java
Table of Contents
- 1 java
- 1.1 相关资料
- 1.2 基本语法
- 1.2.1 标签跳转
- 1.2.2 final
- 1.2.3 assert
- 1.2.4 位移操作
- 1.3 面向对象
- 1.3.1 构造和析构
- 1.3.2 内部类
- 1.3.3 访问修饰符
- 1.3.4 静态导入
- 1.3.5 equals编写
- 1.3.6 import顺序
- 1.4 泛型陷阱
- 1.5 JDK
- 1.5.1 Date & Calendar
- 1.5.2 Exception
- 1.5.3 StackTrace
- 1.5.4 Proxy
- 1.5.5 Class
- 1.5.6 Reflection
- 1.5.7 Runnable & Thread
- 1.5.8 Collection
- 1.5.9 JMX
- 1.6 JVM
- 1.6.1 浮点运算
- 1.6.2 GC
- 1.7 JNI
- 1.7.1 Introduction
- 1.7.2 Getting Started
- 1.7.3 Basic Types, Strings, and Arrays
- 1.7.4 Fields and Methods
- 1.7.5 Local and Gloabl References
- 1.7.6 Exceptions
- 1.7.7 The Invocation Interface
- 1.7.8 Additional JNI Features
- 1.7.9 Leveraging Existing Native Libraries
- 1.7.10 Traps and Pitfalls
- 1.7.11 Overview of the JNI Design
- 1.8 Tool
- 1.8.1 jvisualvm
- 1.8.2 hprof
1 java
1.1 相关资料
- Core Java Volume I: Fundamentals
- JVM performance optimization
- JVM performance optimization, Part 1: A JVM technology primer http://www.javaworld.com/javaworld/jw-08-2012/120821-jvm-performance-optimization-overview.html
- JVM performance optimization, Part 2: Compilers http://www.javaworld.com/javaworld/jw-09-2012/120905-jvm-performance-optimization-compilers.html
- JVM performance optimization, Part 3: Garbage collection http://www.javaworld.com/javaworld/jw-10-2012/121010-jvm-performance-optimization-garbage-collection.html
- JVM performance optimization, Part 4: C4 garbage collection for low-latency Java applications http://www.javaworld.com/javaworld/jw-11-2012/121107-jvm-performance-optimization-low-latency-garbage-collection.html
- Understanding JVM Internals | CUBRID Blog http://www.cubrid.org/blog/dev-platform/understanding-jvm-internals
- The Principles of Java Application Performance Tuning | CUBRID Blog : http://www.cubrid.org/blog/dev-platform/the-principles-of-java-application-performance-tuning/
- Understanding JVM Internals, from Basic Structure to Java SE 7 Features | Architects Zone http://architects.dzone.com/articles/understanding-jvm-internals
1.2 基本语法
1.2.1 标签跳转
label break/continue似乎非常必要,这种情况尤其见于多重循环,如果想直接调到最外层循环(break),或者是从外层循环继续执行(continue).缺少这种机制的话,外层循环只能够使用蹩脚的标记,一层层地逐层跳出。
class X{
public static void main(String[] args){
int i=0;
int j=0;
out:
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if((i+j)==15){
break out;
}
}
}
System.out.println(i+","+j);
}
}
1.2.2 final
final关键字应该是有下面几个用途:
- 如果放在class之前的话,那么这个class则不允许被继承。
- 如果放在method之前的话,那么这个method则不允许被override.
- 如果放在field之前的话,那么这个field则不允许被修改。(但是因为java出了基本类型之外,其他类型都是对象类似于C++指针。这里不允许被修改,是指指针本身不允许修改,而对于指针所指对象是允许被修改的)
1.2.3 assert
java关键字assert可以用来进行断言,和C++一样。但是天煞的java虚拟机必须指定标记才会开启assert特性。java -ea断言才会生效。java -ea:package_name…可以指定名字空间下所有类断言打开,java -ea:classname可以指定某个类断言打开。如果不带任何参数的话那么是将所有断言打开。同样使用-da可以禁用某个特定类或者是包的断言。 NOTE(dirlt):其实想想觉得这个还是很不错的,在运行时控制而不是在编译时控制,会让更多的人喜欢使用assertion.但是我觉得默认的话,应该是开启的除非显示关闭。
java断言可以指定检查表达式以及出错表达式,asser 条件:表达式
class X{
public static void main(String[] args) {
assert 0==1 : "omg";
}
}
有些类不是由类加载器加载,而是直接由虚拟机加载。使用-ea/-da不能够应用到这些类上面。对于系统类来说,需要使用-esa/-dsa来控制断言。
1.2.4 位移操作
java提供了三种位移操作符:
- 逻辑右移 >> (保持高位)
- 逻辑左移 <<
- 算术右移 >>> (丢弃高位用0填充)
注意java只提供了有符号整数
class X{
public static void main(String[] args){
int x=(1 << 31);
assert((x >>> 1) == (1 << 30));
assert((x >> 1) == ((1 << 31) | (1 << 30)));
assert((x << 1) == 0);
}
}
1.3 面向对象
1.3.1 构造和析构
java相对于C++来说,在对象构造上面,需要多考虑初始化块这个概念(包括静态初始化块)。所谓初始化块,可以在对象执行构造函数之前执行的一 块代码。而静态初始化块,当引用到这个类的时候第一次就会执行。有了这个特性之后,我们就可以创建不需要使用main就可以运行的例子
class App {
static {
System.out.println("hello,world");
System.exit(0);
}
}
另外相对于C++来说,java的字段都可以通过简单的赋值就完成初始化,而不需要像C++在构造函数后面接上一推init variable list.
