10-03||pymotw 3|1|write about sqlite3|active|2010-10-03||pymotw
2. 获取数据
要从一个Python程序中获取task表中保存的值,可以从数据库连接创建一个cursor。游标(cursor)会生成一个一致的数据视图。
一般我们要用fetchall()获取所有的数据,而fetchone()一次获取一个结果,用fetchmany()获取固定大小的批量结果。
import sqlite3
db_filename = 'todo.db'
with sqlite3.connect(db_filename) as conn:
cursor = conn.cursor()
cursor.execute("""
select id, priority, details, status, deadline from task where project='pymotw'
""")
for row in cursor.fetchall():
task_id, priority, details, status, deadline = row
print '%2d {%d} %-20s [%-8s] (%s)' % (task_id, priority, details, status, deadline)
cursor.execute("""
select name, description, deadline from project where name='pymotw'
""")
name, description, deadline = cursor.fetchone()
print 'Project details for %s (%s) due %s' % (description, name, deadline)
cursor.execute("""
select id, priority, details, status, deadline from task where project='pymotw' order by deadline
""")
print '\nNext 2 tasks:'
for row in cursor.fetchmany(2):
task_id, priority, details, status, deadline = row
print '%2d {%d} %-25s [%-8s] (%s)' % (task_id, priority, details, status, deadline) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
1 {1} write about select [done ] (2010-10-03)
2 {1} write about random [waiting ] (2010-10-03)
3 {1} write about sqlite3 [active ] (2010-10-03)
Project details for Python MOdule of the Week (pymotw) due 2010-11-01
Next 2 tasks:
1 {1} write about select [done ] (2010-10-03)
2 {1} write about random [waiting ] (2010-10-03)
3. 查询元数据
DB-API2.0规范指出:调用execute()之后,cursor应当设置其description属性,来保存将由fetch方法返回的数据的有关信息。API规范指出这个描述值是一个元组序列,各元组包含列名,类型,显示大小,内部大小,精度,范围和一个指示是否接受null值的标志:
import sqlite3
db_filename = 'todo.db'
with sqlite3.connect(db_filename) as conn:
cursor = conn.cursor()
cursor.execute("""select * from task where project='pymotw'""")
print 'Task table has these columns:'
for colinfo in cursor.description:
print colinfo
4. 行对象
默认情况下,获取方法从数据库作为“行”返回的值是元组。但是如果我们想使用字典方式读取数据,例如row['id']的方式读取id的值,即返回的是一个类似字典和列表的数据结构,而非单纯的列表,那么我们就需要增加其row_factory属性:
import sqlite3
db_filename = 'todo.db'
with sqlite3.connect(db_filename) as conn:
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
cursor.execute("""
select id, priority, details, status, deadline from task where project='pymotw'
""")
for row in cursor.fetchall():
print row['id'], row, type(row) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py 1 (1, 1, u'write about select', u'done', u'2010-10-03') <type 'sqlite3.Row'> 2 (2, 1, u'write about random', u'waiting', u'2010-10-03') <type 'sqlite3.Row'> 3 (3, 1, u'write about sqlite3', u'active', u'2010-10-03') <type 'sqlite3.Row'>
5. 查询中使用变量
要在查询中使用动态值,正确的方法是利用随SQL指令一起传入execute()的宿主变量。SQL语句执行时,语句中的占位符值会替换为宿主变量的值。通过使用宿主变量,而不是解析之前的SQL语句中插入任意的值,这样可以避免注入攻击,因为不可信的值没有机会影响SQL语句的解析。SQLite支持两种形式占位符的查询,分别是位置参数和命名参数(命名参数更灵活):
位置参数
问号(?)指示一个位置参数,将作为元组的一个成员传至execute()
import sqlite3 import sys db_filename = 'todo.db' project_name = sys.argv[1] with sqlite3.connect(db_filename) as conn: cursor = conn.cursor() query = """select id, priority, details, status, deadline from task where project = ?""" cursor.execute(query, (project_name,)) for row in cursor.fetchall(): print row, type(row)解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py pymotw (1, 1, u'write about select', u'done', u'2010-10-03') <type 'tuple'> (2, 1, u'write about random', u'waiting', u'2010-10-03') <type 'tuple'> (3, 1, u'write about sqlite3', u'active', u'2010-10-03') <type 'tuple'>
命名参数
对于包含大量参数的更为复杂的查询,或者如果查询中某些参数会重复多次,则可以使用命名参数。命名参数前面有一个冒号作为前缀(例如,:param_name)
import sqlite3
import sys
db_filename = 'todo.db'
project_name = sys.argv[1]
with sqlite3.connect(db_filename) as conn:
cursor = conn.cursor()
query = """select id, priority, details, status, deadline from task where project = :project_name order by deadline, priority"""
cursor.execute(query, {'project_name': project_name})
for row in cursor.fetchall():
print row, type(row) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py pymotw (1, 1, u'write about select', u'done', u'2010-10-03') <type 'tuple'> (2, 1, u'write about random', u'waiting', u'2010-10-03') <type 'tuple'> (3, 1, u'write about sqlite3', u'active', u'2010-10-03') <type 'tuple'>
6. 批量加载
要对一个很大的数据集应用相同的SQL指令,可以使用executemany().这对于加载数据很有用,底层库会对其进行优化而非循环处理。
要加载的数据在tasks.csv文件中:
leichaojian@leichaojian-ThinkPad-T430:~$ cat tasks.csv deadline, project, priority, details 2010-10-02,pymotw,2,"finish reviewing markup" 2010-10-03,pymotw,2,"revise chapter intros" 2010-10-03,pymotw,1,"subtitle"而示例代码如下:
import csv import sqlite3 import sys db_filename = 'todo.db' data_filename = sys.argv[1] SQL = """insert into task (details, priority, status, deadline, project) values (:details, :priority, 'active', :deadline, :project)""" with open(data_filename, 'rt') as csv_file: csv_reader = csv.DictReader(csv_file) with sqlite3.connect(db_filename) as conn: cursor = conn.cursor() print csv_reader cursor.executemany(SQL, csv_reader)解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py tasks.csv<csv.DictReader instance at 0x7f94525ff8c0> leichaojian@leichaojian-ThinkPad-T430:~$ sqlite3 'todo.db' 'select * from task' 1|1|write about select|done|2010-10-03||pymotw 2|1|write about random|waiting|2010-10-03||pymotw 3|1|write about sqlite3|active|2010-10-03||pymotw 4|2|finish reviewing markup|active|2010-10-02||pymotw 5|2|revise chapter intros|active|2010-10-03||pymotw 6|1|subtitle|active|2010-10-03||pymotw
7. 定义新列类型
尽管SQLite在内部只支持几种数据类型,不过sqlite3包括了一些便利工具,可以定义定制类型,允许Python应用在列中存储任意类型的数据。除了那些得到默认支持的类型外,还可以在数据库连接中使用detect_types标志启用其他类型的转换。如果定义表时使用所要求的类型来声明,可以使用PARSE_DECLTYPES.
