MySQL_HA 部署
提到MySQL高可用性,很多人会想到MySQL Cluster,或者Heartbeat+DRBD,不过这些方案的复杂性常常让人望而却步,与之相对,利用MySQL复制实现高可用性则显得容易很多,目前大致有MMM,PRM,MHA等方案可供选择:MMM是最常见的方案,可惜它问题太多(What’s wrong with MMM,Problems with MMM for MySQL);至于PRM,它还是个新项目,暂时不推荐用于产品环境,不过作为Percona的作品,它值得期待;如此看来目前只能选MHA了,好在经过DeNA大规模的实践应用证明它是个靠谱的工具。
MHA分管理节点和数据库节点,数据库节点由mysql主从或主主构成,当主库挂掉后,管理节点会自动将从节点提升为主节点;管理节点的角色类似于oracle数据库中的fast start failover中的observer,但mha上层可以通过keepalive部署VIP,程序连接数据库使用VIP,从而实现后台数据库的故障切换透明化。
MHA节点包含三个脚本,依赖perl模块;
save_binary_logs:保存和复制当掉的主服务器二进制日志;
apply_diff_relay_logs:识别差异的relay log事件,并应用于其他salve服务器;
purge_relay_logs:清除relay log文件;
#安装:
作为前提条件,应先配置MySQL复制,并设置SSH公钥免密码登录。下面以CentOS为例来说明,最好先安装epel,不然YUM可能找不到某些软件包。
MHA由Node和Manager组成,Node运行在每一台MySQL服务器上,也就是说,不管是MySQL主服务器,还是MySQL从服务器,都要安装Node,而Manager通常运行在独立的服务器上,但如果硬件资源吃紧,也可以用一台MySQL从服务器来兼职Manager的角色。
需要在所有mysql服务器上安装MHA节点,MHA管理服务器也需要安装。MHA管理节点模块内部依赖MHA节点模块;
MHA管理节点通过ssh连接管理mysql服务器和执行MHA节点脚本。MHA节点依赖perl的DBD::mysql模块;
#MHA安装包组成
MHA安装包包括MHA manager和MHA node包。
MHAmanager安装在管理服务器上。
MHA nod安装在每一台服务器上包括manager服务器和master服务器。
MHA程序是用per语言编写
mha4mysql-manager #管理节点需要安装
mha4mysql-node #每个节点都需要安装
#下载地址
https://mysql-master-ha.googlecode.com
#安装Node
在全部服务器上安装mha-node包
作用:
1、Master crash后保存复制二进制日志
2、判断所有的差异中继日志,并应用到需要应用的slave上
3、清空所有的中继日志
yum -y install perl-DBD-MySQL
rpm -ivh mha4mysql-node-0.53-0.noarch.rpm
#安装Manager
在管理节点上安装mha-manager包
作用:监控master是否宕机,进行宕机切换
yum -y install perl-libwww-perl
rpm -ivh perl-Config-Tiny
rpm -ivh perl-Params-Validate
rpm -ivh perl-Log-Dispatch
rpm -ivh perl-Parallel-ForkManager
rpm -ivh mha4mysql-manager-0.53-0.noarch.rpm
rpm -ivh mha4mysql-node-0.53-0.noarch.rpm
#源码安装需要以下包
yum -y install libdbd-mysql-perl
yum -y install libconfig-tiny-perl
yum -y install liblog-dispatch-perl
yum -y install libparallel-forkmanager-perl
yum -y install libnet-telnet-perl
#源码安装mha-manager节点
tar xf mha4mysql-manager-0.52.tar.gz
cd mha4mysql-manager-0.52
perl Makefile.PL
make && make install
#源码安装mha-node节点
tar xf mha4mysql-node-0.52.tar.gz
cd mha4mysql-node-0.52
perl Makefile.PL
make && make install
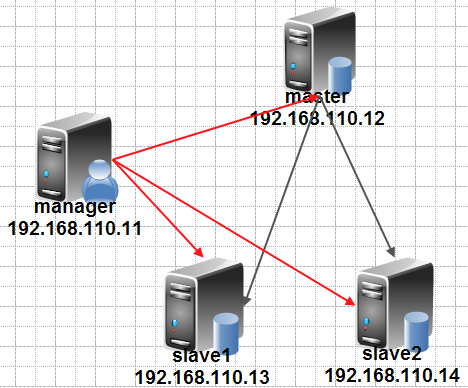
#实验环境:
四台服务器:一个manager服务器,一个master服务器,两个slave服务器
操作系统:CentOS_5.8_64bit
Manager:192.168.110.11
Master:192.168.110.12
Slave1:192.168.110.13
Slave2:192.168.110.14
#配置ssh解决ssh慢的情况
在所有节点上编辑/etc/ssh/sshd_config文件
找到UseDNS、GSSAPIAuthentication设置为no
UseDNS no
GSSAPIAuthentication no
#建立ssh密钥互信
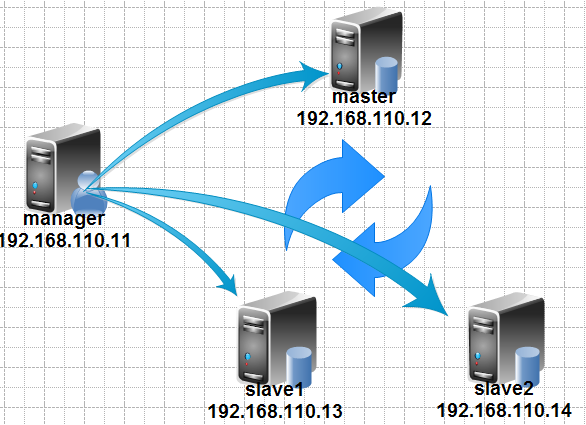
#在manager节点,PS:要在家目录下做以下命令
ssh-keygen
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
#在master节点:
ssh-keygen
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
#在slave1节点:
ssh-keygen
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
#在slave2节点:
ssh-keygen
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
#配置主从
Master和Slave都要开启binlog日志,mysql service_id设置成不同数值。Slave的中继日志不要自定义路径,采用默认路径。如果slave不开启binlog日志,故障切换会不成功。
1,检查每个节点防火墙是否允许节点间相互访问
2,在master节点上建立用于主从复制的账号
mysql> grant replication slave on *.* to 'slave'@'192.168.110.%' identified by "slave";
