Android Text Layout 框架
Text Layout,所完成的最主要的功能主要有两点:
- 正确的处理换行的逻辑。
- 对于那些复杂语系,如阿拉伯语,印度语,希伯来语,缅甸语之类的,依据其语言特性,正确的完成变形,对于由右向左显示的那些语言,正确的完成反序。
在android平台下,其Text Layout框架大体上如下图所显示的这样:
可以看到android 的text layout框架也是牵涉甚广,从Java层,到JNI,到library均有一大坨Code。在Java层,主要完成我们前面提到的第一个功能,即换行的逻辑,其Code主要在StaticLayout这个class中(frameworks/base/core/java/android/text/StaticLayout.java)。这个Class在创建的时候,即会完成整个的换行的处理。它实际上会算出每一行字,在传入的字串中的偏移量,字符的个数,Bidi属性,行的Direction等信息,然后存储在一个数组中,以方便后面在执行绘制等操作的时候使用。
完成换行操作的主要依据有两点,1、Unicode Line Breaking Algorithm有规定说,哪两个字之间可以换行,而哪些字之间最好不要换行;2、依据字的宽度,即每一行在保证能够画得下的情况下,要包含尽可能多的字。在创建StaticLayout的时候,会给它传进去一个参数,outerwidth,做为对于一行的宽度的限制。
StaticLayout切行时的逻辑大致上如下面这样:
1、获取子串中每一个字的宽度,称之为advance或width。
2、初始化如下两组变量,用以记录几种情况下可能可以换行的适当的位置:
248 float w = 0; 249 // here is the offset of the starting character of the line we are currently measuring 250 int here = paraStart; 251 252 // ok is a character offset located after a word separator (space, tab, number...) where 253 // we would prefer to cut the current line. Equals to here when no such break was found. 254 int ok = paraStart; 255 float okWidth = w; 256 int okAscent = 0, okDescent = 0, okTop = 0, okBottom = 0; 257 258 // fit is a character offset such that the [here, fit[ range fits in the allowed width. 259 // We will cut the line there if no ok position is found. 260 int fit = paraStart; 261 float fitWidth = w; 262 int fitAscent = 0, fitDescent = 0, fitTop = 0, fitBottom = 0;如注释中所描述的,以ok开头的那一组,记录依据Unicode Line Breaking Algorithm,可以进行换行的位置;以fit开头的那一组,则记录依据行的宽度,能容纳得下的最多的字的位置。
3、逐个的遍历记录字的宽度的数组,将字的宽度加到w上,然后比较这个w值和调用者传进来的宽度的限制。当w值小于这个限制的时,会首先去更新以fit开头的那一组数据,更新之后,在去检测当前的字符的位置依据Unicode Line Breaking Algorithm 是否是合适的换行的位置,若是,则同时要去更新ok开头的那一组值 。w值大于行宽度的限制时,则会将当前的这一行的信息输出, 也就是放在存储结果的那个数组里。 当前这一行的信息,会优先采用ok开头的那一组,但如果那一组没有被更新过,则采用fit开头的那一组, 然后重置ok开头及fit开头的那两组值,以开始计算下一行的相关信息。
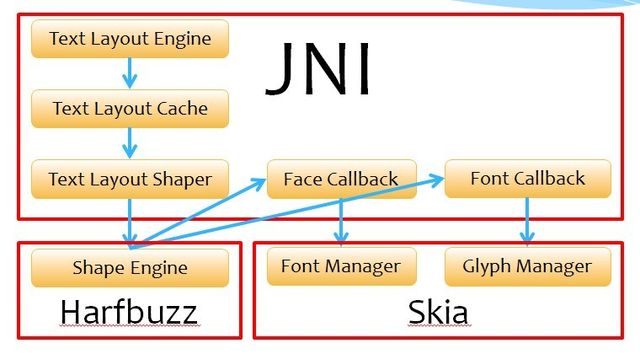
这个地方我们看到,处理换行时,一个比较重要的依据即是每一个字的宽度。复杂语系的cluster,对于阿拉伯语这类RTL字的处理等,使这个问题变得稍微有些复杂。所谓的cluster,即是对于某些复杂语系,如泰语、印度语、缅甸语等,需要放在一起以执行适当的变形规则的一组字。为了使StaticLayout在处理换行的逻辑时,能始终将一个cluster的字放在相同的行里面,StaticLayout所获取的子串中每一个字的宽度值的数组,将需要具有这样的语义:子串的字宽度数组中对应于cluster首字符的位置,需要放上这个cluster shape之后所产生的所有Glyph的advance之和,而对应于相同cluster中其他字符的位置,则均需要放上0值。相关各个结构的关系大致上如下图这样:

这也是前面的图中所显示的JNI和Shape Engine部分存在的最大价值之所在。
JNI这个部分所做的事情(Shape)大致上如下面这样:
