GSUB - Glyph置换表
Glyph置换表(GSUB)包含了用于置换glyphs以便于渲染字库中的script和language system的信息。许多language systems都需要glyph置换。比如,在Arabic script中,描画了一个特定字符的glyph形状会依据于它在单词或字串中的位置而改变(参见figure 1)。在其他的一些language systems中,glyph置换则是用户的一种审美上的选项,比如,在English语言中连字glyphs的使用(参见Figure 2)。
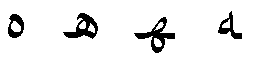
Figure 1. Isolated, initial, medial, and final forms of the Arabic character HAH
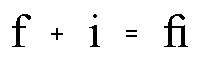
Figure 2. 两个Latin glyphs及他们相关的连字
概览
许多字库使用有限的字符编码标准来一对一的将glyphs映射到字符,给字库中的每个字符代码分配一个glyph。多个字符代码不能被映射为一个单独的glyph,但连字glyph就需要那样的映射,并且多个glyphs不能被映射到一个单独的字符代码,而将一个连字分解为他的成员glyphs时就需要这样的映射。
为了提供glyph置换操作,字库开发者必须为glyphs分配不同的字符代码,或者他们必须创建额外的字库或字符集。为了访问这些glyphs,用户也必须忍受在字符代码间,字符集间或字库间切换的烦扰。
用OpenType来置换Glyphs
OpenType GSUB表完全支持glyph置换。为了访问置换的glyph,GSUB将定义在一个cmap表中的glyph 索引或索引组(被置换的glyph)映射到置换的glyph索引或索引组。比如,如果一个字库中有三种可选形式的&符号(ampersand)的glyph,cmap表只将&符号(ampersand)的字符代码与这些glyphs中的一个关联起来。在GSUB中,其他的&符号(ampersand)的glyphs索引被这一个索引所引用。
文本处理客户端使用GSUB数据来管理glyph置换行为。GSUB描述了输入的glyphs,及来自于每个glyph置换行为的输出,描述了客户端要如何及在何处使用glyph置换,并管理glyph置换操作的顺序。可以为一个字库中表现的每一个script或language system定义任意数量的置换操作。
GSUB表支持国际化排版中广为应用的6中类型的glyph置换:
- 一个single substitution用另外一个单独的glyph替换一个单独的glyph。这被用于渲染Arabic中按位置选择glyph变体及远东地区的竖直文本(参见Figure 3)。

Figure 3. Alternative forms of parentheses used when positioning Kanji vertically
- 一个multiple substitution用多于一个的glyph替换一个单独的glyph。这被用于描述类似于连笔字分解的操作(参见Figure 4)。

Figure 4. Decomposing a Latin ligature glyph into its individual glyph components
- 一个alternate substitution描述了一个glyph的等价但不同的外观样子的功能。这些glyphs常常被作为审美选择来引用。比如,一个字库中可能具有&符号(ampersand)的5种不同的glyph,但在cmap表中它将只有一个默认的glyph索引。客户端可以使用默认的glyph或4种可选的置换形式中的任何一种(参见Figure 5)。
![]()
Figure 5. Alternative ampersand glyphs in a font
- 一个ligature substitution用一个单独glyph索引替换多个glyph索引,比如用一个Arabic连笔字替换一个分开的glyph串时(see Figure 6)。当一个glyphs串可以用一个单独的连笔字glyph替换时,则用连笔字替换第一个glyph。串中剩余的glyph被删除掉,这包括那些由于lookup标记而被跳过的glyph。
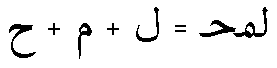
Figure 6. Three Arabic glyphs and their associated ligature glyph
- Contextual substitution,最强大的一种类型,描述了上下文中的glyph置换-即,某一个glyphs模式下一个或多个glyphs的置换。每个置换描述了一个或多个输入glyph序列和在那个序列上执行的一个或多个置换。上下文置换可被用于特定的glyph序列,glyph类别或者glyphs集合。
- Chaining contextual substitution,扩展了上下文置换的能力。借由它,通过将输入序列链接到一个‘backtrack’和/或‘lookahead’序列里去,则在具有一个glyphs模式的一个或多个glyphs(输入序列)上可以执行一个或多个置换。每个这样的置换可以以三种格式应用于处理输入序列中的glyphs,glyphs类别或者glyph集合。这些格式中的每一个可以描述一个或多个backtrack,输入或者lookahead序列。
- Reverse Chaining contextual single substitution,允许通过将输入glyph链接进一个‘backtrack’和/或‘lookahead’序列里去,而将一个glyph替换为另外的一个。这种lookup与其他lookup类型的不同之处在于,输入glyph序列的处理是从结尾到起始处的。
表的组织
GSUB表以一个表头开始,其中表头定义了到一个ScriptList,一个FeatureList和一个LookupList的偏移量(参见Figure 3g):
- ScriptList描述了字库中使用了glyph置换的所有的scripts和language systems。
- FeatureList定义了渲染这些scripts和language systems所需的所有的glyph 置换features。
- LookupList包含了实现每个glyph置换feature所需的所有lookup数据。
关于ScriptLists,FeatureLists和LookupLists的详细讨论,请参考OpenType通用表格式。
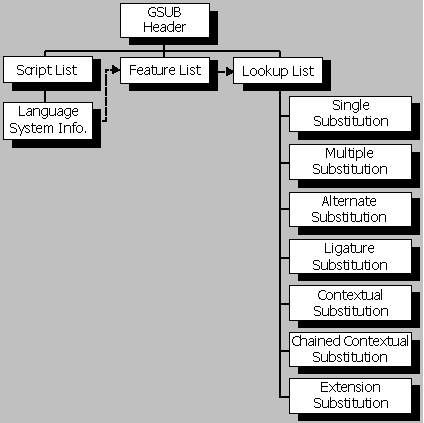
Figure 7. High-level organization of GSUB table
这种组织可以帮助文字处理客户端轻松地定位应用于一个特定的script或language system的features和lookups。为了访问GSUB信息,客户端应该使用下面的过程:
- 在GSUB ScriptList表中定位当前的script。
- 如果language system已知,则搜索script表来找到正确的LangSys表;否则,使用script的默认language system(DefaultLangSys表)。
- LangSys表提供了指到GSUB FeatureList表内去的索引数字,客户端以此来访问一个所需的feature和许多附加的features。
- 检查每个feature的FeatureTag,并选择应用于一个输入glyph串的features。每个feature提供了一个指向GSUB LookupList表内部的索引值的数组。。
- 由选择的feature集合收集所有的lookups,并以LookupList表中定义的顺序应用这些lookups。
Lookup数据在一个或多个子表中定义,其中子表定义了用于实现一个feature的一个置换行为的特定的条件,类型和结果。一个lookup中所有的子表必须具有相同的LookupType,其中LookupType在LookupType Enumeration表中列出:
LookupType Enumeration table for glyph substitution
| Value | Type | Description |
|---|---|---|
| 1 | Single | Replace one glyph with one glyph |
| 2 | Multiple | Replace one glyph with more than one glyph |
| 3 | Alternate | Replace one glyph with one of many glyphs |
| 4 | Ligature | Replace multiple glyphs with one glyph |
| 5 | Context | Replace one or more glyphs in context |
| 6 | Chaining Context | Replace one or more glyphs in chained context |
| 7 | Extension Substitution | Extension mechanism for other substitutions (i.e. this excludes the Extension type substitution itself) |
| 8 | Reverse chaining context single | Applied in reverse order, replace single glyph in chaining context |
| 9+ | Reserved | For future use (set to zero) |