整个java对象构造过程大致如下:
- 对象加载时,按照声明顺序,初始化静态字段,以及执行静态初始化块。
- 对象创建时,按照声明顺序,初始化字段,以及执行初始化块。
- 执行对象的构造函数。
对于构造函数来说,如果需要调用父类构造函数可以使用super(…),如果需要调用同类内部其他重载版本可以使用this(…)
java提供了一个finalize方法,但是这个方法并不是在析构时候执行,而是在被GC之前执行,但是你很难知道这个对象什么时候会被GC.因此最好 不要复写这个方法。如果想在GC之前做一些事情的话,可以通过Runtime.addShutdownHook添加钩子来在GC之前触发。
1.3.2 内部类
引入内部类(inner class)主要有下面三个原因:
- 内部类可以访问该类定义所在的作用域中数据,包括私有数据。
- 内部类可以对同一个包中的其他类隐藏起来。
- 当想要定义一个回调函数且不想编写大量代码时,使用匿名类(anonymous)比较便捷。
关于java的内部类大概有这么几种:
- 内部类。(可以访问到外围类实例)
- 静态内部类。(C++嵌套类和静态内部类更相似)
- 局部类。(通常在方法内使用,可以访问到外围类实例以及方法中final参数)
- 匿名内部类。(局部类一种特例,方便做一个接口简单扩展)
- 内部类
class X{ private int x=1; class Y{ void foo(){ System.out.println(x); } } public static void main(String[] args){ X x=new X(); Y y=x.new Y(); y.foo(); } }内部类生成class使用$分隔,所以可以看到X$Y.class文件。可以看到在Y里面访问x字段。原理非常简单,在Y内部生成了X的一个实例指针,同时在X里面为x字段提供了一个静态访问方法。
class X extends java.lang.Object{ X(); public static void main(java.lang.String[]); static int access$000(X); // 在X中静态访问方法 } class X$Y extends java.lang.Object{ final X this$0; // 在Y里面提供了外围实例指针 X$Y(X); void foo(); }了解了这些之后对于x.new Y()这样的语法就好理解了。我们首先需要一个外围实例,才能够构造Y对象出来。
- 静态内部类
但是并不是所有内部类都需要访问外围实例的。如果没有这样需求的话,我们就可以使用静态内部类static class Y.可以使用X.Y进行引用。
- 局部类
局部类是在方法中定义的内部类,生成类的规则就是X$1Y.class.1使用数字来标记区分不同的方法。class X{ private int x=1; void foo(final int y){ class Y{ void foo(int z){ System.out.println(x+","+y+","+z); } } Y iy=new Y(); iy.foo(20); } public static void main(String[] args){ X x=new X(); x.foo(10); } }这里要求参数为final原因很简单。因为局部类需要将这个参数在构造的时候就拿过来放在自己类中。final的话语义上会比较好理解。可以看看生成class内容
class X$1Y extends java.lang.Object{ final int val$y; // 这里将外部y捕获。 final X this$0; X$1Y(X, int); // 构造函数传入y void foo(int); }
- 匿名类
匿名类编写回调或者是特定的接口扩展非常方便,当然也可以容易地扩展一个类。class X{ public static void main(String[] args) throws InterruptedException { Thread y=new Thread() { // 这个地方需要传入基类的构造参数。 public void run() { for(int i=0;i<10;i++){ System.out.println("run..."); } } }; y.start(); y.join(); } }生成的类名称为X$1.class.其中1是数字用来区别匿名类。注意匿名类都是final的。
final class X$1 extends java.lang.Thread{ X$1(); public void run(); }
1.3.3 访问修饰符
java有下面4个访问修饰符可以用来控制可见性:
- private:仅对本类可见。
- public:对所有类可见。
- protected:对本包和所有子类可见。
- 默认:对本包可见。
访问修饰符可以作用在类,方法以及字段上面,控制可见性效果是相同的。
1.3.4 静态导入
所谓静态导入,就是可以导入某个类下面的静态方法以及静态域,通常来说这样可以使得代码更容易阅读,比如
import static java.lang.Math.*;
class App {
public static void main(String[] args){
// System.out.println(Math.sqrt(Math.pow(3,2)+Math.pow(4,2)));
System.out.println(sqrt(pow(3,2)+pow(4,2)));
}
}
1.3.5 equals编写
- 对于参数必须是Object arg. boolean equals(Object arg)
- 检测两个对象是否相同,可以节省判断开销。if(this == arg) return true;
- 判断arg是否为null. if(arg == null) return false;
- 如果要求判断两者类型必须相同,那么通过getClass判断Class对象是否相同。if(getClass() != arg.getClass()) return false;
- 如果仅仅是想在语义上判断相同的话,那么使用instanceof判断。通常情况是,好比A,B都是容器实现,B extends A.只不过B是A另外一种实现。对于AB来说他们hold数据都是相同的。这种情况下面就是语义的判断相同。可以通过arg instanceof A.class来判断是否为A子类。
- 转换成为相同类型之后逐个比较字段。
1.3.6 import顺序
有时候import顺序还是比较重要的,比如下面这个程序com/dirlt/X.java
/* coding:utf-8
* Copyright (C) dirlt
*/
package com.dirlt;
import com.dirlt.X.B.A;
import java.util.ArrayList;
public class X{
public static class B extends ArrayList {
public class A{
}
}
}
编译会出现如下问题
➜ ~ javac com/dirlt/X.java
com/dirlt/X.java:10: cannot find symbol
symbol : class ArrayList
location: class com.dirlt.X
public static class B extends ArrayList {
^
1 error
这个import顺序intellj认为是正确的,而且只需要反转两个import的顺序就可以正常编译。 NOTE(dirlt):因此我花了比较多的时间纠结在这个问题上面,因为intellij不太可能错误把,而且问题也比较诡异 我不太理解java的导入顺序,但是猜想和C++的include非常类似,出现上面的问题可能就是循环依赖导致的问题
- 当我们引入com.dirlt.X.B.A的时候,javac会去分析这个文件X.java(or X.class)
- 因为引入的是B下面的子类,因此肯定需要分析B这个类
- 而B继承ArrayList这个类,但是javac在当前的名字空间下面找不到ArrayList所以报错
解决这个问题最好的办法,我觉得应该就是: 对于文件内部本身的类,不要使用import来导入,直接使用全称即可。
1.4 泛型陷阱
TODO(dirlt):
1.5 JDK
1.5.1 Date & Calendar
其实一开始Date是想做成日历的。所谓日历就是说能够处理年月日这些信息。但是Date本身处理比较差,没有考虑闰秒这种东西,另外因为日历仅仅 是历法其中的一种,虽然广泛使用。因此有必要将历法单独形成一个类称为Calendar,而日历是历法的一种实现在Java里面是 GregorianCalendar.而现在Date仅仅用于保存一个绝对的时间点就是时刻,保存的方法就是相对于某一固定时间点的毫秒数,而这个时间点 就称为纪元(epoch),它是UTC 1970.1.1 00:00:00。
因此我们在比较时刻方面的话,可以使用Date,而在处理历法方面的话需要使用GregorianCalendar.
