OpenType™ Layout通用表格式
Justification表 (JSTF),和Glyph定义表(GDEF)。这些表使用了一些相同的数据格式。
本章将解释一下在所有的OpenType Layout表中都会用到的约定(conventions ),并描述一下通用表格式。另外的章节会提供关于 GSUB,GPOS,BASE,JSTF和GDEF表,完整而详细的信息。
概览
OpenType Layout表为适当的定位和置换glyphs提供了排版信息,及许多语言环境下精确排版所需的操作(operations)。Script,language system,排版feature,和lookup组织而成了OpenType Layout数据。
Scripts定义在最顶层。一个script是用于以书写形式表现一个或多个语言的一些glyphs(参见Figure 2a)。比如,一个script-Latin-用来书写英语,法语,德语,和许多其他的语言。与此相反,三个scripts-Hiragana,Katakana和Kanji-用来书写日语。通过OpenType Layout,多个script也可以用单独一个字库来支持。

Figure 2a. Latin,Kanji和Arabic scripts里的Glyph
一个language system可能会修改一个script中的glyphs的功能或者外观以表现一个特定的语言。比如,德语language system中使用了eszet连字符,但法语和英语中则没有使用(参见Figure 2b)。Arabic script为书写波斯语和乌尔都语languages而包含有不同的glyphs。在OpenType Layout中,language systems是在script内定义的。
Figure 2b. English,French和German language systems的不同之处
一个language system定义了features,它们是使用glyphs来表现一个语言的排版规则。比如“vert” feature,用于在日语中置换垂直的glyphs, “liga” feature用来协助完成使用连字符对分开的多个glyphs的置换操作,“mark” feature用来在阿拉伯语中调整音节符号相对于基glyphs的位置(参见Figure 2c)。在缺少特定于语言的规则的情况下,则默认的language system features应用于整个script。比如Arabic script的一个默认的language system feature,基于一个glyph在单词中的位置,来置换字首的,字中的和字尾的glyph形式。
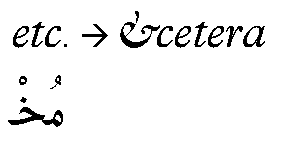
Figure 2c. A ligature glyph feature substitutes the <etc> ligature for individual glyphs, and a mark feature positions diacritical marks above an Arabic ligature glyph.
Features通过lookup数据来实现,文字处理客户端会使用这些数据来置换和定位glyphs。Lookups描述了一个操作会影响到的glyphs,应用于这些glyphs的操作的类型,及作为结果输出的glyph。
表的组织
两种OpenType Layout表,GSUB和GPOS,使用相同的数据格式来描述glyphs的排版功能,及他们支持的language和scripts:一个ScriptList表,一个FeatureList和一个LookupList表。在GSUB中,那些表定义了glyph置换数据。在GPOS中,他们则定义了glyph定位数据。本章将会描述这些通用的表格式。
ScriptList确定了一个字库中的scripts,其中每个script由一个包含有script和language-system数据的Script表来描绘。Language system表引用features,这些features则定义在FeatureList中。每一个feature表引用lookup数据,而lookup 数据则定义在LookupList中,并且描述了如何,何时,及何地来实现那个feature。
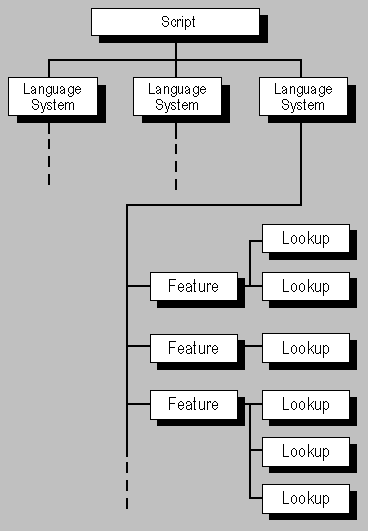
Figure 2d. 置换表和定位表的scripts,language systems,features,和lookups的关系
注意: 和JSTF表中的数据也由script和language system组织而成。然而,其数据格式则与GSUB和GPOS中的不同,而且他们不包含有一个FeatureList或者LookupList。BASE和JSTF数据格式在BASE和JSTF章节中有描述。
用于置换和定位glyphs的信息在Lookup子表中定义。依赖于lookup是否是GSUB或者GPOS表的一部分,每一个子都表提供了一种类型的信息。比如,一个GSUB lookup可能详细说明了将被置换的glyphs及置换发生的上下文,而一个GPOS lookup则可能详述为kerning而做的glyph 位置调整。OpenType Layout具有7种类型的GSUB lookups(在GSUB一章中详述),及9种类型的GPOS lookups(在GPOS一章中描述)。
每个子表(除了一个扩展LookupType子表外)包含一个Coverage表,其中列出了引起一个glyph置换或定位操作的glyphs。Coverage表的格式将在本章中描述。