每个LookupType子表具有一种或多种格式。“最好的”格式依赖于置换的类型和作为结果的存储效率。当glyph信息用多于一种格式来表示最好时,一个单独的lookup也许会定义多于一个的子表,只要所有的子表具有相同的LookupType即可。比如,一个给定的lookup内,一个glyph索引数组格式可能是表示一个目标glyphs集合的最好格式,而一个glyph索引范围格式对于另外一个集合可能更好。
在相同的glyph或glyphs串上的一系列置换操作需要多个lookups,每个单独的行为一个。每个lookup都会被分配一个不同的LookupList表中的数组号,并以在LookupList中的顺序被应用。
在文字处理期间,一个客户端在移向下一个lookup之前,会对字串中的每一个glyph应用一个lookup。对于一个glyph的处理,一个lookup会在客户端定位到了目标glyph或glyph上下文并执行了一个置换操作(如果指定了的话)之后结束。为了移向“下一个”glyph,客户端典型地会跳过参与了当前lookup操作的所有的glyphs:被替换的glyphs,还有为操作形成了一个上下文的任何其他glyphs。
链接的上下文lookup的情况下,glyphs包含可能会参与多于一个上下文的backtrack和lookahead序列。
本章的剩余部分将描述GSUB表头和为每个GSUB LookupType定义的子表。本页结尾处的例子演示了5中LookupTypes中的每一种,包括上下文置换可用的3种格式。
GSUB表头
GSUB表以一个表头开始,其中包含有一个表的版本号(Version),和到三个表的偏移量:ScriptList,FeatureList和LookupList。对于这些表的每一个的描述,请参考章节,OpenType通用表格式。本章结尾处的示例1显示了一个GSUB表头的定义。
GSUB Header
| Type | Name | Description |
|---|---|---|
| Fixed | Version | Version of the GSUB table-initially set to 0x00010000 |
| Offset | ScriptList | Offset to ScriptList table-from beginning of GSUB table |
| Offset | FeatureList | Offset to FeatureList table-from beginning of GSUB table |
| Offset | LookupList | Offset to LookupList table-from beginning of GSUB table |
LookupType 1:Single Substitution子表
Single substitution (SingleSubst)子表告诉一个客户端将一个单独的glyph替换为另一个。这种子表可能是两种格式中的一种。两种格式都需要两个单独的glyph索引集合:一个定义了输入glyphs(在Coverage表中描述),一个定义了输出glyphs。格式1相对于格式2需要更少的空间,但也更缺乏灵活性。
Single Substitution格式1
格式1计算出输出glyphs的索引,输出glyphs索引不是显式地定义在子表中的。为了计算出输出glyph索引,格式1将一个固定的差值加到输入glyph索引上。为了置换操作能够适当的执行,在输入和输出范围中的glyph索引必须是以相同的顺序排列的。这种格式不使用由Coverage表返回的Coverage Index。
SingleSubstFormat1子表以一个格式标识符(SubstFormat)1开始。一个引用了一个Coverage表的偏移量,Coverage表描述了输入glyphs的索引。DeltaGlyphID是需要加到每个输入glyph索引上以计算出对应的输出glyph索引的固定值。
本章结尾处的示例2使用了格式1来将标准的数词(standard numerals)替换为lining numerals。
SingleSubstFormat1 subtable: Calculated output glyph indices
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| int16 | DeltaGlyphID | Add to original GlyphID to get substitute GlyphID |
Single Substitution格式2
格式2相对于格式1更加灵活,但也需要更多的空间。它提供了一个输出glyph索引数组(Substitute)来显式地匹配到Coverage表中描述的输入glyph索引。
SingleSubstFormat2子表指定了一个格式标识符(SubstFormat),一个到Coverage表的偏移,其中Coverage表定义了输入glyph索引,一个Substitute数组中输出glyph索引的个数(GlyphCount),及Substitute数组(Substitute)中一个输出glyph索引的列表。
Substitute数组必须包含有与Coverage表中相同个数的glyph索引。为了定位Substitute数组中对应的输出glyph索引,这种格式使用了由Coverage表返回的Coverage Index。
本章结尾处的示例3使用了格式2来为水平方向glyphs替换竖直方向glyphs。
SingleSubstFormat2 subtable: Specified output glyph indices
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| uint16 | GlyphCount | Number of GlyphIDs in the Substitute array |
| GlyphID | Substitute [GlyphCount] |
Array of substitute GlyphIDs-ordered by Coverage Index |
LookupType 2: Multiple Substitution子表
一个Multiple Substitution (MultipleSubst)子表将一个单独的glyph替换为多余一个的glyph,比如多个glyphs替换一个单独的连笔字符的时候。这种子表具有一个格式:MultipleSubstFormat1。这种子表指定了一个格式标识符(SubstFormat),一个到一个Coverage表的偏移量,其中Coverage表定义了输入glyph索引,一个Sequence数组中偏移量的个数(SequenceCount),及一个偏移量的数组,其中每个偏移量引用一个Sequence表,而Sequence表则定义了输出glyph索引(Sequence)。Sequence偏移量数组的排列必须以输入glyphs的Coverage Index为序。
对于Coverage表中列出的每个输入glyph,一个Sequence表为其定义了输出glyphs。每个Sequence表包含一个输出glyph序列中glyphs的个数(GlyphCount),及一个输出glyph索引的数组(Substitute)。
注意:输出glyph索引的顺序依赖于文本的书写方向。对于自左向右书写的文本,最左边的glyph将会是序列中的第一个glyph。相反地,对于自右向左书写的文本,最右边的glyph将会是第一个。
为了删除一个输入字符而使用multiple substitution是被禁止的。GlyphCount应该总是大于0。
本章结尾处的示例4显示了如何将一个单独的连笔字符替换为3个glyphs。
MultipleSubstFormat1 subtable: Multiple output glyphs
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| uint16 | SequenceCount | Number of Sequence table offsets in the Sequence array |
| Offset | Sequence [SequenceCount] |
Array of offsets to Sequence tables-from beginning of Substitution table-ordered by Coverage Index |
Sequence table
| Type | Name | Description |
|---|---|---|
| uint16 | GlyphCount | Number of GlyphIDs in the Substitute array. This should always be greater than 0. |
| GlyphID | Substitute [GlyphCount] |
String of GlyphIDs to substitute |
LookupType 3: Alternate Substitution子表
一个Alternate Substitution (AlternateSubst)子表描述了任意个数的审美的选项,通过这种选项一个用户可以选择glyph变体来替换输入glyph。比如,如果一个字库包含&符号的4种变体,则cmap表将指定4个glyphs中的一个的索引作为默认的glyph索引,并且一个AlternateSubst子表将列出其他三个glyphs的索引作为选择。一个文字处理客户端将具有一种选择权来将默认的glyph替换为三个选择中的任何一个。