mysql> flush privileges;
mysql> grant replication slave on *.* to 'slave'@'192.168.110.%' identified by "slave";
mysql> flush privileges;
#查看当前binlog日志,和日志位置
mysql> show master status;
3,在slave1上连接master建立主从复制
mysql> change master to
-> master_user='slave',
-> master_password='slave',
-> master_host='192.168.110.12', #指定master服务器IP
-> master_log_file='mysql-bin.00000X',
-> master_log_pos=XXX;
mysql> start slave;
mysql> show slave status\G
4,在slave2上连接master建立主从复制
mysql> change master to
-> master_user='slave',
-> master_password='slave',
-> master_host='192.168.110.12' #指定master服务器IP
-> master_log_file='mysql-bin.00000X',
-> master_log_pos=XXX;
mysql> start slave;
mysql> show slave status\G
#建立manager管理账户
1,在master节点上,建立允许manager访问数据库的“manager”账户,主要用于show slave status,reset salve
mysql> grant super,reload,replication client,select on *.* to 'manager'@'192.168.110.%' identified by "manager"; #指定manager服务器的IP
2,在slave1(192.168.110.13)上,建立用于日志同步的账号和主从同步的账号
mysql> grant super,create,insert,update,delete,drop,select on *.* to 'manager'@'192.168.110.13' identified by "manager"; #日志同步的账号
mysql> grant replication slave on *.* to 'slave'@'192.168.110.%' identified by "slave"; #主从同步的账号
mysql> flush privileges;
3,在slave2(192.168.110.14)上,建立用于日志同步的账号和主从同步的账号
mysql> grant super,create,insert,update,delete,drop,select on *.* 'manager'@'192.168.110.14' identified by "manager"; #日志同步的账号
mysql> grant replication slave on *.* to 'slave'@'192.168.110.%' identified by "slave"; #主从同步的账号
mysql> flush privileges;
#配置mha管理环境及配置文件
1,在备用节点和从节点的slave1和slave2上把slave设置成只读模式,中继日志自动删除去掉
mysql> set global read_only=1;
mysql> set global relay_log_purge=0;
#也可以通过编辑/etc/my.cnf中加入选项
vim /etc/my.cnf
read_only=1
relay_log_purge=0
2,在所有mysql节点上
(1)删除系统自带的mysql管理工具,并对源码包安装的管理工具建立软连接。主要是解决系统自带的管理工具与源码包安装的版本不一致问题。
rm -rf /usr/bin/mysql*
rm -rf /usr/bin/msql2mysql
rm -rf /usr/bin/my_print_defaults
ln -s /usr/local/mysql/bin/* /usr/bin/
(2)注释掉配置文件/etc/my.cnf客户端字符集设置
主要解决使用mysqlbinlog解析binlog日志包mysqlbinlog: unknown variable 'default-character-set=utf8'错误提示
[client]
port = 3306
socket = /tmp/mysql.sock
#default-character-set =utf8
3,在manager节点上
#建立mha管理目录
mkdir -p /etc/managerha #用于存放mha的配置文件
mkdir -p /managerha/app1 #用于存放mha的日志文件
#或可以编辑成两个配置文件
vim masterha_default.cnf #全局配置文件
vim masterha_application.cnf #应用配置文件
cd /etc/managerha/
vim app1.cnf
#配置全局设置
[server default]
manager_workdir=/managerha/app1
manager_log=/managerha/app1/manager.log
user=manager
password=manager
ssh_user=root
repl_user=slave
repl_password=slave
ping_interval=3
#配置应用设置
[server1]
hostname=192.168.110.12
master_binlog_dir=/usr/local/mysql/data
[server2]
hostname=192.168.110.13
master_binlog_dir=/usr/local/mysql/data
[server3]
hostname=192.168.110.14
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
#检查配置环境
#检查ssh互信环境
masterha_check_ssh --conf=/etc/managerha/app1.cnf
Thu Dec 20 08:54:21 2012 - [info] All SSH connection tests passed successfully.