一些置换或定位操作可能会应用于glyphs的群组或类别。GSUB和GPOS Lookup子表使用Class Definition表来给glyphs分配类别。本章包含一个对于Class Definition表的格式的描述。
Lookup子表也可能包含设备表,将会在本章中描述,来为特定的输出大小和分辨率调整放缩轮廓glyph的坐标。本章也会描述OpenType Layout中使用的数据类型。在本章的末尾会提供一些用于说明通用数据格式的示例的表和列表。
Scripts和Languages
三种表及他们相关的表记录适用于scripts和languages:Script List表(ScriptList)和它的script记录(ScriptRecord),Script表和它的language system记录(LangSysRecord)和Language System表(LangSys)。
Script List 表和Script记录
OpenType Layout字库可能包含一个或多个glyphs的群组,用于渲染多种scripts,这些scripts在一个ScriptList中枚举出来。GSUB和GPOS表都定义有Script List表(ScriptList):
- GSUB表使用ScriptList表来访问应用于一个script的glyph置换features。更多详情,请参考, Glyph置换表(GSUB)这一章。
- GPOS表使用ScriptList表来访问应用于一个script的glyph定位features。更多详情,请参考, Glyph定位表(GSUB)这一章。
一个ScriptList表包含有字库中的glyphs将会表现的scripts的个数(ScriptCount),及一个记录的数组(ScriptRecord),字库中定义有script-specific features的script每个一个数组项(一个没有script-specific feature的script不需要一个ScriptRecord)。
如果ScriptList表中出现了一个script tag为'DFLT'(默认)的Script表,则它必须具有一个非空的DefaultLangSys,而且其LangSysCount 必须等于0。被格式化的script没有一个明确的项时,应该使用'DFLT' Script表。
ScriptRecord数组是以标识script的一个ScriptTag的字母顺序来存储记录的。每一个ScriptRecord由一个ScriptTag和一个Script表偏移组成。
本章结尾的例子1显示了一个使用了3个script的日语字库的 ScriptList表和ScriptRecords.
ScriptList table
| Type | Name | Description |
|---|---|---|
| uint16 | ScriptCount | ScriptRecords的个数 |
| struct | ScriptRecord [ScriptCount] |
ScriptRecords的数组 -依据ScriptTag的字母顺序列出 |
ScriptRecord
| Type | Name | Description |
|---|---|---|
| Tag | ScriptTag | 4-byte ScriptTag 标识符 |
| Offset | Script | 到Script表的偏移-自ScriptList的起始位置算起 |
Script 表和Language System记录
一个Script表确定了每个language system,而language system定义了如何为一个特定的语言使用一个script的glyphs。它也引用了一个默认的language system,其中定义了缺少关于特定语言的知识的情况下如何使用script的glyph的方法。
一个Script表以一个到默认的Language System表(DefaultLangSys)的偏移量开始,其中定义了管理script的默认行为的feature的集合。接下来是,Language System Count (LangSysCount)定义了使用了script的language systems的个数(DefaultLangSys除外)。此外,一个Language System Records(LangSysRecord)数组定义了每个language system(除了默认的),其中每个language system通过一个标识tag(LangSysTag)和一个到Language System表(LangSys)的偏移来定义。LangSysRecord 数组以LangSysTag的字母顺序来存储记录。
如果没有定义language-specific script行为,则LangSysCount 被设为0,并且不分配LangSysRecords。
Script table
| Type | Name | Description |
|---|---|---|
| Offset | DefaultLangSys | 到DefaultLangSys表的偏移-从Script表的起始位置算起-可能为null |
| uint16 | LangSysCount | 这个script的LangSysRecords的个数-DefaultLangSys除外 |
| struct | LangSysRecord [LangSysCount] |
LangSysRecords的数组-以LangSysTag的字母顺序列出 |
LangSysRecord
