CentOS 6.4 安装Nagios网络监视工具并解决访问报错问题 (下)
问题分享:我在访问的时候提示没有权限访问,搞了半天原来是SElinux惹的祸,修改SELinux的实时运行模式,setenforce 0 (设置SELinux 成为permissive模式)这个只是临时解决方法,优点是不需重启系统生效,但如果要彻底禁用SELinux 需要在/etc/sysconfig/selinux中设置参数selinux=0
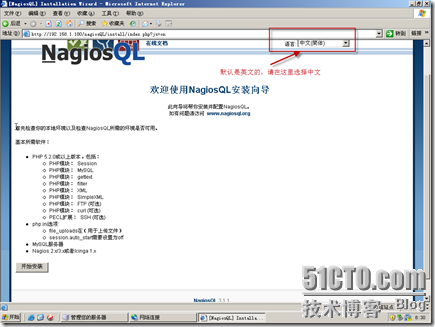
选取中文然后点开始安装按钮
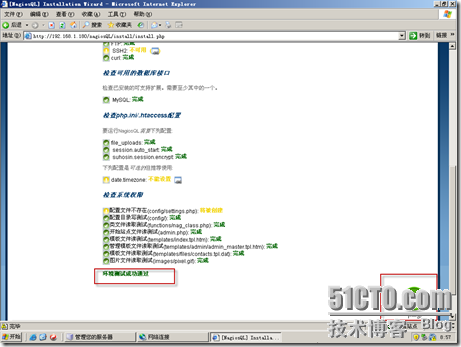
测试所需环境通过,直接按下一步即可
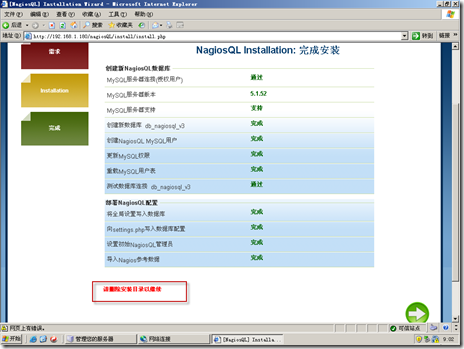
删除安装目录,这里使用改权限:chmod 000 /usr/local/nagios/nagiosql/install
![]()
到这里安装步骤总算结束了,下面我们还需要进行相关配置工作.
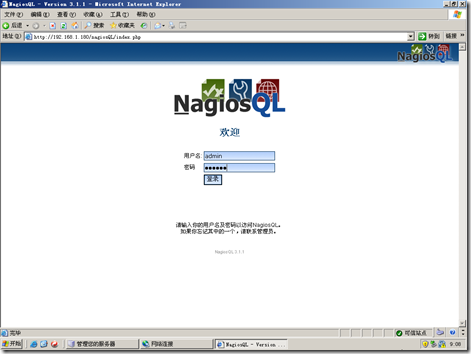
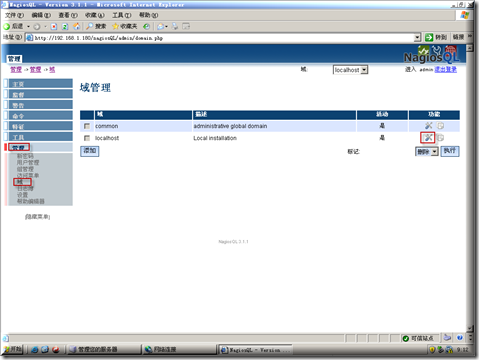
管理-域-localhost---点“修改”
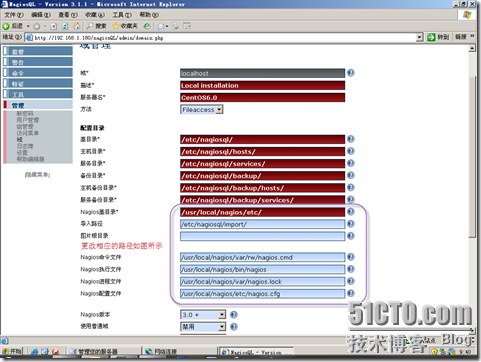
按如图所示更改相应的路径即可
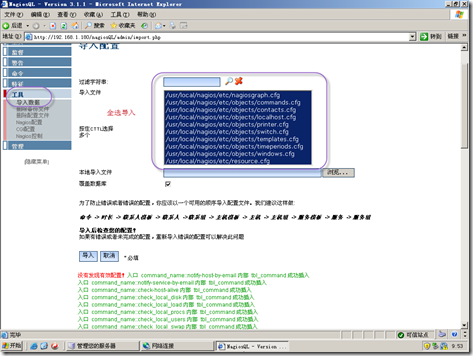
工具-导入数据 右边会列出一些配置文件,选择导入即可。
导入只是把配置文件内容导入到Mysql数据库,而使用其配置文件时,是一个个cfg文件,所以下面要进行写入过程
工具-nagios控制-写入检测数据-写入其他数据
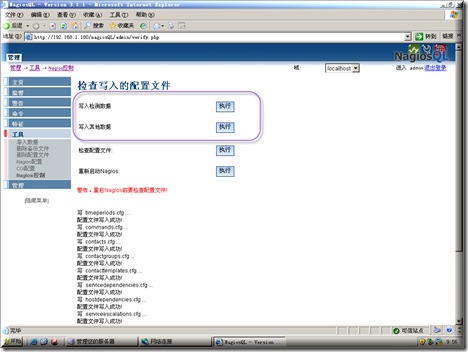
检查配置文件成功
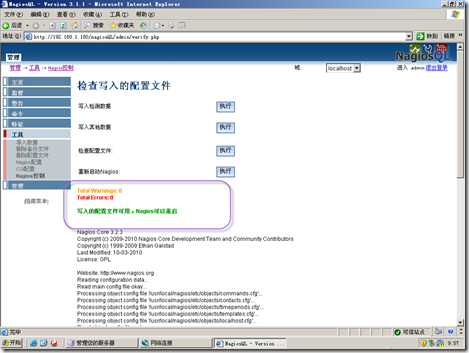
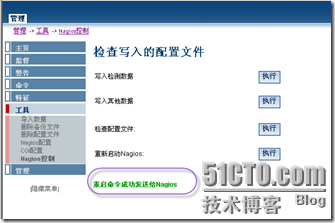
写入之后就可以看到相应的cfg文件了,查看写入是否成功,由下面的输出可以看出写入是成功滴.

修改nagios的配置文件,将原有以cfg_file开头项全部注释掉,加入上面新写入的配置文件
![]()
注释掉
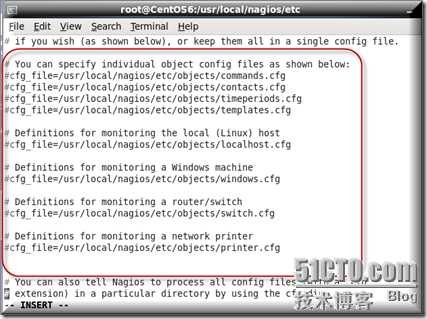
加入新的配置文件路径
cfg_dir=/etc/nagiosql/hosts/
cfg_dir=/etc/nagiosql/services/
cfg_file=/etc/nagiosql/commands.cfg
cfg_file=/etc/nagiosql/contactgroups.cfg
cfg_file=/etc/nagiosql/contacts.cfg
cfg_file=/etc/nagiosql/contacttemplates.cfg
cfg_file=/etc/nagiosql/hostdependencies.cfg
cfg_file=/etc/nagiosql/hostescalations.cfg
cfg_file=/etc/nagiosql/hostextinfo.cfg
cfg_file=/etc/nagiosql/hostgroups.cfg
cfg_file=/etc/nagiosql/hosttemplates.cfg
cfg_file=/etc/nagiosql/servicedependencies.cfg
cfg_file=/etc/nagiosql/serviceescalations.cfg
cfg_file=/etc/nagiosql/serviceextinfo.cfg
cfg_file=/etc/nagiosql/servicegroups.cfg
cfg_file=/etc/nagiosql/servicetemplates.cfg
cfg_file=/etc/nagiosql/timeperiods.cfg