import sqlite3 import sys db_filename = 'todo.db' sql = "select id, details, deadline from task" def show_deadline(conn): conn.row_factory = sqlite3.Row cursor = conn.cursor() cursor.execute(sql) row = cursor.fetchone() for col in ['id', 'details', 'deadline']: print '%-8s %-30r %s' % (col, row[col], type(row[col])) return print 'Without type detection:' with sqlite3.connect(db_filename) as conn: show_deadline(conn) print 'With type detection:' with sqlite3.connect(db_filename, detect_types=sqlite3.PARSE_DECLTYPES) as conn: show_deadline(conn)sqlite3为日期和时间戳提供了转换器,它使用datetime模块的date和datetime表示Python中的值:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Without type detection: id 1 <type 'int'> details u'write about select' <type 'unicode'> deadline u'2010-10-03' <type 'unicode'> With type detection: id 1 <type 'int'> details u'write about select' <type 'unicode'> deadline datetime.date(2010, 10, 3) <type 'datetime.date'>定义一个新类型需要注册两个函数。适配器取Python对象作为输入,返回一个可以存储在数据库中的字节串。转换器从数据库接收串,返回一个Python对象。要使用register_adapter()定义适配器函数,使用register_converter()定义转换器函数。
import sqlite3
try:
import cPickle as pickle
except:
import pickle
db_filename = 'todo.db'
def adapter_func(obj):
"""Convert from in-memory to storage representation."""
print 'adapter_func(%s)\n' % obj
return pickle.dumps(obj)
def converter_func(data):
"""Convert from storage to in-memory representation."""
print 'converter_func(%r)\n' % data
return pickle.loads(data)
class MyObj(object):
def __init__(self, arg):
self.arg = arg
def __str__(self):
return 'MyObj(%r)' % self.arg
# Register the functions for manipulating the type
sqlite3.register_adapter(MyObj, adapter_func)
sqlite3.register_converter('MyObj', converter_func)
#Create some objects to save. Use a list of tuples so the sequence can be passed directly to executemany()
to_save = [(MyObj('this is a value to save'),),
(MyObj(42),),
]
with sqlite3.connect(db_filename,
detect_types=sqlite3.PARSE_DECLTYPES) as conn:
# Create a table with column of type "MyObj"
SQL = """create table if not exists obj (
id integer primary key autoincrement not null,
data MyObj
)"""
conn.execute(SQL)
cursor = conn.cursor()
cursor.executemany("insert into obj (data) values (?)", to_save)
cursor.execute("select id, data from obj")
for obj_id, obj in cursor.fetchall():
print 'Retrieved', obj_id, obj, type(obj)
print
解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
adapter_func(MyObj('this is a value to save'))
adapter_func(MyObj(42))
converter_func("ccopy_reg\n_reconstructor\np1\n(c__main__\nMyObj\np2\nc__builtin__\nobject\np3\nNtRp4\n(dp5\nS'arg'\np6\nS'this is a value to save'\np7\nsb.")
converter_func("ccopy_reg\n_reconstructor\np1\n(c__main__\nMyObj\np2\nc__builtin__\nobject\np3\nNtRp4\n(dp5\nS'arg'\np6\nI42\nsb.")
Retrieved 1 MyObj('this is a value to save') <class '__main__.MyObj'>
Retrieved 2 MyObj(42) <class '__main__.MyObj'>
8. 确定列类型
可以在查询自身的select子句包含类型指示符,采用以下形式: as "name[type]"
import sqlite3
try:
import cPickle as pickle
except:
import pickle
db_filename = 'todo.db'
def adapter_func(obj):
"""Convert from in-memory to storage representation."""
print 'adapter_func(%s)\n' % obj
return pickle.dumps(obj)
def converter_func(data):
"""Convert from storage to in-memory representation."""
print 'converter_func(%r)\n' % data
return pickle.loads(data)
class MyObj(object):
def __init__(self, arg):
self.arg = arg
def __str__(self):
return 'MyObj(%r)' % self.arg
# Register the functions for manipulating the type
sqlite3.register_adapter(MyObj, adapter_func)
sqlite3.register_converter("MyObj", converter_func)
# Create some object to save. Use a list of tuples so we can pass this sequence directly to executemany().
to_save = [(MyObj('this is a value to save'),),
(MyObj(42),),
]
with sqlite3.connect(db_filename,
detect_types=sqlite3.PARSE_COLNAMES) as conn:
# Create a table with column of type "text"
SQL = """create table if not exists obj2 (
id integer primary key autoincrement not null,
data text
)"""
conn.execute(SQL)
cursor = conn.cursor()
#Insert the objects into the database
cursor.executemany("insert into obj2 (data) values (?)", to_save)
cursor.execute('select id, data as "pickle [MyObj]" from obj2')
for obj_id, obj in cursor.fetchall():
print 'Retrieved', obj_id, obj, type(obj)
print 这里:pickle [MyObj]指定了其类型。解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py
adapter_func(MyObj('this is a value to save'))
adapter_func(MyObj(42))
converter_func("ccopy_reg\n_reconstructor\np1\n(c__main__\nMyObj\np2\nc__builtin__\nobject\np3\nNtRp4\n(dp5\nS'arg'\np6\nS'this is a value to save'\np7\nsb.")
converter_func("ccopy_reg\n_reconstructor\np1\n(c__main__\nMyObj\np2\nc__builtin__\nobject\np3\nNtRp4\n(dp5\nS'arg'\np6\nI42\nsb.")