这种子表有一种格式:AlternateSubstFormat1。这种子表包含一个格式标识符(SubstFormat),一个到一个Coverage表的偏移量,其中Coverage表中包含了具有可选形式的glyphs的索引(Coverage),一个到AlternateSet表的偏移量的个数(AlternateSet)。
对于每一个glyph,一个AlternateSet子表包含有一个可选择的glyphs的个数(GlyphCount)及一个它们的glyph索引的数组(Alternate)。由于所有的glyphs在功能上是等价的,则在数组中它们可以以任何顺序排列。
本章结尾处的示例5显示了如何将默认的&符号glyph替换为可选的glyphs。
AlternateSubstFormat1 subtable: Alternative output glyphs
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| uint16 | AlternateSetCount | Number of AlternateSet tables |
| Offset | AlternateSet [AlternateSetCount] |
Array of offsets to AlternateSet tables-from beginning of Substitution table-ordered by Coverage Index |
AlternateSet table
| Type | Name | Description |
|---|---|---|
| uint16 | GlyphCount | Number of GlyphIDs in the Alternate array |
| GlyphID | Alternate[GlyphCount] | Array of alternate GlyphIDs-in arbitrary order |
LookupType 4: Ligature Substitution子表
一个Ligature Substitution (LigatureSubst)子表描述了用单个glyph替换多个glyphs的连笔字符置换。一个LigatureSubst子表可以描述任意数量的连笔字符置换。
这个子表使用一种格式:LigatureSubstFormat1。它包含一个格式标识符(SubstFormat),一个Coverage表的偏移量(Coverage),定义在这个表中的连笔字符(ligature)集合的个数(LigSetCount),和一个到LigatureSet表偏移量的数组(LigatureSet)。Coverage表只说明了每个ligature集第一个glyph组件的索引。
LigatureSubstFormat1 subtable: All ligature substitutions in a script
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| uint16 | LigSetCount | Number of LigatureSet tables |
| Offset | LigatureSet [LigSetCount] |
Array of offsets to LigatureSet tables-from beginning of Substitution table-ordered by Coverage Index |
一个LigatureSet表,每个覆盖的glyph一个,描述了所有以覆盖的glyph开始的连笔字符字串。比如,如果Coverage表为小写字母“f”列出了glyph索引,则一个LigatureSet表将定义“ffl”,“fl”, “ffi”,“fi”和“ff”连笔字符。如果Coverage表也为小写字母"e"列出了glyph索引,则一个不同的LigatureSet表将定义“etc”连笔字符。
一个LigatureSet表由 以覆盖的glyph开头的连笔字符的个数(LigatureCount),及一个指向Ligature表的偏移量的数组组成,其中Ligature表定义了每个连笔字符中的glyphs(Ligature)。Ligature偏移量数组中的顺序定义了使用连笔字符的优先权。比如,如果“ffl”连笔字符比“ff”连笔字符更可取,则Ligature数组将会把到“ffl” Ligature表的偏移量列在到“ff” Ligature表的偏移量的前面。
LigatureSet table: All ligatures beginning with the same glyph
| Type | Name | Description |
|---|---|---|
| uint16 | LigatureCount | Number of Ligature tables |
| Offset | Ligature [LigatureCount] |
Array of offsets to Ligature tables-from beginning of LigatureSet table-ordered by preference |
对于集合中每个连笔字符,一个Ligature表描述了输出连笔字符glyph的GlyphID(LigGlyph);一个连笔字符中组件glyphs的总个数,包括第一个组件(CompCount);及一个组件的GlyphID数组(Component)。数组以连笔字符中的第二个组件glyph开始(数组索引 = 1),因为第一组件glyph在Coverage表中指定。
注意:Component数组依据文字的书写方向来列出GlyphIDs。对于自右向左书写的文字,最右端的glyph最先列出。相反地,对于自左向右书写的文字,最左端的glyph将最先列出。
本章结尾处的示例6显示了如何用单个的连笔字符替换一个glyphs串。
Ligature table: Glyph components for one ligature
| Type | Name | Description |
|---|---|---|
| GlyphID | LigGlyph | GlyphID of ligature to substitute |
| uint16 | CompCount | Number of components in the ligature |
| GlyphID | Component [CompCount - 1] |
Array of component GlyphIDs-start with the second component-ordered in writing direction |
LookupType 5: Contextual Substitution 子表
一个Contextual Substitution (ContextSubst)子表定义了glyph置换lookup的最为强大的类型:它描述了上下文中的glyph置换,即在某一个glyphs模式内替换一个或多个glyphs。
ContextSubst子表可以是依据于一个特定的glyphs序列,glyphs类别序列,或glyph 集合序列定义了上下文的三种格式中的任何一种。每种格式都可以描述一个或多个输入glyph序列和每个序列的一个或多个置换操作。ContextSubst子表的所有三种格式在一个SubstLookupRecord中描述置换数据。下面是那个记录的一个描述。
SubstLookupRecord
| Type | Name | Description |
|---|---|---|
| uint16 | SequenceIndex | Index into current glyph sequence-first glyph = 0 |
| uint16 | LookupListIndex | Lookup to apply to that position-zero-based |
一个SubstLookupRecord中的SequenceIndex必须考虑将会被应用于整个的glyph序列的lookups的顺序。由于每个上下文都可能发生多个置换操作,SequenceIndex和LookupListIndex引用的glyph序列是文字处理客户端已经应用了任何的前面的lookups的glyph序列。换句话说,在lookup即将被应用的时刻,SequenceIndex为置换描述了位置。比如,考虑一个包含有4个glyphs的输入glyph序列。第一个glyph没有一个置换操作,但中间的两个glyphs将被一个连笔字符替换,并且一个单独的glyph将会替换第4个glyph:
- 第一个glyph在位置0.没有lookups将会被应用在位置0处,所以没有SubstLookupRecord被定义。
- 为连笔字符置换定义的SubstLookupRecord将SequenceIndex指定为位置1,即连笔字字串中第一个glyph组件的位置。然而,在连笔字符替换了位置1和2处的glyphs之后,输入glyph序列只由3个glyphs组成,而不是最初的4个。
- 为了置换序列中的最后一个glyph,SubstLookupRecord将SequenceIndex定义为位置2处而不是位置3处。这个位置反应了这个single置换之前所应用的连笔字符置换的效果。
注意:这个例子假设LookupList指定了连笔字符置换lookup在single置换lookup之前。
Context Substitution格式 1
格式1将一个glyph置换上下文定义为一个特定的glyphs的序列。比如,一个上下文可能是<xyz>,<holiday>,<!?*#@>或任何其他的glyph序列。
在一个上下文序列内,格式1将特别的glyph位置(不是glyph索引)指定为特定的置换的目标。当一个文字处理客户端定位一个文本子串中的一个上下文时,它为一个目标位置寻找lookup数据,并通过在那个位置应用lookup数据来执行一个置换操作。