检查nagios的配置文件是否有问题,然后生重启nagios服务,至此整个搭建过程终于完成了,下一节将讲解重头戏,怎么用nagiosQL添加需要监控的主机以及启用nagios报警机制,待续~~!
监控Windows主机
nagios监控windows系统主机有三种实现方式:SNMP,NSClient++,NRPE,后面两种方式都需要在windows上安装agent,本文档只介绍使用NSClient++方式来监控Windows
被监控机Windows主机插件安装和配置
下载地址:
http://nsclient.org/nscp/downloads
这里我用到的是0.3.8.zip版本,发现用0.3.9最新版本在windows server2003 sp1兼容不佳,启动不起来
解压出来然后执行安装命令
![]()
这里前面需要加-noboot参数进行安装,否则也会出问题
![]()
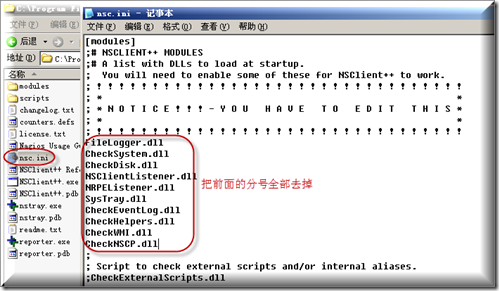
解压出来编辑nsc.ini,把前面的分号去掉如下图所示
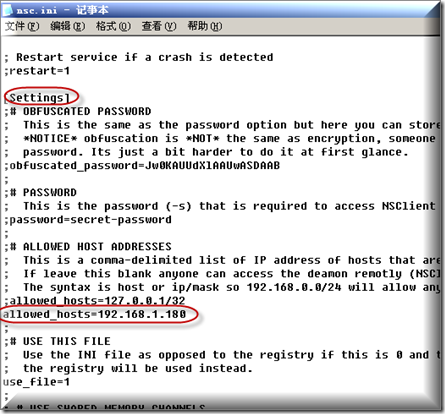
在settings部分加入允许主机访问的服务器IP地址,这里要对号入座,输入你的nagios服务器的IP即可
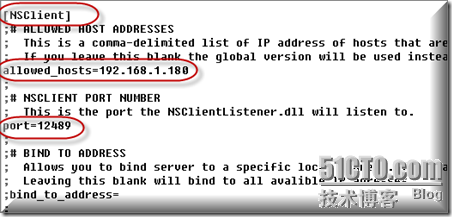
在nsclient部分开启NSClinet的默认监听端口12489以及允许访问本机的主机名称,编辑完以后保存退出.
再用命令netstat �Can 查看确认端口服务已经运行.

再到服务器运行./check_nrpe �CH 要监控服务器的主机IP地址,看到如下图所示表示通过没有问题
![]()
用NagiosQL来添加要监控的主机
监督-HOST-添加
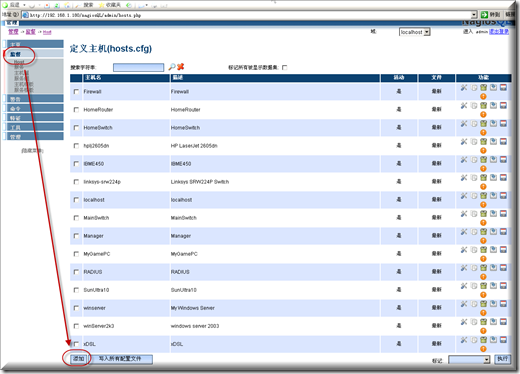
设置主机名、地址、选择模板
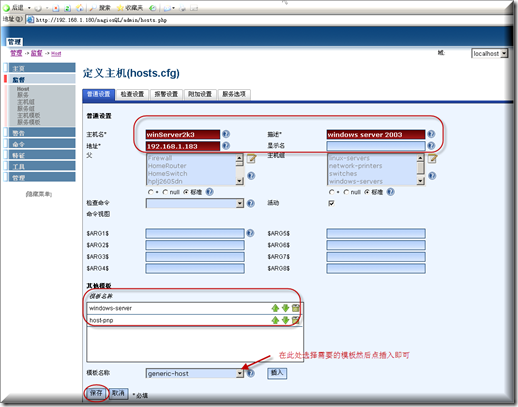
然后添加需要的其它服务,先添加C盘的使用情况,监督-服务-添加
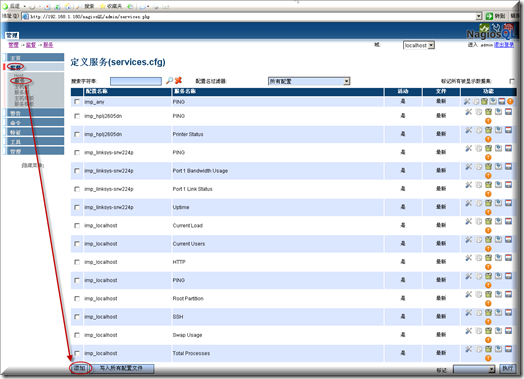
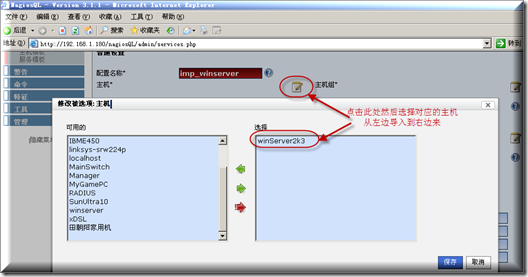
总体设置状况请按如下图所示操作完成

