MySQL服务器学习笔记!(一) ――数据库相关概念
这是一步步从头学习MySQL的笔记历程,本人在学习之前只接触过少量SQL Server。
第二天历程:压榨自己的学习能力极限,每天学习新内容之MySQL服务器!(二)
第三天历程:压榨自己的学习能力极限,每天学习新内容之MySQL服务器!(三)
接下来每天都将更新~相信你通过笔记,一定能从零学会MySQL~
废话不多说,开始今天的学习压榨~!
数据库的发展
今天学习Mysql,不过学习之前,一定是要掌握很多历史的基础的,只有掌握了这些,才能让我们以后对于整个领域的发展和规划起到一个更好的掌握作用~嗯~开始吧~
文本模型:早先的数据保存都是在文本文件中的,所以这就促使了文本文件的编辑器非常的流行。但是,文本检索的速度慢,效率底,当数据库文件变得庞大的时候,快速的检索数据就变成了一项困难的课题。所以出现了DB,DB是以给每一行做一个特定的标志的方式来工作的,这个标记叫key,查找一个值的时候只要先找到这个key值,就能快速的检索到真正的值叫(value)。DB是由伯克利大学开发的,它早期也叫sleepcat。但是随着数据量得加大,以及用户对于检索速度的需求,这就让很多的数据直接工作在了内存之中,当数据文件越来越大的时候,内存的容量就成了我们的瓶颈,而有些操作是完全需要载入内存,然后由内存工作之后,才将结果反馈,在这种越来越复杂的机制面前下,单纯的文本方式来保存数据已经俨然不够了,所以出现了层次模型。
层次模型:它将文本分成了像根→下级目录→下下级目录这样的形式。(层次模型中非常著名的是Sybase,它的信息管理系统非常的著名,现在有很多公司和企业都还在使用着)。信息管理系统中最重要的就是数据,而如果把信息管理系统比作身体的话,数据就相当于血液,而我们的心脏,其实就是数据库。而数据库对任何一家企业来讲,都是非常重要的。对于数据库还是有两个概念的,一个数据库管理软件,另一个是数据库的数据。像我们说的纯文本的数据记录来讲,能够实现数据记录的就是文本文件,而实现数据管理的就是那些检索命令,比如awk,grep,sed等…。层次模型的出现,在很大程度上缓解了数据检索速度的难题,但它毕竟只是按照倒置树的结构来执行的,这样的模型要想在多个节点之间建立一种联系则非常的困难。所以我们在层次模型之上又发展出的,网状模型。
网状模型:这种模型是以彼此间如何建立关联来决定的。它在层次模型的基础上对于不同的节点建立了更多的连接,使得不同节点之间的连接变得轻松简单。但是这两种模型都有一个极大的缺陷,他们需要跟软件的耦合程度非常的高,如果我们想修改一下数据模型中的关系和结构的话,则势必要完全修改对应这个数据模型的数据管理软件。大概在1970年左右,在IBM的一个叫Codd的研究员发表了一篇论文,主要论述的就是数据跟软件之间的关系,这之后另一种模型进入大家的视野,关系模型。
关系模型:其实就是一堆二维表,有行和列组成,在同一个数据库之间可以存在多张表,表与表之间还有相关的属性相关联。这样,表内之间有关系,表与表之间也有关系,这就是关系模型。而现在的关系模型又做了进一步的发展,有所谓的对象――关系模型:而Oracle就是一个对象――关系模型。而能够提供关系模型的,就叫关系型数据库模拟系统(RDBMS)。
DBMS:数据库管理系统(DataBase Management Systems)
RDBMS:关系型数据库管理系统
由于数据对企业特别重要,所以有一个能够管理数据的管理系统,一个良好的数据库管理系统,都会提供以下这许多功能:
a.管理数据存储:这是必须的……
b.安全管理:为数据库提供避免非法访问的机制,非常重要。
c.管理元数据:描述数据库属性的,本身跟数据无关。
d.事务管理:为了保证数据一致性的一个重要机制。现在的大多数数据管理系统都提供事物的功能
e.支持链接:主要指的是网络支持能力
f.性能优化:在性能方面提供一定的优化机制,这是现在最流行的关系型数据管理系统的最重要指标之一。在RDBMS中检索效率最高的,当属Oracle和mysql
g.提供备份和恢复的机制:对于数据库管理系统,都在这方面做足了功夫。比如Oracle在这方面做的尤其好。在这种构建于需要Web应用的,他们都需要Mysql,此时arical就不适用了,重要原因是Mysql是开源的,这就可以让企业去自己定制。
