Linux下电骡aMule Kademlia网络构建分析5 —— 资源的发布
资源发布请求消息的发送
在aMule中,主要用CSharedFileList class来管理共享给其它节点的文件。如我们前面在 Linux下电骡aMule Kademlia网络构建分析3 一文中分析的那样,aMule在启动的时候,会起一些定时器,以便于定期的执行一些任务。CamuleApp::OnCoreTimer()是其中之一,在这个函数中,我们可以看到这样的几行:
// Publish files to server if needed. sharedfiles->Process();
由注释可见,在aMule中,是周期性地执行CSharedFileList::Process(),向网络发布自己的资源。那我们就来看一下这个CSharedFileList::Process()(amule-2.3.1/src/SharedFileList.cpp):
void CSharedFileList::Process()
{
Publish();
if( !m_lastPublishED2KFlag || ( ::GetTickCount() - m_lastPublishED2K < ED2KREPUBLISHTIME ) ) {
return;
}
SendListToServer();
m_lastPublishED2K = ::GetTickCount();
}
在这个函数中,既会向Kademlia网络发布资源,也会向ED2K网络的中心服务器发布资源,这两种发布动作分别由Publish()和SendListToServer()函数完成。这里主要来看向Kademlia网络发布资源的过程,也就是CSharedFileList::Publish():
void CSharedFileList::Publish()
{
// Variables to save cpu.
unsigned int tNow = time(NULL);
bool IsFirewalled = theApp->IsFirewalled();
if( Kademlia::CKademlia::IsConnected() && ( !IsFirewalled || ( IsFirewalled && theApp->clientlist->GetBuddyStatus() == Connected)) && GetCount() && Kademlia::CKademlia::GetPublish()) {
//We are connected to Kad. We are either open or have a buddy. And Kad is ready to start publishing.
if( Kademlia::CKademlia::GetTotalStoreKey() < KADEMLIATOTALSTOREKEY) {
//We are not at the max simultaneous keyword publishes
if (tNow >= m_keywords->GetNextPublishTime()) {
//Enough time has passed since last keyword publish
//Get the next keyword which has to be (re)-published
CPublishKeyword* pPubKw = m_keywords->GetNextKeyword();
if (pPubKw) {
//We have the next keyword to check if it can be published
//Debug check to make sure things are going well.
wxASSERT( pPubKw->GetRefCount() != 0 );
if (tNow >= pPubKw->GetNextPublishTime()) {
//This keyword can be published.
Kademlia::CSearch* pSearch = Kademlia::CSearchManager::PrepareLookup(Kademlia::CSearch::STOREKEYWORD, false, pPubKw->GetKadID());
if (pSearch) {
//pSearch was created. Which means no search was already being done with this HashID.
//This also means that it was checked to see if network load wasn't a factor.
//This sets the filename into the search object so we can show it in the gui.
pSearch->SetFileName(pPubKw->GetKeyword());
//Add all file IDs which relate to the current keyword to be published
const KnownFileArray& aFiles = pPubKw->GetReferences();
uint32 count = 0;
for (unsigned int f = 0; f < aFiles.size(); ++f) {
//Only publish complete files as someone else should have the full file to publish these keywords.
//As a side effect, this may help reduce people finding incomplete files in the network.
if( !aFiles[f]->IsPartFile() ) {
count++;
pSearch->AddFileID(Kademlia::CUInt128(aFiles[f]->GetFileHash().GetHash()));
if( count > 150 ) {
//We only publish up to 150 files per keyword publish then rotate the list.
pPubKw->RotateReferences(f);
break;
}
}
}
if( count ) {
//Start our keyword publish
pPubKw->SetNextPublishTime(tNow+(KADEMLIAREPUBLISHTIMEK));
pPubKw->IncPublishedCount();
Kademlia::CSearchManager::StartSearch(pSearch);
} else {
//There were no valid files to publish with this keyword.
delete pSearch;
}
}
}
}
m_keywords->SetNextPublishTime(KADEMLIAPUBLISHTIME+tNow);
}
}
if( Kademlia::CKademlia::GetTotalStoreSrc() < KADEMLIATOTALSTORESRC) {
if(tNow >= m_lastPublishKadSrc) {
if(m_currFileSrc > GetCount()) {
m_currFileSrc = 0;
}
CKnownFile* pCurKnownFile = const_cast<CKnownFile*>(GetFileByIndex(m_currFileSrc));
if(pCurKnownFile) {
if(pCurKnownFile->PublishSrc()) {
Kademlia::CUInt128 kadFileID;
kadFileID.SetValueBE(pCurKnownFile->GetFileHash().GetHash());
if(Kademlia::CSearchManager::PrepareLookup(Kademlia::CSearch::STOREFILE, true, kadFileID )==NULL) {
pCurKnownFile->SetLastPublishTimeKadSrc(0,0);
}
}
}
m_currFileSrc++;
// even if we did not publish a source, reset the timer so that this list is processed
// only every KADEMLIAPUBLISHTIME seconds.
m_lastPublishKadSrc = KADEMLIAPUBLISHTIME+tNow;
}
}
if( Kademlia::CKademlia::GetTotalStoreNotes() < KADEMLIATOTALSTORENOTES) {
if(tNow >= m_lastPublishKadNotes) {
if(m_currFileNotes > GetCount()) {
m_currFileNotes = 0;
}
CKnownFile* pCurKnownFile = const_cast<CKnownFile*>(GetFileByIndex(m_currFileNotes));
if(pCurKnownFile) {
if(pCurKnownFile->PublishNotes()) {
Kademlia::CUInt128 kadFileID;
kadFileID.SetValueBE(pCurKnownFile->GetFileHash().GetHash());
if(Kademlia::CSearchManager::PrepareLookup(Kademlia::CSearch::STORENOTES, true, kadFileID )==NULL)
pCurKnownFile->SetLastPublishTimeKadNotes(0);
}
}
m_currFileNotes++;
// even if we did not publish a source, reset the timer so that this list is processed
// only every KADEMLIAPUBLISHTIME seconds.
m_lastPublishKadNotes = KADEMLIAPUBLISHTIME+tNow;
}
}
}
}
CSharedFileList::Publish()首先确保(1)、Kademlia正在运行;(2)、本节点不处于防火墙后,或处于防火墙后但BuddyStatus是Connected的;(3)、可供分享的文件数大于0;(4)、同时Kademlia网络的设置允许进行发布。
然后,尝试向Kademlia网络中分别发布3种不同类型的信息,分别为keyword,file,和filenotes。这三种类型发布的实际执行,都要满足一定的约束条件,即正在进行的同种类型发布的个数不能太多,发布的频率不能太高。具体点说,也就是这三种类型的发布,同一时间正在进行的发布个数分别不能多于KADEMLIATOTALSTOREKEY,KADEMLIATOTALSTORESRC和KADEMLIATOTALSTORENOTES个。同时这三种类型的发布有它们自己的周期,也就是KADEMLIAPUBLISHTIME。在amule-2.3.1/src/include/protocol/kad/Constants.h文件中可以看到这几个常量值的定义:
#define KADEMLIAPUBLISHTIME SEC(2) //2 second #define KADEMLIATOTALSTORENOTES 1 //Total hashes to store. #define KADEMLIATOTALSTORESRC 3 //Total hashes to store. #define KADEMLIATOTALSTOREKEY 2 //Total hashes to store. #define KADEMLIAREPUBLISHTIMES HR2S(5) //5 hours #define KADEMLIAREPUBLISHTIMEN HR2S(24) //24 hours #define KADEMLIAREPUBLISHTIMEK HR2S(24) //24 hours
我们具体分析这三种类型发布的执行过程。
1. Keyword的发布。
CSharedFileList用CPublishKeywordList m_keywords管理可供发布的PublishKeyword,用CPublishKeyword来表示一个要发布的keyword。CSharedFileList::Publish()在发布keyword时,会先从m_keywords中取出下一个要发布的CPublishKeyword pPubKw,然后检查这个pPubKw的发布时间是否到了。对于一个具体的PublishKeyword,可以看到,它的发布周期为KADEMLIAREPUBLISHTIMEK,也就是24个小时。
若发布时间到了,则执行Kademlia::CSearchManager::PrepareLookup()为发布创建一个CSearch,设置search的FileName为Keyword,获取与关键字关联的所有的文件。随后逐个地将每个文件的Hash值添加到search。但每个PublishKeyword一次最多只发布150个文件。如果与关键字关联的文件数量超过了150个,则在向search添加了150个文件的hash值之后,还会rotate PublishKeyword的关联文件列表,以便于在下一次执行相同的关键字的发布时,那些没有被发布过的文件能够被优先发布,并跳出添加文件Hash值的循环。
最后更新PublishKeyword的下次发布时间,增加发布的次数值,并通过Kademlia::CSearchManager::StartSearch()来执行发布过程。
我们可以再来看一下与CSearch创建相关的一些函数,CSearchManager::PrepareLookup()如下(amule-2.3.1/src/kademlia/kademlia/SearchManager.cpp):
CSearch* CSearchManager::PrepareLookup(uint32_t type, bool start, const CUInt128& id)
{
// Prepare a kad lookup.