| Type | Name | Description |
|---|---|---|
| Tag | LangSysTag | 4-byte LangSysTag 标识符 |
| Offset | LangSys | 到LangSys表的偏移-自Script表的起始位置算起 |
Language System表
Language System表 (LangSys)确定了用于渲染一个script中的glyph的language-system features。(LookupOrder偏移保留用于未来使用。)
可选地,一个LangSys定义一个Required Feature Index (ReqFeatureIndex)来指定一个feature,作为一个特定的language system上下文中必须的feature。比如,在Cyrillic script中,Serbian language system总是以一种不同于Russian language system的方式来渲染某些glyphs。
只有一个feature索引值可以被标记为ReqFeatureIndex。然而,这不是一个功能限制,由于OpenType Layout中的feature和lookup定义是结构化的,因而一个feature表可以引用许多的glyph置换或者定位lookups。当没有定义必须的feature时,则ReqFeatureIndex被设为0xFFFF。
所有其他的feature都是可选的。对于每一个可选的feature,一个基于0的索引值引用了一个存储于Feature List表(FeatureList)的FeatureRecord 数组中的记录(FeatureRecord)。在FeatureIndex中,feature索引本身(除ReqFeatureIndex外)是以优先级顺序存储的。FeatureCount描述了FeatureIndex 数组中列出的features的总个数。
Feature是的完整的描述在FeatureList表,FeatureRecord和Feature 表中,他们将会在本章稍后的部分介绍。本章结尾处的例子2显示了一个用于在Arabic script中进行上下文的定位的Script表,LangSysRecord和LangSys表。
LangSys table
| Type | Name | Description |
|---|---|---|
| Offset | LookupOrder | = NULL (reserved for an offset to a reordering table) |
| uint16 | ReqFeatureIndex | Index of a feature required for this language system- if no required features = 0xFFFF |
| uint16 | FeatureCount | Number of FeatureIndex values for this language system-excludes the required feature |
| uint16 | FeatureIndex[FeatureCount] | Array of indices into the FeatureList-in arbitrary order |
Features和Lookups
Features 定义了OpenType Layout字库的功能,他们都有一个有意义的名字,以便于向文字处理客户端传递一定的含义。考虑一个名称为“liga”的feature,它被用于创建连字符。由于它的名字,客户端而了解到feature是做什么的,并可以确定是否应用它。更多信息,请参考“OpenType Layout Registered Features”一章。字库创建者可以使用这些features,也可以创建他们自己的。在选中了使用哪些features之后,客户端收集来自于选中的features的所有的lookups。多个lookups可能被用于为不同的置换和定位行为定义所需的数据,也可能被用于控制那些行为的顺序和效果。
为了实现features,一个客户端以LookupList中定义lookups的顺序来应用这些lookups。作为结果,在GSUB或者GPOS表中,在文字处理的过程中,来自于不同的features可能会被交替应用。当客户端定位了一个目标glyph或glyph上下文,并执行了一个置换(如果描述了的话)或者一个定位(如果描述了的话)的话,一个lookup就结束了。
注意:置换(GSUB) lookups总是在定位(GPOS) lookups之前发生。TrueType中的lookup 定序机制依赖于字库,并用于决定文本处理操作的适当的顺序。
Lookup数据定义在一个或多个子表中,其中子表里包含有关于特定的glyph及将会在这些glyphs上执行的操作的信息。每一中类型的lookup具有一个或多个对应的子表定义。一个子表的格式的选择依赖于两个因素:将被应用于一个操作的信息的精确内容,和所需要的存储效率。(关于所有的lookup 类型及子表的完整定义,请参考本文档的GSUB和GPOS章节。)
OpenType Layout features定义了字库中glyphs布局所需的特定信息。他们不编码一个特别的script的特别的语言或排版中常规上固定不变的信息。一个给定的语言的所有的字库间将重复出现的信息属于那个语言的文字处理程序,而不是字库。
Feature List表