上面只是讲解定义一个服务的方法,其实里面都已经定义好了相关要监控的服务了,所以我们可以直接调用这些服务了,想学习更多,可以点修改看看每项是怎么设定的.(想监控什么东西要靠自己多学习然后举一反三来自定义出自己想要的服务来)
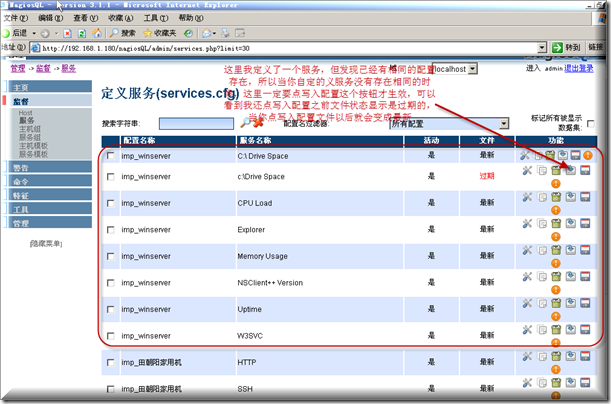
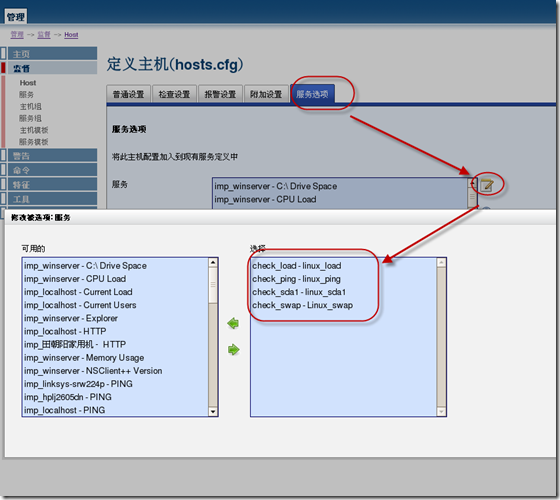
为当前主机添加上面定义好的服务,(再返回到当前以定义好的主机上面来)选择"服务选项"-选择定义好的需要监控服务,其实在定义服务的时候也可以选择主机的,也可以在主机这里选择相关服务
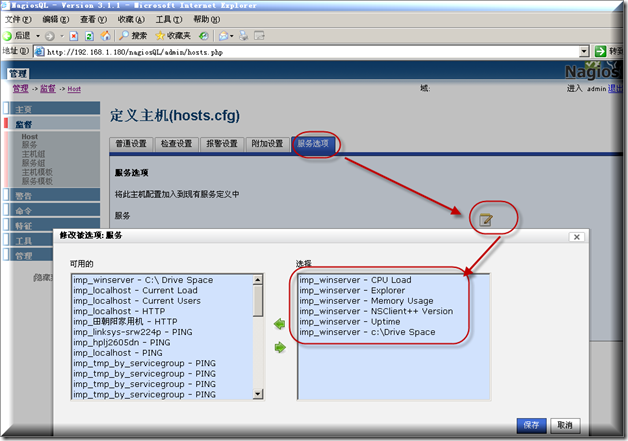
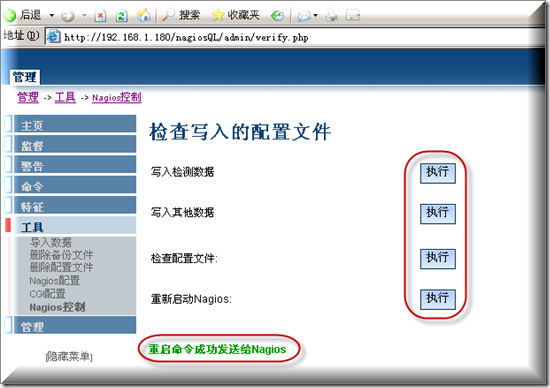
记得需要在这里选写入配置才行,然后重启Nagios服务即可
![]()
从上到下执行一次
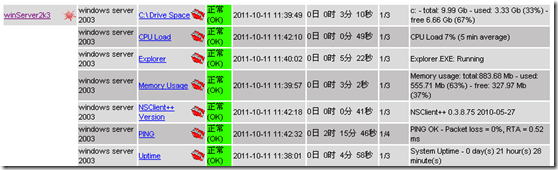
过一段时间就可以在Nagios界面上看到如下界面图
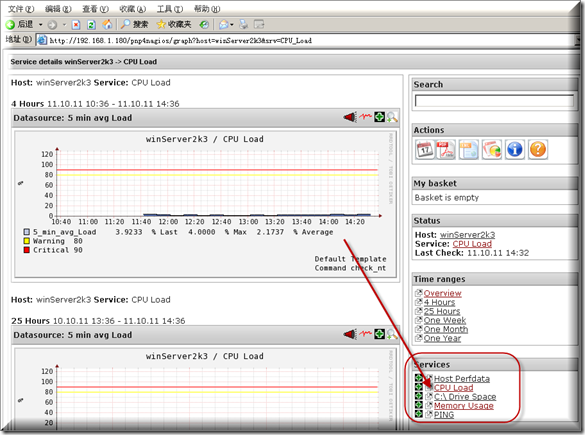
在图形监控界面点相应服务选项则出相应的图形监控界面.
为服务器加美化标识图标
如下图所示若设备是路由器我们就在它后面加一个图由器的图标,是服务就加服务器的图标,一眼就能区别这个设备属于什么类型,方便管理区别,
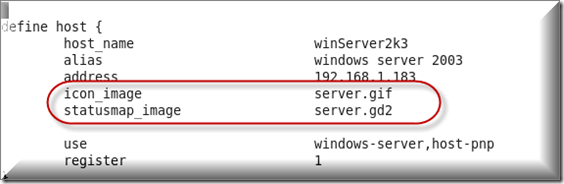
[通过阅读官方文档,得知在host定义中有四个变量可选,用于指定每一个host的图标文件名,默认的存储位置是/usr/local/nagios/share/images/logos
icon_image: 可以使用GIF, PNG,或者是JPG文件,推荐图像尺寸为40x40
icon_image_alt: 即为HTML语法中关于image元素的ALT属性值
vrml_image: Nagios提供使用VRML语言绘制三维图像功能,这里不要使用透明图片(PNG, GIF),最好使用JPG
statusmap_image: 提供给statusmap CGI脚本使用的图片,服务器要支持GD,这个文件的类型为gd2]
winServer2k3未加服务器图标之前的样子

注意主机配置文件在/etc/nagiosql/hosts目录下面
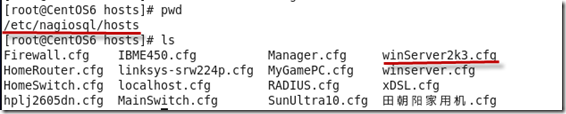
编辑需要加图标的主机配置文件,然后按如下图所示加入两行
![]()
重启nagios服务以后,可以看到图标出来了.

监控Linux主机
nagios监控linux服务器, 因为监控都是依靠插件去完成的,而监控linux主要使用NRPE插件,
首先简单介绍一下NRPE监控基础,及监控过程,然后一步步的配置一个实例实现监控linux服务器
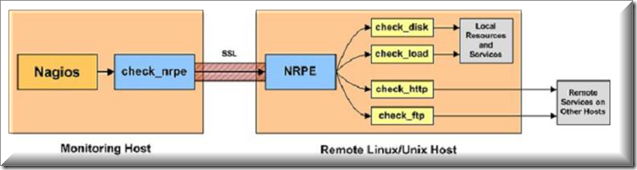
NRPE总共由两部分组成:
check_nrpe插件:运行在监控主机上
NRPE daemon:运行在远程的linux主机上(通常就是被监控机)
整个的监控过程:
当Nagios需要监控某个远程linux主机的服务或者资源情况时:
1:nagios运行check_nrpe插件,我们要在nagios配置文件中告诉它要检查什么.
2:check_nrpe插件会通过SSL连接到远程的NRPE daemon.
3:NRPE daemon会运行相应的nagios插件来执行检查本地资源或服务.
4:NRPE daemon将检查的结果返回给check_nrpe插件,插件将其递交给nagios做处理.
注意:NRPE daemon需要nagios插件和Nrpe一起安装在远程被监控linux主机上,否则,daemon不能做任何的监控. 别外因为它们间的通信是加密的SSL,所以需要安装SSL
被监控端安装NRPE和 nagios-plugins
增加一nagios用户,然后下载插件
wget http://prdownloads.sourceforge.net/sourceforge/nagiosplug/nagios-plugins-1.4.15.tar.gz
解压插件
![]()
编译安装
![]()
![]()
装完以后确认一下相关数据文件是否存在

下载nrpe
wget http://prdownloads.sourceforge.net/sourceforge/nagios/nrpe-2.12.tar.gz
![]()
解压
![]()
编译安装

![]()
然后按如下图所示操作
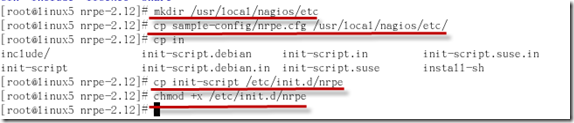
编辑nrpe.cfg在allowed_hosts后面加上nagios服务器的IP地址.
vi /etc/local/nagios/etc/nrpe.cfg

启动服务然后查看服务端口的运行状态.

设定服务自启动
![]()
验证测试NRPE
在本地测试一下自己

在服务器端做测试

配置NRPE文件根据自己的需求加入你需要监控服务,这一步非常重要,比如说你想要监控本机的SWAP分区,那里你需要在里面加入
command[check_swap]=/usr/local/nagios/libexec/check_swap �Cw 20% �Cc 10%,如果这里没有定义好,那你在服务器端会报错误:NRPE command ‘check_swap’ not defined
![]()
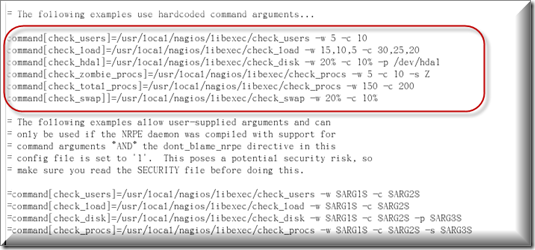
进入nagiosQL管理控制台点 命令-定义-添加
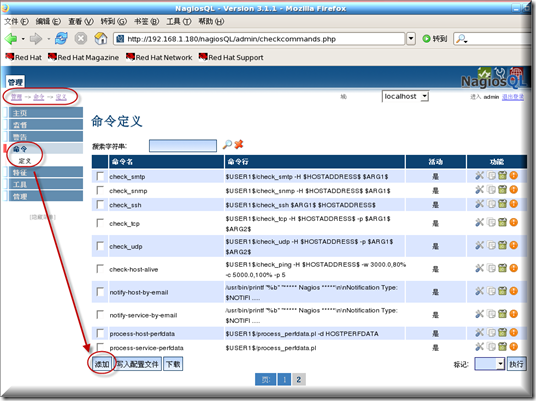
命令:check_nrpe
命令行:$USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$