比如,如果一个客户端要将glyph串<abc>替换为他的反向的glyph串<cba>,则输入上下文被定义为glyph序列,<abc>,为上下文定义的lookups是(1) “a”到“c”和(2)“c”到“a”。当一个客户端遇到了上下文<abc>时,则lookups被以存储的顺序执行。首先,“c”将“a”置换掉而产生<cbc>。第二,“a”将还没有被动过的“c”置换掉产生<cba>。
为了描述一个上下文,一个Coverage表列出了序列中的第一个glyph,而一个SubRule表描述了剩余的glyphs。为了描述前面的例子中所使用的<abc>上下文,Coverage表列出了那个序列的第一个组件的glyph索引-“a” glyph。一个SubRule表为“b”和“c” glyphs定义了索引。
一个单独的ContextSubstFormat1子表可能定义多于一个的上下文glyph序列。如果不同的上下文序列以相同的glyph开头,则Coverage表应该只将那个glyph列出一次,因为表中所有的glyphs必须是唯一的。比如,如果有三个上下文每个都以“s”开头,有两个上下文以“t”开头,则Coverage表将列出一个“s”和一个“t”。
对于每个上下文,一个SubRule表列出了跟在第一个glyph之后的所有的glyphs。这个表也包含一个SubstLookupRecords的数组,其中SubstLookupRecords为上下文中的每个glyph位置(包括第一个glyph位置)描述了置换lookup数据。
所有定义了以相同的首glyph开始的上下文的SubRule表会被分组在一起并定义一个SubRuleSet表。例如,三个定义了以一个“s”开始的上下文的SubRule表被分组进一个SubRuleSet表,两个定义了以一个“t”开始的上下文的SubRule表被分组进第二个SubRuleSet表中。Coverage表中列出的每个glyph必须具有一个SubRuleSet表来定义应用于一个覆盖的glyph的所有的SubRule表。
为了定位一个上下文glyph序列,文字处理客户端在每次遇到一个新的文字glyph时就搜索Coverage表。如果glyph被覆盖了,则客户端读取对应的SubRuleSet表,并检查集合中的每个SubRule表来确定上下文剩余的部分是否与文本中的glyphs子序列匹配。如果上下文与子串匹配,则客户端查找目标glyph的位置,为那些位置应用lookups,并完成置换。
一个ContextSubstFormat1子表包含一个格式标识符(SubstFormat),一个到一个Coverage表的偏移量(Coverage),所定义的SubRuleSets的个数(SubRuleSetCount),及一个到SubRuleSet表的偏移量的数组(SubRuleSet)。如前所述,必须为Coveage表中所列出的每个glyph定义一个SubRuleSet表。
在SubRuleSet数组中,SubRuleSet表偏移量以Coverage Index的顺序排列。数组中的第一个SubRuleSet应用于Coverage表中所列出的第一个GlyphID,数组中的第二个SubRuleSet应用于Coverage表中所列出的第二个GlyphID,以此类推。
ContextSubstFormat1 subtable: Simple context glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| uint16 | SubRuleSetCount | Number of SubRuleSet tables-must equal GlyphCount in Coverage table |
| Offset | SubRuleSet [SubRuleSetCount] |
Array of offsets to SubRuleSet tables-from beginning of Substitution table-ordered by Coverage Index |
一个SubRuleSet表由一个到SubRule表的偏移量的数组(SubRule),其中数组以任意数序排列,及一个定义在集合中的SubRule表的个数(SubRuleCount)组成。SubRule数组中的顺序可能是非常重要的。考虑两个上下文,<abc>及<abcd>。如果SubRule数组中<abc>在前,文本中所有的<abc>实例-包括<abcd>的所有实例-将会被改变。如果数组中<abcd>在前,只有<abcd>序列会被改变,而不会影响到任何<abc>的实例。
一个SubRule表由一个输入上下文序列中被匹配的glyphs的个数(GlyphCount),包括序列中的第一个glyph,和一个描述了上下文的glyph索引的数组(Input)组成。Coverage表描述了上下文中第一个glyph的索引,因而Input数组从上下文序列中的第二个glyph开始(数组索引 = 1)。
注意:Input数组以文本中对应的glyphs出现的顺序列出索引。对于自右向左书写的文字,最右端的glyph将为第一个;相反地,对于自左向右书写的文字,最左端的glyph将是第一个。
一个SubRule表也包含一个将会在输入glyph序列上执行的置换的个数(SubstCount)及一个SubstitutionLookupRecords的数组(SubstLookupRecord)。每个记录描述了一个输入glyph序列里的位置,及一个指向了将在那个位置被应用的置换lookup的LookupListIndex。数组应该以设计顺序列出记录,或者以应该被应用于整个glyph序列的lookups的顺序列出。
SubRule table: One simple context definition
| Type | Name | Description |
|---|---|---|
| uint16 | GlyphCount | Total number of glyphs in input glyph sequence-includes the first glyph |
| uint16 | SubstCount | Number of SubstLookupRecords |
| GlyphID | Input [GlyphCount - 1] |
Array of input GlyphIDs-start with second glyph |
| struct | SubstLookupRecord [SubstCount] |
Array of SubstLookupRecords-in design order |
本章结尾处的示例7显示了如何使用ContextSubstFormat1子表为French language system,将一个三glyphs的序列替换为一个想要的序列。
Context Substitution 格式 2
格式2,一个相对于格式1更灵活的格式,描述了基于类别的上下文置换。对于这种格式,一个称为类别值的特定整数必须被分配给所有的上下文glyph序列中的每个glyph组件。然后上下文被定义为glyph类别值的序列。这种格式可能在同一时间定义多于一个的上下文。
比如,设想一个swash capital glyph应该替换每个前面是一个空格glyph而后面是一个小写字母glyph的大写字母glyph(一个模式为空格-大写字母-小写字母的glyph序列)。大写字母glyphs的集合将形成一个glyph类别(Class 1),小写字母glyphs的集合将形成第二个类别(Class 2),而空格glyph将形成第三个类被(Class 3)。输入上下文也许可以通过一个上下文规则(称为一个SubClassRule)描述为“形成了三个glyph类别的序列的glyph串的集合,一个glyph来自于Class 2,后面跟着一个来自于Class 1的glyph,再后面跟着一个来自于Class 2的glyph”。
每个ContextSubstFormat2子表包含有一个指向了一个类别定义表(ClassDef)的偏移量,其中定义了所有的输入上下文的glyph类别值。通常,一个字库中所包含的每个ContextSubstFormat2表的实例中都会声明一个唯一的ClassDef表,尽管一些格式2的表可以共享ClassDef表。类别分配值是固定的(与上下文中的每个位置相同),并且类别是专有的(同一时刻一个glyph不能在多个类别中)。替换了上下文序列中的glyphs的输出glyphs不需要类别值,因为他们在别处用GlyphID来指定。
ContextSubstFormat2子表也包含一个格式标识符(SubstFormat),并定义了一个到一个Coverage表的偏移量(Coverage)。对于这种格式,一个Coverage表列出了可以作为任何基于类别的上下文的首glyph而出现的唯一的glyphs(不是glyph类别)的完整集合的索引。换句话说,Coverage表包为所有的类别中可能成为任何上下文类别序列的首glyph的所有的glyphs含有glyph索引的列表。比如,如果上下文以一个Class 1或Class 2 glyph开始,则Coverage表将列出所有的Class 1和Class 2 glyphs的索引。
一个ContextSubstFormat2子表也定义了一个到SubClassSet表的偏移量的数组(SubClassSet)及一个SubClassSet表的个数(SubClassSetCnt)。数组为ClassDef表中的每个类别包含一个偏移量(包括Class 0)。在数组中,类别值定义了一个偏移量的索引位置,并且SubClassSet偏移量被以类别值的升序进行排列(从0到SubClassSetCnt - 1)。
例如,数组中所列的第一个SubClassSet包含所有以Class 0的glyphs开头的上下文,第二个SubClassSet包含所有以Class 1的glyphs开头的上下文,以此类推。如果没有上下文以一个特定的类别开始(即,如果一个SubClassSet不包含SubClassRule表),则SubClassSet数组中到那个特定的SubClassSet的偏移量将被设为NULL。
