关系代数――附加的关系运算(2)
本节介绍附加的关系运算之除运算。
除(÷)
除是写为 R ÷ S 的二元关系。其结果由 R 中元组到唯一于 R 的属性名字(就是说只在 R 表头中而不在 S 表头中的属性)的限制构成,并且它们与 S 中的元组的所有组合都存在于 R 中。例如下面的“完成”和“DB项目”和它们的除法:
|
|
|
为了更好的说明,我们在mysql中定义上面的表,并插入相应的数据。
- mysql> create table finish(Student varchar(10), Task varchar(10));
- Query OK, 0 rows affected (0.00 sec)
- mysql> create table DB_Project(Task varchar(10));
- Query OK, 0 rows affected (0.01 sec)
插入相应的数据后结果如下:
- mysql> select * from finish;
- +---------+-----------+
- | Student | Task |
- +---------+-----------+
- | Fred | Database1 |
- | Fred | Database2 |
- | Fred | Compiler1 |
- | Eugene | Database1 |
- | Eugene | Compiler1 |
- | Sara | Database1 |
- | Sara | Database2 |
- +---------+-----------+
- 7 rows in set (0.00 sec)
- mysql> select * from DB_Project;
- +-----------+
- | Task |
- +-----------+
- | Database1 |
- | Database2 |
- +-----------+
- 2 rows in set (0.00 sec)
如果“DB项目”包含数据库项目的所有任务,则这个除法的结果精确的包含已经完成了数据库项目的所有学生。
更形式的说除法的语义定义如下:
-
R ÷
S = {
t[
a1,...,an] : t
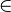 R
R

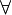 s
S ( (
t[
a1,...,an]
s
S ( (
t[
a1,...,an]
 s)
R) }
s)
R) }
这里的 {a1,...,an} 是唯一于 R 的属性名字的集合而 t[a1,...,an] 是 t 到这个集合的限制。通常要求在 S 的表头中的属性名字是 R 的表头的属性名字的子集,否则运算的结果永远为空。
除运算可以用基本运算模拟如下。
我们假定 a1,...,an 是唯一于 R 的属性名字而 b1,...,bm 是 S 的属性名字。
1. 在第一步中我们投影 R 于它的唯一属性上,并接着构造它们与 S 的元组的所有组合:
- T := π a1,...,an( R) × S
在上面例子中,T 将是表示所有学生(因为 Student 是“完成”表的唯一键/属性)与所有给定任务的组合的表。
相应T的SQL语句和运算结果为:
- mysql> select distinct * from -> (select Student from finish) -> finish, DB_Project; +---------+-----------+ | Student | Task | +---------+-----------+ | Fred | Database1 | | Fred | Database2 | | Eugene | Database1 | | Eugene | Database2 | | Sara | Database1 | | Sara | Database2 | +---------+-----------+ 6 rows in set (0.00 sec)
2.在下个步骤中,我们从这个关系中减去 R:
- U := T - R
注意在 U 的都是 R 中没有出现的可能的组合。
相应U的SQL语句和运算结果为:
- mysql> select distinct * from
- -> (select Student from finish)
- -> finish, DB_Project
- -> where (Student, Task) not in
- -> (select * from finish);
- +---------+-----------+
- | Student | Task |
- +---------+-----------+
- | Eugene | Database2 |
- +---------+-----------+
- 1 row in set (0.00 sec)
3.所以如果现在做到唯一于 R 的属性名字的投影,则我们有了 R 中元组的限制,它们与 S 的元组的所有组合未都出现在 R 中:
- V := π a1,...,an( U)
-
相应V的SQL语句和运算结果为:
- mysql> select distinct Student from
- -> (select Student from finish)
- -> finish, DB_Project
- -> where (Student, Task) not in
- -> (select * from finish);
- +---------+
- | Student |
- +---------+
- | Eugene |
- +---------+
- 1 row in set (0.00 sec)
4.剩下的就是投影 R 到唯一于它的属性名字并减去 V:
- W := π a1,...,an( R) - V
-
相应W的SQL语句和运算结果为:
- mysql> select distinct Student from finish
- -> where Student not in
- -> (select distinct Student from
- -> (select Student from finish)
- -> finish, DB_Project
- -> where (Student, Task) not in
- -> (select * from finish));
- +---------+
- | Student |
- +---------+
- | Fred |
- | Sara |
- +---------+
- 2 rows in set (0.00 sec)
例:找出在位于Brooklyn的所有支行都有账号的客户。
首先得到位于Brooklyn的所有支行:
s = πbranch_name (σbranch_city= "Brooklyn" (branch))
相应s的SQL语句和运算结果为:
- mysql> create view s as -> (select branch_name from branch -> where branch_city="Brooklyn"); Query OK, 0 rows affected (0.02 sec) mysql> select * from s; +-------------+ | branch_name | +-------------+ | Brighton | | Downtown | +-------------+ 2 rows in set (0.00 sec)
其次找出客户在支行有贷款的所有(customer_name,branch_name)对:
r = πcustomer_name, branch_name (depositor
account)
相应r的SQL语句和运算结果为:
- mysql> create view r as
- -> (select customer_name, branch_name
- -> from depositor inner join account
- -> on depositor.account_number=account.account_number);
- Query OK, 0 rows affected (0.01 sec)
- mysql> select * from r;
- +---------------+-------------+
- | customer_name | branch_name |
- +---------------+-------------+
- | Hayes | Perryridge |
- | Johnson | Downtown |
- | Johnson | Brighton |
- | Jones | Brighton |
- | Lindsay | Redwood |
- | Smith | Mianus |
- | Turner | Round Hill |
- +---------------+-------------+
- 7 rows in set (0.00 sec)
现在我们需要找出这样的客户,他与r1中的每个支行名称的结对都在r2中出现。
给出这样的所有客户的运算就是除运算。此查询可以表述为:
πcustomer_name, branch_name (depositor
÷ πbranch_name (σbranch_city= "Brooklyn" (branch))
根据上面的讨论,其实除运算可以用以下基本运算表示:r ÷ s = πR-S(r)-πR-S((πR-S(r)
s)- πR-S,S(r))
因此,我们可以通过以下步骤分解进行计算:
1. 计算T,也即投影 R 于它的唯一属性上,并接着构造它们与 S 的元组的所有组合
T := πa1,...,an(R) × S相应T的SQL语句和运算结果为:
- mysql> select * from (select distinct customer_name from r) r,s;
- +---------------+-------------+
- | customer_name | branch_name |
- +---------------+-------------+
- | Hayes | Brighton |
- | Johnson | Brighton |
- | Jones | Brighton |
- | Lindsay | Brighton |
- | Smith | Brighton |
- | Turner | Brighton |
- | Hayes | Downtown |
- | Johnson | Downtown |
- | Jones | Downtown |
- | Lindsay | Downtown |
- | Smith | Downtown |
- | Turner | Downtown |
- +---------------+-------------+
- 12 rows in set (0.00 sec)
2.在下个步骤中,我们从这个关系中减去 R:
- U := T - R
注意在 U 的都是 R 中没有出现的可能的组合。
相应U的SQL语句和运算结果为:
- mysql> select * from (select distinct customer_name from r) r,s
- -> where (customer_name, branch_name)
- -> not in
- -> (select * from r);
- +---------------+-------------+
- | customer_name | branch_name |
- +---------------+-------------+
- | Hayes | Brighton |
- | Lindsay | Brighton |
- | Smith | Brighton |
- | Turner | Brighton |
- | Hayes | Downtown |
- | Jones | Downtown |
- | Lindsay | Downtown |
- | Smith | Downtown |
- | Turner | Downtown |
- +---------------+-------------+
- 9 rows in set (0.00 sec)
3.所以如果现在做到唯一于 R 的属性名字的投影,则我们有了 R 中元组的限制,它们与 S 的元组的所有组合未都出现在 R 中:
- V := π a1,...,an( U)
-
相应V的SQL语句和运算结果为:
- mysql> select distinct customer_name
- -> from (select distinct customer_name from r) r,s
- -> where (customer_name, branch_name)
- -> not in (select * from r);
- +---------------+
- | customer_name |
- +---------------+
- | Hayes |
- | Lindsay |
- | Smith |
- | Turner |
- | Jones |
- +---------------+
- 5 rows in set (0.00 sec)
4.剩下的就是投影 R 到唯一于它的属性名字并减去 V:
- W := π a1,...,an( R) - V
-
相应W的SQL语句和运算结果为:
- mysql> select distinct customer_name from r
- -> where customer_name not in
- -> (select distinct customer_name
- -> from (select distinct customer_name from r) r,s
- -> where (customer_name, branch_name)
- -> not in (select * from r));
- +---------------+
- | customer_name |
- +---------------+
- | Johnson |
- +---------------+
- 1 row in set (0.01 sec)