// Make sure this target is not already in progress.
if (AlreadySearchingFor(id)) {
return NULL;
}
// Create a new search.
CSearch *s = new CSearch;
// Set type and target.
s->SetSearchTypes(type);
s->SetTargetID(id);
try {
switch(type) {
case CSearch::STOREKEYWORD:
if (!Kademlia::CKademlia::GetIndexed()->SendStoreRequest(id)) {
delete s;
return NULL;
}
break;
}
s->SetSearchID(++m_nextID);
if (start) {
m_searches[id] = s;
s->Go();
}
} catch (const CEOFException& DEBUG_ONLY(err)) {
delete s;
AddDebugLogLineN(logKadSearch, wxT("CEOFException in CSearchManager::PrepareLookup: ") + err.what());
return NULL;
} catch (...) {
AddDebugLogLineN(logKadSearch, wxT("Exception in CSearchManager::PrepareLookup"));
delete s;
throw;
}
return s;
}
AlreadySearchingFor()的检查还是蛮重要的。这个检查确保,同一时间发送到同一个节点的搜索请求不会超过1个。这样在收到目标节点的响应之后,就可以根据target clientID正确地找到对应的CSearch了。
此函数会new一个CSearch对象,并适当地设置一些值。就关键字发布而言,此时这个search还不会被真正执行。
CSearch::AddFileID()如下(amule-2.3.1/src/kademlia/kademlia/Search.h):
void AddFileID(const CUInt128& id) { m_fileIDs.push_back(id); }
CSharedFileList::Publish()通过Kademlia::CSearchManager::StartSearch()执行发布(搜索):
bool CSearchManager::StartSearch(CSearch* search)
{
// A search object was created, now try to start the search.
if (AlreadySearchingFor(search->GetTarget())) {
// There was already a search in progress with this target.
delete search;
return false;
}
// Add to the search map
m_searches[search->GetTarget()] = search;
// Start the search.
search->Go();
return true;
}
确保没有发向同一个目标节点的多个发布/搜索请求。然后执行search。CSearch::Go()前面我们也多次见到了,此处不再赘述。
2. 文件的发布。
(1)、首先会确保欲发布文件的index m_currFileSrc不会超出可发布文件的范围,若超出则重置为0。
(2)、取出要发布的文件。
const CKnownFile *CSharedFileList::GetFileByIndex(unsigned int index) const
{
wxMutexLocker lock(list_mut);
if ( index >= m_Files_map.size() ) {
return NULL;
}
CKnownFileMap::const_iterator pos = m_Files_map.begin();
std::advance(pos, index);
return pos->second;
}
(3)、执行CSearchManager::PrepareLookup()直接发布文件。
(4)、更新下一次要发布的文件的index m_currFileSrc。
3. FileNotes的发布。
FileNotes的发布与文件的发布的过程非常相似,甚至发送出去的消息的内容都基本一样。只是在此处,通过CKnownFile::PublishNotes()来判断是否要发布一个文件,而文件的发布则通过CKnownFile::PublishSrc()来判断。至于这两种判断的具体差别,这里暂且不做太详细的分析。
资源发布消息的发送过程大体如上所示。
资源发布请求消息的处理
我们了解了资源发布消息的发送,那其它节点在接收到这个消息之后,又会做什么样的处理呢?
资源发布消息与关键字的搜索消息区别不大,主要在RequestContactCount,也就是请求的联系的个数上面。这里可以具体来看一下这个参数在不同情况下的具体值的不同,也就是CSearch::GetRequestContactCount()函数(amule-2.3.1/src/kademlia/kademlia/Search.cpp):
uint8_t CSearch::GetRequestContactCount() const
{
// Returns the amount of contacts we request on routing queries based on the search type
switch (m_type) {
case NODE:
case NODECOMPLETE:
case NODESPECIAL:
case NODEFWCHECKUDP:
return KADEMLIA_FIND_NODE;
case FILE:
case KEYWORD:
case FINDSOURCE:
case NOTES:
return KADEMLIA_FIND_VALUE;
case FINDBUDDY:
case STOREFILE:
case STOREKEYWORD:
case STORENOTES:
return KADEMLIA_STORE;
default:
AddDebugLogLineN(logKadSearch, wxT("Invalid search type. (CSearch::GetRequestContactCount())"));
wxFAIL;
return 0;
}
}
Search可以分为3个大类,12个小类,3个大类分别为节点查找,资源查找和资源发布。每个大类中所有的小类请求的联系人个数都相同。
再来看一下几个常量值的定义(amule-2.3.1/src/include/protocol/kad/Constants.h):
// Kad parameters #define KADEMLIA_FIND_VALUE 0x02 #define KADEMLIA_STORE 0x04 #define KADEMLIA_FIND_NODE 0x0B #define KADEMLIA_FIND_VALUE_MORE KADEMLIA_FIND_NODE
接收端对这个消息的处理与对搜索请求的消息的处理也没有太大的区别,都是查找一些节点信息,包在一个KADEMLIA2_RES消息里,返回给发送端。具体可以参考 Linux下电骡aMule Kademlia网络构建分析2 一文。
KADEMLIA2_RES消息的处理
球又被踢回了消息发送节点,对于资源发布的case而言,也就是资源发布节点。来看KADEMLIA2_RES消息的处理。KADEMLIA2_RES消息最终会被dispatch给CKademliaUDPListener::ProcessPacket(),具体dispatch的过程,与KADEMLIA2_REQ消息的dispatch过程没有区别,具体可参考 Linux下电骡aMule Kademlia网络构建分析2 一文。
这里主要关注CKademliaUDPListener::ProcessPacket()中对于KADEMLIA2_RES消息的处理:
case KADEMLIA2_RES: DebugRecv(Kad2Res, ip, port); ProcessKademlia2Response(packetData, lenPacket, ip, port, senderKey); break;
可以看到消息的处理被委托给了CKademliaUDPListener::ProcessKademlia2Response(),这个函数定义如下:
// KADEMLIA2_RES
// Used in Kad2.0 only
void CKademliaUDPListener::ProcessKademlia2Response(const uint8_t *packetData, uint32_t lenPacket, uint32_t ip, uint16_t port, const CKadUDPKey& WXUNUSED(senderKey))
{
CHECK_TRACKED_PACKET(KADEMLIA2_REQ);
// Used Pointers
CRoutingZone *routingZone = CKademlia::GetRoutingZone();
// What search does this relate to
CMemFile bio(packetData, lenPacket);
CUInt128 target = bio.ReadUInt128();
uint8_t numContacts = bio.ReadUInt8();
// Is this one of our legacy challenge packets?