现在开始添加需要监控的linux主机 监督-host-添加
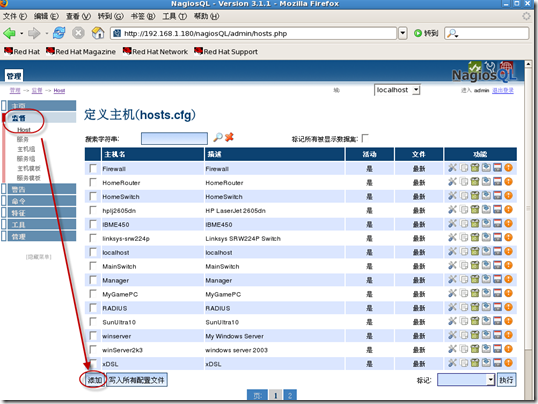
添加主机相关信息及模板
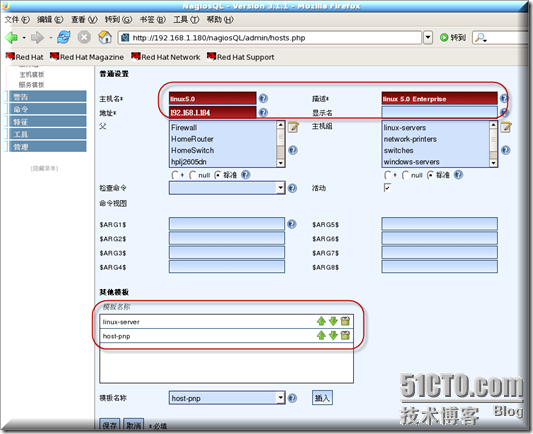
添加一个自定义服务 监督-服务-添加
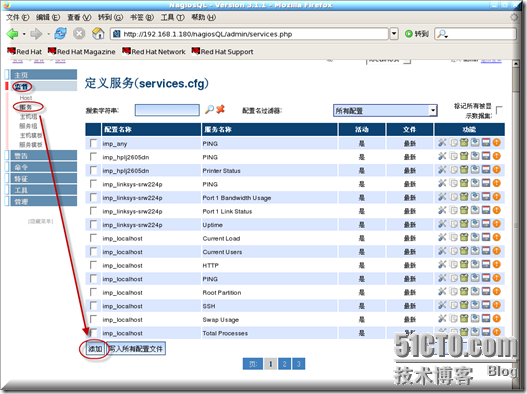
配置名称:check_swap
服务描述:Linux_swap
检查命令:check_nrpe
$ARG1$:check_swap
相当于在服务器端执行这样一条命令,所以可以在添加服务之前先在服务器端执行一下这样的一条命令,确认数据是否可以正常收集得到,想监控什么就想添加相应服务进去.

[cpu使用率服务:$ARG1$:check_load
在线用户服务:$ARG1$:check_users
进程数量服务:$ARG1$:check_total_procs
第一个分区使用情况服务:$ARG1$: check_sda1
注意:这些服务必须在被监控的linux客户端的nrpe.cfg文件中得到定义]
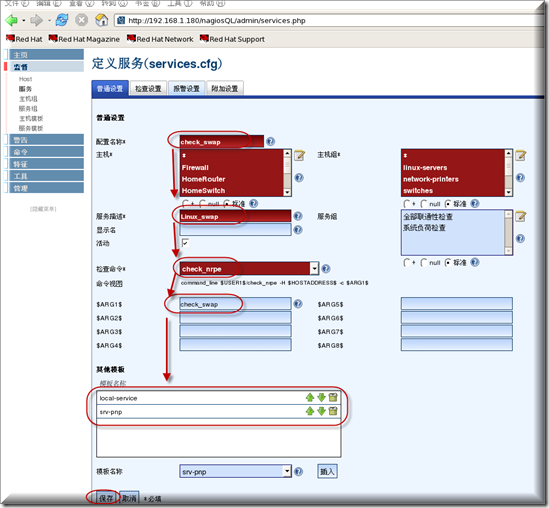
我们这里多加一个ping检查服务
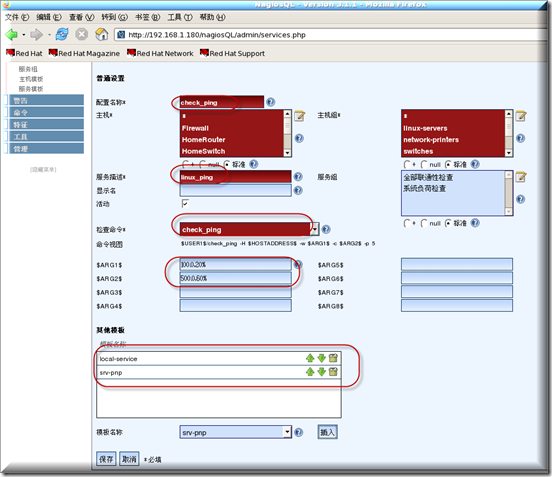
记住每多添加一个服务,请在被监控的linux客户端的nrpe.cfg文件中要定义此命令,在控制台设定的参数和定义命令的参数要一致,搞不明白请仔细看上图和下图对比应该知道怎么做.
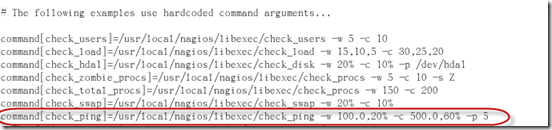
每多添加一条命令都需要重启nrpe服务,以使配置立即生效
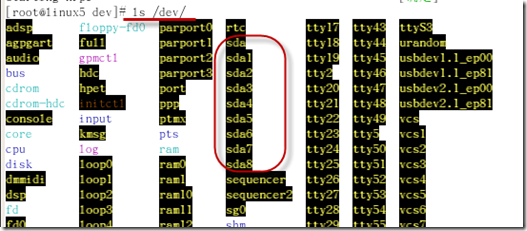
加入第一个分区使用情况,注意有些硬盘用的是hda,有些是sda,[hd(n)是IDE接口的, sd(n)是SCSI接口的]
如果你不确定你所使用的是哪种接口的硬盘,请用命令ls /dev/查看一看,看到我这里用的是SCSI接口的硬盘
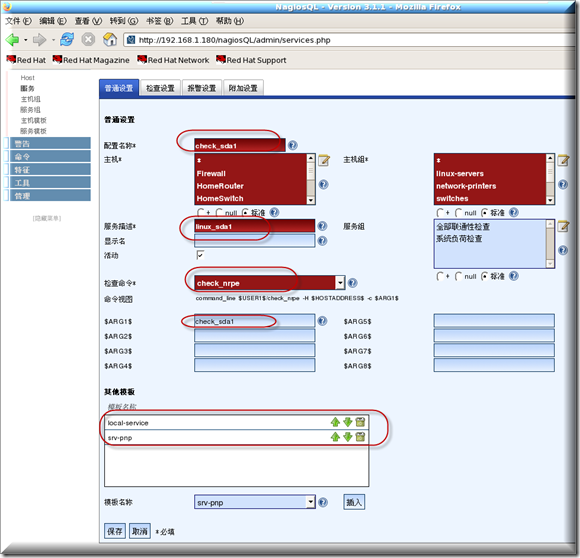
添加更多服务这里我就举以上几个例子,要靠自己多学习举一反三哈,
添加完成记得要点写入配置哈
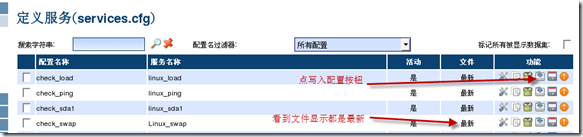
然后在主机端关联刚才自定义好的服务
写入配置文件
![]()
最后在工具-nagios控制 检查写入的配置文件全部执行一次
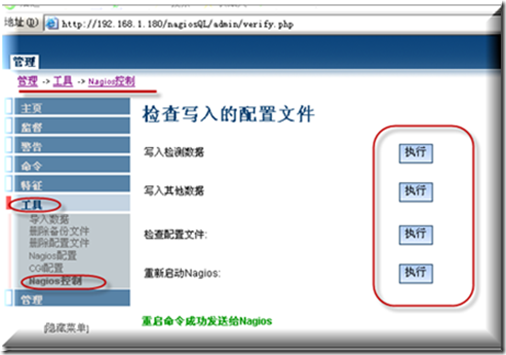
最后在nagios Web控制台可以看到如下表示成功了.