#说明ssh互信环境符合要求。
#检查主从复制配置及管理权限是否配置正确
masterha_check_repl --conf=/etc/managerha/app1.cnf
MySQL Replication Health is OK.
#此句话表明主从复制状态是正常的
#MHA管理
1,启动manager管理进程
masterha_manager --conf=/etc/managerha/app1.cnf
......[info] Reading server configurations from /etc/managerha/app1.cnf......
nohup masterha_manager --conf=/etc/managerha/app1.cnf > /tmp/mha_manager.log < /dev/null 2>&1 &
masterha_check_status --conf=/etc/managerha/app1.cnf
2,查看日志
tail -f /managerha/app1/manager.log
......[info] Ping succeeded, sleeping until it doesn't respond......
#测试
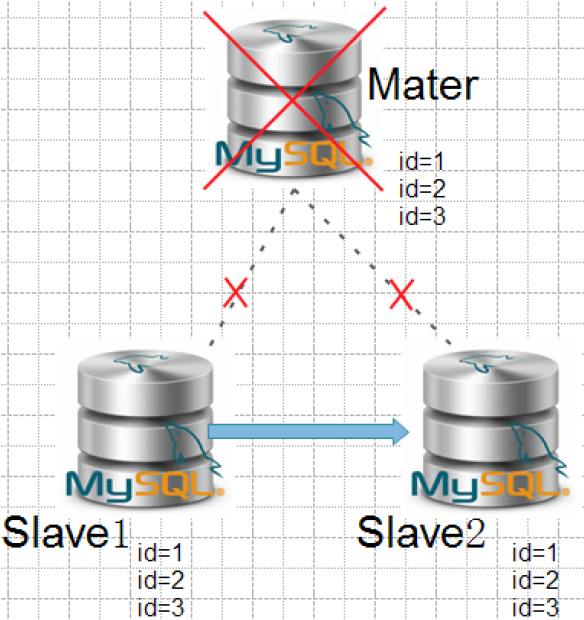
模拟测试一
情景:所有的slave已经接收完整的数据,master宕机。任何一个slave都可以作为master服务器,不需要做数据恢复。
use test;
create table t1 (id int primary key,name varchar(20));
insert into t1 value (1,'demo1');
insert into t1 value (2,'demo2');
insert into t1 value (3,'demo3');
2,在slave1和slave2上查看测试数据
select * from test.t1;
show slave status\G
3,在master节点上kill掉mysql进程
killall -9 mysqld mysqld_safe
tail -f /managerha/app1/manager.log
......
Master failover to 192.168.110.13(192.168.110.13:3306) completed successfully.
