sed和awk的使用
一、sed工具
1. grep, sed, awk区别:
grep: 文本搜索工具;egrep, fgrep
sed: stream editor, 流编辑器;
awk(gawk):文本格式化工具,报告生成器
2.基本正则表达式元字符:
字符匹配:., [], [^]
次数匹配:*, \?, \+, \{m,n\}, \{n\}
位置锚定:^, $, \<, \>
分组及引用:\(\), \1, \2, ...
多选一:a|b|c
3.工作机制:每次读取一行文本至"模式空间(pattern space)"中,在模式空间中完成处理;将处理结果输出至标准输出设备;
4.语法:sed [OPTION]... {script} [input-file]...
5. 选项:
-r: 支持扩展正则表达式;
-n: 静默模式;
-e script1 -e script2 -e script3:指定多脚本运行;
-f /path/to/script_file:从指定的文件中读取脚本并运行;
-i: 直接修改源文件;
6. vim编辑中文本的查找替换:
地址定界s/要查找的内容/替换为的内容/
要查找的内容:可使用正则表达式
替换为的内容:不支持正则表达式,但支持引用前面正则表达式分组中的内容
地址定界:%, startline,endline
7.地址定界:
#: 指定行;
$: 最后一行;
/regexp/:任何能够被regexp所匹配到的行;
\%regexp%:同上,只不过换作%为regexp边界符;
\%regexp%| :匹配时忽略字符大小写;
startline,endline:
#,/regexp/:从#行开始,到第一次被/regexp/所匹配到的行结束,中间的所有行;
#,#
/regexp1/,/regexp2/:从第一次被/regexp1/匹配到的行开始,到第一次被/regexp2/匹配到的行结束,中间的所有行;
#,+n:从#行开始,一直到向下的n行;
first~step:指定起始行,以及步长;
1~2,2~2
8. sed的编辑命令
d: 删除模式空间中的行;
=:显示行号;
a \text:附加text
i \text:插入text,支持\n实现多行插入;
c \text:用text替换匹配到的行;
p: 打印模式空间中的行;
s/regexp/replacement/ g:替换由regexp所匹配到的内容为replacement; g: 全局替换;
w /path/to/somefile:把指定的内容另存至/path/to/somefile路径所指定的文件中;
r /path/from/somefile:在文件的指定位置插入另一个文件的所有内容,完成文件合并;
9.高级命令:
sed命令还有一个称作"hold space"的内存空间
h:用模式空间中的内容覆盖保持空间的内容;
H:把模式空间中的内容追加至保持空间中内容的后面;
g:从保持空间中取到其内容,并将其覆盖模式空间中的内容;
G:从保持空间中取到其内容,并将其追加在模式空间中的内容的后面;
x:把保持空间和模式空间中的进行交换;
n:读取匹配到的行的下一行至模式空间;(会覆盖模式空间中的原有内容);
N:读取匹配到的行的下一行至模式空间,追加在模式空间中原有内容的后面;
d:删除模式空间中的内容;
D:删除多行模式空间中的首行;
注意:命令功能可使用!取反;分号可用于分隔脚本;
示例:
sed 'G' /etc/issue: 在文件中的每行后方添加空白行; sed '$!d' /etc/fstab:保留最后一行; sed '/^$/d;G' /etc/issue: 保证指定的文件每一行后方有且只有一个空白行; sed 'n;d' /etc/issue:保留奇数行;
练习1:
(1) 删除/boot/grub/grub.conf文件中所有行的行首的空白字符;
sed 's/^[[:space:]]\+//' /boot/grub/grub.conf

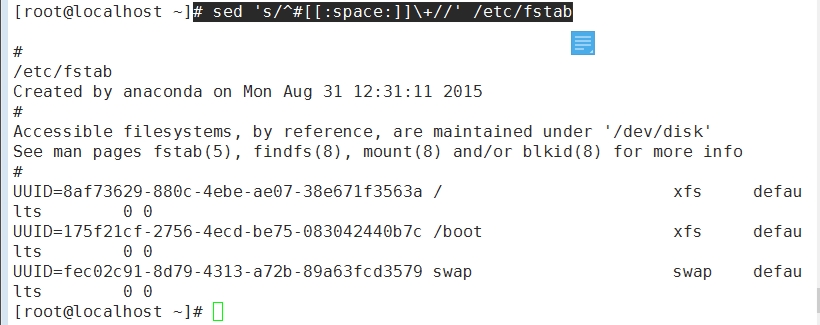
(2) 删除/etc/fstab文件中所有以#开头,后跟至少一个空白字符的行的行首的#和空白字符;
sed 's/^#[[:space:]]\+//' /etc/fstab
(3) 把/etc/fstab文件的奇数行另存为/tmp/fstab.3;
sed '1~2w /tmp/fstab.3' /etc/fstab