Retrieved 1 MyObj('this is a value to save') <class '__main__.MyObj'>
Retrieved 2 MyObj(42) <class '__main__.MyObj'>
9. 事务
关系数据库的关键特性之一是使用事务维护一致的内部状态。启用事务时,在提交结果并刷新输出到真正的数据库之前,可以通过一个连接完成多个变更,而不会影响任何其他用户。
保留变更
不论通过插入还是更新语句改变数据库,都需要显式的调用commit()保存这些变更。这个要求为应用提供了一个机会,可以将多个相关的变更一同完成,使它们以一种“原子”方式保存而不是增量保存,这样可以避免同时连接到数据库的不同客户只看到部分更新情况。
import sqlite3
db_filename = 'todo.db'
def show_projects(conn):
cursor = conn.cursor()
cursor.execute('select name, description from project')
for name, desc in cursor.fetchall():
print ' ', name
return
with sqlite3.connect(db_filename) as conn1:
print 'Before changes:'
show_projects(conn1)
#Insert in one cursor
cursor1 = conn1.cursor()
SQL = """insert into project (name, description, deadline) values ('virtualenvwrapper', 'Virtualenv Extensions', '2011-01-01')"""
cursor1.execute(SQL)
print '\nAfter changes in conn1:'
show_projects(conn1)
#Select from another connection, without committing first
print '\nBefore commit:'
with sqlite3.connect(db_filename) as conn2:
show_projects(conn2)
#Commit then select from another connection
conn1.commit()
print '\nAfter commit:'
with sqlite3.connect(db_filename) as conn3:
show_projects(conn3) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Before changes: pymotw After changes in conn1: pymotw virtualenvwrapper Before commit: pymotw After commit: pymotw virtualenvwrapper
丢弃变更
还可以使用rollback()完全丢弃未提交的变更。commit()和rollback()方法通常在同一个try:except块的不同部分调用,有错误时就会触发回滚。
import sqlite3
db_filename = 'todo.db'
def show_projects(conn):
cursor = conn.cursor()
cursor.execute('select name, description from project')
for name, desc in cursor.fetchall():
print ' ', name
return
with sqlite3.connect(db_filename) as conn:
print 'Before changes:'
show_projects(conn)
try:
#Insert
cursor = conn.cursor()
cursor.execute("""delete from project where name='virtualenvwrapper'""")
#Show the settings
print '\nAfter delete:'
show_projects(conn)
raise RuntimeError('simulated error')
except Exception, err:
# Discard the change
print 'ERROR:', err
conn.rollback()
else:
# Save the changes
conn.commit()
#Show the results
print '\nAfter rollback:'
show_projects(conn)
解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Before changes: pymotw virtualenvwrapper After delete: pymotw ERROR: simulated error After rollback: pymotw virtualenvwrapper
10. 隔离级别
sqlite3支持3种加锁模式,也称为隔离级别。打开一个连接时可以传入一个字符串作为isolation_level参数来设置隔离级别,所以不同的连接可以使用不同的隔离级别值。
下面这个程序展示了使用同一个数据库的不同连接时,不同的隔离级别对于线程中事件的顺序会有什么影响。这里创建了4个线程。两个线程会更新现有的行,将变更写入数据库。另外两个线程尝试从task表读取所有的行。
import logging
import sqlite3
import sys
import threading
import time
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s (%(threadName)-10s) %(message)s',
)
db_filename = 'todo.db'
isolation_level = sys.argv[1]
def writer():
my_name = threading.currentThread().name
with sqlite3.connect(db_filename,
isolation_level=isolation_level) as conn:
cursor = conn.cursor()
cursor.execute('update task set priority = priority + 1')
logging.debug('waiting to synchronize')
ready.wait() #synchronize threads
logging.debug('PAUSING')
time.sleep(1)
conn.commit()
logging.debug('CHANGES COMMITTED')
return
def reader():
my_name = threading.currentThread().name
with sqlite3.connect(db_filename,
isolation_level=isolation_level) as conn:
cursor = conn.cursor()
logging.debug('waiting to synchronize')
ready.wait() #synchronize threads
logging.debug('wait over')
cursor.execute('select * from task')
logging.debug('SELECT EXECUTED')
results = cursor.fetchall()
logging.debug('results fetched')
return
if __name__ == '__main__':
ready = threading.Event()
threads = [
threading.Thread(name='Reader 1', target = reader),
threading.Thread(name='Reader 2', target = reader),
threading.Thread(name='Writer 1', target = writer),
threading.Thread(name='Writer 2', target = writer),
]
[t.start() for t in threads]
time.sleep(1)
logging.debug('setting ready')
ready.set()
[t.join() for t in threads]
这个线程使用threading模块的一个Event完成同步。writer()函数连接数据库,并完成数据库修改,不过在事件触发前并不提交。reader()函数连接数据库,然后等待查询数据库,直到出现同步事件。
延迟
默认的隔离级别是DEFERRED。使用延迟模式会锁定数据库,但只是在修改真正开始时锁定一次。