GSUB和GPOS表的表头包含有到Feature List表(FeatureList)的偏移,其中Feature List表枚举了一个字库中所有的features。一个特定的FeatureList中的Features不限于任何单一的script。一个FeatureList中包含有用于渲染字库中所有scripts的glyphs的GSUB或GPOS features的完整列表。FeatureList表在一个记录(FeatureRecord)的数组中枚举features,并说明了features的总个数(FeatureCount)。每一个feature必须有一个FeatureRecord,其中FeatureRecord由一个标识了feature的FeatureTag和一个到Feature表(下面描述)的偏移量组成。FeatureRecord数组是按FeatureTag名字的字母顺序来安排的。
注意:一个LangSys表的FeatureIndex数组中所存储的值是被用来定位一个FeatureList表的FeatureRecord数组中的记录的。
FeatureList table
| Type | Name | Description |
|---|---|---|
| uint16 | FeatureCount | Number of FeatureRecords in this table |
| struct | FeatureRecord[FeatureCount] | Array of FeatureRecords-zero-based (first feature has FeatureIndex = 0)-listed alphabetically by FeatureTag |
FeatureRecord
| Type | Name | Description |
|---|---|---|
| Tag | FeatureTag | 4-byte feature identification tag |
| Offset | Feature | Offset to Feature table-from beginning of FeatureList |
Feature表
一个Feature表定义了一个具有一个或多个lookups的feature。客户端使用lookups来置换或定位glyphs。
GSUB表中定义的Feature表包含有到glyph置换lookups的引用,而GPOS表中定义的feature表包含有到glyph定位lookups的引用。如果一个文字处理操作同时需要glyph置换和定位,则GSUB和GPOS表中必须各定义一个Feature表,并且这两个表必须使用相同的FeatureTags。
一个Feature表由一个指向了Feature参数(FeatureParams)表的偏移(如果为这个feature定义了一个的话 - 参见下面的段落中的说明),feature的lookups个数(LookupCount),和一个按优先级顺序排列的指向了LookupList(LookupListIndex)里的索引的数组组成。LookupList索引是指向了 到Lookup表的偏移量的数组 里的引用。
Feature参数表的格式是特定于一个feature的,并且必须在OpenType Layout Tag Registry的Feature Tags部分中feature的项里描述。Feature参数表的长度必须隐式地或显式地在Feature参数表中描述。Feature表中FeatureParams成员记录了相对于Feature表起始处的偏移。如果不需要一个Feature参数表,则FeatureParams成员必须被设为NULL。
为了识别一个GSUB或GPOS表中的features,一个文字处理客户端会读取一个给定的LangSys表中所引用的每一个FeatureRecord的FeatureTag。然后选择它想要实现的features,并使用LookupList来提取选中的features的Lookup索引值。接下来,客户端以LookupList顺序来安排这些索引。最后,客户端应用lookup数据来置换或定位glyphs。本章结尾处的示例3显示了用于置换两种语言里的连字符的FeatureList和Feature表。
Feature table
| Type | Name | Description |
|---|---|---|
| Offset | FeatureParams | = NULL (reserved for offset to FeatureParams) |
| uint16 | LookupCount | Number of LookupList indices for this feature |
| uint16 | LookupListIndex [LookupCount] |
Array of LookupList indices for this feature -zero-based (first lookup is LookupListIndex = 0) |
Lookup List表
GSUB和GPOS表的表头包含有到Lookup List表(LookupList)的偏移,其中Lookup List表用于glyph置换(GSUB表)和glyph定位(GPOS表)。LookupList表包含有一个指向Lookup表(Lookup)的偏移量的数组。字库开发者在Lookup数组中以一定的顺序来定义Lookup,以此来控制一个文字处理客户端应用lookup数据来执行glyph置换和定位操作的顺序。LookupCount说明了数组中的Lookup表偏移量的总个数。本章末尾处的示例4显示了LookupList表中的三个连字符lookups。