CUInt128 contactID;
if (IsLegacyChallenge(target, ip, KADEMLIA2_REQ, contactID)) {
// yup it is, set the contact as verified
if (!routingZone->VerifyContact(contactID, ip)) {
AddDebugLogLineN(logKadRouting, wxT("Unable to find valid sender in routing table (sender: ") + KadIPToString(ip) + wxT(")"));
} else {
AddDebugLogLineN(logKadRouting, wxT("Verified contact with legacy challenge (Kad2Req) - ") + KadIPToString(ip));
}
return; // we do not actually care for its other content
}
// Verify packet is expected size
CHECK_PACKET_EXACT_SIZE(16+1 + (16+4+2+2+1)*numContacts);
// is this a search for firewallcheck ips?
bool isFirewallUDPCheckSearch = false;
if (CUDPFirewallTester::IsFWCheckUDPRunning() && CSearchManager::IsFWCheckUDPSearch(target)) {
isFirewallUDPCheckSearch = true;
}
DEBUG_ONLY( uint32_t ignoredCount = 0; )
DEBUG_ONLY( uint32_t kad1Count = 0; )
CScopedPtr<ContactList> results;
for (uint8_t i = 0; i < numContacts; i++) {
CUInt128 id = bio.ReadUInt128();
uint32_t contactIP = bio.ReadUInt32();
uint16_t contactPort = bio.ReadUInt16();
uint16_t tport = bio.ReadUInt16();
uint8_t version = bio.ReadUInt8();
uint32_t hostIP = wxUINT32_SWAP_ALWAYS(contactIP);
if (version > 1) { // Kad1 nodes are no longer accepted and ignored
if (::IsGoodIPPort(hostIP, contactPort)) {
if (!theApp->ipfilter->IsFiltered(hostIP) && !(contactPort == 53 && version <= 5) /*No DNS Port without encryption*/) {
if (isFirewallUDPCheckSearch) {
// UDP FirewallCheck searches are special. The point is we need an IP which we didn't sent a UDP message yet
// (or in the near future), so we do not try to add those contacts to our routingzone and we also don't
// deliver them back to the searchmanager (because he would UDP-ask them for further results), but only report
// them to FirewallChecker - this will of course cripple the search but thats not the point, since we only
// care for IPs and not the random set target
CUDPFirewallTester::AddPossibleTestContact(id, contactIP, contactPort, tport, target, version, 0, false);
} else {
bool verified = false;
bool wasAdded = routingZone->AddUnfiltered(id, contactIP, contactPort, tport, version, 0, verified, false, false);
CContact *temp = new CContact(id, contactIP, contactPort, tport, version, 0, false, target);
if (wasAdded || routingZone->IsAcceptableContact(temp)) {
results->push_back(temp);
} else {
DEBUG_ONLY( ignoredCount++; )
delete temp;
}
}
}
}
} else {
DEBUG_ONLY( kad1Count++; )
}
}
#ifdef __DEBUG__
if (ignoredCount > 0) {
AddDebugLogLineN(logKadRouting, CFormat(wxT("Ignored %u bad %s in routing answer from %s")) % ignoredCount % (ignoredCount > 1 ? wxT("contacts") : wxT("contact")) % KadIPToString(ip));
}
if (kad1Count > 0) {
AddDebugLogLineN(logKadRouting, CFormat(wxT("Ignored %u kad1 %s in routing answer from %s")) % kad1Count % (kad1Count > 1 ? wxT("contacts") : wxT("contact")) % KadIPToString(ip));
}
#endif
CSearchManager::ProcessResponse(target, ip, port, results.release());
}
这个地方主要做了两件事情,
1. 是从消息中解出联系人的信息,并保存至RoutingZone中。
2. 是调用CSearchManager::ProcessResponse(target, ip, port, results.release()),执行一些与所发起的搜索/资源发布等本身有关的动作。具体CSearchManager会如何处理,则需要来看CSearchManager::ProcessResponse()的定义了,代码如下(amule-2.3.1/src/kademlia/kademlia/SearchManager.cpp):
void CSearchManager::ProcessResponse(const CUInt128& target, uint32_t fromIP, uint16_t fromPort, ContactList *results)
{
// We got a response to a kad lookup.
CSearch *s = NULL;
SearchMap::const_iterator it = m_searches.find(target);
if (it != m_searches.end()) {
s = it->second;
}
// If this search was deleted before this response, delete contacts and abort, otherwise process them.
if (s == NULL) {
AddDebugLogLineN(logKadSearch,
wxT("Search either never existed or receiving late results (CSearchManager::ProcessResponse)"));
DeleteContents(*results);
} else {
s->ProcessResponse(fromIP, fromPort, results);
}
delete results;
}
这个函数中,所做的事情主要是找到相对应的CSearch对象(AlreadySearchingFor()的检查的成果在这里派上用场),然后执行它的ProcessResponse()函数。来看CSearch::ProcessResponse()(amule-2.3.1/src/kademlia/kademlia/Search.cpp):
void CSearch::ProcessResponse(uint32_t fromIP, uint16_t fromPort, ContactList *results)
{
AddDebugLogLineN(logKadSearch, wxT("Processing search response from ") + KadIPPortToString(fromIP, fromPort));
ContactList::iterator response;
// Remember the contacts to be deleted when finished
for (response = results->begin(); response != results->end(); ++response) {
m_delete.push_back(*response);
}
m_lastResponse = time(NULL);
// Find contact that is responding.
CUInt128 fromDistance(0u);
CContact *fromContact = NULL;
for (ContactMap::const_iterator it = m_tried.begin(); it != m_tried.end(); ++it) {
CContact *tmpContact = it->second;
if ((tmpContact->GetIPAddress() == fromIP) && (tmpContact->GetUDPPort() == fromPort)) {
fromDistance = it->first;
fromContact = tmpContact;
break;
}
}
// Make sure the node is not sending more results than we requested, which is not only a protocol violation
// but most likely a malicious answer
if (results->size() > GetRequestContactCount() && !(m_requestedMoreNodesContact == fromContact && results->size() <= KADEMLIA_FIND_VALUE_MORE)) {
AddDebugLogLineN(logKadSearch, wxT("Node ") + KadIPToString(fromIP) + wxT(" sent more contacts than requested on a routing query, ignoring response"));
return;
}
if (m_type == NODEFWCHECKUDP) {
m_answers++;
return;
}
// Not interested in responses for FIND_NODE, will be added to contacts by udp listener
if (m_type == NODE) {
AddDebugLogLineN(logKadSearch, wxT("Node type search result, discarding."));
// Note that we got an answer.
m_answers++;
// We clear the possible list to force the search to stop.
m_possible.clear();
return;
}
if (fromContact != NULL) {
bool providedCloserContacts = false;
std::map<uint32_t, unsigned> receivedIPs;
std::map<uint32_t, unsigned> receivedSubnets;
// A node is not allowed to answer with contacts to itself
receivedIPs[fromIP] = 1;
receivedSubnets[fromIP & 0xFFFFFF00] = 1;
// Loop through their responses
for (ContactList::iterator it = results->begin(); it != results->end(); ++it) {
// Get next result
CContact *c = *it;
// calc distance this result is to the target
CUInt128 distance(c->GetClientID() ^ m_target);
if (distance < fromDistance) {
providedCloserContacts = true;
}
// Ignore this contact if already known or tried it.
if (m_possible.count(distance) > 0) {
AddDebugLogLineN(logKadSearch, wxT("Search result from already known client: ignore"));
continue;
}
if (m_tried.count(distance) > 0) {
AddDebugLogLineN(logKadSearch, wxT("Search result from already tried client: ignore"));
continue;
}
// We only accept unique IPs in the answer, having multiple IDs pointing to one IP in the routing tables
// is no longer allowed since eMule0.49a, aMule-2.2.1 anyway
if (receivedIPs.count(c->GetIPAddress()) > 0) {
AddDebugLogLineN(logKadSearch, wxT("Multiple KadIDs pointing to same IP (") + KadIPToString(c->GetIPAddress()) + wxT(") in Kad2Res answer - ignored, sent by ") + KadIPToString(fromContact->GetIPAddress()));
continue;
} else {
receivedIPs[c->GetIPAddress()] = 1;
}
// and no more than 2 IPs from the same /24 subnet
if (receivedSubnets.count(c->GetIPAddress() & 0xFFFFFF00) > 0 && !::IsLanIP(wxUINT32_SWAP_ALWAYS(c->GetIPAddress()))) {
wxASSERT(receivedSubnets.find(c->GetIPAddress() & 0xFFFFFF00) != receivedSubnets.end());
int subnetCount = receivedSubnets.find(c->GetIPAddress() & 0xFFFFFF00)->second;
if (subnetCount >= 2) {
AddDebugLogLineN(logKadSearch, wxT("More than 2 KadIDs pointing to same subnet (") + KadIPToString(c->GetIPAddress() & 0xFFFFFF00) + wxT("/24) in Kad2Res answer - ignored, sent by ") + KadIPToString(fromContact->GetIPAddress()));
continue;
} else {
receivedSubnets[c->GetIPAddress() & 0xFFFFFF00] = subnetCount + 1;
}
} else {
receivedSubnets[c->GetIPAddress() & 0xFFFFFF00] = 1;
}
// Add to possible
m_possible[distance] = c;
// Verify if the result is closer to the target than the one we just checked.