leichaojian@leichaojian-ThinkPad-T430:~$ python sqlite3_isolation_levels.py DEFERRED 2015-03-10 09:17:37,043 (Reader 1 ) waiting to synchronize 2015-03-10 09:17:37,044 (Reader 2 ) waiting to synchronize 2015-03-10 09:17:37,045 (Writer 2 ) waiting to synchronize 2015-03-10 09:17:38,034 (MainThread) setting ready 2015-03-10 09:17:38,034 (Writer 2 ) PAUSING 2015-03-10 09:17:38,035 (Reader 2 ) wait over 2015-03-10 09:17:38,035 (Reader 1 ) wait over 2015-03-10 09:17:38,036 (Reader 1 ) SELECT EXECUTED 2015-03-10 09:17:38,036 (Reader 2 ) SELECT EXECUTED 2015-03-10 09:17:38,037 (Reader 1 ) results fetched 2015-03-10 09:17:38,037 (Reader 2 ) results fetched 2015-03-10 09:17:39,140 (Writer 2 ) CHANGES COMMITTED 2015-03-10 09:17:39,179 (Writer 1 ) waiting to synchronize 2015-03-10 09:17:39,180 (Writer 1 ) PAUSING 2015-03-10 09:17:40,283 (Writer 1 ) CHANGES COMMITTED
立即
采用立即模式时,修改一开始时就会锁定数据库,从而在事务提交之前避免其他游标修改数据库。如果数据库有复杂的写操作,但是阅读器比书写器更多,这种模式就非常适合,因为事务进行中不会阻塞阅读器。
leichaojian@leichaojian-ThinkPad-T430:~$ python sqlite3_isolation_levels.py IMMEDIATE 2015-03-10 09:42:24,475 (Reader 2 ) waiting to synchronize 2015-03-10 09:42:24,476 (Reader 1 ) waiting to synchronize 2015-03-10 09:42:24,477 (Writer 1 ) waiting to synchronize 2015-03-10 09:42:25,478 (MainThread) setting ready 2015-03-10 09:42:25,479 (Writer 1 ) PAUSING 2015-03-10 09:42:25,479 (Reader 1 ) wait over 2015-03-10 09:42:25,479 (Reader 2 ) wait over 2015-03-10 09:42:25,481 (Reader 2 ) SELECT EXECUTED 2015-03-10 09:42:25,481 (Reader 1 ) SELECT EXECUTED 2015-03-10 09:42:25,482 (Reader 2 ) results fetched 2015-03-10 09:42:25,482 (Reader 1 ) results fetched 2015-03-10 09:42:26,570 (Writer 1 ) CHANGES COMMITTED 2015-03-10 09:42:26,612 (Writer 2 ) waiting to synchronize 2015-03-10 09:42:26,613 (Writer 2 ) PAUSING 2015-03-10 09:42:27,713 (Writer 2 ) CHANGES COMMITTED
互斥
互斥模式会对所有阅读器和书写器锁定数据库。如果数据库性能很重要,这种情况下就要限制使用这种模式,因为每个互斥的连接都会阻塞所有其他用户。
leichaojian@leichaojian-ThinkPad-T430:~$ python sqlite3_isolation_levels.py EXCLUSIVE 2015-03-10 09:48:37,776 (Reader 2 ) waiting to synchronize 2015-03-10 09:48:37,777 (Reader 1 ) waiting to synchronize 2015-03-10 09:48:37,779 (Writer 1 ) waiting to synchronize 2015-03-10 09:48:38,778 (MainThread) setting ready 2015-03-10 09:48:38,779 (Reader 2 ) wait over 2015-03-10 09:48:38,779 (Reader 1 ) wait over 2015-03-10 09:48:38,779 (Writer 1 ) PAUSING 2015-03-10 09:48:39,880 (Writer 1 ) CHANGES COMMITTED 2015-03-10 09:48:40,010 (Writer 2 ) waiting to synchronize 2015-03-10 09:48:40,010 (Writer 2 ) PAUSING 2015-03-10 09:48:41,098 (Writer 2 ) CHANGES COMMITTED 2015-03-10 09:48:41,112 (Reader 1 ) SELECT EXECUTED 2015-03-10 09:48:41,112 (Reader 1 ) results fetched 2015-03-10 09:48:41,141 (Reader 2 ) SELECT EXECUTED 2015-03-10 09:48:41,142 (Reader 2 ) results fetched由于第一个书写器已经开始修改,所以阅读器和第二个书写器会阻塞,直到第一个书写器提交。sleep()调用在书写器线程中引入一个人为的延迟,以强调其他连接已阻塞这个事实。
自动提交
连接的isolation_level参数还可以设置为None,以启用自动提交模式。启用自动提交时,每个execute()调用会在语句完成时立即提交。自动提交模式很适合简短的事务,如向一个表插入少量数据。数据库锁定时间尽可能短,所以线程间竞争的可能性更小。
以下实例和上述的代码基本相同,只是删除了commit()的显式调用,并设置隔离级别为None。
import logging
import sqlite3
import sys
import threading
import time
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s (%(threadName)-10s) %(message)s',
)
db_filename = 'todo.db'
isolation_level = None
def writer():
my_name = threading.currentThread().name
with sqlite3.connect(db_filename,
isolation_level=isolation_level) as conn:
cursor = conn.cursor()
cursor.execute('update task set priority = priority + 1')
logging.debug('waiting to synchronize')
ready.wait() #synchronize threads
logging.debug('PAUSING')
time.sleep(1)
logging.debug('CHANGES COMMITTED')
return
def reader():
my_name = threading.currentThread().name
with sqlite3.connect(db_filename,
isolation_level=isolation_level) as conn:
cursor = conn.cursor()
logging.debug('waiting to synchronize')
ready.wait() #synchronize threads
logging.debug('wait over')
cursor.execute('select * from task')
logging.debug('SELECT EXECUTED')
results = cursor.fetchall()
logging.debug('results fetched')
return