1.5.2 Exception
java里面异常都是派生于Throwable,但是分解成为两个分支:
- Error.描述Java运行时系统的内部错误和资源耗尽。应用程序不应该抛出该类型对象。
- Exception.分解为RuntimeException(运行时异常)和其他(编译时异常)。
RuntimeException包括下面几种情况:
- 错误类型转换。
- 数组访问越界。
- 访问空指针。
java语言规范将派生于Error或者是RuntimeException的所有异常称为未检查异常(unchecked exception),而将所有其他异常(也就是编译时异常)称为已检查异常(checked).称为已检查异常原因是因为,java的异常规格也是作为 函数声明的一部分的。因此如果方法foo抛出异常X,那么调用foo的方法,要么检查异常X,要么就在自己的规则里面写上throws X传给上层处理,无论如何你都是需要面对这个异常的,所以称为已检查。
- 抛出异常非常简单,使用new Exception()即可
- 创建异常的话继承Throwable即可,构造参数可以传入message表示这个异常的详细信息。
- 如果重新抛出异常的话会将异常链断开,可以通过调用initCause将原始的cause保存起来,getCause可以取出。这样可以保持异常链完整信息。
1.5.3 StackTrace
- 使用Thread.getStackTrace获得某个线程的堆栈信息
- 使用Thread.getAllStackTrace可以获得所有线程的堆栈信息
- 异常对象可以使用e.printStackTrace打印堆栈信息
1.5.4 Proxy
使用代理可以动态地生成一些类或者是接口(但是不是动态生成代码)。创建一个代理对象,使用Proxy类的newProxyInstance方法,有下面三个参数:
- 类加载器(class loader).null表示使用默认加载器。
- class对象数组。表示想实现的接口。
- 调用处理器(invocation handler)。可以截获方法调用然后做代理。
调用处理器接口为Object invoke(Object proxy, Method method, Object… args).其中proxy表示代理对象本身,method,args表示调用方法以及参数。
import java.util.logging.*;
import java.lang.reflect.*;
class X{
public static void main(String[] args) throws InterruptedException {
final Runnable r=new Runnable() {
public void run() {
for(int i=0;i<10;i++){
System.out.println("run...");
}
}
};
Runnable proxy=(Runnable)Proxy.newProxyInstance(r.getClass().getClassLoader(),new Class[]{Runnable.class}, new InvocationHandler() {
public Object invoke(Object proxy, Method m, Object[] args){
System.out.println("entering...");
try {
return m.invoke(r,args);
} catch(Exception ex){
return null;
}
}
});
Thread t=new Thread(proxy);
t.start();
t.join();
}
}
- java没有定义代理类的名字,sun虚拟机中的Proxy类将生成一个以字符串$Proxy开头的类名。
- 对于特定的类加载器和预设的一组接口来说,只能够有一个代理类。也就是说,如果使用同一个类加载器刚和接口数组调用newProxyInstance方法两次的话,那么只能够得到同一个类的两个对象。
- 可以使用Proxy.getProxyClass获得对应代理类,通过Proxy.isProxyClass判断某个类是否为代理类。
1.5.5 Class
Class类本身表示这个类的一些元信息。通常拿到这个类的元信息之后,就可以完成一些动态事情比如反射。java有三种方式可以获得Class类:
- 对象调用getClass()方法。
- 字面量直接获取 App.class
- 通过类名动态查找 Class.forName("java.util.Date")
获得Class之后,就可以获取到这个class内部:
- fields
- methods
- constructors
这样就可以开始做一些反射工作了。 NOTE(dirlt):more about reflection
1.5.6 Reflection
1.5.7 Runnable & Thread
线程包括下面6种状态,并且切换关系如下:
- new 线程创建好并且分配资源但是没有运行,调用start进入runnable状态。
- runnable 正在运行的状态。运行过程中如果调用return或者是exit的话,那么进入terminated状态。
- terminated 线程已经被终止并且进行资源回收。
- blocked 在runnable时候,如果acquire lock失败的话那么会进行block状态,当获得锁之后那么返回runnable状态。
- waiting 在runnable时候,如果等待notification那么进行这个状态,如果notification触发的话那么返回runnable状态。
- timed waiting 其实和waiting状态差不多,只不过这个notification状态会存在一个超时。
守护线程(daemon)和unix操作系统的daemon有些差别。在java里面如果还有存活的线程的话,即使main线程完毕那么程序依然不会结束 (这个在c/c++程序里面则不然)。如果将线程设置成为daemon状态的话,那么最后剩下的线程都是daemon的话,那么jvm也会自动退出。
Runnable的run方法是不允许抛出任何异常的,对于可检查的异常可以在代码里面完成,而对于不可检查的异常因为不能够处理,因此如果触发的话那么线程终止。而对于可检查异常如果没有处理的话,那么在线程死亡之前,异常会被一个异常处理器处理:
- Thread.UncaughtExceptionHandler接口(void uncaughtException(Thread t,Throwable e) ),通过setUncaughtExceptionHandler为单个线程安装处理器,也可以通过 setDefaultUncaughtExceptionHandler为所有线程安装。
- 默认处理器为空。如果线程安装的话,那么使用该线程的ThreadGroup对象作为异常处理器
- 如果这个线程存在父线程组,那么交给父线程组处理。
- 如果Thread.getDefaultUncaughtExceptionHandler为非空的话那么调用。
- 如果Throwable为ThreadDeath实例,那么什么也不做。
- 将线程名字和Throwable的stacktrace输出到stderr上面。
synchronized关键字其实有两个场景
- 如果作用于对象或者是对象方法的话,那么其实相当是同步这个对象(对象存在一个mutex lock)
- 如果作用于静态字段或者是静态方法的话,那么其实相当是同步这个类(类有一个mutex lock)
一旦理解这点之后,就比较好理解為什麼存在
- wait
- notify
- notifyAll
这些方法了。其实都是相当于这个lock对应的condition本身提供的方法。
volatile关键字为 实例字段 的同步访问提供了一种免锁机制。如果声明一个字段为volatile的话,那么编译器和虚拟机就可以知道这个字段很可能会被另外一个线程并发更新。 NOTE(dirlt):在我看来使用volatile最好是作用在基本类型上面,这里将对象指针本身也作为基本类型来看待=D
為什麼抛弃stop和suspend方法? 其实这点非常好理解,因为这些方法都尝试破坏线程本身正常的行为。比如A,B两个线程同时acquire一个lock,如果A成功之后,B在等待,这个之后A被stop或者是suspend的话,那么情况就变成了死锁。
1.5.8 Collection
TODO(dirlt):
1.5.9 JMX
- jmxtrans/jmxtrans · GitHub https://github.com/jmxtrans/jmxtrans
- Trail: Java Management Extensions (JMX) (The Java™ Tutorials) http://docs.oracle.com/javase/tutorial/jmx/index.html
- Lesson: Introducing MBeans (The Java™ Tutorials > Java Management Extensions (JMX)) http://docs.oracle.com/javase/tutorial/jmx/mbeans/index.html
- Standard MBeans (The Java™ Tutorials > Java Management Extensions (JMX) > Introducing MBeans) http://docs.oracle.com/javase/tutorial/jmx/mbeans/standard.html
jmx似乎是一个标准,在JDK里面有默认的实现。通过jmx可以暴露jvm进程的一些运行参数以及系统状态(jdk默认实现),也可以暴露应用程序状态 (需要自己实现),在jvm内部用单独的线程以server运行。外部client可以通过jmx协议访问,然后输出到其他terminal上面(比如 opentsdb, ganglia等,jmxtrans就是做这个事情的)。