h.提供数据检索和修改的处理机制:这也是必须的……
什么是SQL
SQL:结构化查询语言,是上个世纪70年代由IBM公司发明的专门去检索,去查询数据的编程语言,这种编程语言类似于脚本语言。它是一大堆的命令,语句。只不过它执行的接口是SQL接口。它也提供了SQL的语句的解释器,比如select,update等命令,只不过这样的命令要比bash更加复杂一点。要想执行sql的语句,需要有SQL的模型才行。我们需要把用户所写的语句输送到服务器端。这就要服务器端能够接受客户端的命令,并将命令所返回的结果,送回客户端。这就是SQL的执行环境。而这些语句,则是实现检索修改,等相关的数据管理工作的
所以SQL其实就是一个管理语言,用于关系型管理系统的,实现管理,修改,数据等工作的,一个语言解释器。
最开始是IBM提供的SQL数据接口(SEQUEL),但是Oracle也有自己的SQL数据接口,这就造成了规则的不匹配。所以美国国家标准委员会,就定义了一个新标准:ANSI SQL标准 ,它的发展历程:
1.上个世纪80年代,1986年研发出来的, 叫SQL-86标准
2.89年再次扩展 SQL-89
3.1992年再次扩展,SQL-92 :这一代被应用了相当长的时间:各生产厂商RDBMS公司,要想实现上市,则必须严格的按照92的标准。但是这个标准定义的太严格,以至于几乎无厂商能够达成这种标准,所以兼容的标准也分成了三种级别:Entry级别,Intermediate级别,Full级别,几乎没有厂商能够达到Full级别,大部分都是Entry级别
4.1999年再次扩展,SQL-99:我们的Mysql是完全兼容SQL-99的Entry级别。而在此又出现了Core SQL级别。
5.2003年,又出现了SQL-2003标准。XML标准。
SQL的版本这就和bash一样,它是有版本的,每一个高版本都有新功能,而且它的执行速度,使用便捷,提供的扩展也不一样。
全球比较著名的RDBMS软件:
大型的: Oracle Sybase Informix DB2
中型的: SQL Server
开源的: MySQL PostgreSQL:
PostgreSQL:是由伯克利大学研发,跟Oracle同时代,但是由于一个决策失误,导致它淡出了人们的视野。而它的功能强于Mysql但是由于Mysql的轻量级简单化,导致PostgreSQL还没有什么大的市场,现在PostgreSQL已经被EnterpriseDB收购,而且Redhat已经决定全力支持EnterpriseDB
MySQL:
全球最流行的数据库
读法:/mai’S,Q,L/或者/ mai’si:kwel /
但是Mysql现在已经被Oracle收购,他的老总Michael Widenius发现软件以后可能收费,于是另起炉灶,制作了MariaDB这款数据库软件。MySQL的公司就叫MySQL AB(MYSQL有限责任公司)。以前的Michael Widenius他在另一个软件公司工作,发现他们工作的这个公司中的软件对于数据库缺少一个接口,于是他们就决定自己做一个接口出来……于是做接口的这几个人做出了MySQL,并成立了MySQL AB。
MySQL发展史:
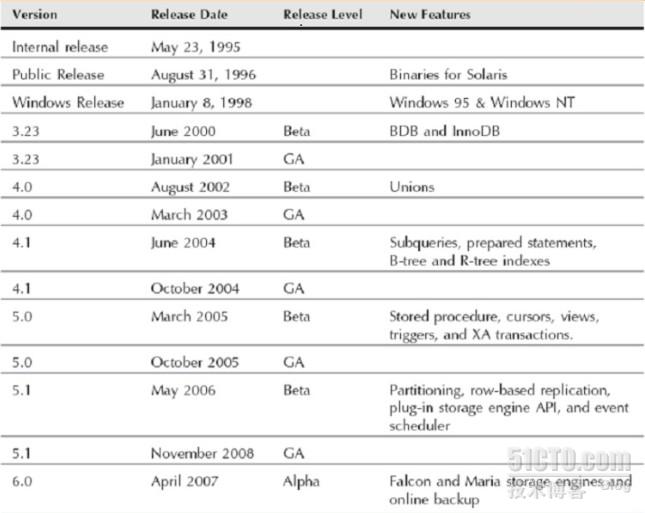
5.0的时候,才是MySQL的真正强大的开始。包括一系列比如游标器等功能,插件等功能……
5.1的时候,支持了,分区,数据库的切割(横向和纵向的切割)。复制,完全支持插件式引擎,时间调度器(周期计划)
5.5的时候:支持了,半同步复制插件(Google公司出产的)
Mysql发行版的不同之处:
MySQL Community :社区版:不提供服务,免费使用(搜狐镜像)
MySQL Enterprise:企业版:提供不同的服务级别,提供管理组件,比如“企业监控套件”这都是社区版所不具备的。
向MySQL提供帮助的方法:
1.写博客,向大家宣传MySQL
2.参与邮件讨论
3.进入官方论坛参与讨论
4.帮助官方写文档/翻译文档
5.帮助Mysql写代码
6.向MySQL的杂志免费投稿
MySQL的逻辑结构
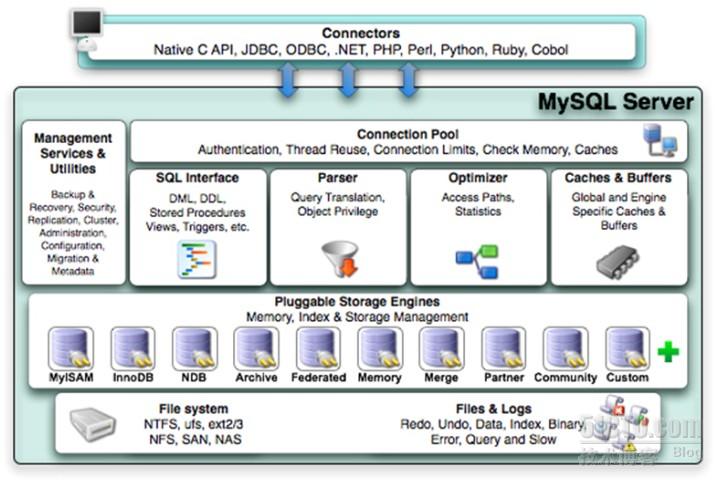
1.客户端:需要专门的客户端工具,可能是一个3层接口。比如“php-mysql”,作为用户来讲,我们要想使用bash的语句,需要有bash的接口,所以我们要是需要Mysql,则需要一个Mysql的接口。mysql,而客户端叫做mysqld.
