Rhel6-hadoop分布式部署配置文档
理论基础:
Hadoop 分布式文件系统架构
HDFS 负责大数据存储
MapReduce 负责大数据计算
namenode master守护进程
datanode slaves上负责存储的进程
secondarynamenode master上提供周期检查和清理任务的进程
jobtracker master上负责调度datanode上工作的进程
tasktracker slaves上负责计算的进程
Hadoop 主从节点分解:
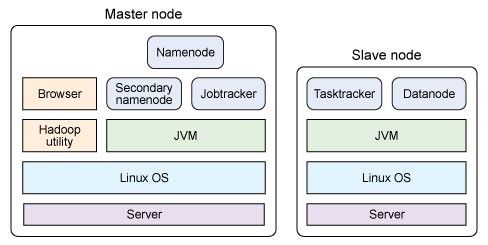
主节点包括名称节点、从属名称节点和jobtracker守护进程(即所谓的主守护进程)以及管理集群所用的实用程序和浏览器。从节点包括tasktracker和数据节点(从属守护进程)。两种设置的不同之处在于,主节点包括提供Hadoop集群管理和协调的守护进程,而从节点包括实现Hadoop文件系统(HDFS)存储功能和MapReduce功能(数据处理功能)的守护进程。
每个守护进程在Hadoop框架中的作用。namenode是Hadoop中的主服务器,它管理文件系统名称空间和对集群中存储的文件的访问。还有一个secondary namenode,它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。在每个Hadoop集群中可以找到一个namenode和一个secondarynamenode。
datanode管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
每个集群有一个jobtracker,它负责调度datanode上的工作。每个 datanode有一个tasktracker,它们执行实际工作。jobtracker和tasktracker 采用主-从形式,jobtracker跨datanode分发工作,而tasktracker执行任务。jobtracker还检查请求的工作,如果一个datanode由于某种原因失败,jobtracker 会重新调度以前的任务。
配置:
系统环境: rhel6 x86_64 iptables and selinux disabled
主机: 192.168.122.112 server12.example.com Master 192.168.122.234 server34.example.com Slave
192.168.122.20 server20.example.com Slave
注:所有主机间时间需同步,并实现无密码认证
所需的包: hadoop-1.1.2.tar.gz
相关网址:http://hadoop.apache.org/
#在所有节点上安装jdk
[root@server12 ~]# sh jdk-6u32-linux-x64.bin
[root@server12 ~]# tar zxf hadoop-1.1.2.tar.gz -C /usr/local/
[root@server12 ~]# mv jdk1.6.0_32/ /usr/local/hadoop-1.1.2/jdk
[root@server12 ~]# vim /etc/profile
export JAVA_HOME=/usr/local/hadoop-1.1.2/jdk
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
[root@server12 ~]# source /etc/profile
生产环境中建议建立一个普通用户来实施以下操作,本文档直接用root用户执行
Standalone Operation
以下步骤在server12上实施:
[root@server12 hadoop-1.1.2]# mkdir dir1
[root@server12 hadoop-1.1.2]# cp conf/* dir1/
[root@server12 hadoop-1.1.2]# bin/hadoop jar hadoop-examples-1.1.2.jar grep dir1/ dir2/ 'dfs[a-z.]+'
[root@server12 hadoop-1.1.2]# cat dir2/*
1 dfs.server.namenode.
1 dfsadmin
注:出现类似如上输出说明成功
Pseudo-Distributed Operation(伪分布式)
以下步骤在server12上实施:
[root@server12 ~]# cd /usr/local/hadoop-1.1.2/conf/
[root@server12 conf]# vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.122.112:9000</value> #指定 namenode
</property>
</configuration>
[root@server12 conf]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name> #指定文件保存的副本数
<value>1</value>
</property>
</configuration>
[root@server12 conf]# vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name> #指定 jobtracker
<value>192.168.122.112:9001</value>
</property>
</configuration>
[root@server12 conf]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/hadoop-1.1.2/jdk (此JAVA_HOME路径跟安装jdk时候指定的JAVA_HOME一致)
#建立ssh无密码登录
[root@server12 conf]# ssh-keygen (一路回车即可)
[root@server12 conf]# ssh-copy-id localhost
[root@server12 conf]# cd /usr/local/hadoop-1.1.2/
[root@server12 hadoop-1.1.2]# bin/hadoop namenode -format
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = server12.example.com/192.168.122.112
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.1.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013
************************************************************/
13/12/01 15:49:39 INFO util.GSet: VM type = 64-bit
13/12/01 15:49:39 INFO util.GSet: 2% max memory = 19.33375 MB
13/12/01 15:49:39 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/12/01 15:49:39 INFO util.GSet: recommended=2097152, actual=2097152
13/12/01 15:49:39 INFO namenode.FSNamesystem: fsOwner=root
13/12/01 15:49:39 INFO namenode.FSNamesystem: supergroup=supergroup
13/12/01 15:49:39 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/12/01 15:49:39 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/12/01 15:49:39 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/12/01 15:49:39 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/12/01 15:49:40 INFO common.Storage: Image file of size 110 saved in 0 seconds.