摘录一些参数信息供大家参考
如果丢包率到达20%则报warning,到达60%则报critical:
check_ping!100.0,20%!500.0,60%
如果可用空间低于20%会报Warning,如果可用空间低于10%则报Critical:
check_local_disk!20%!10%!/
监测远程主机当前的登录用户数量,如果大于20用户则报warning,如果大于50则报critical:
check_local_users!20!50
监测远程主机当前的进程总数,如果大于250进程则报warning,如果大于400进程则报critical:
check_local_procs!250!400!RSZDT
监测远程主机swap文件系统使用量,如果swap可用空间低于20%则报warning,低于10%则报critical:
check_local_swap!20!10
“-H 192.168.1.220”定义目标主机的地址,-w说明后面的一对值对应的是“WARNING”状态,“80%”是其临界值。“-c 500.0,100%” 其中“-c”说明后面的一对值对应的是" CRITICAL",“100%”是其临界值。“-p 1”说明每次探测发送一个包
check_ping -H 192.168.1.220 -w 300.0,80% -c 500.0,100% -p 1
检查http的80端口
check_http!80
用法: check_nt -H <hostname> -p <port> -v INSTANCES -l <counter object>
<counter object> 是一个windows性能对象计数 (eg. Process),
如果它是两个词,它应该引号括起来,返回的结果将是一个逗号分隔的对象
check_nt用法举例:
check_nt -H 192.168.1.2 -p 12489 -v CPULOAD -l 60,90,95 //显示最后60分钟waring为90%,critical为95%时的平均cpuload
check_nt -H 192.168.1.2 -p 12489 -v UPTIME //显示192.168.1.2从开机到现在运行时间
check_nt -H 192.168.1.2 -p 12489 -v USEDDISKSPACE -l c //显示192.168.1.2 C盘使用情况
check_nt -H 192.168.1.2 -p 12489 -v USEDDISKSPACE -l d -w 60 -c 95 //显示192.168.1.2 D盘设waring为90%,critical为95%时的空间使用信息
check_nt -H 192.168.1.2 -p 12489 -v MEMUSE //显示192.168.1.2内存使用情况
check_nt -H 192.168.1.2 -p 12489 -v SERVICESSTATE -d SHOWALL //显示192.168.1.2所有正在运行的服务
check_nt -H 192.168.1.2 -p 12489 -v SERVICESSTATE -d SHOWALL -l W3SVC //显示192.168.1.2上IIS网站服务运行情况
check_nt -H 192.168.1.2 -p 12489 �Cs 7758521 �Cv CLIENTVERSION //查看192.168.1.2上nsclient++版本
check_nt -H 192.168.1.2 -p 12489 �Cs 7758521 -v INSTANCES -l Process //列举192.168.1.2上运行的进程
监控路由器
这里我先用模拟的路由器来桥接到物理网络然后配置好ip地址和启用SNMP相关信息
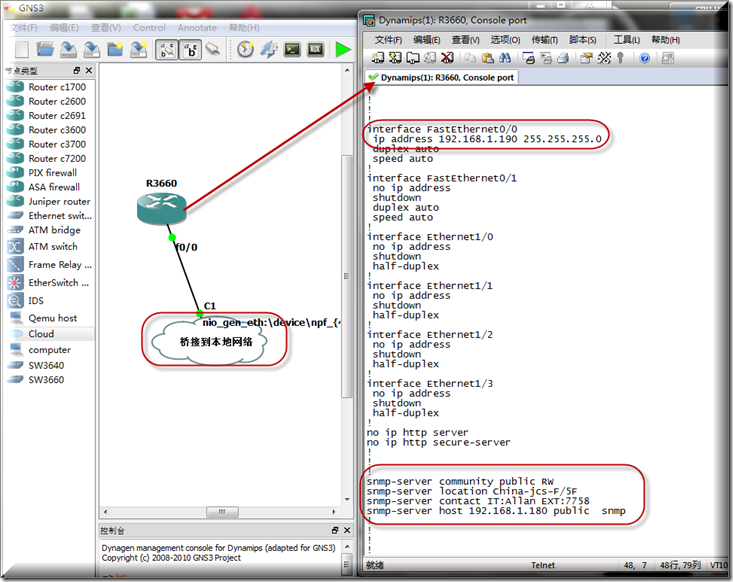
安装check_snmp plugin
在编译 nagios-plugins 时,如果系统支持net-snmp, 会自动编译 check_snmp 插件。(刚开始可能我们没有安装net-snmp,所以没有出现check_snmp这个插件)
1、安装net-snmp
yum -y install net-snmp-libs net-snmp-devel net-snmp net-snmp-utils
2、重新再编译安装插件 nagios-plugins-1.4.13
./configure
make && make install
3、检查SNMP的当前版本 ![]()
如果版本过低,可能不支持 snmp v2c
相应的OID可以通过厂商的MIB查询;也可以在一些专业网站查询 Online MIB Database;也可以通过snmpwalk 得到。
snmpwalk -v version -c community hostname
4、相应的命令可以通过snmpget 测试。
snmpget -c community -v 2c hostname iso.3.6.1.4.1.3224.16.3.2.0
在日常监控中,经常会用到snmp服务,而snmpwalk命令则是测试系统各种信息最有效的方法,现总结一些常用的方法如下:
snmpwalk -v 1 -c public 10.103.33.1 .1.3.6.1.2.1.25.2.2 取得系统总内存
snmpwalk -v 1 -c public 10.103.33.1 hrSystemNumUsers 取得系统用户数
snmpwalk -v 1 -c public 10.103.33.1 .1.3.6.1.2.1.4.20 取得IP信息
snmpwalk -v 1 -c public 10.103.33.1 system 查看系统信息
snmpwalk -v 1 -c public 10.103.33.1 ifDescr 获取网卡信息
以上只是一些常用的信息,snmpwalk功能很多,可以获取系统各种信息,只要更改后面的信息类型即可.如果不知道什么类型,也可以不指定,这样所有系统信息都获取到:
snmpwalk -v 1 -c public 10.103.33.1
现在我们测试一下连接到到模拟路由器上面去获取MIB信息,可以看到我们设置的SNMP相关信息在这里全部出现了,
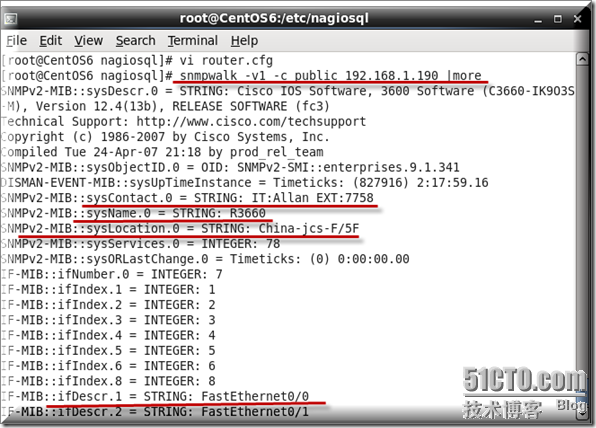
通过以上命令查看到的结果我们再来执行以下命令就应该知道如果想查看路由器上f0/0的信息那么在MIB信息库里面对就的查询名称就是ifDescr.1,