2.连接器:比如JDBC(Java Datebase Conneter),比如ODBC,实现客户端和服务器端进行交互,来实现连接的。大多数都支持ODBC,因为它非常底层,比如.NET,PHP之类的。其中最通用的就是ODBC,Natice C API等。
3.连接/线程处理器(Connection Pool连接池):通过连接器连接到服务器上,服务器上的这个叫做服务器组件,这个组件叫做连接处理器。当有客户端连接到服务器上的这个组件的时候,则服务器端会给这个进程地址里面生成一个线程,客户端所有的工作都在这个线程内进行。
在连接池的后台,有SQL InterfaceSQL的接口,里面非常重要的两个内容:
DML:数据操作语言
DDL:数据定义语言
4.查询缓存(Caches & Buffers)/分析器(Parser):用户发起Mysql命令,连接器将命令发送到查询缓存中进行询问,如果缓存中没有,则进入分析器,分析器包括词法分析器和语法分析器,语法分析器主要用于识别用户提交的命令是否有语法问题,然后进行词法分析,词法分析将用户的命令进行切片,词法分析器分析命令的特定信息(比如命令内容,命令参数,命令选项,以及哪个表,哪个字段,字段是否存在,表中有什么内容)等等。
5.优化器:当进行完词法分析之后,则将内容放入优化器,优化器会对命令的执行路径进行优化,选择速度最快的那个执行路径,并生成对应的可执行的二进制格式并进行执行。
6.存储引擎:一个个存储在设备上的存储程序。不同的存储程序拥有不同的特性。插件式的存储引擎:数据库要产生大量的数据,而Mysql只是提供数据库的管理软件,它并不是数据库其实。其实数据库对应在物理概念上,其实就是存放在磁盘上的一个个文件。它到底该如何将这些文件,这些表对应到一个个的文件上呢?则需要存储引擎,而存储引擎其实就是将逻辑结构转换成数据结构的一个工具。对于Mysql来说他提供了非常灵活的方式,是一种接口式的管理。官方提供了很多不同的存储引擎,而且每一个的功能也不一样。在5.1的版本以后,Mysql的插件式的存储引擎功能才真正的体现了出来。
7.管理应用的组件:这可以直接给你的存储引擎打交道的一些工具,备份工具,恢复工具,集群,管理,配置工具,移植工具,元数据管理。这些工具其实都对应在一个个的命令上,这些命令是可以和数据甚至文件系统打交道的。
Mysql的安装
Mysql的版本:Alpha:内测版;Beta:公测版;RC:准备发行版;GA:使用版
安装Mysql的方式:1.编译的方式;2.二进制的方式:绿色的软件包;rpm直接安装包
MySQL的rpm包种类(√为常用的软件包)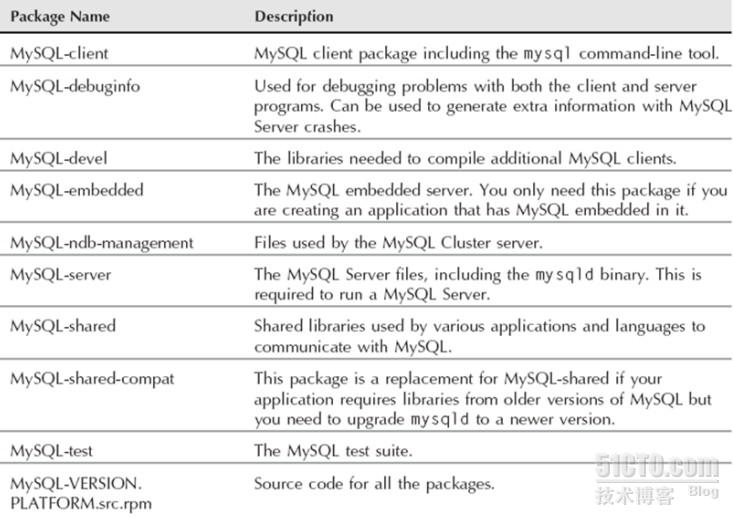
√client :客户端
debuginfo:可以产生额外的debug信息,用于排错
√devel :开发组文件,头文件定义,库文件定义,尤其是开发库,当你编译安装的时候,一般需要这个
embedded:嵌入式环境需要用的
ndb-management:官方为Mysql集群提供的管理工具
√server:服务器端包,主要提供Mysqld程序
√shared:共享库,可能被许多的客户端工具,或者服务器端得工具所用到
shared-compat:能够给mysql-shared提供向前兼容的,提供老版本库的
test:mysql的测试组件,比如测试mysql的响应能力,做性能侦测的。
VERSION PLATFORM.src.rpm
如果是解压安装的:则里面的目录是干什么的?

bin:命令文件目录
data:默认情况下数据的索引文件的存放位置,这个事可以改的
include:头文件
lib:库文件
man:说明文件
mysql-test:测试Mysql的文件
scripts:脚本文件
share:某种错误信息所对应的提示文件
sql-bench:性能测试的文件
support-files:提供额外的系统文件,和脚本
安装完之后的初始化过程
主要的初始化功能,是通过一个集中式的配置文件来实现的。
/etc/my.cnf
在Mysql启动的时候,去哪找配置文件:(LINUX版)
1./etc/my.cnf
2./etc/mysql/my.cnf