if (distance < fromDistance) {
// The top ALPHA_QUERY of results are used to determine if we send a request.
bool top = false;
if (m_best.size() < ALPHA_QUERY) {
top = true;
m_best[distance] = c;
} else {
ContactMap::iterator worst = m_best.end();
--worst;
if (distance < worst->first) {
// Prevent having more than ALPHA_QUERY within the Best list.
m_best.erase(worst);
m_best[distance] = c;
top = true;
}
}
if (top) {
// We determined this contact is a candidate for a request.
// Add to tried
m_tried[distance] = c;
// Send the KadID so other side can check if I think it has the right KadID.
// Send request
SendFindValue(c);
}
}
}
// Add to list of people who responded.
m_responded[fromDistance] = providedCloserContacts;
// Complete node search, just increment the counter.
if (m_type == NODECOMPLETE || m_type == NODESPECIAL) {
AddDebugLogLineN(logKadSearch, wxString(wxT("Search result type: Node")) + (m_type == NODECOMPLETE ? wxT("Complete") : wxT("Special")));
m_answers++;
}
}
}
这个函数,
(1)、首先会在m_delet中记录下结果里面所有的联系人信息,以便在结束之后可以将它们都移除掉。
(2)、然后更新m_lastResponse为当前时间。
(3)、在发送消息的时候,会在m_tried中记录都向那些联系人发送了消息。这里则将在m_tried中查找这个响应具体是哪个目标联系人发送回来的,也就是fromContact。
(4)、基于安全考虑,确保响应中的联系人不会过多。返回的联系人个数超出预期的话,可能说明,这是一个恶意的响应。
(5)、遍历返回回来的所有联系人,找到distance与target clientID更近的联系人,向其发送相同的搜索/发布资源的消息。
总结一下KADEMLIA2_RES消息的处理过程,主要是解析消息中发回来的节点信息,并向那些与target clientID 距离更近的节点重复发送相同的搜索/发布资源的消息,持续地进行这样的节点查找的过程。
发送资源信息至其他节点
如我们前面看到的,Kademlia网络中,不管是搜索关键字的过程,还是发布资源的过程,最先要做的事情都是先发送KADEMLIA2_REQ消息,找到一些合适的节点回来。但是搜索到的这么多节点,又会如何被使用呢?
如我们前面在 Linux下电骡aMule Kademlia网络构建分析3 一文中所看到的。Kademlia::CKademlia::Process()会通过一个定时器周期性地被执行,在这个函数中,我们可以看到这样几行:
// This is a convenient place to add this, although not related to routing
if (m_nextSearchJumpStart <= now) {
CSearchManager::JumpStart();
m_nextSearchJumpStart = SEARCH_JUMPSTART + now;
}
所以,CSearchManager::JumpStart()也会被周期性地执行。在这个函数中,CSearchManager会遍历所有的CSearch,找到所有那些需要做进一步动作的searches,并jumpstart它们,即推动search的进一步执行。来看一下这个函数的定义:
void CSearchManager::JumpStart()
{
// Find any searches that has stalled and jumpstart them.
// This will also prune all searches.
time_t now = time(NULL);
SearchMap::iterator next_it = m_searches.begin();
while (next_it != m_searches.end()) {
SearchMap::iterator current_it = next_it++; /* don't change this to a ++next_it! */
switch(current_it->second->GetSearchTypes()){
case CSearch::FILE: {
if (current_it->second->m_created + SEARCHFILE_LIFETIME < now) {
delete current_it->second;
m_searches.erase(current_it);
} else if (current_it->second->GetAnswers() > SEARCHFILE_TOTAL ||
current_it->second->m_created + SEARCHFILE_LIFETIME - SEC(20) < now) {
current_it->second->PrepareToStop();
} else {
current_it->second->JumpStart();
}
break;
}
case CSearch::KEYWORD: {
。。。。。。
case CSearch::STOREFILE: {
if (current_it->second->m_created + SEARCHSTOREFILE_LIFETIME < now) {
delete current_it->second;
m_searches.erase(current_it);
} else if (current_it->second->GetAnswers() > SEARCHSTOREFILE_TOTAL ||
current_it->second->m_created + SEARCHSTOREFILE_LIFETIME - SEC(20) < now) {
current_it->second->PrepareToStop();
} else {
current_it->second->JumpStart();
}
break;
}
case CSearch::STOREKEYWORD: {
if (current_it->second->m_created + SEARCHSTOREKEYWORD_LIFETIME < now) {
delete current_it->second;
m_searches.erase(current_it);
} else if (current_it->second->GetAnswers() > SEARCHSTOREKEYWORD_TOTAL ||
current_it->second->m_created + SEARCHSTOREKEYWORD_LIFETIME - SEC(20)< now) {
current_it->second->PrepareToStop();
} else {
current_it->second->JumpStart();
}
break;
}
case CSearch::STORENOTES: {
if (current_it->second->m_created + SEARCHSTORENOTES_LIFETIME < now) {
delete current_it->second;
m_searches.erase(current_it);
} else if (current_it->second->GetAnswers() > SEARCHSTORENOTES_TOTAL ||
current_it->second->m_created + SEARCHSTORENOTES_LIFETIME - SEC(20)< now) {
current_it->second->PrepareToStop();
} else {
current_it->second->JumpStart();
}
break;
}
default: {
if (current_it->second->m_created + SEARCH_LIFETIME < now) {
delete current_it->second;
m_searches.erase(current_it);
} else {
current_it->second->JumpStart();
}
break;
}
在这里我们主要关注与资源发布相关的几个case,STOREFILE,STOREKEYWORD,和STORENOTES。这几个case内的人处理也比较相似,都是根据search的不同状态来执行不同的动作:
1. Search创建的时间已经很长了,具体点说,即是创建的时间已经超出了其生命周期SEARCHSTOREFILE_LIFETIME,SEARCHSTOREKEYWORD_LIFETIME或SEARCHSTORENOTES_LIFETIME了。直接删除search。
2. Search创建的时间已经比较长了,具体点说,即是创建的时间已经超出了各自生命周期减去20S了;或者已经得到的足够多的响应了,由CSearch::GetAnswers()的定义,可知足够多的含义是指平均每50个要发布的文件,得到了超过SEARCHSTOREFILE_TOTAL,SEARCHSTOREKEYWORD_TOTAL,或SEARCHSTORENOTES_TOTAL个相应了。停掉搜索过程。
3. 其它情况。执行search的JumpStart()推动search的进一步执行。
这里主要来看CSearch::JumpStart()的执行过程:
void CSearch::JumpStart()
{
AddLogLineNS(CFormat(_("CSearch::JumpStart, search type is %s, search id is %u, answers is %u, fileID size is %d"))
% SearchTypeToString() % m_searchID % m_answers % m_fileIDs.size());
// If we had a response within the last 3 seconds, no need to jumpstart the search.
if ((time_t)(m_lastResponse + SEC(3)) > time(NULL)) {
return;
}
// If we ran out of contacts, stop search.
if (m_possible.empty()) {
PrepareToStop();
return;
}
// Is this a find lookup and are the best two (=KADEMLIA_FIND_VALUE) nodes dead/unreachable?