13/12/01 15:49:40 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/tmp/hadoop-root/dfs/name/current/edits
13/12/01 15:49:40 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/tmp/hadoop-root/dfs/name/current/edits
13/12/01 15:49:40 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
13/12/01 15:49:40 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server12.example.com/192.168.122.112
************************************************************/
注:出现类似如上输出为正常
[root@server12 hadoop-1.1.2]# bin/start-all.sh
[root@server12 hadoop-1.1.2]# jps
2065 NameNode
2164 DataNode
2346 JobTracker
2262 SecondaryNameNode
2448 TaskTracker
注:出现类似如上5个进程说明启动成功.
此时访问192.168.122.112:50070和192.168.122.112:50030可分别看到如下页面:

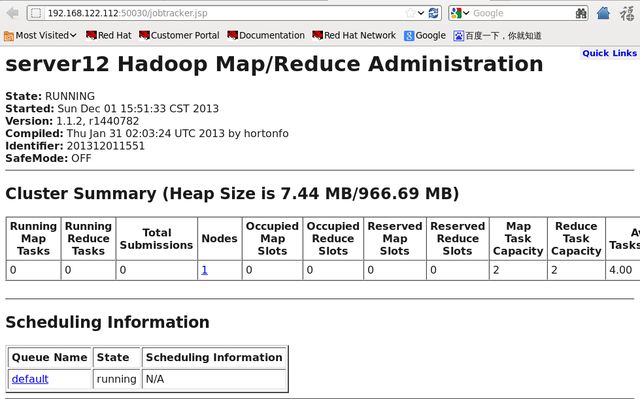
测试:
[root@server12 hadoop-1.1.2]# mkdir input
[root@server12 hadoop-1.1.2]# cp conf/* input/
[root@server12 hadoop-1.1.2]# bin/hadoop fs -mkdir dir1
[root@server12 hadoop-1.1.2]# bin/hadoop fs -ls
Found 1 items
drwxr-xr-x - root supergroup 0 2013-12-01 15:57 /user/root/dir1
[root@server12 hadoop-1.1.2]# bin/hadoop fs -put input/* dir1
[root@server12 hadoop-1.1.2]# bin/hadoop fs -ls dir1 (列出分布式文件系统dir1中的内容)
[root@server12 hadoop-1.1.2]# bin/hadoop jar hadoop-examples-1.1.2.jar grep dir1 dir2 'dfs[a-z.]+'
[root@server12 hadoop-1.1.2]# bin/hadoop fs -cat dir2/*
cat: ouput/_logs: Is a directory
1 dfs.server.namenode.
1 dfsadmin
[root@server12 hadoop-1.1.2]# bin/hadoop fs -get dir2 output (将分布式文件系统中的文件导出到本地的output文件夹中)
[root@server12 hadoop-1.1.2]# cat output/*
cat: ouput/_logs: Is a directory
1 dfs.server.namenode.
