新浪微博基于MySQL的分布式数据库实践
分享到
一键分享
QQ空间
新浪微博
百度云收藏
人人网
腾讯微博
百度相册
开心网
腾讯朋友
百度贴吧
豆瓣网
搜狐微博
百度新首页
QQ好友
和讯微博
更多...
百度分享
北京行情上海行情广东行情深圳行情东莞行情辽宁行情山东行情河南行情湖北行情湖南行情江苏行情陕西行情四川行情重庆行情云南行情浙江行情
通行证登录|退出
首页 | 产品报价 全国行情 产品排行榜 | 渠道商情 | 评测 iGeek | 文库 高端访谈 IT选型顾问 | 本友会 板友会 摄友会
消费数码| 笔记本 手机 平板电脑 超极本 数码相机 摄像机 投影机 家电 耳机 MP3|MP4 智能电视机
硬件设备| 显示器 显卡 一体电脑 台式机 CPU内存硬盘 主板 键鼠 音箱 机箱|电源 软件|下载
办公| 服务器 网络通信 信息化 CU社区 安防监控
存储| IT文库 技术开发 企业安全 打印扫描 虚拟化
IT168技术开发频道
IT168首页 > 技术开发 > 新浪微博基于MySQL的分布式数据库实践

新浪微博基于MySQL的分布式数据库实践
2011年04月15日10:33 it168网站原创 作者:kaduo 编辑:董建伟 我要评论(0)
标签: mysql , 数据库 , MYSQL开发
【IT168 资讯】提起微博,相信大家都是很了解的。但是有谁知道微博的数据库架构是怎样的呢?在今天举行的2011数据库技术大会上,新浪首席DBA杨海潮为我们详细解读了新浪微博的数据库架构――基于MySQL的分布式数据库实践。

▲新浪首席DBA杨海潮
在本次演讲中,杨海潮简述了分布式数据库设计中的sharding策略:replication和partitioning;MySQL如何和Cache系统更好的结合来实现高并发的读写服务,同时减少应用开发复杂度,以及如何应对Cache层失效带来的高并发读以及瞬时写入高峰问题;怎样使用WT和WR的实现思想来处理数据库的读/写扩展性。
Sharding的原则:杨海潮表示有以下几点:一开始就关注架构设计;Scale up--Scale out--Scale up;成本可控下硬件是首选;逐步解决拆分中成本问题。
Caching原则:采用一致性Hash部署;Cache按照冷热分层;所有热数据都放入Cache;双写来避免雪崩问题;队列方式持久化落入MySQL。杨海潮谈到,DB的延时越来越不可以接爱,进行了并发复制的开发,降低响应时间还是没有解决。
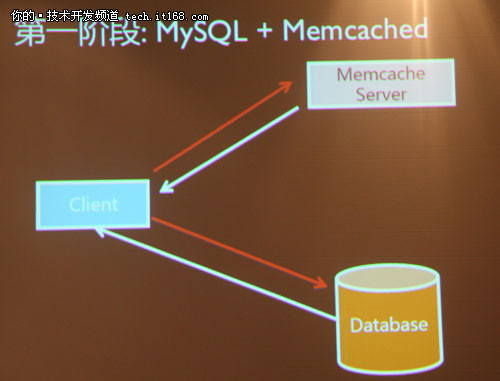
▲第一阶段:MySQL+Memcached
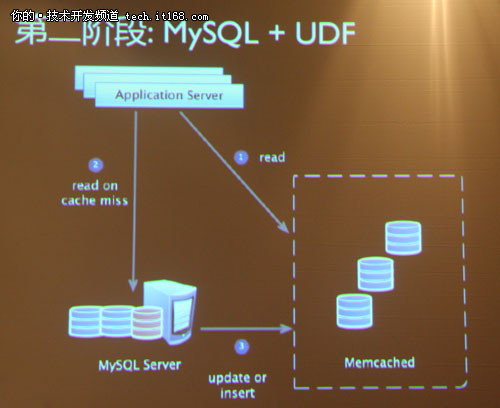
▲第二阶段:MySQL+UDF
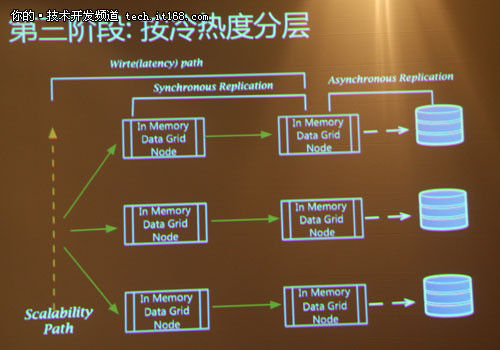
▲第三阶段:按冷热度分层
围脖,织围脖――这是什么?冬天到了,织条围脖保暖吗?错,这是网络流行用语。这还是大家的生活方式,生活态度。“找我?来我微博啊!”最近身边的朋友都在织啊织,你不织?你就是“奥特曼”。那么大家是否知道微博的开发模式吗?数据库是如何部署的?又是如何优化的?这些问题一出,必要找达人为我们解惑。51CTO有幸请到新浪首席DBA杨海潮先生来为我们解一解上述的疑惑。