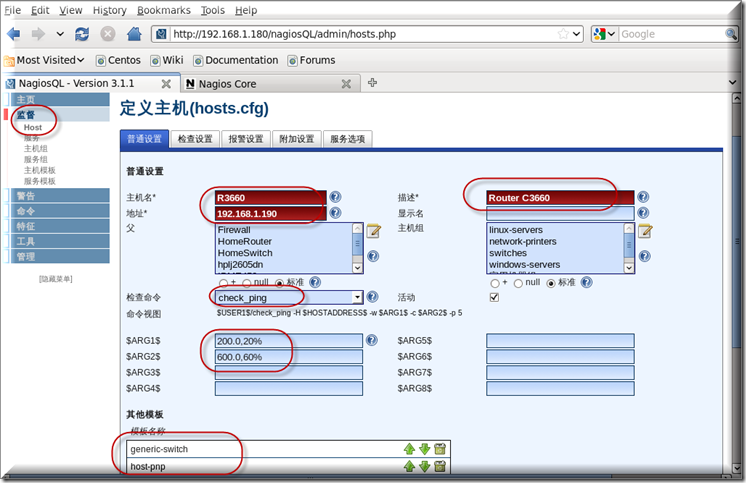
上面讲了这么多是为了下面的监控做铺垫,现在然正式开始添加需要监控的路由器
添加一主机如图所示,这里用先用PING命令检查路由器的连通性,相关参数设置代表什么意思上面说得清楚这里不再说明
可以根据自己的需要来自定义一个命令,命令-定义-添加
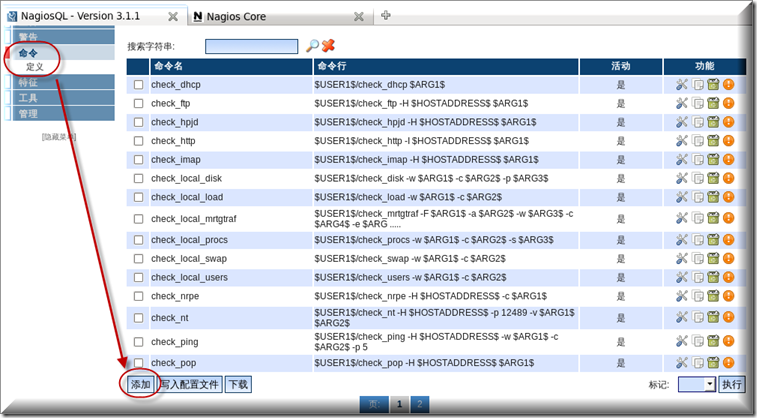
比如我现在想检查路由器启动了多长时间,其实我们要执行的命令是:check_snmp -H '$HOSTADDRESS -C '$ARG1 -o sysUpTime.0
先通过命令查看到sysuptime的OID的值为:sysUpTimeInstance
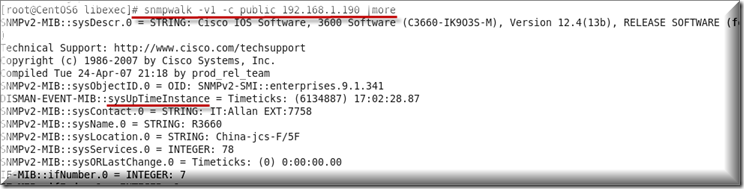
![]()
调出check_snmp参数用法详解,自己好好研究看一看

现在开始我们来自定义符合自己要求的命令来,到管理-命令-定义
由于这里只需要用到-H-C �Co 三个参数,注意这里要区分大小写,这里命令行里面就按如图所示进行添加,最后记得点保存即可
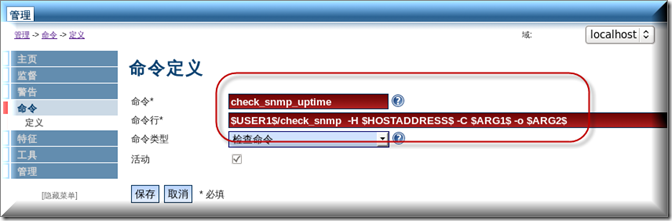
然后再到监督-服务-添加 在查检命令这里我们可以选择到我们刚才自定义好的命令
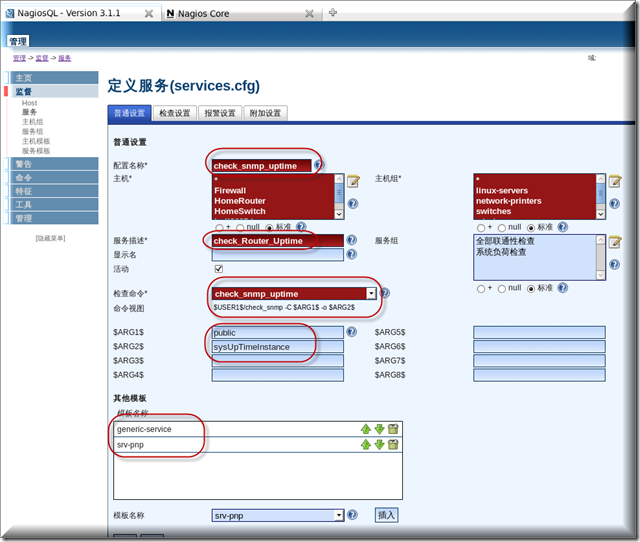
多添加一个服务检查路由器f0/0接口的状态
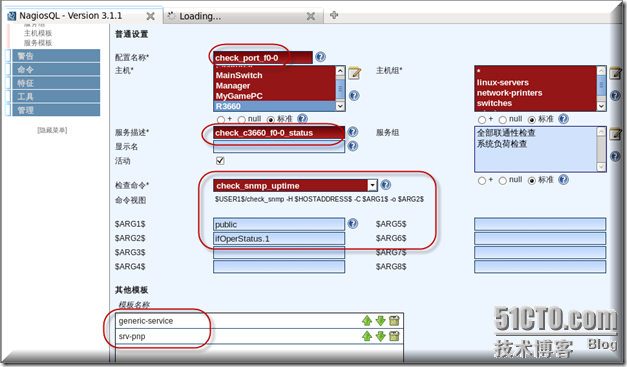
写入配置

然后再到主机里面关联刚才建好的服务
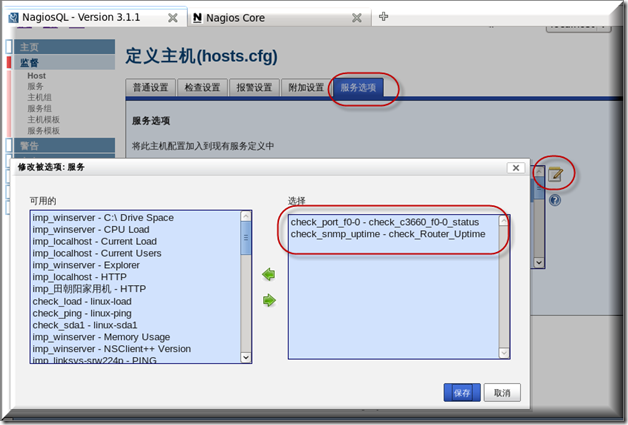
最后记得要从上到下执行一下这个动作,不然会出问题滴.
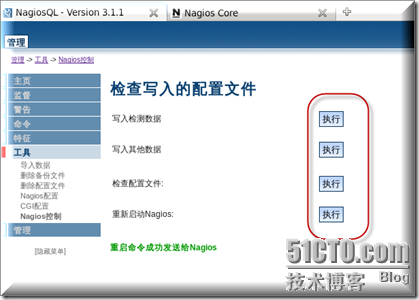
最后的战果如下图所示

邮件报警
邮件报警这里我们用最简单的方法就是调用系统自带的mailx来发警告邮件(也可自己搭建第三方的邮件服务器)
手机接收邮件的方法其实也很简单,发到163的邮箱也支持手机接收,还有移动的139邮箱都可以滴,到手机做简单的设定即可.