3.$MYSQL_HOME/my.cnf
4./path/to/file when defaults-extra-file=/path/to/file is specified
5.~/.my.cnf
它是一个个找的,当找到第一个之后,还是要找第二个,当多个配置文件定义了相同段落的不同内容的时候(内容冲突的情况下),以最后定义的那个文件为准。如果每一个文件都定义了不同的内容,则将读取所有配置文件的所有内容,来当做配置文件的主题。
关于4.我们在安装的时候也可以定义一个其他的目录,来定义。
关于5.可以在用户的家目录下,作为用户特有的Mysql配置为准。
MYSQL_HOME这个变量,主要是用于定义MYSQL的工作目录,一般是安装目录,如果没有设定的话,它会自动设定为basedir,将数据目录设为自己的目录。所以我们的配置文件完全可以放在数据目录中。
去哪找配置文件(Windows版)
1.%WINDIR%\my.ini, %WINDIR%\my.cnf
2.C:\my.ini, C:\my.cnf
3.%INSTALLDIR%\my.ini, %INSTALLDIR%\my.cnf
4./path/tofile when defaults-extra-file=/path/to/file is specified
安装完成之后:
Mysql会自动给我们生成5个用户
其中3个是管理员账号
[email protected] root@localhost root@hostname
以及两个匿名账号,密码为空
‘’@localhost ‘’@hostname
对于mysql来讲,它的账号不光包括用户名,还要包含主机。user@localhost
,对于Mysql来讲,使用主机名和使用地址表示两个不同的账号。
安装好之后要做的两件事:
1.为所有空密码的管理员账号设置密码
2.删除匿名账号
如何给管理员设置密码的三种方式:
1.在bash环境下设置使用mysqladmin(这里的参数后可以直接不加空格)
mysqladmin -u root password ‘newpassword’
mysqladmin -uroot -hlocalhost password ’redhat’
2.SET PASSWORD
3.修改表中的数据来实现。
UPDATE mysql user SET Password=PASSWORD(‘redhat’) WHERE User=’root’ and Host=’127.0.0.1’
把用户名为root,主机名为127.0.0.1的表为mysql的使用加密存储的方式设置password的密码为redhat。
刚刚修改的内容可能还没有被读进内存,这时候就要执行FLUSH PRIVILEGES命令,强制其读入内存一次。
对于匿名用户来讲:
DROP USER ‘’@localhost;
DROP USER ‘’@localhost.localdomain;
DROP USER root@’::1’;
FLUSH PRIVILEGES;
如何访问MySQL
(Mysql的客户端工具,接入Mysql)
Mysql是C/S架构的,所以他有很多工具可以连入Mysql实现跟Mysql交互。一种是客户端交互工具,一种是客户端的非交互式工具,以及非客户端的交互工具,以及mysqldump,mysql的备份工具。mysql还可以开启额外的端口,来实现管理
比较常见的mysql工具:
1.mysql
以及windows上的Mysql mysql -uroot -h172.16.100.1 -p
新建一个用户:密码为redhat
GRANT ALL PRIVILEGES ON *.* TO root@’%’ IDENTIFIED BY ‘redhat’
FLUSH PRIVILEGES
2.mysqlimport
3.mysqladmin
4.mysqlshow
所有的工具中使用 -? -I --help都可以获得帮助
通用的选项:
--user = -u 表示,以哪个用户的身份访问
--password = -p 表示使用密码访问
--protocol : 表示使用的协议是什么
tcp:只要客户端和服务器端不在一台主机上必须使用的是tcp
socket:在进程间通信的方式,实现客户端和服务器端通信的机制