- 调用ICU的函数,对传进来的子串做Bidi,将整个字串切分成几个不同方向的子串,每一个子串称为一个 Bidi Run,每一个子串内的字具有相同的方向属性。
- 分别处理每一个Bidi Run。对于一个Bidi Run,会首先调用ICU的函数对它做Normalization(依据字串的上下文,将某些字替换为另外的一些字,如越南语中的一些字符,或者依据Bidi属性,比如RTL,将左括号("(")替换为右括号(")")等)。Normalization的逻辑是在Jelly Bean时加入的,因而在ICS上显示越南语时就会产生一些问题。之后将一个Bidi Run切分成几个Script Run。Script Run可以理解为,它们的Glyph的信息一定会同时都包含在或同时都不包含在同一个字库文件中的一组字,通常情况下就是某一个语系的所有的字等。然后,将一个Script Run的文本传递给Shape Engine,来做shape。所谓Shape,即为依据每一个字出现的上下文,来为这个字找到一个适当的Glyph,对字做适当的变形,确定每一个字的适当的位置等。
- 依据前面所描述的cluster的逻辑,在通过shape engine对Script run 做shape之后,将advances返回给调用者。返回position信息,返回Glyph ID数组等。
在4.0之后的Android平台,Shape Engine为Harfbuzz。这是一个Open Type shape引擎。即它在对字做变形,确定每一个字的适当的位置的时候,主要利用的是OpenType 字库文件里面的一些如GSUB、GPOS等Table所包含的信息。
可以看到,Shape Engine是需要获取每一个字所对应的GlyphID,并且需要获取到GSUB、GPOS这些table的信息的。许多的Shape Engine在这个地方都做了一些抽象,它们将可以获取到Glyph ID的object称为Font,将可以获取到GSUB、GPOS这些table信息的object称为Face。两者的区别在什么地方呢,最终这些信息不都要从字库文件中来获取吗?仔细考虑,我们会发现,Glyph ID暗含有字体大小,倾斜度等信息在里面,即我们其实要获取的是某一字体大小下的Glyph ID,而GPOS这些table的内容,则实实在在是直接从字库文件里面读取的。
那要如何为Harfbuzz创建Face和Font这些结构呢?直觉上,当然是用字库文件创建了。那要如何使用字库文件呢?传字库文件的path进去,Harfbuzz不就可以想怎么搞就怎么搞了嘛。Harfbuzz等shape engine确实提供有类似于这样的方式来创建Face和Font。但通常情况下,各个系统都会有自己的一套进行Glyph管理,和字库文件管理的系统。由于各个系统,都会有一套自己的Glyph管理系统,一些系统特定的抽象,以便于做cache等以优化性能,因而前面所描述的那种做法所获取的Glyph ID,未必能够和系统的Glyph管理系统实现很好的对接。如果不能对得上的话,那乱码就是必然的了。通常情况下,系统本地都会对字库文件有自己的一套抽象,因而使得对于字库文件的访问,没有办法使用直接传path这类简便的方法。同时借助于系统已有的获取字库文件的table的功能,可以给客户端更大的灵活性来针对系统特性做缓存等,以提升性能、优化memory use等。
在android系统中,是将字库文件抽象为SkTypeface,用SkFontHost来作为字库文件管理系统(Font Manager,此处的Font与前面提到Shape Engine时的那个Font具有不一样的含义,此处指字库文件)。而Glyph管理,则是借助于SkPaint、SkGlyphCache、SkScalerContext等来完成。
那究竟要如何对接shape engine和字库管理系统及Glyph管理系统呢?答案就是callback。通过SkTypeface创建Harfbuzz的Face的code像下面这样:
900HB_Face TextLayoutShaper::getCachedHBFace(SkTypeface* typeface) {
901 SkFontID fontId = typeface->uniqueID();
902 ssize_t index = mCachedHBFaces.indexOfKey(fontId);
903 if (index >= 0) {
904 return mCachedHBFaces.valueAt(index);
905 }
906 HB_Face face = HB_NewFace(typeface, harfbuzzSkiaGetTable);
907 if (face) {
908#if DEBUG_GLYPHS
909 ALOGD("Created HB_NewFace %p from paint typeface = %p", face, typeface);
910#endif
911 mCachedHBFaces.add(fontId, face);
912 }
913 return face;
914}
可以看到主要是将SkTypeface的指针及harfbuzzSkiaGetTable函数指针作为参数,来构造HB_Face。SkTypeface的指针将会被作为Face的user data,在Harfbuzz实际需要读取字库文件中的表的时候,它会被传给harfbuzzSkiaGetTable()函数。而harfbuzz所需要的Font的创建,则主要在TextLayoutShaper的构造函数中:
329TextLayoutShaper::TextLayoutShaper() : mShaperItemGlyphArraySize(0) {
330 init();
331
332 mFontRec.klass = &harfbuzzSkiaClass;
333 mFontRec.userData = 0;
334
335 // Note that the scaling values (x_ and y_ppem, x_ and y_scale) will be set
336 // below, when the paint transform and em unit of the actual shaping font
337 // are known.
338
339 memset(&mShaperItem, 0, sizeof(mShaperItem));
340
341 mShaperItem.font = &mFontRec;
342 mShaperItem.font->userData = &mShapingPaint;
343}
创建FontRec时,所传递的为一组Callback harfbuzzSkiaClass,FontRec的user data为SkPaint的实例mShapingPaint,同前面提到的创建HBFace是的情况类似,harfbuzz 在shape的过程中,需要获取和Glyph有关的信息时,会将SkPaint作为user data传给call back。在Script Run的shape时,会更新
mShapingPaint以适应当前的这次shape。
可以随便拿两个callback是的实现来看看,里面究竟在搞些什么东西,harfbuzzSkiaGetTable()函数:
191HB_Error harfbuzzSkiaGetTable(void* font, const HB_Tag tag, HB_Byte* buffer, HB_UInt* len)
192{
193 SkTypeface* typeface = static_cast<SkTypeface*>(font);
194
195 if (!typeface) {
196 ALOGD("Typeface cannot be null");
197 return HB_Err_Invalid_Argument;
198 }
199 const size_t tableSize = SkFontHost::GetTableSize(typeface->uniqueID(), tag);
200 if (!tableSize)
201 return HB_Err_Invalid_Argument;
202 // If Harfbuzz specified a NULL buffer then it's asking for the size of the table.
203 if (!buffer) {
204 *len = tableSize;
205 return HB_Err_Ok;
206 }
207
208 if (*len < tableSize)
209 return HB_Err_Invalid_Argument;
210 SkFontHost::GetTableData(typeface->uniqueID(), tag, 0, tableSize, buffer);
211 return HB_Err_Ok;
212}
harfbuzzSkiaClass
的convertStringToGlyphIndices callback stringToGlyphs()函数:
50static HB_Bool stringToGlyphs(HB_Font hbFont, const HB_UChar16* characters, hb_uint32 length,
51 HB_Glyph* glyphs, hb_uint32* glyphsSize, HB_Bool isRTL)
52{
53 SkPaint* paint = static_cast<SkPaint*>(hbFont->userData);
54 paint->setTextEncoding(SkPaint::kUTF16_TextEncoding);
55
56 uint16_t* skiaGlyphs = reinterpret_cast<uint16_t*>(glyphs);
57 int numGlyphs = paint->textToGlyphs(characters, length * sizeof(uint16_t), skiaGlyphs);
58
59 // HB_Glyph is 32-bit, but Skia outputs only 16-bit numbers. So our
60 // |glyphs| array needs to be converted.
61 for (int i = numGlyphs - 1; i >= 0; --i) {
62 glyphs[i] = skiaGlyphs[i];
63 }
64
65 *glyphsSize = numGlyphs;
66 return 1;
67}
可以看到,是强制类型转换的巧妙的应用,使得Harfbuzz和Skia完成了对接。