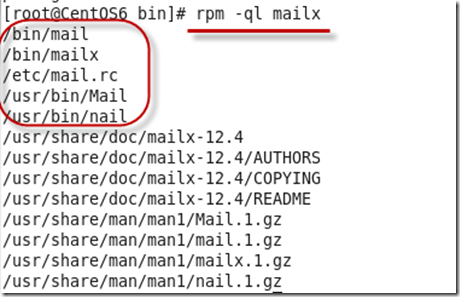
确认一下程序文件安装存入的路径
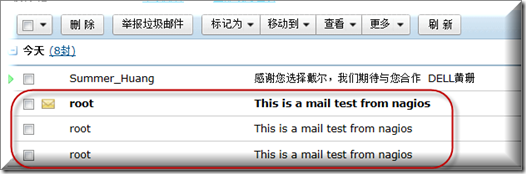
试着发一封邮件到自己的邮箱试试看,
![]()
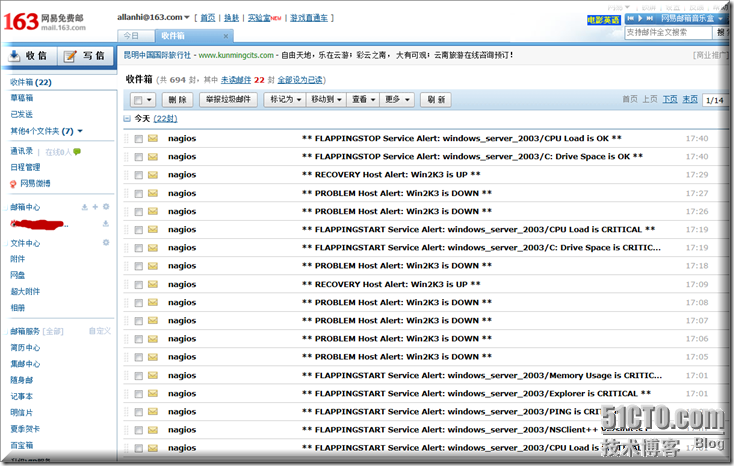
打开邮箱确认邮件是否能够成功收到
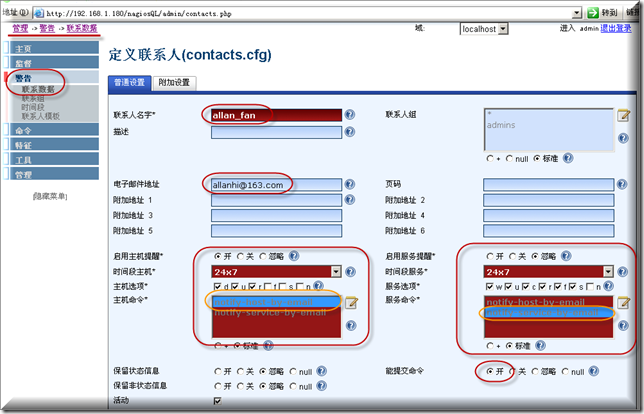
到警告-联系数据-添加
可以自定义一个联系组 警告-联系组-添加
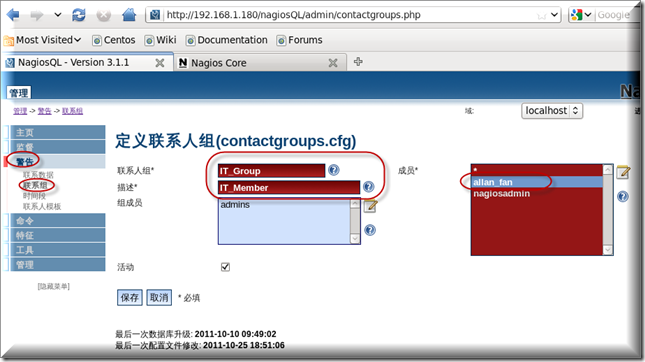
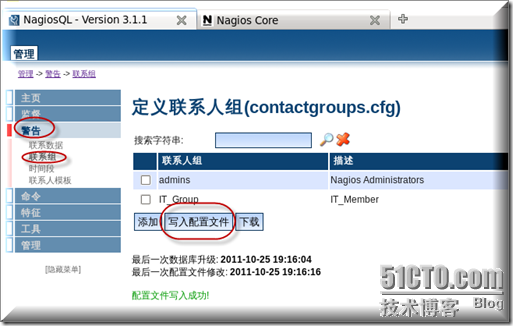
添加完成以后记得要点写入配置文件
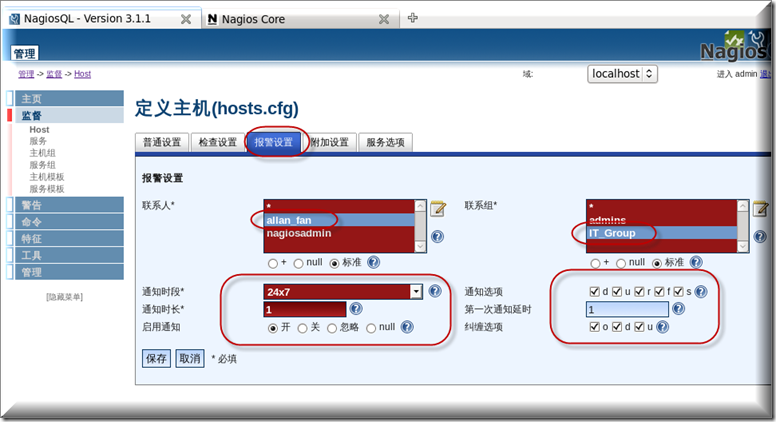
到需要启用报警的主机上面启用报警,监督-Host-需要启用报警的主机-报警设置,注意配置完成以后要记得点写入配置按钮哈.
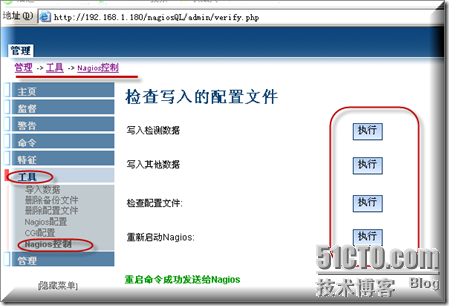
然后再从上到下全部点执行
由于主机检查刷新有一定的时间间隔,最先反应报警是ping服务
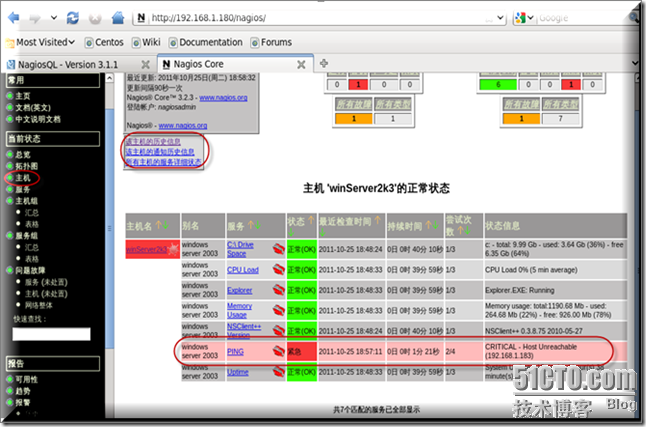
问题分享:过几十秒相关服务才全部相继开始告警,不注意这里有个尝试次数的设定,我测试发现一直要等到这个尝试次数结束以后才能报警,而这中间尝试的时间大约为10分钟,这里需要调整,要不然明明主机down要等半天才反应过来岂不没有什么意义了
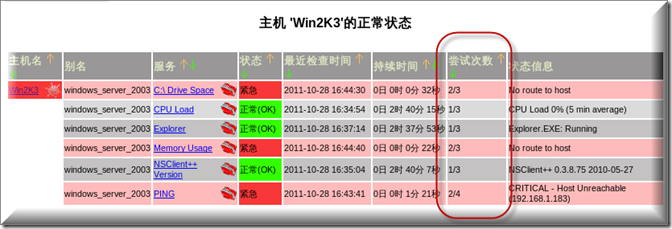
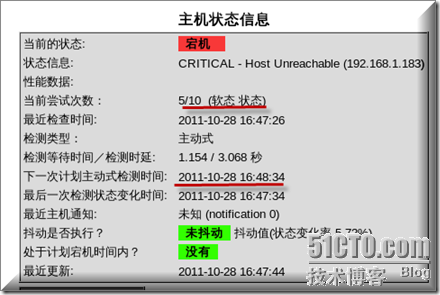
足足等了十分钟才终于收到报警邮件,晕