// In this case try to discover more close nodes before using our other results
// The reason for this is that we may not have found the closest node alive due to results being limited to 2 contacts,
// which could very well have been the duplicates of our dead closest nodes
bool lookupCloserNodes = false;
if (m_requestedMoreNodesContact == NULL && GetRequestContactCount() == KADEMLIA_FIND_VALUE && m_tried.size() >= 3 * KADEMLIA_FIND_VALUE) {
ContactMap::const_iterator it = m_tried.begin();
lookupCloserNodes = true;
for (unsigned i = 0; i < KADEMLIA_FIND_VALUE; i++) {
if (m_responded.count(it->first) > 0) {
lookupCloserNodes = false;
break;
}
++it;
}
if (lookupCloserNodes) {
while (it != m_tried.end()) {
if (m_responded.count(it->first) > 0) {
AddDebugLogLineN(logKadSearch, CFormat(wxT("Best %d nodes for lookup (id=%x) were unreachable or dead, reasking closest for more")) % KADEMLIA_FIND_VALUE % GetSearchID());
SendFindValue(it->second, true);
return;
}
++it;
}
}
}
// Search for contacts that can be used to jumpstart a stalled search.
while (!m_possible.empty()) {
// Get a contact closest to our target.
CContact *c = m_possible.begin()->second;
// Have we already tried to contact this node.
if (m_tried.count(m_possible.begin()->first) > 0) {
// Did we get a response from this node, if so, try to store or get info.
if (m_responded.count(m_possible.begin()->first) > 0) {
StorePacket();
}
// Remove from possible list.
m_possible.erase(m_possible.begin());
} else {
// Add to tried list.
m_tried[m_possible.begin()->first] = c;
// Send the KadID so other side can check if I think it has the right KadID.
// Send request
SendFindValue(c);
break;
}
}
}
这个函数主要做2件事情,
1是,在需要的时候,继续发送相同的发布资源/搜索请求出去,以便于能找到更多的节点。
2是,执行CSearch::StorePacket()来推动资源发布/搜索的更进一步执行。
至于这两件是的具体执行条件,如上面代码所示,此处不再赘述。这里主要来看一下CSearch::StorePacket()的执行:
void CSearch::StorePacket()
{
wxASSERT(!m_possible.empty());
// This method is currently only called by jumpstart so only use best possible.
ContactMap::const_iterator possible = m_possible.begin();
CUInt128 fromDistance(possible->first);
CContact *from = possible->second;
if (fromDistance < m_closestDistantFound || m_closestDistantFound == 0) {
m_closestDistantFound = fromDistance;
}
// Make sure this is a valid node to store.
if (fromDistance.Get32BitChunk(0) > SEARCHTOLERANCE && !::IsLanIP(wxUINT32_SWAP_ALWAYS(from->GetIPAddress()))) {
return;
}
// What kind of search are we doing?
switch (m_type) {
case FILE: {
。。。。。。
case STOREFILE: {
AddDebugLogLineN(logKadSearch, wxT("Search request type: StoreFile"));
// Try to store ourselves as a source to a Node.
// As a safeguard, check to see if we already stored to the max nodes.
if (m_answers > SEARCHSTOREFILE_TOTAL) {
PrepareToStop();
break;
}
// Find the file we are trying to store as a source to.
uint8_t fileid[16];
m_target.ToByteArray(fileid);
CKnownFile* file = theApp->sharedfiles->GetFileByID(CMD4Hash(fileid));
if (file) {
// We store this mostly for GUI reasons.
m_fileName = file->GetFileName().GetPrintable();
// Get our clientID for the packet.
CUInt128 id(CKademlia::GetPrefs()->GetClientHash());
TagPtrList taglist;
//We can use type for different types of sources.
//1 HighID sources..
//2 cannot be used as older clients will not work.
//3 Firewalled Kad Source.
//4 >4GB file HighID Source.
//5 >4GB file Firewalled Kad source.
//6 Firewalled source with Direct Callback (supports >4GB)
bool directCallback = false;
if (theApp->IsFirewalled()) {
directCallback = (Kademlia::CKademlia::IsRunning() && !Kademlia::CUDPFirewallTester::IsFirewalledUDP(true) && Kademlia::CUDPFirewallTester::IsVerified());
if (directCallback) {
// firewalled, but direct udp callback is possible so no need for buddies
// We are not firewalled..
taglist.push_back(new CTagVarInt(TAG_SOURCETYPE, 6));
taglist.push_back(new CTagVarInt(TAG_SOURCEPORT, thePrefs::GetPort()));
if (!CKademlia::GetPrefs()->GetUseExternKadPort()) {
taglist.push_back(new CTagInt16(TAG_SOURCEUPORT, CKademlia::GetPrefs()->GetInternKadPort()));
}
if (from->GetVersion() >= 2) {
taglist.push_back(new CTagVarInt(TAG_FILESIZE, file->GetFileSize()));
}
} else if (theApp->clientlist->GetBuddy()) { // We are firewalled, make sure we have a buddy.
// We send the ID to our buddy so they can do a callback.
CUInt128 buddyID(true);
buddyID ^= CKademlia::GetPrefs()->GetKadID();
taglist.push_back(new CTagInt8(TAG_SOURCETYPE, file->IsLargeFile() ? 5 : 3));
taglist.push_back(new CTagVarInt(TAG_SERVERIP, theApp->clientlist->GetBuddy()->GetIP()));
taglist.push_back(new CTagVarInt(TAG_SERVERPORT, theApp->clientlist->GetBuddy()->GetUDPPort()));
uint8_t hashBytes[16];
buddyID.ToByteArray(hashBytes);
taglist.push_back(new CTagString(TAG_BUDDYHASH, CMD4Hash(hashBytes).Encode()));
taglist.push_back(new CTagVarInt(TAG_SOURCEPORT, thePrefs::GetPort()));
if (!CKademlia::GetPrefs()->GetUseExternKadPort()) {
taglist.push_back(new CTagInt16(TAG_SOURCEUPORT, CKademlia::GetPrefs()->GetInternKadPort()));
}
if (from->GetVersion() >= 2) {
taglist.push_back(new CTagVarInt(TAG_FILESIZE, file->GetFileSize()));
}
} else {
// We are firewalled, but lost our buddy.. Stop everything.
PrepareToStop();
break;
}
} else {
// We're not firewalled..
taglist.push_back(new CTagInt8(TAG_SOURCETYPE, file->IsLargeFile() ? 4 : 1));
taglist.push_back(new CTagVarInt(TAG_SOURCEPORT, thePrefs::GetPort()));
if (!CKademlia::GetPrefs()->GetUseExternKadPort()) {
taglist.push_back(new CTagInt16(TAG_SOURCEUPORT, CKademlia::GetPrefs()->GetInternKadPort()));
}
if (from->GetVersion() >= 2) {
taglist.push_back(new CTagVarInt(TAG_FILESIZE, file->GetFileSize()));
}
}
taglist.push_back(new CTagInt8(TAG_ENCRYPTION, CPrefs::GetMyConnectOptions(true, true)));
// Send packet
CKademlia::GetUDPListener()->SendPublishSourcePacket(*from, m_target, id, taglist);
m_totalRequestAnswers++;
// Delete all tags.
deleteTagPtrListEntries(&taglist);
} else {
PrepareToStop();
}
break;
}
case STOREKEYWORD: {
AddDebugLogLineN(logKadSearch, wxT("Search request type: StoreKeyword"));
// Try to store keywords to a Node.