pipe/memory :基于windows的命名管道/内存的形式通信
--host = -h :指定连接到哪个服务器上去
--port :指定服务器上的端口
--socket :指定socket文件在哪
--shared-memory-base-name
特殊选项
-D db_name :
--database db_name :这两个都是可以直接指定连接到某个数据库上并将其设定为默认数据库的。
SELECT DATABASE();用于显示当前默认的数据库是什么
SELECT USER();用于显示当前默认用户是谁
--compress :数据传输的时候是否需要压缩
在mysql的配置文件中设置默认的属性
在自己家目录下vim .my.cnf
[client]
user=root
password=redhat
一定注意这个文件的权限。
如何使用客户端工具
客户端的两种使用模式:
一种叫交互式模式:直接在Mysql中输入命令
一种叫批处理模式:把那些在客户端中需要执行的指令写成一个mysql的脚本,然后一次性的送入mysql,让其直接执行
批处理模式1: 写入文件内:比如: vim test.sql 写入:
CREATE DATABASE mydb;
CREATE DATABASE testdb;
执行:
mysql -uroot -p < test.sql 使用输入重定向,直接将脚本文件中的内容写入Mysql.
批处理模式2:
在mysql命令行中使用:SOURCE /root/test.sql ,则也能直接执行一个文件中的内容。
交互式的:
每一个SQL语句需要一个结束符,明确的告诉Mysql到底这个语句什么时候执行完了,默认情况下这个结束符是分号“;”这就明确的告诉了服务器端,一般来讲只要不加分号就能执行的语句,一般都是在客户端执行的,所以对于mysql来讲命令有两类,一种是客户端命令,一种是服务器端命令,服务器端命令必须要有分号,而客户端命令可以不加分号。
比如 STATUS 这个可以不加分号,这显示了连接的信息。里面只有一条信息的获取需要送到服务器端,所以这个可以不加分号。
mysql的提示符
mysql> :标准命令行,准备接受命令
-> :表示续行服
‘> :表示单引号缺一部分
“> :双引号缺一部分
`> :反引号缺一部分
/*> :注释信息缺一部分
Mysql的其他的有用的特征:\h 可以获得帮助信息
\q 或者 exit : 退出客户端工具
\c 取消一个已经写好的命令
\d 更换行结束符,默认情况下是“;”要想使用其他的。比如
\d // 则定义使用了双斜杠作为结束符
\g 无论是什么结束符,则表示都送到服务器端执行。忽略默认的结束符直接送去执行。
\G 以列的方式来显示行(竖排显示)
启动时候加上 -E 或者 --vertical 默认就使用竖排显示
在内存当中保留命令历史,在用户的家目录下保存命令历史至一个文件中.mysql_history。
\# 或者 rehash 命令
在非windows的主机上,mysql支持基于TAB键的命令补全功能,不过要想使用补全的功能,需要在开机的时候,默认打开命令补全,但是有些安装版本在设置中给你禁用了。当你的数据库内容比较多的时候,你会发现当你进入mysql的时候会很慢才进入,这就是在读取数据库的元数据信息,生成这种命令补全机制的文件的。
mysql还支持命令行编辑的功能:
Ctrl+e/a/w/u/y : 使用的方式和linux中的命令行支持方式几乎是一样的
Mysql的客户端命令和SQL语句:
HELP keyword :查看一个命令的语法结构和使用方法
比如HELP SELECT
-e 选项,可以让你我们不用登陆到服务器端,而直接在客户端就将命令交由mysql处理并返回。
比如:mysql -e “SHOW DATABASES”
所有在mysql里支持的特性,在这里都支持。
mysql -e “SELECT User,Host,Password FROM mysql.user;”
跟数据库管理相关的工作:mysqladmin
命令的使用格式:
mysqladmin [option] command [arg] [command]
ping:查看当期的服务器是否正常
create db_name:用于创建数据库
drop :用于删除数据库(这个过程是不可逆的,删之前一定要小心)