LookupList table
| Type | Name | Description |
|---|---|---|
| uint16 | LookupCount | Number of lookups in this table |
| Offset | Lookup[LookupCount] | Array of offsets to Lookup tables-from beginning of LookupList -zero based (first lookup is Lookup index = 0) |
Lookup表
一个Lookup表(Lookup)定义了用于实现一个feature的一个置换或定位行为的特定的条件,类型和结果。比如,一个置换操作需要一个被替换的目标glyph索引的列表,一个替换的glyphs索引的列表,和一个替换行为的类型的描述。
由lookup是否是一个GSUB或GPOS表的一部分决定,每个Lookup表可能只包含一种类型的信息(LookupType)。GSUB支持吧中LookupTypes,GPOS支持九中LookupTypes(关于LookupTypes的详细信息,参见本文档的GSUB和GPOS章节)。
每一个LookupType通过一个或多个子表来定义,而且每一个子表的定义提供了一种不同的表现格式。格式由一个操作所需的信息的内容和所需的存储效率决定。当glyph信息的以多余一种的格式表示做好时,一个单独的lookup可能包含多余一个的子表,只要所有的子表具有相同的LookupType。比如,一个给定的lookup中,一个glyph索引数组用于表示目标glyphs的一个集合可能最好,而对于另一个目标glyphs的集合可能glyph索引范围格式更好。
在文字处理过程中,一个客户端在移向下一个lookup之前,会为字串中的每一个glyph应用一个lookup。在客户端执行了置换/定位操作之后,则对于一个glyph的lookup即结束。为了移向“下一个” glyph,典型地,客户端会跳过所有参与了lookup操作的glyphs:被替换/定位的glyphs,还有为操作的形成了一个上下文的任何其他glyphs。然而,成对定位操作(比如,kerning)的情况下,一个序列中的“下一个”glyph可能是被定位的对的第二个glyph(更多详情请参考成对定位lookup)。
一个Lookup表包含一个LookupType,由一个整数来描述,,定义了lookup中存储的信息的类型。LookupFlag描述了帮助一个文字处理客户端置换或定位glyphs的lookup修饰。SubTableCount说明了SubTable的总个数。SubTable数组描述了偏移量,由Lookup表的开始处计算,每个SubTable都在SubTable数组中枚举出来。
Lookup table
| Type | Name | Description |
|---|---|---|
| uint16 | LookupType | Different enumerations for GSUB and GPOS |
| uint16 | LookupFlag | Lookup qualifiers |
| uint16 | SubTableCount | Number of SubTables for this lookup |
| Offset | SubTable [SubTableCount] |
Array of offsets to SubTables-from beginning of Lookup table |
| unit16 | MarkFilteringSet | Index (base 0) into GDEF mark glyph sets structure. This field is only present if bit UseMarkFilteringSet of lookup flags is set. |
LookupFlag使用两字节的数据:
- 首四位中的每一位都可以被设置来描述一些对一个glyph串应用一个lookup的额外的信息。LookupFlag枚举表提供了关于这些位的使用的详细信息。
- 第五位表示Lookup表中的MarkFilteringSet成员的存在。
- 接下来的三位保留,留给未来使用。
- 高位字节设置用于说明mark attachment的类型。
LookupFlag bit enumeration
| Type | Name | Description |
|---|---|---|
| 0x0001 | RightToLeft | This bit relates only to the correct processing of the cursive attachment lookup type (GPOS lookup type 3). When this bit is set, the last glyph in a given sequence to which the cursive attachment lookup is applied, will be positioned on the baseline. Note: Setting of this bit is not intended to be used by operating systems or applications to determine text direction. |
| 0x0002 | IgnoreBaseGlyphs | If set, skips over base glyphs |