// As a safeguard, check to see if we already stored to the max nodes.
if (m_answers > SEARCHSTOREKEYWORD_TOTAL) {
PrepareToStop();
break;
}
uint16_t count = m_fileIDs.size();
if (count == 0) {
PrepareToStop();
break;
} else if (count > 150) {
count = 150;
}
UIntList::const_iterator itListFileID = m_fileIDs.begin();
uint8_t fileid[16];
while (count && (itListFileID != m_fileIDs.end())) {
uint16_t packetCount = 0;
CMemFile packetdata(1024*50); // Allocate a good amount of space.
packetdata.WriteUInt128(m_target);
packetdata.WriteUInt16(0); // Will be updated before sending.
while ((packetCount < 50) && (itListFileID != m_fileIDs.end())) {
CUInt128 id(*itListFileID);
id.ToByteArray(fileid);
CKnownFile *pFile = theApp->sharedfiles->GetFileByID(CMD4Hash(fileid));
if (pFile) {
count--;
packetCount++;
packetdata.WriteUInt128(id);
PreparePacketForTags(&packetdata, pFile);
}
++itListFileID;
}
// Correct file count.
uint64_t current_pos = packetdata.GetPosition();
packetdata.Seek(16);
packetdata.WriteUInt16(packetCount);
packetdata.Seek(current_pos);
// Send packet
if (from->GetVersion() >= 6) {
DebugSend(Kad2PublishKeyReq, from->GetIPAddress(), from->GetUDPPort());
CUInt128 clientID = from->GetClientID();
CKademlia::GetUDPListener()->SendPacket(packetdata, KADEMLIA2_PUBLISH_KEY_REQ, from->GetIPAddress(), from->GetUDPPort(), from->GetUDPKey(), &clientID);
} else if (from->GetVersion() >= 2) {
DebugSend(Kad2PublishKeyReq, from->GetIPAddress(), from->GetUDPPort());
CKademlia::GetUDPListener()->SendPacket(packetdata, KADEMLIA2_PUBLISH_KEY_REQ, from->GetIPAddress(), from->GetUDPPort(), 0, NULL);
wxASSERT(from->GetUDPKey() == CKadUDPKey(0));
} else {
wxFAIL;
}
}
m_totalRequestAnswers++;
break;
}
case STORENOTES: {
AddDebugLogLineN(logKadSearch, wxT("Search request type: StoreNotes"));
// Find file we are storing info about.
uint8_t fileid[16];
m_target.ToByteArray(fileid);
CKnownFile* file = theApp->sharedfiles->GetFileByID(CMD4Hash(fileid));
if (file) {
CMemFile packetdata(1024*2);
// Send the hash of the file we're storing info about.
packetdata.WriteUInt128(m_target);
// Send our ID with the info.
packetdata.WriteUInt128(CKademlia::GetPrefs()->GetKadID());
// Create our taglist.
TagPtrList taglist;
taglist.push_back(new CTagString(TAG_FILENAME, file->GetFileName().GetPrintable()));
if (file->GetFileRating() != 0) {
taglist.push_back(new CTagVarInt(TAG_FILERATING, file->GetFileRating()));
}
if (!file->GetFileComment().IsEmpty()) {
taglist.push_back(new CTagString(TAG_DESCRIPTION, file->GetFileComment()));
}
if (from->GetVersion() >= 2) {
taglist.push_back(new CTagVarInt(TAG_FILESIZE, file->GetFileSize()));
}
packetdata.WriteTagPtrList(taglist);
// Send packet
if (from->GetVersion() >= 6) {
DebugSend(Kad2PublishNotesReq, from->GetIPAddress(), from->GetUDPPort());
CUInt128 clientID = from->GetClientID();
CKademlia::GetUDPListener()->SendPacket(packetdata, KADEMLIA2_PUBLISH_NOTES_REQ, from->GetIPAddress(), from->GetUDPPort(), from->GetUDPKey(), &clientID);
} else if (from->GetVersion() >= 2) {
DebugSend(Kad2PublishNotesReq, from->GetIPAddress(), from->GetUDPPort());
CKademlia::GetUDPListener()->SendPacket(packetdata, KADEMLIA2_PUBLISH_NOTES_REQ, from->GetIPAddress(), from->GetUDPPort(), 0, NULL);
wxASSERT(from->GetUDPKey() == CKadUDPKey(0));
} else {
wxFAIL;
}
m_totalRequestAnswers++;
// Delete all tags.
deleteTagPtrListEntries(&taglist);
} else {
PrepareToStop();
}
break;
}
这个函数有点长,但结构不复杂。先是取出m_possible中的首个contact from,做一些检查。然后就根据具体的search type,执行一些操作。对于我们的发布资源而言,主要关注STOREFILE,STOREKEYWORD和STORENOTES三个case。我们来分别分析三种不同类型的发布具体的执行过程。
1. 文件的发布,也就是case STOREFILE。
(1)、根据fileid找到相应的文件的表示file CKnownFile。fileid也是搜索的target,同时fileid经过MD4Hash之后也是CSharedFileList在管理文件时的index。
(2)、从文件中读出信息,包装成一个个的CTag,并放在一起构造一个TagPtrList。
(3)、通过CKademliaUDPListener::SendPublishSourcePacket()函数将TagPtrList发送给from contact。
(4)、删除TagPtrList的内容。
这里可以再来看一下CKademliaUDPListener的SendPublishSourcePacket()函数:
void CKademliaUDPListener::SendPublishSourcePacket(const CContact& contact, const CUInt128 &targetID, const CUInt128 &contactID, const TagPtrList& tags)
{
uint8_t opcode;
CMemFile packetdata;
packetdata.WriteUInt128(targetID);
if (contact.GetVersion() >= 4/*47c*/) {
opcode = KADEMLIA2_PUBLISH_SOURCE_REQ;
packetdata.WriteUInt128(contactID);
packetdata.WriteTagPtrList(tags);
DebugSend(Kad2PublishSrcReq, contact.GetIPAddress(), contact.GetUDPPort());
} else {
opcode = KADEMLIA_PUBLISH_REQ;
//We only use this for publishing sources now.. So we always send one here..
packetdata.WriteUInt16(1);
packetdata.WriteUInt128(contactID);
packetdata.WriteTagPtrList(tags);
DebugSend(KadPublishReq, contact.GetIPAddress(), contact.GetUDPPort());
}
if (contact.GetVersion() >= 6) { // obfuscated ?
CUInt128 clientID = contact.GetClientID();
SendPacket(packetdata, opcode, contact.GetIPAddress(), contact.GetUDPPort(), contact.GetUDPKey(), &clientID);
} else {
SendPacket(packetdata, opcode, contact.GetIPAddress(), contact.GetUDPPort(), 0, NULL);
}
}
这个函数主要是将所有的数据写入一个CMemFile packetdata中,根据contact版本的不同,将packetdata包装为一个KADEMLIA2_PUBLISH_SOURCE_REQ或KADEMLIA_PUBLISH_REQ消息,通过CKademliaUDPListener::SendPacket()函数发送出去。
packetdata的格式也会根据contact的版本不同而略有差异。
CKademliaUDPListener::SendPacket()函数的具体执行过程可以参考 Linux下电骡aMule Kademlia网络构建分析2 一文。
2. 关键字Keyword的发布,case STOREKEYWORD。
关键字Keyword发布的search在创建时,会将与关键字Keyword相关的所有文件的fileID都添加进m_fileIDs。在这里则是将所有的文件信息打包进CMemFile packetdata,并将packetdata包装为KADEMLIA2_PUBLISH_KEY_REQ消息,然后通过CKademliaUDPListener::SendPacket()函数发送出去。
可以看到,每个packetdata最多包50个文件的信息,如果文件过多,则通过多个packetdata发送出去。
这里会使用CSearch::PreparePacketForTags()将一个文件的信息组装为一个TagPtrList,然后将TagPtrList写入packetdata。
CKademliaUDPListener::SendPacket()函数的具体执行过程可以参考 Linux下电骡aMule Kademlia网络构建分析2 一文。
3. FileNotes的发布,case STORENOTES
将文件的信息包装为一个个的CTag,并放在一起构造一个TagPtrList。
将TagPtrList包装为一个CMemFile packetdata。
将packetdata包装为一个KADEMLIA2_PUBLISH_NOTES_REQ通过CKademliaUDPListener::SendPacket()函数发送出去。
目标节点对所发布资源的相关信息的保存
一个节点可以向Kademlia网络发布三种不同类型的资源信息,File,Keyword,和FileNotes,具体的信息则会通过KADEMLIA2_PUBLISH_SOURCE_REQ、KADEMLIA2_PUBLISH_KEY_REQ或KADEMLIA2_PUBLISH_NOTES_REQ发送出去。
Kademlia网络中的目标节点在接收到这些消息之后,又是如何处理的呢?CKademliaUDPListener::ProcessPacket()可以看到这样的几个case:
case KADEMLIA2_PUBLISH_NOTES_REQ: DebugRecv(Kad2PublishNotesReq, ip, port); Process2PublishNotesRequest(packetData, lenPacket, ip, port, senderKey); break; case KADEMLIA2_PUBLISH_KEY_REQ: DebugRecv(Kad2PublishKeyReq, ip, port); Process2PublishKeyRequest(packetData, lenPacket, ip, port, senderKey); break; case KADEMLIA2_PUBLISH_SOURCE_REQ: DebugRecv(Kad2PublishSourceReq, ip, port); Process2PublishSourceRequest(packetData, lenPacket, ip, port, senderKey); break;
这些消息又会被委托给CKademliaUDPListener的Process2PublishNotesRequest(),Process2PublishKeyRequest()和Process2PublishSourceRequest()处理,来看这几个函数的定义,首先是Process2PublishNotesRequest():
// KADEMLIA2_PUBLISH_NOTES_REQ
// Used only by Kad2.0
void CKademliaUDPListener::Process2PublishNotesRequest(const uint8_t *packetData, uint32_t lenPacket, uint32_t ip, uint16_t port, const CKadUDPKey& senderKey)
{
// check if we are UDP firewalled
if (CUDPFirewallTester::IsFirewalledUDP(true)) {
//We are firewalled. We should not index this entry and give publisher a false report.
