Hadoop 2.x HDFS新特性
Hadoop 2.x HDFS新特性
HDFS联邦
HDFS HA(要用到zookeeper等,留在后面再讲)
HDFS快照
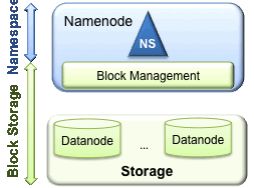
回顾: HDFS两层模型
Namespace: 包括目录、文件和块。它支持所有命名空间相关的文件操作,如创建、删除、修改,查看所有文件和目录。
Block Storage Service(块存储服务) 包括两部分:
1 在namenode中的块的管理:提供datanode集群的注册、心跳检测等功能。处理块的报告信息和维护块的位置信息。支持块相关的操作,如创建、删除、修改、获取块的位置信息。管理块的冗余信息、创建副本、删除多余的副本等。
2 存储: datanode提供本地文件系统上块的存储、读写、访问等。
1.x HDFS架构的弱点
HDFS架构在整个集群中允许且仅允许一个单独的命名空间。命名空间被一个单独的namenode节点所管理。这种架构决策实现简单。但也会产生单点,内存瓶颈,性能瓶颈等限制。
HDFS联邦
目的:水平扩展名称服务
使用多个独立的namenode和namespaces。每个namenode是独立的,不需要和其它namenode协调合作。
datanode作为统一的块存储设备被所有namenode节点使用。
每一个datanode节点都在所有的namenode进行注册。 datanode发送心跳信息、块报告到所有namenode,同时执行所有namenode发来的命令。
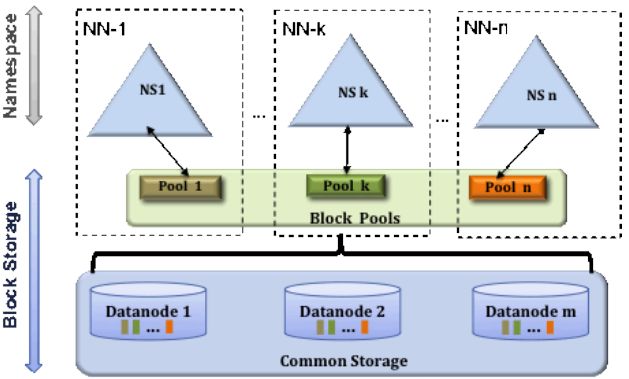
块池( Block Pool)
块池是属于单个命名空间的一组块。
每一个datanode为所有的block pool存储块。
Datanode是一个物理概念,而block pool是一个重新将block划分的逻辑概念。
同一个datanode中可以存着属于多个block pool的多个块。
Block pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。
一个Namenode失效不会影响其下的datanode为其他Namenode的服务。
HDFS联邦的好处
Namespace的可扩展性, 1.x中集群存储可以水平扩展(增加节点),但namespace不可以。
1.x的Namenode 存在单点瓶颈,在2.x中可以通过增加 namenode解决
隔离性。在1.x中,一个拙劣的应用可能耗尽namenode的性能资源从而影响其他应用运行, 2.x的多namenode可以将不同类型的应用和用户隔离在不同的namespaces
命名空间管理细节
https://issues.apache.org/jira/secure/attachment/12453067/high-leveldesign.pdf
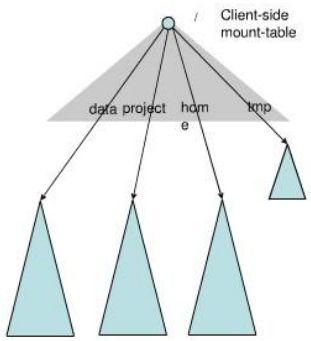
不采用文件名Hash这一在分布式系统里常用的手段,因为同一目录下的文件可能散布于各个命名空间,性能很差
采用Client Side Mount Table,如下图
联邦未解决问题
并非真正HA, namenode失效会造成部分数据无法访问
负载均衡难以自劢完成
HDFS快照
在2.x终于实现了快照
设置一个目录为可快照:
hdfs dfsadmin -allowSnapshot <path>
取消目录可快照:
hdfs dfsadmin -disallowSnapshot <path>
生成快照:
hdfs dfs -createSnapshot <path> [<snapshotName>]
删除快照:
hdfs dfs -deleteSnapshot <path> <snapshotName>
快照位置
可快照目录下的.snapshot子目录
其它快照操作
列出所有可快照目录:
hdfs lsSnapshottableDir
比较快照之间的差异:
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
HDFS联邦
HDFS HA(要用到zookeeper等,留在后面再讲)
HDFS快照
回顾: HDFS两层模型
Namespace: 包括目录、文件和块。它支持所有命名空间相关的文件操作,如创建、删除、修改,查看所有文件和目录。
Block Storage Service(块存储服务) 包括两部分:
1 在namenode中的块的管理:提供datanode集群的注册、心跳检测等功能。处理块的报告信息和维护块的位置信息。支持块相关的操作,如创建、删除、修改、获取块的位置信息。管理块的冗余信息、创建副本、删除多余的副本等。
2 存储: datanode提供本地文件系统上块的存储、读写、访问等。
1.x HDFS架构的弱点
HDFS架构在整个集群中允许且仅允许一个单独的命名空间。命名空间被一个单独的namenode节点所管理。这种架构决策实现简单。但也会产生单点,内存瓶颈,性能瓶颈等限制。
HDFS联邦
目的:水平扩展名称服务
使用多个独立的namenode和namespaces。每个namenode是独立的,不需要和其它namenode协调合作。
datanode作为统一的块存储设备被所有namenode节点使用。
每一个datanode节点都在所有的namenode进行注册。 datanode发送心跳信息、块报告到所有namenode,同时执行所有namenode发来的命令。
块池( Block Pool)
块池是属于单个命名空间的一组块。
每一个datanode为所有的block pool存储块。
Datanode是一个物理概念,而block pool是一个重新将block划分的逻辑概念。
同一个datanode中可以存着属于多个block pool的多个块。
Block pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。
一个Namenode失效不会影响其下的datanode为其他Namenode的服务。
HDFS联邦的好处
Namespace的可扩展性, 1.x中集群存储可以水平扩展(增加节点),但namespace不可以。
1.x的Namenode 存在单点瓶颈,在2.x中可以通过增加 namenode解决
隔离性。在1.x中,一个拙劣的应用可能耗尽namenode的性能资源从而影响其他应用运行, 2.x的多namenode可以将不同类型的应用和用户隔离在不同的namespaces
命名空间管理细节
https://issues.apache.org/jira/secure/attachment/12453067/high-leveldesign.pdf
不采用文件名Hash这一在分布式系统里常用的手段,因为同一目录下的文件可能散布于各个命名空间,性能很差
采用Client Side Mount Table,如下图
联邦未解决问题
并非真正HA, namenode失效会造成部分数据无法访问
负载均衡难以自劢完成
HDFS快照
在2.x终于实现了快照
设置一个目录为可快照:
hdfs dfsadmin -allowSnapshot <path>
取消目录可快照:
hdfs dfsadmin -disallowSnapshot <path>
生成快照:
hdfs dfs -createSnapshot <path> [<snapshotName>]
删除快照:
hdfs dfs -deleteSnapshot <path> <snapshotName>
快照位置
可快照目录下的.snapshot子目录
其它快照操作
列出所有可快照目录:
hdfs lsSnapshottableDir
比较快照之间的差异:
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>