我大致阅读了一下代码,在server有两个比较重要的概念:agent(mbean server)和mxbean. agent(mbean server)类似server启动,mxbean则是各个data source. 但是从jdk默认的实现(ManagementFactory::getPlatformMBeanServer)里面可以看到,mxbean不是一个静 态基类,而是通过反射的方式将mxbean类转换成为DynamicMBean(猜测数据传输格式应该是JPO,Java Persistent Object,也就是java对象自带序列化方式,这种方式的好处就是没有限制data source format,但是却复杂了实现)。
- com.dirlt.java.playboard.SimpleJMX 例子比较简单,显示和修改数据 NOTE(dirlt):只有基本类型可以显示和修改。如果数据类型为object的话,那么不能显示和修改
- MXBean允许做RMI
- Notifcation允许RMI之后做通知
- so advanced, so powerful, yet so complex
1.6 JVM
1.6.1 浮点运算
float类型数值常量后面加上F比如3.042F,而double类型数值常量后面加上D比如3.402D.所有浮点数值计算都遵循IEEE 752规范。java提供了三种表示溢出或者计算错误的三种特殊浮点数值:
- 正无穷大 Double.POSITIVE_INFINITY
- 负无穷大 Double.NEGATIVE_INFINITY
- NaN(不是数字) Double.NaN. 浮点数/0的话就会得到NaN.判断是否为NaN不应该使用==因为和一个NaN比较始终都是false,而应该使用Double.isNaN(x)
对于较大浮点数应该使用BigDecimal来进行计算。
java虚拟机规范强调可移植性,对于在任何机器上来说相同的程序得到的结果应该是相同的。但是对于浮点计算的话,比如Intel CPU针对于浮点数计算所有中间结果都使用bit 80表示,而最后截取bit 64,造成和其他CPU计算结果不同。为了达到可移植性,java规范所有中间结果必须使用bit 64截断,但是遭反对,因此java提供了strictfp关键字标记某个方法,对于这个方法里面所有浮点数计算,所有中间结果使用64 bit截断,否则使用适合native方式计算。另外一些浮点数计算比如pow2,pow3,sqrt的话,一方面依赖于CPU浮点计算方式,另外一方面 依赖于本身算法(如果CPU本身提供这种指令的话就可以使用CPU指令),也会造成不可移植性,比如Math.sqrt.如果希望在这方面也达到同样效果 的话,可以使用StrictMath类,底层使用fdlibm,以确保所有平台上得到相同的结果。
1.6.2 GC
- Sun jdk 1.6 gc http://www.slideshare.net/BlueDavy/sun-jdk-16-gc
- Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning : http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html
- Performance Tuning Garbage Collection in Java : http://www.petefreitag.com/articles/gctuning/
- java - Garbage Collection and Threads - Stack Overflow : http://stackoverflow.com/questions/2085544/garbage-collection-and-threads
1.7 JNI
- Java Native Interface: Programmer's Guide and Specification http://192.9.162.55/docs/books/jni/ NOTE(dirlt):比较详细
1.7.1 Introduction
The JNI is designed to handle situations where you need to combine Java applications with native code. As a two-way interface, the JNI can support two types of native code: native libraries and native applications. (允许相互调用)
- You can use the JNI to write native methods that allow Java applications to call functions implemented in native libraries. (native libraries通过native methods被JVM调用)
- The JNI supports an invocation interface that allows you to embed a Java vir-tual machine implementation into native applications.(native applications通过invocation interface调用JVM)
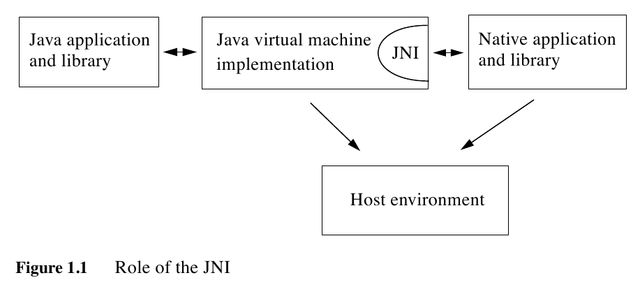
下面是一些JNI的代替方案 NOTE(dirlt):主要都是通过进程间通信来完成的
- A Java application may communicate with a native application through a TCP/IP connection or through other inter-process communication (IPC) mechanisms.
- A Java application may connect to a legacy database through the JDBC API.
- A Java application may take advantage of distributed object technologies such as the Java IDL API.
下面是一些JNI比较适合的场景
- The Java API might not support certain host-dependent features needed by an application. An application may want to perform, for example, special file operations that are not supported by the Java API, yet it is both cumbersome and inefficient to manipulate files through another process.(在一些host上面非常特殊的操作)
- You may want to access an existing native library and are not willing to pay for the overhead of copying and transmitting data across different processes. Loading the native library in the same process is much more efficient.(进程之间通信需要拷贝传输大量的数据)
- Having an application span multiple processes could result in unacceptable memory footprint. This is typically true if these processes need to reside on the same client machine. Loading a native library into the existing process hosting the application requires less system resources than starting a new pro-cess and loading the library into that process.(单独的进程会存在相当的overhead)
- You may want to implement a small portion of time-critical code in a lower-level language, such as assembly. If a 3D-intensive application spends most of its time in graphics rendering, you may find it necessary to write the core por-tion of a graphics library in assembly code to achieve maximum performance.(控制底层提高性能效率)
1.7.2 Getting Started
主要介绍的是native methods编写,JVM通过so来调用native methods.这里给出一个无参native mthods例子。
- javac Hello.java 生成 Hello.class
- javah -jni Hello 生成 Hello.h
- 编写 Hello.cc 使用 Hello.h 生成 libHello.so # g++ Hello.cc -fPIC -o libHello.so -shared -I$JAVA_HOME/include
- 将 libHello.so 加入到library path.