debug:将mysql执行过程中产生的错误信息发送至错误信息文件,错误信息日志一般保存在 SHOW VARIABLES LIKE ‘%datadir’;来显示数据文件的目录的。而我们的debug文件就保存在这里。
extended-status:扩展的状态信息,可以显示mysql的所有的状态变量中所记录的状态变量信息。比如有多少用户进来,查询过多少次,建立过多少表,删除过多少表,指定查询缓存是有效的(Qcache_hits),当然这些信息也可以使用SHOW STATUS;在Mysql中查看。
flush-hosts:清空一个主机所记录的所有状态信息。
flush-logs:刷新日志的,手动实现日志文件的滚动操作。
flush-privileges:刷新权限方面的定义
flush-status:重置信息记录的大多数变量
flush-tables:用于关闭当前打开的所有Mysql的文件的句柄
password:定义密码
processlist:用于显示mysql当前执行的所有进程和线程,也可以使用(SHOW PROCESSLIST;)在mysql中查看,类似于Linux的ps命令。
reload:等同于flush-privileges
refresh: 等同于flush-hosts和flush-logs
start-slave:启动从服务器
status:显示全局状态的简要信息,以及长选项
--sleep:每多长时间刷新一次
--count:定义显示多少次后退出
variables:查看变量的
version:显示当前Mysql服务器的版本号(里面有一些详细信息)
Mysql的图形化客户端工具:
SQLyog:能够安装在windows上,并连接在linux上实现远程管理
MySQL Front:前端管理工具
phpMyAdmin:基于Web的管理工具
MySQL Query Browser 后面这三个是官方提供的工具。
MySQL Administrator
MySQL Workbench
Mysql开发相关的知识:
定义一个二维关系(表)的时候,除了定义这个字段的内容之外,还要定义这个字段的类型。对于关系型数据库来讲,每一个字段都必须定义数据类型。这个数据类型决定了:
1.这个字段中可以存储的所有字段的种类。
2.可以使用多大的存储空间
3.决定这个数值到底是一个固定长度(大家都是20个字符)还是可变长度(根据名字长短来定义字符长度)。
4.决定对应的数值类型的排序机制和比较方法(有的区分大小写,有的不区分大小写)
5.我们的类型是否可以被索引,也是又数据类型决定的。
SQL语句的两大类:
DML:比如像update,delete,操作数据本身的
DDL:比如像CREATE DROP,等操作数据对象的
CREATE DATABASE创建数据库
CREATE INDEX 创建索引
CREATE TABLE 创建表
表的创建:
CREATE TABLE 表名 (定义字段:列名/列定义(数据类型/数据修饰符))
如果这个table没有什么特殊意义的话,尽量做到见名知意
比如:
CREATE TABLE stus (
-> Name CHAR(18),
-> Gender CHAR(1));
使用DESC stus;查看我们的刚定义的表。
常见的数据类型
1.Character String Types字符串型
CHAR: 固定长度
VARCHAR: 浮动长度
BINARY: 按照二进制的格式存储(严格区分大小写)
VARBINARY: 可变程度的二进制格式存储
TINYBLOB: 极小的二进制大对象(binary large boject)
BLOB: 小的的二进制大对象
MEDIUMBLOB: 中等的二进制大对象
LONGBLOB: 超大的二进制大对象
TINYTEXT: 极小的整篇字符
TEXT: 存储类似于论坛发帖的那样的对象的
MEDIUMTEXT: 中等的整篇字符
LONGTEXT: 超大的整篇字符
ENUM: 内置的两种特殊类型,枚举类型(选男女)
SET: 也是枚举,不过比较方法不同
2.Binary Large Object String Type二进制型
3.Numeric Types数值型
精确数值型:整型,表示精确值(无符号类型的范围)
TINYINT (255)
SMALLINT (65535)