| 0x0004 | IgnoreLigatures | If set, skips over ligatures |
| 0x0008 | IgnoreMarks | If set, skips over all combining marks |
| 0x0010 | UseMarkFilteringSet | If set, indicates that the lookup table structure is followed by a MarkFilteringSet field. The layout engine skips over all mark glyphs not in the mark filtering set indicated. |
| 0x00E0 | Reserved | For future use (Set to zero) |
| 0xFF00 | MarkAttachmentType | If not zero, skips over all marks of attachment type different from specified. |
IgnoreBaseGlyphs,IgnoreLigatures或者IgnoreMarks引用了GDEF表中Glyph Class Definition表中定义的base glyph,连字符(ligatures)和marks。如果这些标记中的任何一个被设置了,则必须有一个Glyph Class Definition表出现。如果这些标记中的任何一个被设置了,则lookups必须忽略具有各自类型的glyphs;即,必须像这些glyphs没有出现一样处理其他的glyphs。
如果MarkAttachmentType非零,则GDEF表中的Mark Attachment Class Definition表中必须定义mark attachment类别。当处理glyph序列时,一个lookup必须忽略不在指定的mark attachment类别里的任何的mark glyphs;只处理特定类型的marks。
如果任何lookup设置了UseMarkFilteringSet标记,则Lookup头必须包含MarkFilteringSet成员,并且GDEF表中必须要有一个MarkGlyphSetsTable。lookup必须忽略任何不属于指定的mark glyph集合的mark glyphs;而只处理特定的mark glyph集合中的glyphs。
如果指定了一个mark filtering集合,这将代替lookup标记中的任何的mark attachment type 指示。如果设置了IgnoreMarks位,这将代替任何的mark filtering集合或者mark attachment type 指示。
比如,在Arabic文本中,一个字符串可能具有模式base mark base。那个字串可能被转换为一个由两个部分组成的连字符,每个base字符一个,combining mark glyph则在第一个组件上。为了产生这个连字符,字库开发者将设置连字符置换lookup的IgnoreMarks位,来告诉客户端忽略mark,先置换连字符glyph,然后通过后来的GPOS lookup数据定位mark glyph。另外,一个没有设置IgnoreMarks位的lookup可以被用于描述一个三组件的连字符glyph,由第一个base glyph,mark glyph,和第二个base glyph组成。
另外的一个例子,用于创建带有一个top mark的base glyph连字符的lookup,可以通过设定mark attachment类型为只包含top marks的类别而跳过所有的bottom marks。
Coverage表
一个lookup中的每个子表(除了扩展LookupType子表外)引用一个Coverage表(Coverage),该表详述了子表中所描述的一个置换或定位操作所影响到的所有的glyphs。GSUB,GPOS和GDEF表均依赖于这个coverage的概念。如果一个glyph没有出现在一个Coverage表中,则客户端可跳过那个子表,并立即移向下一个子表。
一个Coverage表以两种方式通过glyph 索引(GlyphIDs)来描述glyphs:
- 以glyph集合中的独立的glyph索引的列表的形式。
- 以连续索引的范围的形式。范围的格式给出了一个起始glyph和结束glyph索引对的数字来表示表所覆盖的连续的glyphs。
在一个Coverage表中,一个格式码(CoverageFormat)以一个整数的形式说明了格式:1 = 列表,而2 = 范围。
一个Coverage表为每一个覆盖的glyph定义了一个唯一的索引值(CoverageIndex)。这个唯一的值说明了Coverage表中覆盖的glyph的位置。客户端使用Coverage Index来在子表中为每一个glyph查找值。
Coverage格式1
Coverage格式1由一个格式码(CoverageFormat),所覆盖的glyphs的个数(GlyphCount),后接一个glyph索引的数组(GlyphArray)组成。glyph索引的排列必须是数值顺序的,以方便列表的二分搜索。当在Coverage表中发现了一个glyph时,则它在GlyphArray中的位置决定了返回的Coverage Index-第一个glyph的Coverage Index = 0,最后一个glyph的Coverage Index = GlyphCount - 1.