- 然后 java Hello 启动
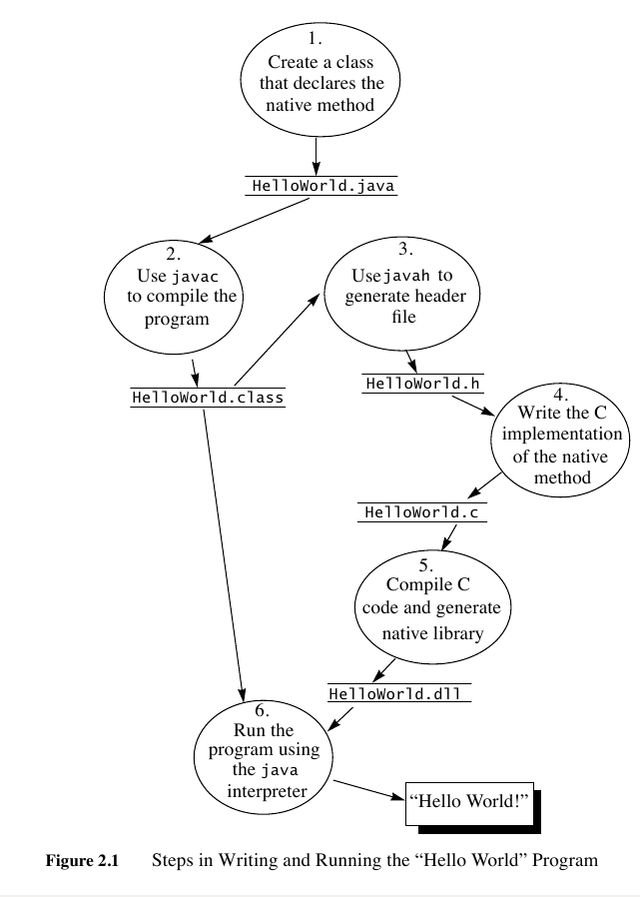
- Hello.java
/* coding:utf-8 * Copyright (C) dirlt */ public class Hello { private static native void run(); public static void main(String[] args) { System.loadLibrary("Hello"); run(); } }
- Hello.h
/* DO NOT EDIT THIS FILE - it is machine generated */ #include <jni.h> /* Header for class Hello */ #ifndef _Included_Hello #define _Included_Hello #ifdef __cplusplus extern "C" { #endif /* * Class: Hello * Method: run * Signature: ()V */ JNIEXPORT void JNICALL Java_Hello_run (JNIEnv *, jclass); #ifdef __cplusplus } #endif #endif
- Hello.cc
/* coding:utf-8 * Copyright (C) dirlt */ #include <cstdio> #include "Hello.h" JNIEXPORT void JNICALL Java_Hello_run (JNIEnv * env, jclass cls) printf("Hello,World\n"); }
1.7.3 Basic Types, Strings, and Arrays
- The static initializer calls the System.loadLibrary method to load a native library called Prompt.
- 使用System.loadLibrary来载入动态库
- The JNIEXPORT and JNICALL macros (defined in the jni.h header file) ensure that this function is exported from the native library and C compilers generate code with the correct calling convention for this function
- JNIEXPORT用来导出函数声明,JNICALL用来规定函数调用方式
- The name of the C function is formed by concatenating the “Java_” prefix, the class name, and the method name.
- Java_作为前缀,然后是class name,然后是method_name
- The first parameter, the JNIEnv interface pointer, points to a location that contains a pointer to a function table.
- JNIEnv定义了JNI所有可以访问JVM对象的接口方法
- NOTE(dirlt):这个接口在$JAVA_HOME/include/jni.h里面有定义
- The second argument to an instance native method is a reference to the object on which the method is invoked, similar to the this pointer in C++. The second argument to a static native method is a reference to the class in which the method is defined.
- 如果是static方法的话,那么参数是指class对象
- 如果不是static方法的话,那么参数是指object对象
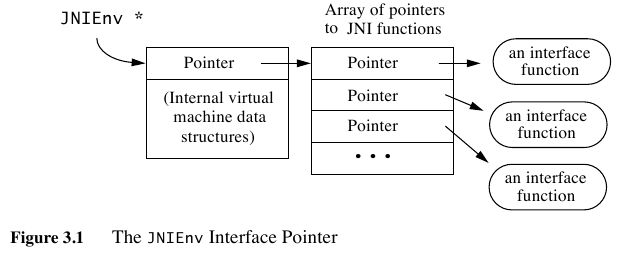 NOTE(dirlt):可以看到在pointer下面还有一个internal VM数据块,这个是线程级别的私有数据跟在pointer之后,可以通过指针偏移进行访问
NOTE(dirlt):可以看到在pointer下面还有一个internal VM数据块,这个是线程级别的私有数据跟在pointer之后,可以通过指针偏移进行访问
对于类型还说分为primitive和reference两种类型,reference type都是opaque pointer获取数据必须通过JNIEnv接口提供的方法才能够获得。 至于具体类型是pritmitive还是reference的话,可以通过阅读jni.h和jni_md.h来判断。primitive type只有下面几种 NOTE(dirlt):in jni_md.h
#ifndef _JAVASOFT_JNI_MD_H_ #define _JAVASOFT_JNI_MD_H_ #define JNIEXPORT #define JNIIMPORT #define JNICALL typedef int jint; #ifdef _LP64 /* 64-bit Solaris */ typedef long jlong; #else typedef long long jlong; #endif typedef signed char jbyte; #endif /* !_JAVASOFT_JNI_MD_H_ */
1.7.4 Fields and Methods
NOTE(dirlt):field和method的访问接口,非常类似google::protobuf提供的reflection接口
Field操作:
- GetObjectClass获取object所属的class对象,类型是jclass
- 如果是本地静态方法的话,那么传入参数应该就是class对象 NOTE(dirlt):FindClass
- NOTE(dirlt):应该也可以通过类加载器来获取
- GetFieldID/GetStaticFieldID根据field descriptor获取field id,类型是jfieldID.
- field descriptor字符串可以通过javap -s -p <class>来获取
- 字符串称为JNI field descriptor
- I int
- F float
- D double
- Z boolean
- / 代替package name中的.