ContextSubstFormat2 subtable: Class-based context glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| Offset | ClassDef | Offset to glyph ClassDef table-from beginning of Substitution table |
| uint16 | SubClassSetCnt | Number of SubClassSet tables |
| Offset | SubClassSet [SubClassSetCnt] |
Array of offsets to SubClassSet tables-from beginning of Substitution table-ordered by class-may be NULL |
每个上下文被定义在一个SubClassRule表中,并且所描述的上下文以相同的类别值开始的所有的SubClassRules被分组进一个SubClassSet表中。因此,SubClassSet包含一个上下文描述了一个上下文的第一个类别组件。
每个SubClassSet表由一个定义在SubClassSet中的SubClassRule表的个数(SubClassRuleCnt)及一个到SubClassRule表的偏移量的数组(SubClassRule)组成。SubClassSet的SubClassRule数组里的SubClassRule表被以任意顺序排列。
SubClassSet subtable
| Type | Name | Description |
|---|---|---|
| uint16 | SubClassRuleCnt | Number of SubClassRule tables |
| Offset | SubClassRule [SubClassRuleCount] |
Array of offsets to SubClassRule tables-from beginning of SubClassSet-ordered by preference |
对于每个上下文,一个SubClassRule表包含一个上下文序列中glyph类别的个数(GlyphCount),包括第一个类别。一个Class数组列出了序列中所有glyphs的类别,从第二个类别开始(数组索引 = 1),即上下文中跟在第一个类别后面的类别。
注意:文字的顺序依赖于文字的书写方向。对于自右向左书写的文字,最右端的类别将是第一个。相反地,对于自左向右书写的文字,最左端的类别将是第一个。
Class数组中所描述的值都是定义在ClassDef表中的值。比如,一个上下文由序列“Class 2,Class 7,Class 5,Class 0”组成,则它将产生一个元素为7,5,0的Class数组。序列中的第一个类别,Class 2,在ContextSubstFormat2表中通过对应的SubClassSet在SubClassSet数组中的索引来确定。
一个SubClassRule也包含一个将会在那个上下文上执行的置换的个数(SubstCount)及一个SubstLookupRecords的数组组成(SubstLookupRecord),而SubstLookupRecords则提供了置换数据。对于上下文中需要一个置换的每个位置,会有一个SubstLookupRecord来指定一个LookupList索引和输入glyph序列中lookup被应用的一个位置。SubstLookupRecord数组以设计顺序列出SubstLookupRecords-即,lookups应该被应用于整个glyph序列的顺序。
SubClassRule table: Context definition for one class
| Type | Name | Description |
|---|---|---|
| uint16 | GlyphCount | Total number of classes specified for the context in the rule-includes the first class |
| uint16 | SubstCount | Number of SubstLookupRecords |
| uint16 | Class [GlyphCount - 1] |
Array of classes-beginning with the second class-to be matched to the input glyph class sequence |
| struct | SubstLookupRecord [SubstCount] |
Array of Substitution lookups-in design order |
本章结尾处的示例8使用了Format 2来为不同高度的base glyphs置换Arabic mark glyphs。
Context Substitution Format 3
Format 3,基于Coverage的上下文置换,将一个上下文规则定义为一个Coverage表的序列。序列中的每个位置可能为匹配了上下文模式的glyph集合定义了一个不同的Coverage表。通过Format 3,在不同的Coverage表中定义的glyph集合可能会交叉,而不像Format 2那样确定了固定的类别分配值(上下文序列中的每个位置都是一致的)和独有的类别(一个glyph不能同时属于多个类别)。
比如,考虑一个输入上下文,它包含一个小写字母 glyph(position 0),后面跟一个大写字母glyph(position 1),接下来是一个小写字母或数字的glyph(position 2),然后是一个小写字母或大写的元音(position 3)。这个上下文需要4个Coverage表,每个位置一个:
- 在位置0,其Coverage表列出了小写字母glyphs的集合。
- 在位置1,其Coverage表列出了大写字母glyphs的集合。
- 在位置2,其Coverage表列出了小写字母和数字的glyphs的集合,它是为位置0定义的Coverage表中所定义的glyphs的超集。
- 在位置3,其Coverage表列出了小写字母和大写元音的集合,位置0和1的Coverage表中所定义的glyphs的子集。
不像Formats 1和2,这种格式同一时刻只定义一个上下文规则。它由一个格式标识符(SubstFormat),一个序列中被匹配的glyphs的个数(GlyphCount),及一个Coverage偏移量的数组组成(Coverage),其中Coverage表描述了输入上下文序列。
注意:Coverage数组中所列出的Coverage表的顺序必须遵从书写的方向。对于自右向左书写的文字,则最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将会是第一个。
这个子表也包含在输入Coverage序列上将会被执行的置换的个数(SubstCount)及一个SubstLookupRecords的数组(SubstLookupRecord)以设计顺序排列-即,lookups应该被应用于整个glyph序列的顺序。
ContextSubstFormat3 subtable: Coverage-based context glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 3 |
| uint16 | GlyphCount | Number of glyphs in the input glyph sequence |
| uint16 | SubstCount | Number of SubstLookupRecords |
| Offset | Coverage[GlyphCount] | Array of offsets to Coverage table-from beginning of Substitution table-in glyph sequence order |
| struct | SubstLookupRecord [SubstCount] |
Array of SubstLookupRecords-in design order |
LookupType 6:Chaining Contextual Substitution Subtable
一个Chaining Contextual Substitution子表(ChainContextSubst)描述了上下文中的glyph置换,同时具有一种在glyphs序列中向后看(look back)和/或向前看(look ahead)的能力。Chaining Contextual Substitution子表的设计与Contextual Substitution子表的设计是类似的,也包含三种用于处理glyphs序列,glyph类别序列或者glyph集合序列的格式。每种格式都可以描述一个或多个backtrack,input和lookahead序列和每个序列的一个或多个置换。
Chaining Context Substitution Format 1: Simple Chaining Context Glyph Substitution
Format 1将一个glyph置换的上下文定义为一个特定的glyphs序列。比如,一个上下文可能是<xyz>,<holiday>,<!?*#@>或任何其他的glyph序列。
在一个上下文序列中,Format 1将特定的glyph位置(不是glyph索引)标识为特定的置换的目标。当一个文字处理客户端定位到了一个文本串中的一个上下文时,它为一个目标位置查找lookup数据,并通过在那个位置应用那个lookup数据来执行一个置换。
