Ceilometer简介
1.1 历史和任务
1.1.1 历史
l Ceilometer项目开始于2012年的4,5月份,由 Julien Danjou, Dreamhost 和 Canonical等发起。
l 经过6个月的开发,在2012年的10月份,伴随着Folsom的发布,Ceilometer也发布了它的v1.0版本,在 第一个版本中,Ceilometer主要实现了对一些重要数据的计量,包括Compute, Network, Memory, CPU, Image, Volume等,并且提供了REST API。
l 在2013年的2月份,Ceilometer完成了由Incubation到Integrated的转变,这意味着Ceilometer将作为OpenStack 发行版的一部分而发布。
l 在Grizzly版中,Ceilometer添加了对Swift的支持,增加了SQLAlchemy作为Storage Backend,开发了Multi Publisher, 并且发布了V2版本的API。
l 现在Havana中,Ceilometer已经发布了2个milestone,主要增加了HBase作为Storage Backend,Alarm功能也基本完成, 并且增加了UDP Publisher作为取代RPC发送消息的第二选择,更加高效。正在开发的havana-3,一个重要的新功能是 又增加了DB2作为Storage Backend.
1.1.2 任务
Ceilometer的使命经过一次变化,在项目提出之初,对它的定位就只是专注于计量,为计费而生。我们可以从它 v1.0的Mission看出。
但是Ceilometer收集的是有用的数据,我们都知道数据的价值,所以随着Ceilometer的发展,对它的需求也在不断的增长, 除了计费之外,像监控、Autoscalling、数据统计分析、benchmarking等都需要这些数据。所以从Grizzly开始,Ceilometer 扩展了它的目标,不仅仅局限在计量和计费上,又由于Ceilometer的扩展性很强,很容易通过扩展去满足这些需求。
1.2 核心架构
Ceilometer收集的是OpenStack内部各个服务(nova, neutron, cinder等),以及将来很多未知的服务的信息,这个基本的 需求决定了它的架构必须是灵活可扩展的,因此,Ceilometer采用了一种“微内核”的架构,通过插件的机制来实现扩展。
这里不得不说一下它的设计者Doug Hellmann为此做出的努力,可扩展可以说是软件设计的一个基本特征,不同的项目 有不同的实现方法,Doug Hellmann花了一年的时间,调研了很多项目的扩展机制,包括Sphinx, Nose, Django,SQLAlchemy, Nova等,最终开发了Python的一个基于setuptools entry points三方库Stevedore, 并且使用Stevedore设计了Ceilometer的插件机制,现在Stevedore已经被OpenStack中的很多新的项目使用, nova中也有用到。
下面是Ceilometer的核心架构图:
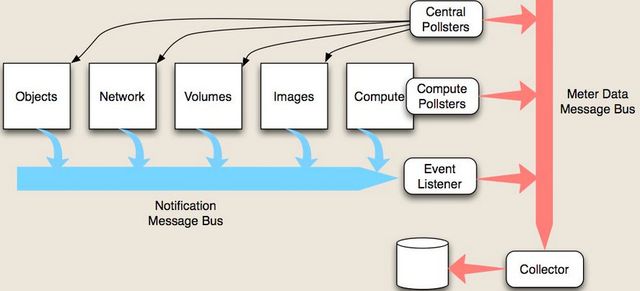
Ceilometer使用了两种收集数据的方式,一种是消费OpenStack各个服务内发出的notification消息(对应上图中的蓝色箭头),一种 是通过调用各个服务的API去主动的获取数据(对应上图中的黑色箭头)。
为什么会需要两种方式呢?
Ceilometer作为OpenStack内部 notification的最大消费者,OpenStack内部发生的一些事件都会发出对应的notification消息,比如说创建和删除instance,这些 信息是计量/计费的重要信息,因此第一种方式是Ceilometer第一数据来源,但是有些计量信息通过notification消息是获取不到的, 比如说instance的CPU的运行时间,或者是CPU的使用率,这些信息不会通过notification消息发送出来,因此Ceilometer增加了第二种 方式,周期性的调用相关的API去获取这些信息。
Ceilometer由5个重要的组件以及一个Message Bus组成,简单介绍一下各个组件以及他们之间的关系:
(1) Compute Agent
该组件用来收集计算节点上的信息,在每一个计算节点上都要运行一个Compute Agent,该Agent通过Stevedore管理了一组pollster插件, 分别用来获取虚拟机的CPU, Disk IO, Network IO, Instance这些信息,值得一提的是这些信息大部分是通过调用Hypervisor的API来获取的, 目前,Ceilometer仅提供了Libvirt的API。
(2) Central Agent
Central Agent运行在控制节点上,它主要收集其它服务(Image, Volume, Objects, Network)的信息,实现逻辑和Compute Agent类似,但是 是通过调用这些服务的REST API去获取这些数据的。
(3) Collector
这个应该是最为核心的组件了,它的主要作用是监听Message Bus,将收到的消息以及相应的数据写入到数据库中,它是在核心架构中唯一一个 能够对数据库进行写操作的组件。除此之外,它的另一个作用是对收到的其它服务发来的notification消息做本地化处理,然后再重新发送到 Message Bus中去,随后再被其收集。
(4) Storage
数据存储现在支持MongoDB, MySQL, Postgresql和HBase,现在H3又新增加了对DB2的支持,其中MongoDB是支持最好的。
(5) REST API
像其它服务一样,Ceilometer也提供的是REST API,API是唯一一个能对数据库进行读操作的组件,虽然后来加入的Alarm API能够直接对数据库 进行读写,但是Alarm应该是一个较为独立的功能,并且它的读写量也不大
(6) Message Bus
Message Bus是整个数据流的瓶颈,所有的数据都要经过Message Bus被Collector收集而存到数据库中,目前Message Bus采用RabbitMQ实现。
(7) Pipeline
Pipeline虽然不是其中一个组件,但是也是一个重要的机制,它是Agent和Message Bus以及外界之间的桥梁,Agent将收集来的数据发送到pipeline中, 在pipeline中,先经过一组transformer的处理,然后通过Multi Publisher发送出去,可以通过Message Bus发送到Collector,或者是发送到其它的 地方。Pipeline是可配置的,Agent poll数据的时间间隔,以及Transformers和Publishers都是通pipeline.yaml文件进行配置。