- [ array
- L reference
- V void
- 比如如果是String[]的话,那么就是"[Ljava/lang/String;"
- Get<type>Field/GetStatic<type>Field获取field data.
- Set<type>Field/GetStatic<type>Field设置field data.
Method操作:
- 获取jclass
- GetMethodID/GetStaticMethodID根据method descriptor获取method id,类型是jmethodID.
- method descriptor同样可以使用javap来获得
- 字符串形式如下"(arg types)return type"
- 比如如果是void f(String arg),那么就是"(Ljava/lang/String;)V"
- Call<Type>Method/CallStatic<Type>Method来调用method.
- 如果调用superclass method的话,那么调用CallNonvirtual<Type>Method.
- 构造函数的名称是"<init>" (返回参数是void类型)
- NewObject分配空间并且调用构造函数
- AllocObject只是开辟空间需要自己调用构造函数
Cache fieldID/methodID:
- 每次查找ID的代价非常大,通过cache可以避免
- 第一种方法是每次查找的时候都判断是否为null,如果为null那么查找然后缓存起来。
- 第二种方法是在类static区域调用初始化函数,初始化函数一次性获取所有的ID然后缓存。
- 可以认为第一种方法就是lazy evaluation.
Let us start by comparing the cost of Java/native calls with the cost of Java/Java calls. Java/native calls are potentially slower than Java/Java calls for the fol-lowing reasons: (Java/Java calls和Java/native calls的对比,Java/native calls通常更慢):
- Native methods most likely follow a different calling convention than that used by Java/Java calls inside the Java virtual machine implementation. As a result, the virtual machine must perform additional operations to build argu-ments and set up the stack frame before jumping to a native method entry point.(额外操作来建立stack frame调用native method)
- It is common for the virtual machine to inline method calls. Inlining Java/native calls is a lot harder than inlining Java/Java calls. (inline方面Java/Java calls更容易做)
The overhead of field access using the JNI lies in the cost of calling through the JNIEnv. Rather than directly dereferencing objects, the native code has to per- form a C function call which in turn dereferences the object. The function call is necessary because it isolates the native code from the internal object representa-tion maintained by the virtual machine implementation. The JNI field access over-head is typically negligible because a function call takes only a few cycles.(字段访问开销主要是通过一次得到ID间接访问造成的,但是这样带来的收益是能够将内部object表示不暴露出来,但是索性的是带来的开 销并不大)
NOTE(dirlt):我理解这里的意思主要是说在调用和字段访问方面,Java/native calls的开销更大,但是native methods本身在运行速度上可能会带来更大的收益
1.7.5 Local and Gloabl References
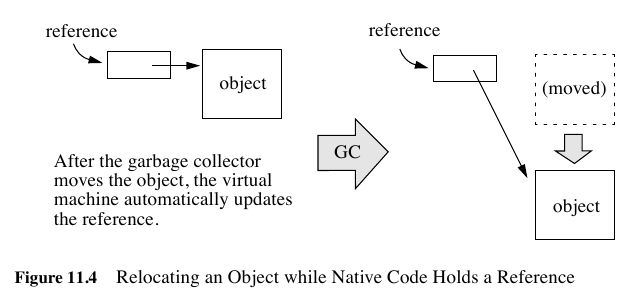
reference和GC非常相关,决定了哪些对象作用域多大以及生命周期多长:
- The JNI supports three kinds of opaque references: local references, global references, and weak global references.
- Local and global references have different lifetimes. Local references are automatically freed, whereas global and weak global references remain valid until they are freed by the programmer.
- A local or global reference keeps the referenced object from being garbage collected. A weak global reference, on the other hand, allows the referenced object to be garbage collected.
分为三类references:
- local 对象超过函数作用域之后就会自动释放
- Why do you want to delete local references explicitly if the virtual machine automatically frees them after native methods return? A local reference keeps the referenced object from being garbage collected until the local reference is invali-dated.
- 但是也可以显示标记不需要这个对象,这样可以减少无用对象的持有。使用DeleteLocalRef来标记。*NOTE(dirlt):似乎对于每一个native method最多支持16个local reference.
- NewLocalRef/DeleteLocalRef.
- JDK1.2以上有另外的方法支持很多local reference NOTE(dirlt):不过似乎没有什么太大的意思
- EnsureLocalCapacity 确保这个frame至少之后可以分配多少个local ref
- PushLocalFrame/PopLocalFrame 新建和释放一个local frame.这样可以开辟更多的local ref.
- global 对象生命周期直到程序结束
- NewGlobalRef/DeleteGlobalRef
- weak global 和global非常类似,但是可以通过操作标记这个对象不在需要然后被GC
- NewGlobalWeakRef/DeleteGlobalWeakRef
- IsSameObject 能够判断两个reference是否相同
- 如果传入NULL的话表示,对于local和lglobal表示对象是否为null,对于weak global来说的话判断这个对象是否依然指向一个lived object而没有被回收。
1.7.6 Exceptions
- Throw 抛出已有异常
- ThrowNew 创建异常对象抛出
- ExceptionOccurred 获得pending exception.
- ExceptionCheck 检查是否存在pending exception.
- ExceptionDescribe 打印pening exception描述信息
- ExceptionClear 清除pending exception状态
- FatalError 打印fatal信息
JNI programmers may deal with an exception in two ways:
- The native method may choose to return immediately, causing the exception to be thrown in the code that initiated the native method call.
- The native code may clear the exception by calling ExceptionClear and then execute its own exception-handling code.
It is extremely important to check, handle, and clear a pending exception before calling any subsequent JNI functions.
native code如果不处理异常的话,可以直接返回交给caller来处理异常。如果是自己处理异常的话,获得具体异常之后最好立刻清除状态,然后做后续操作。
Calling most JNI functions with a pending exception leads to undefined results. The following is the complete list of JNI functions that can be called safely when there is a pending exception:
- ExceptionOccurred
- ExceptionDescribe
- ExceptionClear
- ExceptionCheck
- ReleaseStringChars
- ReleaseStringUTFchars
- ReleaseStringCritical
- Release<Type>ArrayElements
- ReleasePrimitiveArrayCritical
- DeleteLocalRef
- DeleteGlobalRef
- DeleteWeakGlobalRef
- MonitorExit
1.7.7 The Invocation Interface
NOTE(dirlt):代码整个过程还是比较清晰的
/* coding:utf-8
* Copyright (C) dirlt
*/
#include <cstdio>
#include <cstdlib>
#include <jni.h>
static JNIEnv* env;
static JavaVM* jvm;
void destroy() {
if (env->ExceptionOccurred()) {
env->ExceptionDescribe();
}
jvm->DestroyJavaVM();
}
int main() {
JavaVMInitArgs vm_args;
JavaVMOption options[1];
options[0].optionString = "-Djava.class.path=.";
vm_args.version = JNI_VERSION_1_6;
vm_args.options = options;
vm_args.nOptions = 1;
vm_args.ignoreUnrecognized = JNI_TRUE;
/* Create the Java VM */
jint res = JNI_CreateJavaVM(&jvm, (void**)&env, &vm_args);
if (res < 0) { // can't create jvm.