专访人物介绍
杨海潮,新浪首席DBA,在大规模高并发,海量访问有丰富的管理经验。热衷于数据库设计,性能优化,分布式部署方案和高可用性方面的研究。
之前从事大访问量网站的部署以及优化工作,加入新浪后主要负责整个公司的数据库管理工作。
sharding 只用于数据量大同时有性能瓶颈的库,大部分库不进行sharding处理。对于数据量比较大的库,在一开始就考虑sharding策略,例如索引数据和内容数据分开设计,每类数据库根据业务逻辑选择恰当的partitioning key,拆分成一定数量的表。然后随着压力的增加进行垂直拆分,垂直拆分后的库再遇到性能瓶颈时首先考虑用硬件来解决。当硬件解决不了时才开始考虑水平拆分。在选择sharding方案时仔细考虑业务逻辑。对于读密集型应用,基本上通过增加slave来解决,对于写密集型应用才进行垂直和水平拆分工作。
51CTO:跨越越多的sharding,带来的开销就越大,这个数量是如何控制的?杨海潮:目前我在设计之前就避免跨表操作,选择适当的paritioning key,也即合适的拆分维度,避免对后期业务的影响。根据业务逻辑的重要程度,如果业务逻辑是查询某一个用户的信息,那么会按用户进行拆分,那么保证一个用户的数据是落在一张表里面。按时间维度进行拆分,那么会分析数据的冷热程度,把80%以上的数据放在一个表,避免过多的跨表查询。在这种拆分维度满足不了业务需求时,我们会利用空间换时间的思想,同一份数据按多种维度进行拆分,让每种业务逻辑的查询语句都有很高的效率。51CTO:很多用户都会把 sharding和partitioning混淆,您能讲讲您是怎么区分sharding与partitioning的异同。杨海潮:sharding通常是指垂直拆分和水平拆分,是一个总体的概念,mysql的partitioning是实现sharding的一种技术。
51CTO:新浪现在采用SQL+NoSQL结合的数据库部署,那么对于两种数据库,分别是如何进行优化的呢?杨海潮:目前NoSQL和MySQL是结合使用的,根据应用的特点选择合适存储方式。譬如:关系型数据,例如:索引使用MySQL存储,非关系数据库,例如:一些K/V需求的,对并发要求比较高的放入NoSQL产品存储,或者通过关系数据复制到NoSQL(redis)来显示不同的应用需求。针对MySQL做的优化比较多,从硬件(使用SSD,Fusion-IO,Cachecade等),文件系统(尝试XFS),调整IO调度,优化参数,调整索引到减少应用对数据库的访问和交换等。NoSQL(redis)通过修改源码满足自己的业务需求:完善它的replication机制,加入position的概念,让维护更容易,同时failover能力也大大增强。改善Hashset在rdb里面的存储方式,提升复杂数据类型的加载速度。
51CTO:如何保证数据库的安全性的呢?杨海潮:主要通过几个方面进行考虑:
只通过内网进行访问。
对来源IP做限制。
使用一定复杂度的密码策略。
从程序的角度对于输入进行检查,例如使用绑定变量防止SQL注入。
对一些敏感的信息会记录上操作日志,定期以报表的形式发给相关人员。
详细请参考:http://www.codesky.net/article/201105/166522.html