为了详细说明上下文,Coverage表列出了输入序列中的第一个glyph,而ChainSubRule子表则定义了剩余的。一旦在位置i处(Coverage表中)发现了一个包含的glyph(子串中),则客户端将读取对应的ChainSubRuleSet表,并检查每个表来决定它是否匹配文字中附近的glyphs。最简单的一些情形中,如果字串<backtrack序列>+<input序列>+<lookahead序列>匹配了文本中位置(i - BacktrackGlyphCount)处的glyphs则有一个匹配。LookupFlag值会影响backtrack/lookahead序列。
为了给input,backtrack及lookahead序列阐明glyph数组的排序规则,而提供了下面的说明。Input序列从i处开始匹配,i也是input序列匹配开始的位置。backtrack序列从i - 1处开始排列,并且以距离i的偏移值增加。lookahead序列从input序列之后的位置开始,并且以逻辑顺序增加。
| Logical order - | a | b | c | d | e | f | g | h | i | j |
| i | ||||||||||
| Input sequence - | 0 | 1 | ||||||||
| Backtrack sequence - | 3 | 2 | 1 | 0 | ||||||
| Lookahead sequence - | 0 | 1 | 2 | |
如果存在一个匹配,则客户端为置换操作查找目标glyph位置并完成置换操作。请注意(像在ContextSubstFormat1子表中的那样),这些lookups需要在文本中由所覆盖的glyph开始到input序列结束的这个范围内执行。(即,backtrack序列和lookahead序列只用于确定上下文)。不能为backtracking序列或者lookahead序列定义置换操作。
一旦置换操作完成了,则文字处理客户端应该移向紧跟在匹配的input序列后面的glyph位置,并从那里重新开始lookup处理。
一个单独的ChainContextSubstFormat1子表可能定义多于一个的上下文glyph序列。如果有不同的上下文序列以相同的glyph开始,则Coverage表应该只列出那个glyph一次,因为表中所有的glyphs都必须是唯一的。比如,如果有三个上下文每个都以一个“s”开头,两个上下文每个都以一个“t”开头,则Coverage表将只列出一个“s”和一个“t”。
所有定义了以相同的首glyph开头的上下文的ChainSubRule表被分组在一起,并被定义在一个ChainSubRuleSet表中。比如,定义了三个以“s”开头的上下文的ChainSubRule表会被分组进一个ChainSubRuleSet表中,定义了两个以“t”开头的上下文的ChainSubRule表会被分组进另一个ChainSubRuleSet表中。Coverage表中所列出的每个glyph都必须有一个ChainSubRuleSet表来定义应用于一个覆盖的glyph的所有的ChainSubRule表。
一个ChainContextSubstFormat1子表包含一个格式标识符(SubstFormat),及一个到一个Coverage表的偏移量(Coverage),一个所定义的ChainSubRuleSets的个数(ChainSubRuleSetCount),和一个到ChainSubRuleSet表的偏移量的数组(ChainSubRuleSet)。如前所述,必须为Coverage表中所列出的每个glyph定义一个ChainSubRuleSet表。
在ChainSubRuleSet数组中,ChainSubRuleSet表偏移量以Coverage Index的顺序排列。数组中的第一个ChainSubRuleSet应用于Coverage表中所列出的第一个GlyphID,数组中的第二个ChainSubRuleSet应用于Coverage表中所列出的第二个GlyphID,以此类推。
ChainContextSubstFormat1 subtable: Simple context glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| uint16 | ChainSubRuleSetCount | Number of ChainSubRuleSet tables-must equal GlyphCount in Coverage table |
| Offset | ChainSubRuleSet [ChainSubRuleSetCount] |
Array of offsets to ChainSubRuleSet tables-from beginning of Substitution table-ordered by Coverage Index |
一个ChainSubRuleSet表由一个到ChainSubRule表的偏移量的数组(ChainSubRule)(依据偏好排列),及一个集合中所定义的ChainSubRule表的个数(ChainSubRuleCount)组成。
ChainSubRule数组中的排序可能是非常重要的。考虑两个上下文,<abc>及<abcd>。如果ChainSubRule数组中<abc>在前,文本中所有的<abc>实例-包括<abcd>的所有实例-将会被改变。如果数组中<abcd>在前,则只有<abcd>序列会被改变,而不会影响到任何<abc>的实例。
ChainSubRuleSet table: All contexts beginning with the same glyph
| Type | Name | Description |
|---|---|---|
| uint16 | ChainSubRuleCount | Number of ChainSubRule tables |
| Offset | ChainSubRule [ChainSubRuleCount] |
Array of offsets to ChainSubRule tables-from beginning of ChainSubRuleSet table-ordered by preference |
一个ChainSubRule表由一个将被匹配的backtrack,input和lookahead上下文序列中的glyphs的个数(包括每个序列的第一个glyph),及一个描述了上下文的每个部分的glyph索引数组组成。Coverage表确定了每个上下文中第一个glyph的索引,而每个数组都以上下文序列中的第二个glyph(数组索引 = 1)开始。
注意:所有的数组都以文本中对应的glyphs出现的顺序排列glyph索引。对于自右向左书写的文字,则最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将会是第一个。
一个ChainSubRule表也包含一个将会在输入glyph序列上执行的置换的个数(SubCount)及一个SubstitutionLookupRecords的数组(SubstLookupRecord)。每个记录说明了一个输入glyph序列中的位置及一个引用了在那个位置应用的置换操作lookup的LookupListIndex。数组应该以设计顺序排列记录,或者lookups应该被应用于整个glyph序列的顺序排序。
ChainSubRule subtable
| Type | Name | Description |
|---|---|---|
| uint16 | BacktrackGlyphCount | Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph) |
| GlyphID | Backtrack [BacktrackGlyphCount] |
Array of backtracking GlyphID's (to be matched before the input sequence) |
| uint16 | InputGlyphCount | Total number of glyphs in the input sequence (includes the first glyph) |
| GlyphID | Input [InputGlyphCount - 1] |
Array of input GlyphIDs (start with second glyph) |
| uint16 | LookaheadGlyphCount | Total number of glyphs in the look ahead sequence (number of glyphs to be matched after the input sequence) |
| GlyphID | LookAhead [LookAheadGlyphCount] |
Array of lookahead GlyphID's (to be matched after the input sequence) |
| uint16 | SubstCount | Number of SubstLookupRecords |
| struct | SubstLookupRecord [SubstCount] |
Array of SubstLookupRecords (in design order) |
Chaining Context Substitution Format 2: Class-based Chaining Context Glyph Substitution
格式2描述了基于类别的chaining context substitution。对于这种格式,一个称为类别值的特定整数必须被分配给所有的上下文glyph序列中的每个glyph组件。然后上下文被定义为glyph类别值的序列。这种格式可能在同一时间定义多于一个的上下文。