fprintf(stderr, "Can't create Java VM\n");
exit(1);
}
jclass cls = env->FindClass("Hello");
if (cls == NULL) { // can't find class.
destroy();
}
jmethodID mid = env->GetStaticMethodID(cls, "main", "([Ljava/lang/String;)V");
if (mid == NULL) { // no main method.
destroy();
}
jstring jstr = env->NewStringUTF(" from C!");
if (jstr == NULL) {
destroy();
}
jclass stringClass = env->FindClass("java/lang/String");
jobjectArray args = env->NewObjectArray(1, stringClass, jstr);
if (args == NULL) {
destroy();
}
env->CallStaticVoidMethod(cls, mid, args);
destroy();
}
➜ ~ g++ Hello.cc -I$JAVA_HOME/include -L$JAVA_HOME/jre/lib/amd64/server -ljvm Hello.cc: In function ‘int main()’: Hello.cc:22:29: warning: deprecated conversion from string constant to ‘char*’ [-Wwrite-strings] ➜ ~ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$JAVA_HOME/jre/lib/amd64/server ➜ ~ ./a.out Hello,World
可以通过创建一个JVM来将多个线程attach上去,相当于这个JVM启动的多个线程。这里的线程使用的是OS native thread实现。
- AttachCurrentThread
- DetachCurrentThread
1.7.8 Additional JNI Features
- JNI and Threads
- MonitorEnter/MonitorExit可以操作monitor. NOTE(dirlt):对应java里面的synchronized关键字区域
- Registering Native Methods
允许动态注册native methods.
- Load and Unload Handlers
系统加载和卸载native library回调函数:- JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM *jvm, void *reserved); // 返回JNI版本比如 JNI_VERSION_1_6
- JNIEXPORT void JNICALL JNI_OnUnload(JavaVM *jvm, void *reserved)
load/unload工作流程是这样的:
- The virtual machine associates each native library with the class loader L of the class C that issues the System.loadLibrary call. // 每次加载的时候创建ClassLoader,并且记录这个ClassLoader关联了哪些对象。
- The virtual machine calls the JNI_OnUnload handler and unloads the native library after it determines that the class loader L is no longer a live object. Because a class loader refers to all the classes it defines, this implies that C can be unloaded as well. // 如果ClassLoader里面没有任何live object的话,那么就会被GC
- The JNI_OnUnload handler runs in a finalizer, and is either invoked synchro-niously by java.lang.System.runFinalization or invoked asynchro-nously by the virtual machine. // unload可能会被同步调用也可能会被异步调用。
NOTE(dirlt):因此如果ClassLoader里面关键了global reference的话那么这个class loader是不会被卸载的
1.7.9 Leveraging Existing Native Libraries
如何使用现有的native library:
- one-to-one mapping. 针对每个函数做一个包装,外部做类型转换.
- shared stubs. 做一个dispatcher函数,根据所传参数包装成为合适的C++类型,然后直接传给C++函数。但是调用C++函数这个部分需要自己实现函数调用栈 *NOTE(dirlt):文章里面是asm_dispatch)
NOTE(dirlt):个人觉得one-to-one mapping虽然实现比较麻烦,可是用起来比较简单,而shared stubs则相反。自己完全可以实现一些简单的common library来简化编写过程
1.7.10 Traps and Pitfalls
- Error Checking
- Passing Invalid Arguments to JNI Functions
- Confusing jclass with jobject
- Truncating jboolean Arguments
- Boundaries between Java Application and Native Code
- Confusing IDs with References
- Caching Field and Method IDs
- Terminating Unicode Strings
- Violating Access Control Rules
- Disregarding Internationalization
- Retaining Virtual Machine Resources
- Excessive Local Reference Creation
- Using Invalid Local References
- Using the JNIEnv across Threads
- Mismatched Thread Models
1.7.11 Overview of the JNI Design
Locating Native Libraries
- System.loadLibrary throws an UnsatisfiedLinkError if it fails to load the named native library. 如果找不到native library就会抛出UnsatisfiedLinkError异常。
- System.loadLibrary completes silently if an earlier call to System.loadLibrary has already loaded the same native library. 如果已经加载的话就不会重复加载。
- If the underly-ing operating system does not support dynamic linking, all native methods must be prelinked with the virtual machine. 如果不支持动态链接的话就只能够预先链接做静态链接。
- ClassLoader.findLibrary 定位library路径
Linking Native Methods
- the native method by concatenating the following components:
- the prefix “Java_”
- an encoded fully qualified class name
- an underscore (“_”) separator
- an encoded method name
- for overloaded native methods, two underscores (“__”) followed by the encoded argument descriptor
- If native functions matching an encoded native method name are present in multiple native libraries, the function in the native library that is loaded first is linked with the native method. 如果存在多个定义那么使用找到的第一个使用。
- If no function matches the native method name, an UnsatisfiedLinkError is thrown. 否则抛出异常。
Passing Data
使用reference的好处可以使得访问数据更加灵活。
Accessing Objects
- Accessing Primitive Arrays
- One solution introduces a notion of “pinning” so that the native method can ask the virtual machine not to move the contents of an array. 对于原始类型数组访问的话可以考虑使用pinning的方式,这种方式直接返回数据内容而不需要copy
- The garbage collector must support pinning. In many implementations, pin-ning is undesirable because it complicates garbage collection algorithms and leads to memory fragmentation. 支持pinning首先需要GC支持,但是这样会复杂GC算法并且造成内存碎片
- The virtual machine must lay out primitive arrays contiguously in memory. Although this is the natural implementation for most primitive arrays, boolean arrays can be implemented as packed or unpacked. 其次需要VM内部实现的时候就是按照原始类型连续存放的
- GetIntArrayRegion/SetIntArrayRegion 操作的是数组的copy版本
- GetIntArrayElements/ReleaseIntArrayElements VM尽量返回pinning版本
- GetPrimitiveArrayCritical/ReleasePrimitiveArrayCritical 和上面非常类似,但是进入的是一个critical region停止GC算法,所以更有可能返回pinning版本。
- Fields and Methods
- A field or method ID remains valid until the virtual machine unloads the class or interface that defines the corresponding field or method. After the class or inter-face is unloaded, the method or field ID becomes invalid. 在class被unload之前field/method ID都是有效的。
1.8 Tool
1.8.1 jvisualvm
- 远程调试需要程序启动的时候加上下面这些选项:
- -Dcom.sun.management.jmxremote.port=1999
- -Dcom.sun.management.jmxremote.ssl=false 不走ssl
- -Dcom.sun.management.jmxremote.authenticate=false 不做验证
- -Dcom.sun.management.jmxremote.port=12345 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
- NOTE(dirlt):我始终没有搞懂profiler和sampler两者的区别 ,不过从官方指南来看 Profiling Applications with VisualVM — Java.net http://visualvm.java.net/profiler.html 应该是使用profiler.