if __name__ == '__main__':
ready = threading.Event()
threads = [
threading.Thread(name='Reader 1', target = reader),
threading.Thread(name='Reader 2', target = reader),
threading.Thread(name='Writer 1', target = writer),
threading.Thread(name='Writer 2', target = writer),
]
[t.start() for t in threads]
time.sleep(1)
logging.debug('setting ready')
ready.set()
[t.join() for t in threads]
解释器显式如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python sqlite3_autocommit.py 2015-03-10 09:55:07,945 (Reader 1 ) waiting to synchronize 2015-03-10 09:55:07,945 (Reader 2 ) waiting to synchronize 2015-03-10 09:55:08,036 (Writer 1 ) waiting to synchronize 2015-03-10 09:55:08,145 (Writer 2 ) waiting to synchronize 2015-03-10 09:55:08,947 (MainThread) setting ready 2015-03-10 09:55:08,948 (Writer 2 ) PAUSING 2015-03-10 09:55:08,948 (Writer 1 ) PAUSING 2015-03-10 09:55:08,948 (Reader 1 ) wait over 2015-03-10 09:55:08,949 (Reader 2 ) wait over 2015-03-10 09:55:08,951 (Reader 1 ) SELECT EXECUTED 2015-03-10 09:55:08,951 (Reader 2 ) SELECT EXECUTED 2015-03-10 09:55:08,951 (Reader 1 ) results fetched 2015-03-10 09:55:08,952 (Reader 2 ) results fetched 2015-03-10 09:55:09,950 (Writer 2 ) CHANGES COMMITTED 2015-03-10 09:55:09,951 (Writer 1 ) CHANGES COMMITTED备注:对这一小节不是很理解,后期需要阅读APUE,UNP这类的书籍。
11. 内存中数据库
SQLite支持在RAM中管理整个数据库,而不是依赖开一个磁盘文件。如果测试运行之间不需要保留数据库,或者要尝试一个模式或其他数据库特性,此时内存中数据库对于自动测试会很有用。要打开一个内存中数据库,创建Connection时可以使用串':memory:'而不是一个文件名。每个‘:memory:’连接会创建一个单独的数据库实例,所以一个连接中游标所做的修改不会影响其他连接。
12. 导出数据库内容
内存中数据库的内容可以使用Connection的iterdump()方法保存。iterdump()方法返回迭代器生成一系列字符串,这些字符串将共同构造相应的SQL指令来重新创建数据库的状态。
import sqlite3
schema_filename = 'todo_schema.sql'
with sqlite3.connect(':memory:') as conn:
conn.row_factory = sqlite3.Row
print 'Create schema'
with open(schema_filename, 'rt') as f:
schema = f.read()
conn.executescript(schema)
print 'Inserting initial data'
SQL = """insert into project (name, description, deadline) values ('pymotw', 'Python Module of the Week', '2010-11-01')"""
conn.execute(SQL)
data = [
('write about select', 'done', '2010-10-03', 'pymotw'),
('write about random', 'waiting', '2010-10-10', 'pymotw'),
('write about sqlite3', 'active', '2010-10-17', 'pymotw'),
]
SQL = """insert into task (details, status, deadline, project) values (?,?,?,?)"""
conn.executemany(SQL, data)
print 'Dumping:'
for text in conn.iterdump():
print text iterdump()也适用于保存到文件的数据库,不过对于未保存的数据库最为有用。
leichaojian@leichaojian-ThinkPad-T430:~$ python sqlite3_iterdump.py
Create schema
Inserting initial data
Dumping:
BEGIN TRANSACTION;
CREATE TABLE project (
name text primary key,
description text,
deadline date
);
INSERT INTO "project" VALUES('pymotw','Python Module of the Week','2010-11-01');
DELETE FROM "sqlite_sequence";
INSERT INTO "sqlite_sequence" VALUES('task',3);
CREATE TABLE task (
id integer primary key autoincrement not null,
priority integer default 1,
details text,
status text,
deadline date,
completed_on date,
project text not null references project(name)
);
INSERT INTO "task" VALUES(1,1,'write about select','done','2010-10-03',NULL,'pymotw');
INSERT INTO "task" VALUES(2,1,'write about random','waiting','2010-10-10',NULL,'pymotw');
INSERT INTO "task" VALUES(3,1,'write about sqlite3','active','2010-10-17',NULL,'pymotw');
COMMIT;
13. SQL中使用Python函数
SQL语法支持在查询中调用函数,可以在列表中调用,也可以在select语句的where子句中调用。
import sqlite3
db_filename = 'todo.db'
def encrypt(s):
print 'Encrypting %r' % s
return s.encode('rot-13')
def decrypt(s):
print 'Decrypting %r' % s
return s.encode('rot-13')
with sqlite3.connect(db_filename) as conn:
conn.create_function('encrypt', 1, encrypt)
conn.create_function('decrypt', 1, decrypt)
cursor = conn.cursor()
print 'Original vlaues:'
query = 'select id, details from task'
cursor.execute(query)
for row in cursor.fetchall():
print row
print '\nEncrypting...'
query = 'update task set details = encrypt(details)'
cursor.execute(query)
print '\nRaw encrypted values:'
query = 'select id, details from task'
cursor.execute(query)
for row in cursor.fetchall():
print row
print '\nDecrypting in query...'