本章末尾处的示例5显示了一个Coverage表,它使用了格式1来列出字库中所有的lowercase descender glyphs的GlyphIDs。
CoverageFormat1 table: Individual glyph indices
| Type | Name | Description |
|---|---|---|
| uint16 | CoverageFormat | Format identifier-format = 1 |
| uint16 | GlyphCount | Number of glyphs in the GlyphArray |
| GlyphID | GlyphArray[GlyphCount] | Array of GlyphIDs-in numerical order |
Coverage Format 2
格式2有一个格式码(CoverageFormat),glyph索引范围的个数(RangeCount),后面接着一个记录(RangeRecords)的数组组成。每个RangeRecords由一个起始glyph索引(Start),一个结束glyph索引(End),及与范围的Start glyph相关联的Coverage Index组成。范围必须是按照GlyphID的顺序排序的,并且他们必须是有区别的,没有重叠的。
第一个范围的Coverage Indexes以0值开始,并且每一个连续的范围的Start Coverage Indexes通过将前一个范围的长度(End GlyphID - Start GlyphID + 1)加上数组索引而求得。这样就可以通过公式迅速地计算任何范围中任何glyph的Coverage Index了:Coverage Index (GlyphID) = StartCoverageIndex + GlyphID - Start GlyphID。
本章结尾处的示例6显示了一个Coverage表,它使用了格式2来描述字库中的一个数字glyphs的范围。
CoverageFormat2 table: Range of glyphs
| Type | Name | Description |
|---|---|---|
| uint16 | CoverageFormat | Format identifier-format = 2 |
| uint16 | RangeCount | Number of RangeRecords |
| struct | RangeRecord [RangeCount] |
Array of glyph ranges-ordered by Start GlyphID |
RangeRecord
| Type | Name | Description |
|---|---|---|
| GlyphID | Start | First GlyphID in the range |
| GlyphID | End | Last GlyphID in the range |
| uint16 | StartCoverageIndex | Coverage Index of first GlyphID in range |
类别定义表
在OpenType Layout中,用索引值表示glyphs。为了高效并简单的表示,一个字库开发者可以将glyph索引分成组以形成类别。分配的类别值的含义在不同的lookup子表中是不同的。比如,在GSUB和GPOS表中,类被被用于描述glyph上下文。GDEF表也使用glyph 类别的概念。
考虑一个置换行为,它只置换一个glyph串中的lowercase ascender glyphs。为了更简单的描述置换的适当的上下文,字库开发者可能会将字库的lowercase glyphs分为两个类别,一个包含ascenders,另一个包含没有ascenders的glyphs。
一个字库开发者可以给任何glyph分配任何的类别,每一个类别通过一个称为类别值的整数来识别。一个Class Definition表(ClassDef)通过类别值来为glyph索引分组,由Class 1开始,然后是Class 2,等等。所有那些没有分配类别的glyphs落入Class 0。一个给定的类别定义表中,字库中的每个glyph都精确的属于一个类别。
ClassDef表可能具有两种格式中的一种:一种是将一个连续的glyph索引范围分配不同的类别,另一种是连续的glyph索引的组放进相同的类别。
Class Definition Table Format 1
第一种类别定义格式(ClassDefFormat1)描述了一个连续的glyph索引的范围和一个对应的glyph类别值的列表。这个表在给每个glyph分配不同的类别时很有用,因为没个类别的glyph索引没有办法被分组在一起。
一个ClassDef 格式1表以一个格式标识符(ClassFormat)开始。表所覆盖的glyph索引(GlyphIDs)的范围由两个值来描述:第一个glyph的GlyphID(StartGlyph),及将会被分配类别值的连续GlyphIDs(包括第一个)的个数(GlyphCount)。ClassValueArray列出了给每个GlyphID分配的类别值,以StartGlyph的类别值开始,后面以与GlyphIDs相同的顺序排序。任何没有被包含在所覆盖的GlyphIDs范围的glyph自动地归为类别0。
本章结尾处的示例7使用格式1来给一个字库中的lowercase,x-height,ascender,和descender glyphs分配类别值。
ClassDefFormat1 table: Class array
| Type | Name | Description |
|---|---|---|
| uint16 | ClassFormat | Format identifier-format = 1 |