MEDIUNINT (16777215)
INT (4294967295)
BIGINT (18446744073709551615)
浮点型:单精度浮点型和双精度浮点型(非精确值)
FLOAT 4字节
DOUBLE 8字节
REAL
Bit型:
4.Boolean Types波尔型 TINYINT(1)
BOOLEAN
BOOL
5.Datetime Types日期时间型
DATE:日期(3字节) ‘1000-01-01’-‘9999-12-31’
TIME(p):时间
DATETIME:日期+时间(3字节) ‘1000-01-01 00:00:01’-‘9999-12-31 23:59:59’
TIMESTAMP(p):时间戳(4字节)(做相对计时的,从XX年XX月XX日到现在的经过的秒数) ‘1970-01-01 00:00:00’- ‘2038-01-18 22:14:07’
YEAR:年份,
YEAR4 (1901-2155)
YEAR2 (00-99),表示2011年还是11年
6.Interval Types:
枚举型,
ENUM 1-65535
集合型
SET 1-64
分类的简单介绍:
1.字符串类型:(具体定义成什么,要视内容的变化而定)
固定长度的定义方式:(最多255字符)
CHARACTER(length)
CHAR(length)
可变长度的定义方式:(定义大小一般为大小+1)(最多65535)
CHARAVTER VARYING(length)
CHAR VARYING(length)
VARCHAR(length)
字符串类型的修饰类型:
NOT NULL :非空
NULL:允许为空
DEFAULT:给一个默认值,默认值应该加引号,在mysql里所有的默认值都必须加引号
BINARY:
CHARACTER SET:字符集,使用哪一种格式的字符集。
COLLATION:定义某种特定字符集的排序方式。
SHOW CHARACTER SET:用于显示我们系统支持的所有字符集的类型。
SHOW COLLATION:查看所有的排序方式,排序方式是肯定多于字符集的,因为每一种字符集都有多种排序方式。
BLOB:二进制大对象的特点:
按照字母表的严格区分大小写的方式进行排序的。BLOB在定义的时候,而这些大对象的存储一般都不会在表中存储,而是在表之外的特定地方
数值型:
精确数值型:整形,BIT等
浮点型:FLOAT REAL DOUBLE
整形的修饰符:
AUTO_INCREMENT :自动增长,一个字段用于表述行的ID号的。大部分情况下,它是无符号类型的。凡是定义成这个的,必须定义成主键或者唯一键。类型不能为空
UNSIGNED:无符号
FLOAT的修饰符
对于FLOAT我们可以定义整体位宽:(p),以及精度:(g,f)
char和int括号里的内容是不一样的,char后的括号表示限定多少长度,而int的括号表示到时候显示的时候显示多少位
日期时间:
日期时间的修饰符:
NOTNULL
NULL
Default
使用 SELECT CURRENT_DATE();
SELECT CURRENT_TIME();可以查看当前系统的日期和时间
枚举型:
比如创建一个枚举型的用户表,前面有自动生成的ID号,然后对应非空的姓名,性别枚举只有男女,默认男,含年龄的表
CREATE TABLE users (
-> ID INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
-> Name VARCHAR(100) NOT NULL,
-> Gender ENUM(‘M’,’F’) NOT NULL DEFAULT ‘M’,
-> Age TINYINT UNSIGNED
-> );
插入数据
INSERT INTO users (Name,Age) values (‘Jerry’,18);
当我们插入一个非法的数据的时候,能否插入数据,则根据Mysql的工作模式来定义了。
Mysql的工作模式:
决定了我们的sql在书写语法的时候到底有多高的规范要求。当存储数据在违反规则的时候,是否能够允许插入禁区
SHOW VARIABLES LIKE ‘%sql_mode%’;查看工作模式
SET sql_mode=’ansi’将我们的SQL模型定义为ansi。
常用的模式有哪些呢?