1 dfsadmin
Fully-Distributed Operation(分布式)
以下步骤在server12上实施:
[root@server12 ~]# cd /usr/local/hadoop-1.1.2/conf/
[root@server12 conf]# vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.122.112:9000</value> #指定 namenode
</property>
</configuration>
[root@server12 conf]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name> #指定文件保存的副本数
<value>2</value>
</property>
</configuration>
[root@server12 conf]# vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name> #指定 jobtracker
<value>192.168.122.112:9001</value>
</property>
</configuration>
[root@server12 conf]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/hadoop-1.1.2/jdk (此JAVA_HOME路径跟安装jdk时候指定的JAVA_HOME一致)
[root@server12 conf]# vim masters
192.168.122.112 #指定master节点的IP
[root@server12 conf]# vim slaves
192.168.122.234 #指定slave节点的IP
192.168.122.20
[root@server12 conf]# scp -r /usr/local/hadoop-1.1.2/ [email protected]:/usr/local/
[root@server12 conf]# scp -r /usr/local/hadoop-1.1.2/ [email protected]:/usr/local/
[root@server12 conf]# scp /etc/profile [email protected]:/etc/
[root@server12 conf]# scp /etc/profile [email protected]:/etc/
以下步骤在server34和server20上实施:
[root@server34 ~]# source /etc/profile
#建立ssh无密码登录
[root@server12 conf]# ssh-keygen (一路回车即可)
[root@server12 conf]# ssh-copy-id 192.168.122.234
[root@server12 conf]# ssh-copy-id 192.168.122.20
[root@server12 conf]# cd /usr/local/hadoop-1.1.2/
[root@server12 hadoop-1.1.2]# bin/hadoop namenode -format
13/12/01 17:10:42 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = server12.example.com/192.168.122.112
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.1.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013
********13/12/01 17:10:45 INFO util.GSet: VM type = 64-bit
13/12/01 17:10:45 INFO util.GSet: 2% max memory = 19.33375 MB
13/12/01 17:10:45 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/12/01 17:10:45 INFO util.GSet: recommended=2097152, actual=2097152
13/12/01 17:10:45 INFO namenode.FSNamesystem: fsOwner=root
13/12/01 17:10:45 INFO namenode.FSNamesystem: supergroup=supergroup
13/12/01 17:10:45 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/12/01 17:10:45 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/12/01 17:10:45 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/12/01 17:10:45 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/12/01 17:10:46 INFO common.Storage: Image file of size 110 saved in 0 seconds.
13/12/01 17:10:46 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/tmp/hadoop-root/dfs/name/current/edits
13/12/01 17:10:46 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/tmp/hadoop-root/dfs/name/current/edits
13/12/01 17:10:46 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
13/12/01 17:10:46 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server12.example.com/192.168.122.112
************************************************************/ ****************************************************/
注:出现类似如上输出为正常
[root@server12 hadoop-1.1.2]# bin/start-all.sh
[root@server12 hadoop-1.1.2]# jps
5385 NameNode
5526 SecondaryNameNode
5612 JobTracker
注:在master节点上查看到如上3个进程说明启动成功.
[root@server34 ~]# jps
1942 TaskTracker
1873 DataNode
注:在每个slave节点上查看到如上2个进程说明启动成功.
此时访问192.168.122.112:50070和192.168.122.112:50030可分别看到如下页面:


测试:仿照伪分布式的测试方式即可
Hadoop 在线添加节点:
1. 在新增节点上安装jdk,并创建相同的hadoop用户,uid等保持一致
2. 在conf/slaves文件中添加新增节点的ip
3. 同步master上hadoop所有数据到新增节点上,路径保持一致
4. 在新增节点上启动服务:
# bin/hadoop-daemon.sh start datanode
# bin/hadoop-daemon.sh start tasktracker
5. 均衡数据:
# bin/start-balancer.sh
1)如果不执行均衡,那么cluster会把新的数据都存放在新的datanode上,这样会降低mapred的工作效率
2)设置平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长
# bin/start-balancer.sh -threshold 5
Hadoop 在线删除 datanode 节点:
1. 在master上修改conf/mapred-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/datanode-excludes</value>
</property>
2. 创建datanode-excludes文件,并添加需要删除的主机,一行一个
192.168.122.77
3. 在master上在线刷新节点
# bin/hadoop dfsadmin -refreshNodes
此操作会在后台迁移数据,等此节点的状态显示为Decommissioned,就可以安全关闭了。
4. 你可以通过以下命令查看 datanode 状态
# bin/hadoop dfsadmin -report
在做数据迁移时,此节点不要参与 tasktracker,否则会出现异常。
Hadoop 在线删除 tasktracker 节点:
1. 在master上修改conf/mapred-site.xml
<property>
<name>mapred.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/tasktracker-excludes</value>
</property>
2. 创建tasktracker-excludes文件,并添加需要删除的主机名,一行一个
192.168.122.77
3. 在master上在线刷新节点
# bin/hadoop mradmin -refreshNodes
4. 登录 jobtracker 的网络接口,进行查看。