| GlyphID | StartGlyph | First GlyphID of the ClassValueArray |
| uint16 | GlyphCount | Size of the ClassValueArray |
| uint16 | ClassValueArray[GlyphCount] | Array of Class Values-one per GlyphID |
Class Definition Table Format 2
第二种类别定义格式(ClassDefFormat2)定义了分别属于相同的类别的多个glyph索引的组。各个组以连续顺序(范围不能重叠)由glyph 索引的分离的范围组成。
ClassDef 格式2表包含一个格式标识符(ClassFormat),定义了组及其分配的类别值的ClassRangeRecords的个数(ClassRangeCount),及以每个记录(ClassRangeRecord)中的第一个glyph的GlyphID排序的ClassRangeRecords 数组组成。
每个ClassRangeRecord由一个Start glyph索引,一个End glyph索引,和一个类别值组成。范围内的所有的GlyphIDs,从Start到End都包括,构成了类别值所描述的类别。没有一个ClassRangeRecord 覆盖的任何glyph假设属于类别0。
本章结尾处的示例8使用了格式2来为Arabic script里四种类型的glyphs分配类别值。
ClassDefFormat2 table: Class ranges
| Type | Name | Description |
|---|---|---|
| uint16 | ClassFormat | Format identifier-format = 2 |
| uint16 | ClassRangeCount | Number of ClassRangeRecords |
| struct | ClassRangeRecord [ClassRangeCount] |
Array of ClassRangeRecords-ordered by Start GlyphID |
ClassRangeRecord
| Type | Name | Description |
|---|---|---|
| GlyphID | Start | First GlyphID in the range |
| GlyphID | End | Last GlyphID in the range |
| uint16 | Class | Applied to all glyphs in the range |
设备表
字库中的glyphs都是由字库开发者专门以设计单位定义。字体缩放增加或这减小一个glyph的大小,并将它round到最接近的整数pixel上。然而,精确的glyph定位常常需要调整这些缩放和rounded的值。微调(Hinting),应用于glyph轮廓的点上,是这个问题的一个有效的解决方案,但它可能需要字库开发者来重新设计或re-hint glyphs。
另一个解决方案-由GPOS,BASE,JSTF和GDEF所使用的-是使用设备表描述校正值以便于调整缩放的设计单位。一个设备表给由StartSize和EndSize所描述的大小的范围应用校正值,大小范围描述了需要调整的最小的和最大的pixel-per-em(ppem)大小。由于这种调整常常都是很小的(一个pixel或两个),校正值可以被压缩进每大小一个的2-,4-或者8-bit的representation。两位可以表示一个范围在{-2, -1, 0, or 1}的数,4位可以表示一个范围在{-8 to 7}的数,8位则可以表示一个范围为{-128 to 127}的数。设备表为校正值说明了三种数据—2-,4-,或8-bit值—格式中的一种(DeltaFormat)。一个单独的设备表为某一大小范围的调整提供增量信息。
| Type | Name | Description |
|---|---|---|
| 1 | 2 | Signed 2-bit value, 8 values per uint16 |
| 2 | 4 | Signed 4-bit value, 4 values per uint16 |
| 3 | 8 | Signed 8-bit value, 2 values per uint16 |
2-,4-,或8-bit有符号值会被打包进uint16的高位优先的数字里。比如,DeltaFormat为2(4-bit 值),则一个值为{1, 2, 3, -1}的数组将会由一个DeltaValue 0x123F来表示。
DeltaValue数组列出了在目标范围内每个ppem大小下,glyph上特定的点或整个glyph所需调整的像素数。在数组中,第一个索引位置描述了需要校正的最小的ppem大小下,坐标所需要加或减的像素数,第二个索引位置描述了下一个ppem大小下,坐标所需要加或减的像素数,以此方式定义范围内每个ppem大小的信息。
本章结尾处的示例9描述了一个设备表来为一个匹配的script定义的最小的扩展值。
Device table
| Type | Name | Description |
|---|---|---|
| uint16 | StartSize | Smallest size to correct-in ppem |
| uint16 | EndSize | Largest size to correct-in ppem |
| uint16 | DeltaFormat | Format of DeltaValue array data: 1, 2, or 3 |
| uint16 | DeltaValue[ ] | Array of compressed data |
通用表的例子
本章的剩余部分将描述和说明所有的通用表格式的例子。
Done