- NOTE(dirlt):可能对于profiler是通过在function前后加上instructment来完成的,而sampler就是纯粹的采样。
插件 Tools->Plugins
- https://visualvm.java.net/pluginscenters.html
- VisualGC 可以用来观察GC执行情况
- VisualVM-MBeans 用来察看mbean对象
1.8.2 hprof
HPROF: A Heap/CPU Profiling Tool
- http://docs.oracle.com/javase/7/docs/technotes/samples/hprof.html
- HPROF is actually a JVM native agent library which is dynamically loaded through a command line option, at JVM startup, and becomes part of the JVM process. TODO(dirlt):什么叫做agent library?.属于JVM进程的一个部分
- The binary format file from HPROF can be used with tools such as HAT to browse the allocated objects in the heap. 二进制输出可以使用HAT这个工具来察看
- HPROF is capable of presenting
- CPU usage,
- heap allocation statistics,
- and monitor contention profiles. TODO(dirlt):什么是monitor?
- complete heap dumps and
- states of all the monitors and threads
使用java -agentlib:hprof=help可以察看hprof的调用方式
HPROF: Heap and CPU Profiling Agent (JVMTI Demonstration Code)
hprof usage: java -agentlib:hprof=[help]|[<option>=<value>, ...]
Option Name and Value Description Default
--------------------- ----------- -------
heap=dump|sites|all heap profiling all
cpu=samples|times|old CPU usage off
monitor=y|n monitor contention n
format=a|b text(txt) or binary output a
file=<file> write data to file java.hprof[{.txt}]
net=<host>:<port> send data over a socket off
depth=<size> stack trace depth 4
interval=<ms> sample interval in ms 10
cutoff=<value> output cutoff point 0.0001
lineno=y|n line number in traces? y
thread=y|n thread in traces? n
doe=y|n dump on exit? y
msa=y|n Solaris micro state accounting n
force=y|n force output to <file> y
verbose=y|n print messages about dumps y
Obsolete Options
----------------
gc_okay=y|n
Examples
--------
- Get sample cpu information every 20 millisec, with a stack depth of 3:
java -agentlib:hprof=cpu=samples,interval=20,depth=3 classname
- Get heap usage information based on the allocation sites:
java -agentlib:hprof=heap=sites classname
Notes
-----
- The option format=b cannot be used with monitor=y.
- The option format=b cannot be used with cpu=old|times.
- Use of the -Xrunhprof interface can still be used, e.g.
java -Xrunhprof:[help]|[<option>=<value>, ...]
will behave exactly the same as:
java -agentlib:hprof=[help]|[<option>=<value>, ...]
Warnings
--------
- This is demonstration code for the JVMTI interface and use of BCI,
it is not an official product or formal part of the JDK.
- The -Xrunhprof interface will be removed in a future release.
- The option format=b is considered experimental, this format may change
in a future release.
- force=y 会删除原来的文件,如果是多个VM来同时使用hprof的话那么需要使用force=n
- heap= sites能够看到所有的分配以及热点,而dump能够看到所有引用的对象,而all则能看到两个 NOTE(dirlt):dump,all能够消耗大量内存,最好别使用,而且没有太大意义
- 如果不希望对heap做分析的话,那么不要指定这个选项。
- cpu=samples采用采样方式来做分析,interval则是设置采样间隔。 NOTE(dirlt):可能比较使用于长期运行的程序profiling
- cpu=times采用代码注入的方式在函数entry和return部分加上代码来做profile.
- thread=y 可以针对将不同线程区分开,每个线程单独进行profile. NOTE(dirlt):似乎没有太大的用途
- depth=n 控制stacktrace的深度,加大深度可以看到更详细的调用栈。
- doe=n 在exit的时候不dump任何数据 TODO(dirlt):?这个有什么用呢
代码处理选项部分还是比较诡异的,可以看看代码是如何处理的 https://cluster.earlham.edu/trac/bccd-ng/browser/branches/skylar-install_jdk/trees/software/bccd/software/jdk1.6.0_14/demo/jvmti/hprof/src/hprof_init.c?rev=1854
How Does HPROF Work?
- a dynamically-linked native library that uses JVM TI and writes out profiling information either to a file descriptor or to a socket in ascii or binary format. (native动态链接库完成的,使用了JVM TI接口,将数据写到socket或者是文件)
- JVM TI Java Virtual Machine Tool Interface
- calls to JVM TI
- event callbacks from JVM TI,
- and through Byte Code Insertion (BCI) NOTE(dirlt):修改bytecode,这个用来修改class文件
- The cpu=samples option doesn't use BCI, HPROF just spawns a separate thread that sleeps for a fixed number of micro seconds, and wakes up and samples all the running thread stacks using JVM TI. 通过另外线程通过JVM TI来监控其他线程栈
- The cpu=times option attempts to track the running stack of all threads, and keep accurate CPU time usage on all methods. This option probably places the greatest strain on the VM, where every method entry and method exit is tracked. Applications that make many method calls will be impacted more than others.
- The heap=sites and heap=dump options are the ones that need to track object allocations. These options can be memory intensive (less so with hprof=sites) and applications that allocate many objects or allocate and free many objects will be impacted more with these options. On each object allocation, the stack must be sampled so we know where the object was allocated, and that stack information must be saved. HPROF has a series of tables allocated in the C or malloc() heap that track all it's information. HPROF currently does not allocate any Java objects.