query = 'select id, decrypt(details) from task'
cursor.execute(query)
for row in cursor.fetchall():
print row 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Original vlaues: (1, u'write about select') (2, u'write about random') (3, u'write about sqlite3') (4, u'finish reviewing markup') (5, u'revise chapter intros') (6, u'subtitle') Encrypting... Encrypting u'write about select' Encrypting u'write about random' Encrypting u'write about sqlite3' Encrypting u'finish reviewing markup' Encrypting u'revise chapter intros' Encrypting u'subtitle' Raw encrypted values: (1, u'jevgr nobhg fryrpg') (2, u'jevgr nobhg enaqbz') (3, u'jevgr nobhg fdyvgr3') (4, u'svavfu erivrjvat znexhc') (5, u'erivfr puncgre vagebf') (6, u'fhogvgyr') Decrypting in query... Decrypting u'jevgr nobhg fryrpg' Decrypting u'jevgr nobhg enaqbz' Decrypting u'jevgr nobhg fdyvgr3' Decrypting u'svavfu erivrjvat znexhc' Decrypting u'erivfr puncgre vagebf' Decrypting u'fhogvgyr' (1, u'write about select') (2, u'write about random') (3, u'write about sqlite3') (4, u'finish reviewing markup') (5, u'revise chapter intros') (6, u'subtitle')
14. 定制聚集
聚集函数会收集多个单独的数据,并以某种方式汇总。avg(),min(),max()和count()都是内置聚集函数的例子。
import sqlite3
import collections
db_filename = 'todo.db'
class Mode(object):
def __init__(self):
self.counter = collections.Counter()
def step(self, value):
print 'step(%r)' % value
self.counter[value] += 1
def finalize(self):
result, count = self.counter.most_common(1)[0]
print 'finalize() -> %r (%d times)' % (result, count)
return result
with sqlite3.connect(db_filename) as conn:
conn.create_aggregate('mode', 1, Mode)
cursor = conn.cursor()
cursor.execute("""select mode(deadline) from task where project='pymotw'""")
row = cursor.fetchone()
print 'mode(deadline) is:', row[0] 聚集器类用Connection的create_aggregate()方法注册。参数包括函数名,step()方法所取的参数个数,以及要使用的类。
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py step(u'2010-10-03') step(u'2010-10-03') step(u'2010-10-03') step(u'2010-10-02') step(u'2010-10-03') step(u'2010-10-03') finalize() -> u'2010-10-03' (5 times) mode(deadline) is: 2010-10-03 leichaojian@leichaojian-ThinkPad-T430:~$ sqlite3 'todo.db' 'select * from task' 1|11|jevgr nobhg fryrpg|done|2010-10-03||pymotw 2|11|jevgr nobhg enaqbz|waiting|2010-10-03||pymotw 3|11|jevgr nobhg fdyvgr3|active|2010-10-03||pymotw 4|12|svavfu erivrjvat znexhc|active|2010-10-02||pymotw 5|12|erivfr puncgre vagebf|active|2010-10-03||pymotw 6|11|fhogvgyr|active|2010-10-03||pymotw
15. 定制排序
比对是一个比较函数,在SQL查询的order by部分使用。
import sqlite3
try:
import cPickle as pickle
except:
import pickle
db_filename = 'todo.db'
def adapter_func(obj):
return pickle.dumps(obj)
def converter_func(data):
return pickle.loads(data)
class MyObj(object):
def __init__(self, arg):
self.arg = arg
def __str__(self):
return 'MyObj(%r)' % self.arg
def __cmp__(self, other):
return cmp(self.arg, other.arg)
sqlite3.register_adapter(MyObj, adapter_func)
sqlite3.register_converter("MyObj", converter_func)
def collation_func(a, b):
a_obj = converter_func(a)
b_obj = converter_func(b)
print 'collation_func(%s, %s)' % (a_obj, b_obj)
return cmp(a_obj, b_obj)
with sqlite3.connect(db_filename,
detect_types=sqlite3.PARSE_DECLTYPES,
) as conn:
#Define the collation
conn.create_collation('unpickle', collation_func)
#clear the table and insert new values
conn.execute('delete from obj')
conn.executemany('insert into obj (data) values (?)',
[(MyObj(x),) for x in xrange(5, 0, -1)],
)
print 'Querying:'
cursor = conn.cursor()
cursor.execute("""select id, data from obj order by data collate unpickle""")
for obj_id, obj in cursor.fetchall():
print obj_id, obj 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Querying: collation_func(MyObj(2), MyObj(1)) collation_func(MyObj(4), MyObj(3)) collation_func(MyObj(3), MyObj(1)) collation_func(MyObj(3), MyObj(2)) collation_func(MyObj(5), MyObj(1)) collation_func(MyObj(5), MyObj(2)) collation_func(MyObj(5), MyObj(3)) collation_func(MyObj(5), MyObj(4)) 7 MyObj(1) 6 MyObj(2) 5 MyObj(3) 4 MyObj(4) 3 MyObj(5)
16. 线程和连接共享
Connection对象不能在线程间共享。每个线程必须创建自己的数据库连接。
import sqlite3
import sys
import threading
import time
db_filename = 'todo.db'
isolation_level = None
def reader(conn):
my_name = threading.currentThread().name
print 'Starting thread'
try:
cursor = conn.cursor()
cursor.execute('select * from task')
results = cursor.fetchall()
print 'results fetched'
except Exception, err:
print 'ERROR:', err
return
if __name__ == '__main__':
with sqlite3.connect(db_filename,
isolation_level=isolation_level,
) as conn:
t = threading.Thread(name='Reader 1',
target=reader,
args=(conn,),
)
t.start()
t.join() 如果试图在线程之间共享一个连接,这会导致一个异常:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Starting thread ERROR: SQLite objects created in a thread can only be used in that same thread.The object was created in thread id 140642553907008 and this is thread id 140642521552640
17. 限制对数据的访问
SQLite提供了一种机制来限制列访问。每个连接可以安装一个授权函数,运行时可以根据所需的原则来批准或拒绝访问列。这个授权函数会在解析SQL语句时调用,将传入5个参数。第一个参数是一个动作码,指示所完全的操作的类型(读,写,删除等等)。其余的参数则取决于动作码。
import sqlite3
db_filename = 'todo.db'
def authorizer_func(action, table, column, sql_location, ignore):
print '\nauthorizer_func(%s, %s, %s, %s, %s)' % \
(action, table, column, sql_location, ignore)
response = sqlite3.SOLITE_OK
if action == sqlite3.SQLITE_SELECT:
print 'requesting permission to run a select statement'
response = sqlite3.SQLITE_OK
elif action == sqlite3.SQLITE_READ:
print 'requesting access to column %s.%s from %s' % \
(table, column, sql_location)
if column == 'details':
print 'ignoring details column'
response = sqlite3.SQLITE_IGNORE
elif column == 'priority':
print 'preventing access to priority column'
response = sqlite3.SQLITE_DENY
return response
with sqlite3.connect(db_filename) as conn:
conn.row_factory = sqlite3.Row
conn.set_authorizer(authorizer_func)
print 'Using SQLITE_IGNORE to mask a column vlaue:'
cursor = conn.cursor()
cursor.execute("""
select id, details from task where project='pymotw'
""")
for row in cursor.fetchall():
print row['id'], row['details']
print '\nUsing SQLITE_DENY to deny access to a column:'
cursor.execute("""
select id, priority from task where project='pymotw'
""")
for row in cursor.fetchall():
print row['id'], row['details'] 但是,运行除错!