为了链接上下文,而在glyph ClassDef表中使用了三种类别:Backtrack ClassDef,Input ClassDef,和Lookahead ClassDef。
ChainContextSubstFormat2子表也包含一个格式标识符(SubstForamt),并定义了一个指向了一个Coverage表的偏移量(Coverage)。对于这种格式,Coverage表中列出了可能作为任何的一个基于类别的上下文首glyph的唯一的glyphs的完整集合的索引(不是glyph类别)。换句话说,Coverage表为任何的上下文类别序列中可能成为首class的class中所有的glyphs包含了glph索引的列表。比如,如果上下文以一个Class 1或Class 2的glyph开头,则Coverage表将列出所有的Class 1和Class 2 glyphs的索引。
一个ChainContextSubstFormat2子表,也定义了一个引用了ChainSubClassSet表的偏移量的数组(ChainSubClassSet),及一个ChainSubClassSet表的个数(ChainSubClassSetCnt)。那个数组为ClassDef表中的每个类别(包括Class 0)包含一个偏移量。在那个数组中,类别值定义了一个偏移量的索引位置,而且ChainSubClassSet的偏移量是以类别值的升序排序的(从0到ChainSubClassSetCnt - 1)。
如果没有以某个特定的类别开始的上下文(即,如果一个ChainSubClassSet不包含ChainSubClassRule表),则ChainSubClassSet数组中引用那个特定的ChainSubClassSet的偏移量将被设为NULL。
ChainContextSubstFormat2 subtable: Class-based chaining context glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of Substitution table |
| Offset | BacktrackClassDef | Offset to glyph ClassDef table containing backtrack sequence data-from beginning of Substitution table |
| Offset | InputClassDef | Offset to glyph ClassDef table containing input sequence data-from beginning of Substitution table |
| Offset | LookaheadClassDef | Offset to glyph ClassDef table containing lookahead sequence data-from beginning of Substitution table |
| uint16 | ChainSubClassSetCnt | Number of ChainSubClassSet tables |
| Offset | ChainSubClassSet [ChainSubClassSetCnt] |
Array of offsets to ChainSubClassSet tables-from beginning of Substitution table-ordered by input class-may be NULL |
每个上下文都被定义在一个ChainSubClassRule表中,所有描述了以相同的类别值开始的上下文的ChainSubClassRules被分组进一个ChainSubClassSet表中。因而,ChainSubClassSet包含一个上下文,确定了一个上下文的首class组件。
每个ChainSubClassSet表由一个ChainSubClassSet中所定义的ChainSubClassRule表的个数(ChainSubClassRuleCnt)及一个 引用了ChainSubClassRule表的偏移量的数组(ChainSubClassRule)组成。ChainSubClassSet的ChainSubClassRule数组中的ChainSubClassRule表依据偏好来排序。
ChainSubClassSet subtable
| Type | Name | Description |
|---|---|---|
| uint16 | ChainSubClassRuleCnt | Number of ChainSubClassRule tables |
| Offset | ChainSubClassRule [ChainSubClassRuleCount] |
Array of offsets to ChainSubClassRule tables-from beginning of ChainSubClassSet-ordered by preference |
对于每个上下文,一个ChainSubClassRule 表包含一个上下文序列中glyph类别的个数(GlyphCount),包括第一个类别。一个Class数组列出了所有的类别,从第二个类别(数组索引=1),即上下文中紧随第一个类别的类别,开始。
注意:文字的顺序依赖于文字的书写方向。对于自右向左书写的文字,则最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将会是第一个。
Class数组中描述的值都是定义在ClassDef表中的值。序列中的第一个类别,Class 2,在ChainContextSubstFormat2表中通过对应的ChainSubClassSet 在ChainSubClassSet数组中的索引来确定。
一个ChainSubClassRule也包含一个将在上下文上执行的置换的个数(SubstCount)及一个SubstLookupRecords的数组(SubstLookupRecord),其中后者提供了置换数据。对于上下文中需要一个置换操作的每个位置,一个SubstLookupRecord确定了一个LookupList索引,和输入glyph序列中那个lookup被应用的一个位置。SubstLookupRecord数组以设计顺序列出SubstLookupRecords-即,lookups应该被应用于整个glyph序列的顺序。
ChainSubClassRule table: Chaining context definition for one class
| Type | Name | Description |
|---|---|---|
| uint16 | BacktrackGlyphCount | Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph) |
| uint16 | Backtrack [BacktrackGlyphCount] |
Array of backtracking classes(to be matched before the input sequence) |
| uint16 | InputGlyphCount | Total number of classes in the input sequence (includes the first class) |
| uint16 | Input [InputGlyphCount - 1] |
Array of input classes(start with second class; to be matched with the input glyph sequence) |
| uint16 | LookaheadGlyphCount | Total number of classes in the look ahead sequence (number of classes to be matched after the input sequence) |
| uint16 | LookAhead [LookAheadGlyphCount] |
Array of lookahead classes(to be matched after the input sequence) |
| uint16 | SubstCount | Number of SubstLookupRecords |
| struct | SubstLookupRecord [SubstCount] |
Array of SubstLookupRecords (in design order) |
Chaining Context Substitution Format 3: Coverage-based Chaining Context Glyph Substitution
Format 3将一个链接上下文规则定义为一个Coverage表的序列。序列中的每个位置可能为匹配了上下文模式的glyphs集合定义了一个不同的Coverage表。通过Format 3,不同的Coverage表中所定义的glyph集合可能会交叉,不像Format 2那样确定了固定的类别分配值(backtrack,input或者lookahead序列中的每个位置都是一致的)和独有的类别(一个glyph不能同时属于多个类别)。
注意:Coverage数组中所列出的Coverage表的顺序必须遵从书写的方向。对于自右向左书写的文字,则最右端的glyph将是第一个。相反地,对于自左向右书写的文字,最左端的glyph将会是第一个。