整体上看,Ceilometer对数据流的处理,给人一种大禹治水的感觉。
1.3 Roadmap and status
可能由于Ceilometer的PTL Julien Danjou比较强悍,Ceilometer从一开始就保持着非常好的项目进度,这也是它能够在很短的时间内,就由孵化项目 成为OpenStack Core项目的原因之一,在Havana Release中,已经发布了2个Milestone,分别实现了10, 11个Blueprints,修复了60多个bug,正在进行 的Havana-3,有27个Blueprints,其中大部分都保持着很好的进度。
l 在H版中,一个重量级功能是给Ceilometer添加了Alarm功能,该Alarm的实现几乎跟AWS的CloudWatch Alarm一模一样。
l 在H-1中,添加的POST meter API是一个重要的API,它的实现其实是打破了Ceilometer只局限在OpenStack内部服务的限制。可以直接通过该API 向Ceilometer写入数据,而不是去写plugin,完成了Ceilometer由poll向poll+push的转变。
l 在H-2中,实现的One Meter per Pollster Plugin简洁和规范化了Ceilometer的插件机制。
l 在H-3中,也有很多BP会被实现,对API进行查询优化的Implements GROUP BY operations in API,Pipeline的Mutiple dispatcher enablement, 以及db2 support, Enable/Disable/Configure a pollster in runtime,还有一个Monitoring Physical Devices 的BP,它的实现会使 Ceilometer向监控迈出重要一步,但是该BP中间换过一个Assignee,现在进度比较慢。
1.4 计量或监控
这个问题相信很多人都比较关心,而且也经常在邮件列表中被争论,在Ceilometer的Mission中清晰的写着Its primary targets are monitoring and metering, 但是到底Ceiometer能用来做什么,为什么会有这些争论,先不忙下结论,先来看看别人是如何使用它的。
Ceilometer的PTL Julien Danjou是一个自由职业者,在很多的开源社区做过重要贡献,有很多公司雇佣他做技术Leader,近期的包括eNovance, DreamHost, Talligent 和 EISTI,而这些公司都使用Ceilometer来做billing systems,accounting solution for openstack,我想这应该是最有力的解释了。
Ceilometer在G版改变了它的Mission之后,在Monitoring方面做了一些努力,曾想和其它一些开源监控项目合并,比如三星的synaps,还有Healthnmon,但是最后由于各种原因都不了了之。G版为这个Misson做的比较重要的工作集中在数据流的导入导出上,直到H版Ceilometer才为Monitor做了一些实际工作,包括Alarming, Monitoring Physical Devices ,Ceilometer CloudWatch API,但是目前,只有Alarm的大部分代码被Merge进代码仓库中。
虽然计量和监控他们的数据相似,但是对数据的要求却 大相径庭,前者重点在Allocated,而后者重点在Utilization,Allocated这些信息能够很容易通过消费其它服务的notification消息来获得,比如通过 捕获compute.instance.create.start, compute.instance.delete.end这些Event可以比较准确的知道一个instance是否创建成功,是否删除失败,但是像Instance 的Memory Utilization, Disk Space Utilization这些数据是监控非常关心的,然而想获取这些数据却不容易,没有现成的API可以使用,写Agent,兼容性是个头疼的问题, 这也是虚拟化平台监控的难点之一,目前Ceilometer在这方面还是空白,由此在邮件列表中也引发的一次不愉快的争论。但是关于OpenStack的监控,Mirantis给出了一个解决方案,使用sFlow 来解决虚拟资源监控的难点,有兴趣可以阅读一下。
所以,最终的结论是Ceilometer做计量系统已经比较成熟,但是如果有能力hack它,使用它做监控也是可以的,毕竟它已经做了一些工作,而且有很好的扩展性,相信在 I版会在这方面投入更多精力的。
1.5 UnitedStack’s Effort
我们使用Ceilometer来做基础监控服务。从现在Ceilometer的测量指标来看,它根本不能满足我们的需求,数据来源太少,而且大部分的数据对监控来说,没有多大的价值,如果通过写插件的形式去主动的poll数据,不能满足众多应用程序通用性的需求,并且Ceilometer对虚拟资源的监控有着难以规避的问题。这些问题迫使着我们需要再次扩展Ceilometer的Mission,将它的Within OpenStack扩展到Out of OpenStack,让Ceilometer更加的开放,更加的通用。
于是,我们给Ceilometer添加了Ceilometer CloudWatch API,一是解决了数据来源的问题,很多应用程序都会提供基于AWS CloudWatch API的监控数据,我们可以无痛的收集到这些数据;二是将Ceilometer由poll模式,改造成了push+agent模式,变得更加的通用,可以使它不仅仅局限在OpenStack内部的服务,使它可以面对更多的未知的服务;三是CloudWatch API为Heat基于Ceilometer做AutoScalling提供了接口支持。
早在G版的时候,Ceilometer就想和三星公司开源的synaps合并,它是一个OpenStack的监控项目,提供CloudWatch API,但是后来由于种种原因作废了,所以,我们的patch一提出,就受到了社区的热烈欢迎,并且很快给出了修改的意见。目前,该patch仅仅实现了三个接口,还有一些问题需要修改,希望最迟在I版能Merge进社区。