6. xml.etree.ElementTree---XML操纵API
作用:生成和解析XML文档
1. 解析XML文档
已解析的XML文档在内存中由ElementTree和Element对象表示,这些对象基于XML文档中节点嵌套的方式以数结构相互连接。
用parse()解析一个完整的文档时,会返回一个ElementTree实例。
测试的数据如下(podcasts.opml):
<?xml version="1.0" encoding="UTF-8"?> <opml version="1.0"> <head> <title>My Podcasts</title> <p>this is a paragraph 1</p> <p>this is a paragraph 2</p> </head> <body> <outline text="Fiction"> <p1>this is a outline 1</p1> </outline> <outline text="Python"> <outline text="text1" xmlUrl="http://www.google.com" /> <outline text="text2" xmlUrl="http://www.baidu.com" /> </outline> </body> </opml>要解析这个文档,需要向parse()传递一个打开的文件句柄:
from xml.etree import ElementTree
with open('podcasts.opml', 'rt') as f:
tree = ElementTree.parse(f)
print tree
2. 遍历解析树
要按顺序访问所有子节点,可以使用iter()创建一个生成器,迭代器处理这个ElementTree实例。
from xml.etree import ElementTree
import pprint
with open('podcasts.opml', 'rt') as f:
tree = ElementTree.parse(f)
for node in tree.iter():
print node.tag 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py opml head title p p body outline p1 outline outline outline如果只要打印具体的属性名,可以使用attrib属性:
from xml.etree import ElementTree
import pprint
with open('podcasts.opml', 'rt') as f:
tree = ElementTree.parse(f)
for node in tree.iter('outline'):
name = node.attrib.get('text')
url = node.attrib.get('xmlUrl')
if name and url:
print '%s' % name
print '%s' % url
else:
print name 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Fiction Python text1 http://www.google.com text2 http://www.baidu.com
3. 查找文档中的节点
如果我们知道url的具体路径在哪个outline下,我们就不必遍历所有的outline。通过具体的路径和findall函数即可办到:
from xml.etree import ElementTree
import pprint
with open('podcasts.opml', 'rt') as f:
tree = ElementTree.parse(f)
for node in tree.findall('.//outline/outline'):
url = node.attrib.get('xmlUrl')
print url 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py http://www.google.com http://www.baidu.com
4. 解析节点属性
findall()和iter()返回的元素是Element对象。
示例数据data.xml:
<?xml version="1.0" encoding="UTF-8"?> <top> <child>Regular text.</child> <child_with_tail>Regular text.</child_with_tail>"Tail" text. <with_attributes name="value" foo="bar" /> <entity_expansion attribute="This & That"> That & This </entity_expansion> </top>而测试代码如下:
from xml.etree import ElementTree
with open('data.xml', 'rt') as f:
tree = ElementTree.parse(f)
node = tree.find('./with_attributes')
print node.tag
for name, value in sorted(node.attrib.items()):
print ' %-4s = "%s"' % (name, value) 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py with_attributes foo = "bar" name = "value"还可以得到节点的文本内容,以及结束标记后面的tail文本。
from xml.etree import ElementTree
with open('data.xml', 'rt') as f:
tree = ElementTree.parse(f)
for path in ['./child', './child_with_tail']:
node = tree.find(path)
print node.tag
print ' child node text:', node.text
print ' and tail text:', node.tail 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py child child node text: Regular text. and tail text: child_with_tail child node text: Regular text. and tail text: "Tail" text.返回值之前,文档中嵌入的XML实体引用会转换为适当的字符。
from xml.etree import ElementTree
with open('data.xml', 'rt') as f:
tree = ElementTree.parse(f)
node = tree.find('entity_expansion')
print node.tag
print ' in attribute:', node.attrib['attribute']
print ' in text:', node.text.strip() 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py entity_expansion in attribute: This & That in text: That & This
5. 解析时监视事件
另一个处理XML文档的API是基于事件的。解析器为开始标记生成start事件,为结束标记生成end事件。解析阶段中可以通过迭代处理事件流从文档抽取数据。如果以后没有必要处理整个文档,或者没有必要将整个解析文档都保存在内存中,基于事件的API就会很方便。
备注:XML这部分不想看,后期如果有欲望,就补上。
7. CSV---逗号分隔值文件
作用:读写逗号分隔值文件
可以用csv模块处理从电子表格和数据库导出的数据,并写入采用字段和记录格式的文本文件,这种格式通常称为逗号分隔值格式,因为常用逗号来分隔记录中的字段。
1. 读文件
数据文件testdata.csv:
hello world i love this world and i love python too测试代码:
import csv import sys with open(sys.argv[1], 'rt') as f: reader = csv.reader(f) for row in reader: print row解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py testdata.csv ['hello world'] ['i love this world'] ['and i love python too']
2. 写文件
可以使用writer()创建一个对象来写数据,然后使用writerow()迭代处理文本行进行打印。
import csv
import sys
with open(sys.argv[1], 'wt') as f:
writer = csv.writer(f)
writer.writerow(('Title 1', 'Title 2', 'Title 3'))