子表也包含一个输入Coverage序列上将被执行的置换操作的个数(SubstCount)及一个以设计顺序排序的SubstLookupRecords的数组(SubstLookupRecord):即,lookups应该被应用于整个glyph序列的顺序(SubstLookupRecords在后面描述)。
ChainContextSubstFormat3 subtable: Coverage-based chaining context glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 3 |
| uint16 | BacktrackGlyphCount | Number of glyphs in the backtracking sequence |
| Offset | Coverage[BacktrackGlyphCount] | Array of offsets to coverage tables in backtracking sequence, in glyph sequence order |
| uint16 | InputGlyphCount | Number of glyphs in input sequence |
| Offset | Coverage[InputGlyphCount] | Array of offsets to coverage tables in input sequence, in glyph sequence order |
| uint16 | LookaheadGlyphCount | Number of glyphs in lookahead sequence |
| Offset | Coverage[LookaheadGlyphCount] | Array of offsets to coverage tables in lookahead sequence, in glyph sequence order |
| uint16 | SubstCount | Number of SubstLookupRecords |
| struct | SubstLookupRecord [SubstCount] |
Array of SubstLookupRecords, in design order |
LookupType 7: Extension Substitution
这种Lookup提供了一种机制,以帮助在‘GSUB’表中将任何其他的lookup类型的子表存储在一个32-bit偏移量的位置。如果子表的总大小超出了‘GSUB’表中各种其他的偏移量都会有的16-bts的限制,则会需要用到这种表。这份规范中,把存储在32-bt偏移量位置处的子表乘坐“扩展”子表。
ExtensionSubstFormat1 subtable
| Type | Name | Description |
|---|---|---|
| USHORT | SubstFormat | Format identifier. Set to 1. |
| USHORT | ExtensionLookupType | Lookup type of subtable referenced by ExtensionOffset (i.e. the extension subtable). |
| ULONG | ExtensionOffset | Offset to the extension subtable, of lookup type ExtensionLookupType, relative to the start of the ExtensionSubstFormat1 subtable. |
ExtensionLookupType必须被设为7之外的其他的lookup类型。一个LookupType 7 lookup中的所有的子表必须具有相同的ExtensionLookupType。扩展子表中所有的偏移量以平常的方式设置,比如,相对于扩展子表本身。
当一个OpenType layout引擎遇到一个LookupType 7 Lookup表时,它应该:
- 就像Lookup表的LookupType成员被设为了其子表的ExtensionLookupType一样的来处理。
- 就像由ExtensionOffset所引用的每个扩展子表替换了引用它的LookupType 7 子表一样来处理。
Substitution Lookup Record
所有的上下文置换子表在一个Substitution Lookup Record (SubstLookupRecord)中说明置换数据。每个记录包含一个SequenceIndex,它表示了将在glyph序列中发生的置换操作的位置。此外,一个LookupListIndex确定了将被应用于由SequenceIndex所确定的glyph位置的lookup。
本章结尾处的示例7,8,9所定义的上下文置换子表显示了一些SubstLookupRecords。
LookupType 8: Reverse Chaining Contextual Single Substitution子表
Reverse Chaining Contextual Single Substitution子表(ReverseChainSingleSubst)上下文中单个glyph的置换,同时具有一种在glyphs序列中向后看(look back)和/或向前看(look ahead)的能力。这种lookup类型与其他lookup类型的主要的区别是,对于输入glyph序列的处理是由后向前的。相比于Chaining Contextual Sustitution,这种格式的限制是,它只能使用基于Coverage的子表格式,输入序列能只包含单独的一个glyph,并且只有一个置换操作可以在这个glyph上执行。这种置换规则被集成进子表格式中。
这种lookup类型是特别为Arabic scripts书写风格而设计的,像nastaliq,它的glyph的shpe是由接着的glyph来决定的,从“joor”的最后一个glyph开始。或者连接的glyphs的集合。本章结尾处的示例10定义了一个这种lookup类型的例子。
Reverse Chaining Contextual Single Substitution Format 1: Coverage Based Reverse Chaining Contextual Single Glyph Substitution
Format 1将一个链接上下文规则定义为一个Coverage表的序列。序列中的每个位置可能为匹配了上下文模式的glyphs集合定义了一个不同的Coverage表。通过Format 1,不同的Coverage表中所定义的glyph集合可能会交叉。
注意:尽管是逆序处理的,但Coverage数组中所列出的Coverage表的顺序必须是逻辑顺序(遵从书写方向)。backtrack序列就像在LookupType 6中所描述的那样:Chaining Contextual Substitution子表。输入序列是逻辑字串中位置在i处的一个glyph。backtrack从i - 1处开始,并且随着向字串的逻辑开始处移动1而递增偏移值。lookahead序列从i + 1处开始,并且随着向字串的逻辑结束处移动1而增加偏移值。在逆向链接处理i中从字串的逻辑结束处开始而移向起始处。
这种子表为输入glyph包含了Coverage表,并为lookahead和backtrack序列包含了Coverage表,也包含了置换数组中输出glyph索引的个数(GlyphCount)及一个输出glyph索引的列表(Substitute数组)。Substitute数组必须包含有与Coverage表中所包含的相同个数的glyph索引。为了定位Substitue数组中对应的输出glyph索引,这种格式使用了返回自Coverage表的Coverage Index。
ReverseChainSingleSubstFormat1 subtable: Coverage-based Reverse Chaining Contextual Single Glyph substitution
| Type | Name | Description |
|---|---|---|
| uint16 | SubstFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table - from beginning of Substitution table |
| uint16 | BacktrackGlyphCount | Number of glyphs in the backtracking sequence |
| Offset | Coverage[BacktrackGlyphCount] | Array of offsets to coverage tables in backtracking sequence, in glyph sequence order |
| uint16 | LookaheadGlyphCount | Number of glyphs in lookahead sequence |
| Offset | Coverage[LookaheadGlyphCount] | Array of offsets to coverage tables in lookahead sequence, in glyph sequence order |
| uint16 | GlyphCount | Number of GlyphIDs in the Substitute array |
| GlyphID | Substitute[GlyphCount] | Array of substitute GlyphIDs-ordered by Coverage Index |
GSUB子表例子
本章剩余的部分将描述和说明一些GSUB子表的例子。
Done。