4,观察slave1的复制进程
已经连接到新的master(slave2)192.168.110.14上
show slave status\G
5,观察slave2的复制进程
复制进程已经关闭
结论:
在slave数据完全同步的情况下,mha可以完成故障切换,重构主从架构
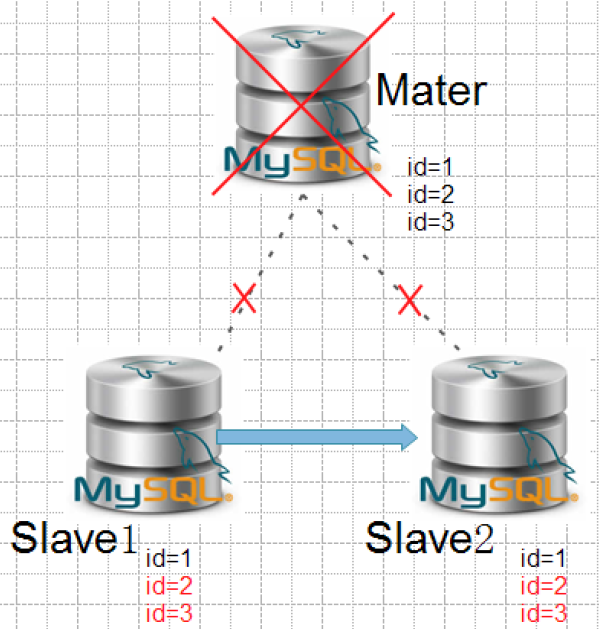
模拟测试二
情景:所有的slave接收到了相同的数据,但是不完整。这时Master机器出现故障如果主机还可以通过ssh访问的话,MHA可以把差异的binlog数据,并应用到slave,选一个slave做新的master。使用mysql的半同步来减少所有的slave数据不完整的风险。
rm -rf /managerha/app1/app1.app1.failover.complete
2,重新搭建master对应两个slave架构
3,在master节点上,创建测试数据
drop table test.t1;
use test;
create table t1 (id int primary key,name varchar(20));
insert into t1 value (1,'demo1');
4,在salve上停止slave复制
stop slave
5,在master上插入测试数据
insert into t1 value (2,'demo2');
insert into t1 value (3,'demo3');
6,查看master测试数据
select * from test.t1;
7,查看slave测试数据
8,在master上kill掉mysql进程
killall -9 mysqld mysqld_safe
tail -f /managerha/app1/manager.log
9,观察slave测试数据
没有从主同步的数据已经恢复到slave上
10,观察slave1已经连接到新的master(slave2)上
show slave status\G
结论:
Slave没有完全同步数据且slave的数据一致master crash时,mha可以同步未同步的数据后进行主从结构重构。
#模拟测试三
情景:Slave接受到的数据不一致,并且没有slave接受了完整的数据。选择一个接收数据最多的slave把差异数据应用到别的slave上,并应用master的binlog使数据完整。
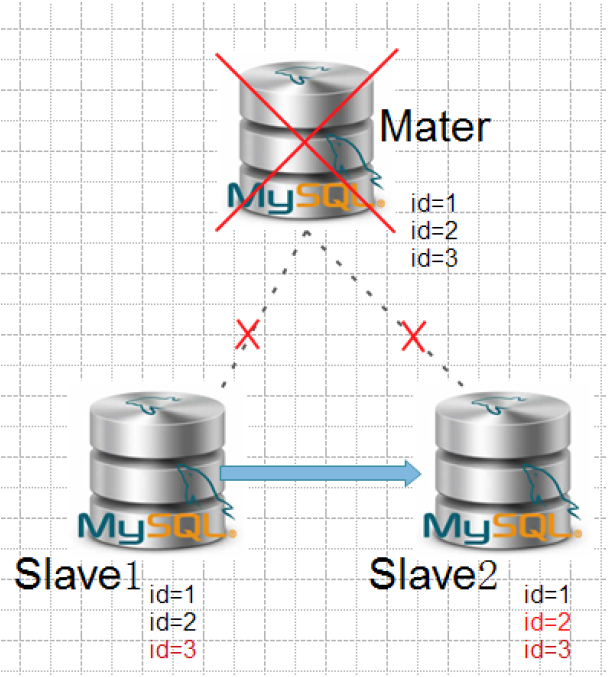
rm -rf /managerha/app1/app1.failover.complete
2,重新搭建master对应两个slave架构
3,在master节点上创建测试数据
drop table test.t1;
use test;
create table t1(id int primary key,name varchar(20));
insert into t1 value (1,'demo1');
4,在slave2上关闭slave复制
stop slave;
5,在master上插入测试数据
insert into t1 value (2,'demo2');
6,在slave1上关闭复制进程
stop slave;
7,在master上插入测试数据
insert into t1 value (3,'demo3');
8,查看master测试数据
select * from test.t1;
9,查看slave1测试数据
select * from test.t1;
10,查看slave2测试数据
select * from test.t1;
11,在master上kill掉mysql进程
killall -9 mysqld mysqld_safe
12,查看manager日志
tail -f /managerha/app1/manager.log
13,slave1上查看
slave数据没有复制的数据都已经同步。并且slave1连接到了新的master(slave2)上。
select * from test.t1;
14,slave2上查看测试数据
select * from test.t1;
结论:
Master crash时Slave接受到的数据不一致,并且没有slave接受了完整的数据。MHA选择一个接收数据最多的slave把差异数据应用到别的slave上,并应用master的差异binlog到slave上使数据完整,再完成主从架构重构。