基本上3-5分钟之内就会发送一份邮件报警
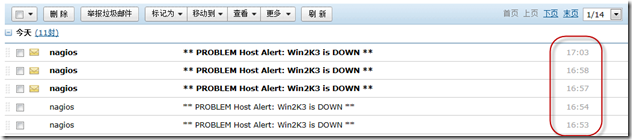
以上遇到两个问题需要解决,报警的延时拖得太长,邮件发送的次数太多,我们需要限制报警邮件的发送次数,要不然一直这样发下去邮箱都要塞爆了.
先解决报警的延时拖得太长的问题,这里我们其实只要修改服务的重试次数和检查间隔时长. 监督-服务-修改
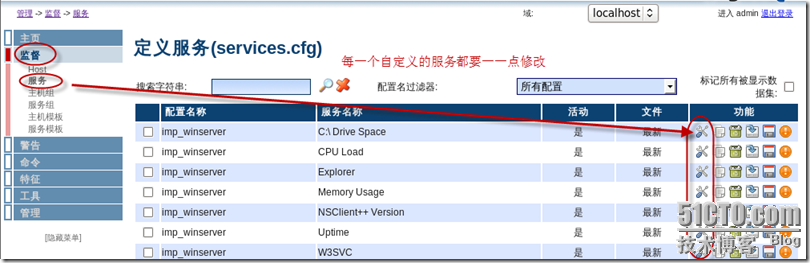
然后在每个检查设置选项按如下图所示设置,当服务是正常状态时每隔1分钟检查一次,当服务有问题时的时候也每隔1分钟重试一次,但最大只能重试2次

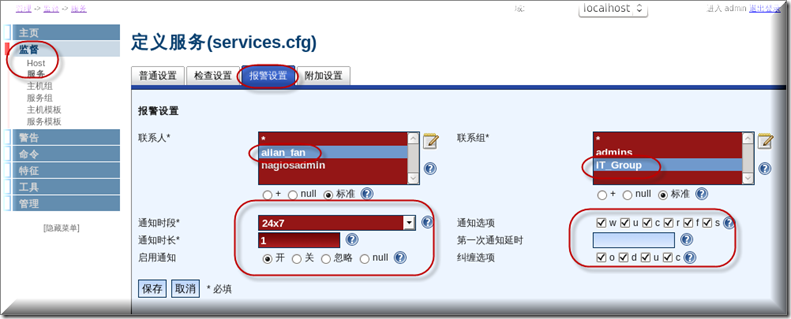
主机检查设置同样按如下图所示操作.
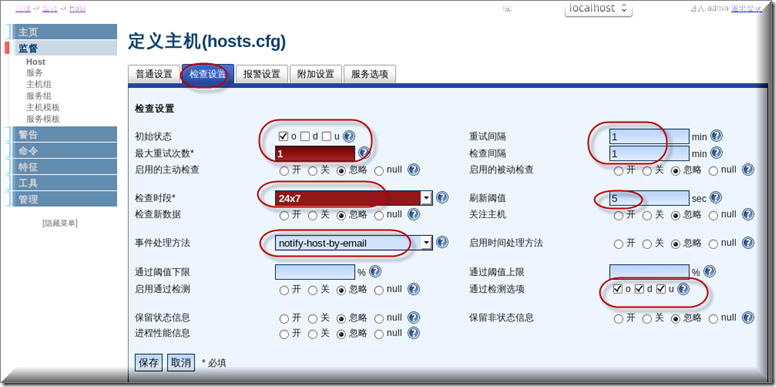
这里想说明一下,默认的ping服务检查调用是imp_any这个自定义命令,要修改ping的检查次数请到这里来改.改完后记得到nagios控制里面去点执行然后重启nagios服务一次
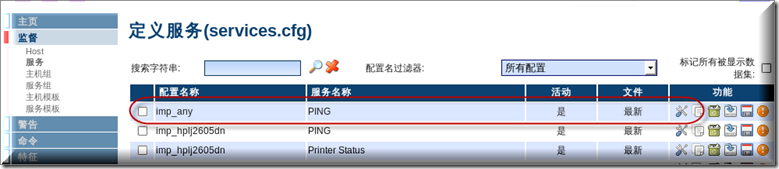
最后可以看到所有重试次数全部变成了2次,每分钟检查一下状态信息(频繁检查状态信息会对网络带宽有一定的影响,请大家根据自己的情况去定检查的间隔时间)
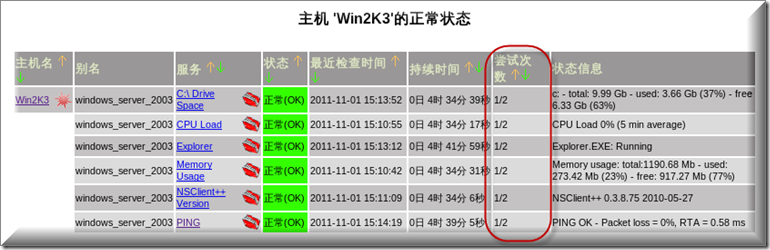
上图为证成功通过
下面开始解决邮件发送的次数太多的问题,如果服务器出现故障而未能及时的解决,Nagios就会不断的发送告警信息,实在令人头疼,Nagios于是用hostescalations和serviceescalations来控制报警间隔时间来完善它的报警功能.
通过查看nagios.cfg配置文件可以发现上次我们添加的时候,此配置文件已经写入在里面了

这里我们设定简单点不要搞得那么复杂,通知前3条信息我们按正常频率接由邮件,从第3条信息以后我们改变它有通知时间,这里我设为120分钟,当然你可以根据自己的情况去定,然后从第5条信息起再恢复它有通知频率间隔,就是这么简单.
![]()
添加如下内容:
define serviceescalation{
host_name Win2K3 ;被监控主机名称 ,要与hosts.cfg中的名称一致
service_description PING,Memory Usage,Explorer,CPU Load,C:\ Drive Space ;被监控服务名称多个用逗号隔开
first_notification 3 ;第3条信息起,改变频率间隔
last_notification 5 ;第5条信息起,恢复频率间隔
notification_interval 120 ;通知间隔(单位:分)
contact_groups IT_Group ;要通知的群组
} 
![]()
添加如下内容:
define hostescalation{
host_name Win2K3 ;被监控主机名称,要与hosts.cfg中名称一致
first_notification 3 ;第3条信息起,改变频率间隔
last_notification 5 ;第5条信息起,恢复频率间隔
notification_interval 120 ;通知间隔(单位:分)
contact_groups IT_Group ;要通知的群组
}

问题分享:这里要说明一点问题,习惯性每次配置完成以后都从上到下点执行一次,而这次却出了问题
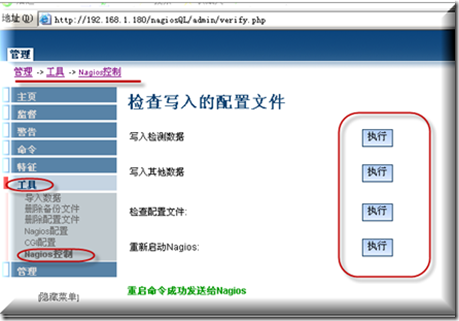
当执行写入其他数据的时候我们可以发现我们刚手动加入信息的两个文件在这里的配置再次被重写了,刚手动加入的信息全部都恢复成默认的了,难怪我在测试的时候发现明明设置了限制的时间却发现没有起效果,原来发现原因在这个地方(我估计需要通过这个控制台来修改这两个配置文件,但我没有找到哪个地方可以去修改)所以当你手动改了以后,请不要执行这一步就行了.

最后总结:我发现在测试的时候有些服务有告警有些没有,有时全没有,但主机告警每次都很及时,服务的报警设置是 一致的,应该没有问题,我怀疑是不是我的主机性能的问题,开几台虚拟机还加一些应用使用主机在应用上感觉就很慢,待以后有空再来验证,我也是初次研究这个 东东,写这篇可花了我不少时间,我也是摸着石头过河,有错误再所难免,发现问题欢迎大家指正.