for i in range(3):
writer.writerow((i + 1, chr(ord('a') + i),
'08/%02d/07' % (i + 1),
))
print open(sys.argv[1], 'rt').read() 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py testout.csv Title 1,Title 2,Title 3 1,a,08/01/07 2,b,08/02/07 3,c,08/03/07引号
对于书写器,默认的引号行为有所不同。要加上引号,则需要添加quoting属性:
QUOTE_ALL:不论类型是什么,对所有字段都加引号。
QUOTE_MINIMAL:对包含特殊字符的字段加引号,这是默认选项。
QUOTE_NONNUMERIC: 对所有非整数或浮点数的字段加引号。
QUOTE_NONE:输出中所有内容都不加引号。
writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py testout.csv "Title 1","Title 2","Title 3" 1,"a","08/01/07" 2,"b","08/02/07" 3,"c","08/03/07"
3. 方言
我们可以使用dislects()获取已注册方言列表
>>> import csv >>> csv.list_dialects() ['excel-tab', 'excel']
创建方言
使用竖线("|")来作为分隔符。
"Title 1"|"Title 2"|"Title 3" 1|"first line\nsecond line"|08/18/07我们将注册一个新方言,将竖线("|")作为分隔符:
import csv
csv.register_dialect('pipes', delimiter='/')
with open('testdata.pipes', 'r') as f:
reader = csv.reader(f, dialect='pipes')
for row in reader:
print row 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py ['Title 1|"Title 2"|"Title 3"'] ['1|"first line\\nsecond line"|08', '18', '07']
方言参数
方言指定了解析或写一个数据文件时使用的所有记号。
| 属性 |
默认值 |
含义 |
| delimiter |
, |
字段分隔符(一个字符) |
| doublequote |
True |
这个标志控制quotechar实例是否成对 |
| escapechar |
None |
这个字符用来指示一个转义序列 |
| lineterminator |
\r\n |
书写器使用这个字符串结束一行 |
| quotechar |
" |
这个字符串用来包围包含特殊值的字段(一个字符) |
| quoting |
QUOTE_MINIMAL |
控制前面介绍的引号行为 |
| skipinitialspace |
False |
忽略字段定界符后面的空白符 |
测试实例如下:
import csv
import sys
csv.register_dialect('escaped',
escapechar='\\',
doublequote=False,
quoting=csv.QUOTE_NONE,
)
csv.register_dialect('singlequote',
quotechar="'",
quoting=csv.QUOTE_ALL,
)
quoting_modes = dict((getattr(csv, n), n)
for n in dir(csv)
if n.startswith('QUOTE_'))
for name in sorted(csv.list_dialects()):
print 'Dialect: "%s"\n' % name
dialect = csv.get_dialect(name)
print 'delimiter = %-6r skipinitialspace = %r' % (dialect.delimiter, dialect.skipinitialspace)
print 'doublequote = %-6r quoting = %s' % (dialect.doublequote, quoting_modes[dialect.quoting])
print 'quotechar = %-6r lineterminator = %r' % (dialect.quotechar, dialect.lineterminator)
print 'escapechar = %-6r' % dialect.escapechar
print
writer = csv.writer(sys.stdout, dialect=dialect)
writer.writerow(
('coll', 1, '10/01/2010',
'special chars: "\' %s to parse' % dialect.delimiter)
)
print 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py Dialect: "escaped" delimiter = ',' skipinitialspace = 0 doublequote = 0 quoting = QUOTE_NONE quotechar = '"' lineterminator = '\r\n' escapechar = '\\' coll,1,10/01/2010,special chars: \"' \, to parse Dialect: "excel" delimiter = ',' skipinitialspace = 0 doublequote = 1 quoting = QUOTE_MINIMAL quotechar = '"' lineterminator = '\r\n' escapechar = None coll,1,10/01/2010,"special chars: ""' , to parse" Dialect: "excel-tab" delimiter = '\t' skipinitialspace = 0 doublequote = 1 quoting = QUOTE_MINIMAL quotechar = '"' lineterminator = '\r\n' escapechar = None coll 1 10/01/2010 "special chars: ""' to parse" Dialect: "singlequote" delimiter = ',' skipinitialspace = 0 doublequote = 1 quoting = QUOTE_ALL quotechar = "'" lineterminator = '\r\n' escapechar = None 'coll','1','10/01/2010','special chars: "'' , to parse'
4. 使用字段名
DictReader和DictWriter类将行转换为字典而不是列表。
import csv import sys with open(sys.argv[1], 'rt') as f: reader = csv.DictReader(f) for row in reader: print row解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py testdata.csv
{'hello world': 'i love this world'}
{'hello world': 'and i love python too'}
leichaojian@leichaojian-ThinkPad-T430:~$ cat testdata.csv
hello world
i love this world
and i love python too 必须为DictWriter提供一个字段名列表,使它知道如何在输出中确定列的顺序:
import csv
import sys
with open(sys.argv[1], 'wt') as f:
fieldnames = ('Title 1', 'Title 2', 'Title 3')
headers = dict((n, n) for n in fieldnames)
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(headers)
for i in range(3):
writer.writerow({'Title 1': i + 1,
'Title 2': chr(ord('a') + i),
'Title 3': '08/%02d/07' % (i + 1),
})
print open(sys.argv[1], 'rt').read() 解释器显示如下:
leichaojian@leichaojian-ThinkPad-T430:~$ python test.py testout.csv Title 1,Title 2,Title 3 1,a,08/01/07 2,b,08/02/07 3,c,08/03/07