ANSI [QUOTES]:定义字符串只能使用单引号,双引号和反引号引用表的名字等……(在传统模型下,引号什么的是不分的)
IGNORE_SPACE:忽略内建函数的空白字符
STRICT_ALL_TABLES:所有的非法数据都不允许插入
STRICT_TRANS_TABLES:
TRADITIONAL:默认格式
Mysql变量类型:
全局变量:对每一个新建立的会话(用户连接进来)都是生效的
会话变量:只对当前会话有效,而且登出之后就无效了。
查看变量:
SHOW VARIABLES 查看所有变量
SHOW GLOBAL VARIABLES:查看所有的全局变量
SHOW SESSION VARIABLES:查看所有的会话变量
模式匹配:
LIKE ‘%sql_mode%’比如:
SHOW GLOBAL VARIABLES LIKE ‘time%’:time开头的
SHOW GLOBAL VARIABLES LIKE ‘%time%’:包含time的
SHOW GLOBAL VARIABLES LIKE ‘%time’:time结尾的
设置变量:
SELECT @@global.sql_mode : 设置全局变量
SELECT @@session.sql_mode :设置会话变量
SET sql_mod = ‘XXX’设置的是会话变量
SET GLOBAL sql_mode = ‘XXX’ 设置全局变量
MySQL到底如何区分大小写:
1.对于关键字:
是不分大小写的,但是,如果你习惯小写就一定小写,习惯大写一定大写,但是默认应该都是大写的。对于后期的缓存识别非常重要。
2.对于数据库名,表明,视图的名字
关乎于你的操作系统,Linux上是完全区分大小写的,Windows是不分大小写的
3.存储过程和存储函数是不区分大小写的。
4.触发器区分大小写。
5.别名:区分大小写。
6.字符串:取决于你的数据类型。char是区分的,
跟数据库相关的命令:
mysql每一个数据库都考一个对应的目录来存储。每一个目录,都由表来对应数据文件。数据库其实就是由表组成的数据集。
1.创建数据库:
CREATE DATABASE XXX;
为了避免数据库重复,可以使用
CREATE DATABASE IF NOT EXISTS db_name; 则表示如果db_name不存在则创建
2.指定额外信息:
指定默认字符集,和排序法则
CREATE DATEBASE db_name CHARACTER SET char_set COLLATE collate;
3.查看一个数据库在创建的时候用什么命令来创建:
SHOW CREATE DATABASE db_name;
4.删除数据库:
DROP DATABASE db_name;
DROP DATABASE IF EXISTS db_name;如果数据库存在则删除,否则报告。
5.改变数据库属性:改变字符集合默认法则的
ALTER DATABASE db_name COLLATE collate
ALTER DATABASE db_name CHARACTER SET charset
表和索引:
索引的主要作用是加快查找的,但是也有弊病,就是当数据更新的时候,索引必须重建。所以对于数据库的修改,是会降低速度的。
键:key,constraints
候选键:类似于ID这样的,让某一个字段来唯一的代表/标示某一行的,这样的字段或者字段的组合就叫做候选键:能够唯一标示这个表中唯一行的某一个字段或者字段的组合。比如ID号什么的。
主键(primary key):从候选键中挑出一个,来代表这一行。主键一般会被默认定义成为mysql的索引。
唯一键(unique key):一个字段或者多个字段组成的数据必须是唯一的,他和主键候选键的区别,他们不允许为空,但是唯一键允许为空值。
外键(foreign key):用于在表和表之间建立关系的。而外键则是用于在两个表之间建立关系的。
为了不产生多余的冗余,比如800人同时选择了课程“马克思主义***思想***理论和三个代表”则这就很多人选择了很多相同的,这就产生了很多冗余。我们可以完全重新编辑一个表,将这个表定义成1=“XXXXX”则,我们就可以在之后的定义课程中直接定义为课程1。这就是外键的定义。
数据库的范式:数据库设计的时候数据冗余以及数据存储的约束/标准。一般分为1-5范式……常用的必须符合第三范式。
对于Mysql来讲,如果想支持外键,必须选择支持事务的存储引擎。
索引应该优先创建在那些经常在SELECT语句里那些经常出现在WHERE语句中的命令的。
查看mysql的当前系统所有的支持的存储引擎:
SHOW ENGINES;
显示为DEFAULT的为默认的数据引擎。
我们在创建数据库表的时候可以定义到底使用哪个数据引擎。在5.1以前的mysql中默认引擎都是MyISAM,但是当被oricla收购之后,则InnoDB变成了默认的数据引擎。
2011-8-31:18:40:更新下午所学习的内容。
今天的学习笔记学习总量,今天你在努力学习了么?每天1W字的笔记,加大自己的脑容量吧!一起学习~
未完待续................
明天还有更多的内容~每天学习新内容~让每天都变得充实起来~