return;
}
CMemFile bio(packetData, lenPacket);
CUInt128 target = bio.ReadUInt128();
CUInt128 distance(CKademlia::GetPrefs()->GetKadID());
distance.XOR(target);
if (distance.Get32BitChunk(0) > SEARCHTOLERANCE && !::IsLanIP(wxUINT32_SWAP_ALWAYS(ip))) {
return;
}
CUInt128 source = bio.ReadUInt128();
Kademlia::CEntry* entry = new Kademlia::CEntry();
try {
entry->m_uIP = ip;
entry->m_uUDPport = port;
entry->m_uKeyID.SetValue(target);
entry->m_uSourceID.SetValue(source);
entry->m_bSource = false;
uint32_t tags = bio.ReadUInt8();
while (tags > 0) {
CTag* tag = bio.ReadTag();
if(tag) {
if (!tag->GetName().Cmp(TAG_FILENAME)) {
if (entry->GetCommonFileName().IsEmpty()) {
entry->SetFileName(tag->GetStr());
}
delete tag;
} else if (!tag->GetName().Cmp(TAG_FILESIZE)) {
if (entry->m_uSize == 0) {
entry->m_uSize = tag->GetInt();
}
delete tag;
} else {
//TODO: Filter tags
entry->AddTag(tag);
}
}
tags--;
}
} catch(...) {
//DebugClientOutput(wxT("CKademliaUDPListener::Process2PublishNotesRequest"),ip,port,packetData,lenPacket);
delete entry;
entry = NULL;
throw;
}
uint8_t load = 0;
if (CKademlia::GetIndexed()->AddNotes(target, source, entry, load)) {
CMemFile packetdata(17);
packetdata.WriteUInt128(target);
packetdata.WriteUInt8(load);
DebugSend(Kad2PublishRes, ip, port);
SendPacket(packetdata, KADEMLIA2_PUBLISH_RES, ip, port, senderKey, NULL);
} else {
delete entry;
}
}
从消息里面解出FileNotes信息,然后调用CIndexed::AddNotes()将相关信息保存起来,最后发回一个KADEMLIA2_PUBLISH_RES消息。
然后是Process2PublishKeyRequest():
// KADEMLIA2_PUBLISH_KEY_REQ
// Used in Kad2.0 only
void CKademliaUDPListener::Process2PublishKeyRequest(const uint8_t *packetData, uint32_t lenPacket, uint32_t ip, uint16_t port, const CKadUDPKey& senderKey)
{
//Used Pointers
CIndexed *indexed = CKademlia::GetIndexed();
// check if we are UDP firewalled
if (CUDPFirewallTester::IsFirewalledUDP(true)) {
//We are firewalled. We should not index this entry and give publisher a false report.
return;
}
CMemFile bio(packetData, lenPacket);
CUInt128 file = bio.ReadUInt128();
CUInt128 distance(CKademlia::GetPrefs()->GetKadID());
distance.XOR(file);
if (distance.Get32BitChunk(0) > SEARCHTOLERANCE && !::IsLanIP(wxUINT32_SWAP_ALWAYS(ip))) {
return;
}
DEBUG_ONLY( wxString strInfo; )
uint16_t count = bio.ReadUInt16();
uint8_t load = 0;
while (count > 0) {
DEBUG_ONLY( strInfo.Clear(); )
CUInt128 target = bio.ReadUInt128();
Kademlia::CKeyEntry* entry = new Kademlia::CKeyEntry();
try
{
entry->m_uIP = ip;
entry->m_uUDPport = port;
entry->m_uKeyID.SetValue(file);
entry->m_uSourceID.SetValue(target);
entry->m_tLifeTime = (uint32_t)time(NULL) + KADEMLIAREPUBLISHTIMEK;
entry->m_bSource = false;
uint32_t tags = bio.ReadUInt8();
while (tags > 0) {
CTag* tag = bio.ReadTag();
if (tag) {
if (!tag->GetName().Cmp(TAG_FILENAME)) {
if (entry->GetCommonFileName().IsEmpty()) {
entry->SetFileName(tag->GetStr());
DEBUG_ONLY( strInfo += CFormat(wxT(" Name=\"%s\"")) % entry->GetCommonFileName(); )
}
delete tag; // tag is no longer stored, but membervar is used
} else if (!tag->GetName().Cmp(TAG_FILESIZE)) {
if (entry->m_uSize == 0) {
if (tag->IsBsob() && tag->GetBsobSize() == 8) {
entry->m_uSize = PeekUInt64(tag->GetBsob());
} else {
entry->m_uSize = tag->GetInt();
}
DEBUG_ONLY( strInfo += CFormat(wxT(" Size=%u")) % entry->m_uSize; )
}
delete tag; // tag is no longer stored, but membervar is used
} else {
//TODO: Filter tags
entry->AddTag(tag);
}
}
tags--;
}
#ifdef __DEBUG__
if (!strInfo.IsEmpty()) {
AddDebugLogLineN(logClientKadUDP, strInfo);
}
#endif
} catch(...) {
//DebugClientOutput(wxT("CKademliaUDPListener::Process2PublishKeyRequest"),ip,port,packetData,lenPacket);
delete entry;
throw;
}
if (!indexed->AddKeyword(file, target, entry, load)) {
//We already indexed the maximum number of keywords.
//We do not index anymore but we still send a success..
//Reason: Because if a VERY busy node tells the publisher it failed,
//this busy node will spread to all the surrounding nodes causing popular
//keywords to be stored on MANY nodes..
//So, once we are full, we will periodically clean our list until we can
//begin storing again..
delete entry;
entry = NULL;
}
count--;
}
CMemFile packetdata(17);
packetdata.WriteUInt128(file);
packetdata.WriteUInt8(load);
DebugSend(Kad2PublishRes, ip, port);
SendPacket(packetdata, KADEMLIA2_PUBLISH_RES, ip, port, senderKey, NULL);
}
从消息里面解出Keyword信息,然后调用CIndexed::AddKeyword()将相关信息保存起来,最后发回一个KADEMLIA2_PUBLISH_RES消息。
最后是Process2PublishSourceRequest():
// KADEMLIA2_PUBLISH_SOURCE_REQ
// Used in Kad2.0 only
void CKademliaUDPListener::Process2PublishSourceRequest(const uint8_t *packetData, uint32_t lenPacket, uint32_t ip, uint16_t port, const CKadUDPKey& senderKey)
{
//Used Pointers
CIndexed *indexed = CKademlia::GetIndexed();
// check if we are UDP firewalled
if (CUDPFirewallTester::IsFirewalledUDP(true)) {
//We are firewalled. We should not index this entry and give publisher a false report.
return;
}
CMemFile bio(packetData, lenPacket);
CUInt128 file = bio.ReadUInt128();
CUInt128 distance(CKademlia::GetPrefs()->GetKadID());
distance.XOR(file);
if (distance.Get32BitChunk(0) > SEARCHTOLERANCE && !::IsLanIP(wxUINT32_SWAP_ALWAYS(ip))) {
return;
}
DEBUG_ONLY( wxString strInfo; )
uint8_t load = 0;
bool flag = false;
CUInt128 target = bio.ReadUInt128();
Kademlia::CEntry* entry = new Kademlia::CEntry();
try {
entry->m_uIP = ip;
entry->m_uUDPport = port;
entry->m_uKeyID.SetValue(file);
entry->m_uSourceID.SetValue(target);
entry->m_bSource = false;
entry->m_tLifeTime = (uint32_t)time(NULL) + KADEMLIAREPUBLISHTIMES;
bool addUDPPortTag = true;
uint32_t tags = bio.ReadUInt8();
while (tags > 0) {
CTag* tag = bio.ReadTag();
if (tag) {
if (!tag->GetName().Cmp(TAG_SOURCETYPE)) {
if (entry->m_bSource == false) {
entry->AddTag(new CTagVarInt(TAG_SOURCEIP, entry->m_uIP));
entry->AddTag(tag);
entry->m_bSource = true;
} else {
//More than one sourcetype tag found.
delete tag;
}
} else if (!tag->GetName().Cmp(TAG_FILESIZE)) {
if (entry->m_uSize == 0) {
if (tag->IsBsob() && tag->GetBsobSize() == 8) {
entry->m_uSize = PeekUInt64(tag->GetBsob());
} else {
entry->m_uSize = tag->GetInt();
}
DEBUG_ONLY( strInfo += CFormat(wxT(" Size=%u")) % entry->m_uSize; )
}
delete tag;
} else if (!tag->GetName().Cmp(TAG_SOURCEPORT)) {
if (entry->m_uTCPport == 0) {
entry->m_uTCPport = (uint16_t)tag->GetInt();
entry->AddTag(tag);
} else {
//More than one port tag found
delete tag;
}
} else if (!tag->GetName().Cmp(TAG_SOURCEUPORT)) {
if (addUDPPortTag && tag->IsInt() && tag->GetInt() != 0) {
entry->m_uUDPport = (uint16_t)tag->GetInt();
entry->AddTag(tag);
addUDPPortTag = false;
} else {
//More than one udp port tag found
delete tag;
}
} else {
//TODO: Filter tags
entry->AddTag(tag);
}
}
tags--;
}
if (addUDPPortTag) {
entry->AddTag(new CTagVarInt(TAG_SOURCEUPORT, entry->m_uUDPport));
}
#ifdef __DEBUG__
if (!strInfo.IsEmpty()) {
AddDebugLogLineN(logClientKadUDP, strInfo);
}
#endif
} catch(...) {
//DebugClientOutput(wxT("CKademliaUDPListener::Process2PublishSourceRequest"),ip,port,packetData,lenPacket);
delete entry;
throw;
}
if (entry->m_bSource == true) {
if (indexed->AddSources(file, target, entry, load)) {
flag = true;
} else {
delete entry;
entry = NULL;
}
} else {
delete entry;
entry = NULL;
}
if (flag) {
CMemFile packetdata(17);
packetdata.WriteUInt128(file);
packetdata.WriteUInt8(load);
DebugSend(Kad2PublishRes, ip, port);
SendPacket(packetdata, KADEMLIA2_PUBLISH_RES, ip, port, senderKey, NULL);
}
}
从消息里面解出File信息,然后调用CIndexed::AddSources()将相关信息保存起来,最后发回一个KADEMLIA2_PUBLISH_RES消息。
CIndexed在aMule的Kademlia协议实现中,用来管理发布的资源信息。
球再一次被提给了发送资源的节点。来看KADEMLIA2_PUBLISH_RES消息的处理。在CKademliaUDPListener::ProcessPacket()中可以看到这样的几个case:
case KADEMLIA2_PUBLISH_RES: DebugRecv(Kad2PublishRes, ip, port); Process2PublishResponse(packetData, lenPacket, ip, port, senderKey); break;
消息的处理被委托给了CKademliaUDPListener::Process2PublishResponse():
void CKademliaUDPListener::Process2PublishResponse(const uint8_t *packetData, uint32_t lenPacket, uint32_t ip, uint16_t port, const CKadUDPKey& senderKey)
{
if (!IsOnOutTrackList(ip, KADEMLIA2_PUBLISH_KEY_REQ) && !IsOnOutTrackList(ip, KADEMLIA2_PUBLISH_SOURCE_REQ) && !IsOnOutTrackList(ip, KADEMLIA2_PUBLISH_NOTES_REQ)) {
throw wxString(CFormat(wxT("***NOTE: Received unrequested response packet, size (%u) in %s")) % lenPacket % wxString::FromAscii(__FUNCTION__));
}
CMemFile bio(packetData, lenPacket);
CUInt128 file = bio.ReadUInt128();
uint8_t load = bio.ReadUInt8();
CSearchManager::ProcessPublishResult(file, load, true);
if (bio.GetLength() > bio.GetPosition()) {
// for future use
uint8_t options = bio.ReadUInt8();
bool requestACK = (options & 0x01) > 0;
if (requestACK && !senderKey.IsEmpty()) {
DebugSend(Kad2PublishResAck, ip, port);
SendNullPacket(KADEMLIA2_PUBLISH_RES_ACK, ip, port, senderKey, NULL);
}
}
}
执行CSearchManager::ProcessPublishResult()做最后的处理,然后根据需要再发送一个KADEMLIA2_PUBLISH_RES_ACK消息回去。至此,整个资源的发布过程完全结束。
再来通过几张图,来总结一下,aMule资源发布过程的消息传递:
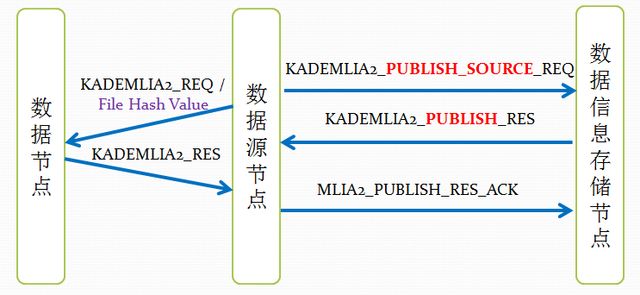
文件发布过程的消息传递
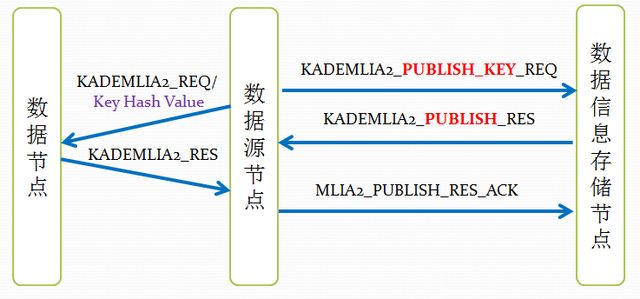
关键字发布的消息传递
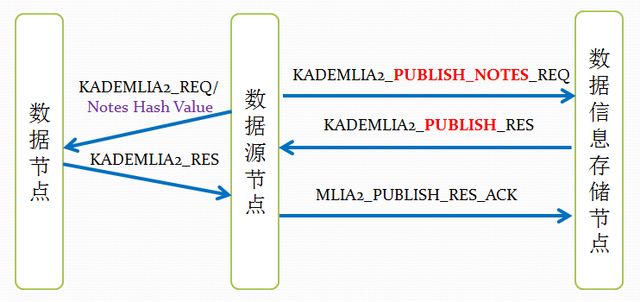
FileNotes发布过程的消息传递
Done。