(4) echo一个文件路径给sed命令,取出其基名;进一步地,取出其路径名;
取基名:echo "/etc/sysconfig/network-scripts/" | sed 's@^.*/\([^/]\+\)/\?$@\1@'

取路径名:echo "/etc/sysconfig/network-scripts/" | sed 's@[^/]\+/\?$@@'

二、awk工具
1.awk: 报告生成器
AWK a.k.a Aho, Weinberger, Kernighan
Gnu AWK, gawk
2. 基本语法
awk [options] 'program' file file ...
awk [options] 'PATTERN{action}' file file ...
-F CHAR:输入分隔符
3. awk的输出
print item1, item2,...
要点:
(1) 各项目之间使用逗号分隔,而输出时则使用输出分隔符分隔;
(2) 输出的各item可以字符串或数值、当前记录的字段、变量或awk的表达式;数值会被隐式转换为字符串后输出;
(3) print后面item如果省略,相当于print $0;输出空白,使用pirnt "";
4.awk的变量
内置变量,自定义变量
4.1 内置变量
FS:Field Seperator, 输入时的字段分隔符
# awk 'BEGIN{FS=":"}{print $1,$7}' /etc/passwd
RS:Record Seperator, 输入行分隔符
OFS: Output Field Seperator, 输出时的字段分隔符;
ORS: Outpput Row Seperator, 输出时的行分隔符;
NF:Numbers of Field,字段数
NR:Numbers of Record, 行数;所有文件的一并计数;
FNR:行数;各文件分别计数;
ARGV:数组,保存命令本身这个字符,awk '{print $0}' 1.txt 2.txt,意味着ARGV[0]保存awk,
ARGC: 保存awk命令中参数的个数;
FILENAME: awk正在处理的当前文件的名称;
4.2可自定义变量
-v var_name=VALUE 变量名区分字符大小写;
(1) 可以program中定义变量;
(2) 可以命令行中通过-v选项自定义变量;
5.awk的printf命令
5.1命令的使用格式:printf format, item1, item2,...
5.2要点:
(1) 要指定format;
(2) 不会自动换行;如需换行则需要给出\n
(3) format用于为后面的每个item指定其输出格式;
5.3 format格式的指示符都%开头,后跟一个字符:
%c: 显示字符的ASCII码;
%d, %i: 十进制整数;
%e, %E: 科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法格式或浮点数格式显示数值;
%s: 显示字符串;
%u: 显示无符号整数;
%%: 显示%自身;
5.4修饰符:
#:显示宽度
-:左对齐
+:显示数值的符号
.#: 取值精度
6. awk输出重定向
print items > output-file
print items >> output-file
print items | command
6.1特殊文件描述符:
/dev/stdin: 标准输入
/dev/stdout: 标准输出
/dev/stderr: 错误输出
7.awk的操作符
7.1算术操作符:
x+y
x-y
x*y
x/y
x**y, x^y
x%y
-x:负值
+x:转换为数值
7.2 字符串操作符:连接
7.3赋值操作符:
=
+=
-=
*=
/=
%=
^=
**=
++
--
如果模式自身是=号,要写为/=/
7.3比较操作符:
<
<=
>
>=
==
!=
~:模式匹配,左边的字符串能够被右边的模式所匹配为真,否则为假;
!~:
7.4逻辑操作符:
&&:与
||:或
7.5条件表达式:
selector?if-true-expression:if-false-expression
7.6函数调用:
function_name(argu1,argu2)
8.模式
(1) Regexp: 格式为/PATTERN/ 仅处理被/PATTERN/匹配到的行;
(2) Expression: 表达式,其结果为非0或非空字符串时满足条件;仅处理满足条件的行;
(3) Ranges: 行范围,此前地址定界, NR仅处理范围内的行
(4) BEGIN/END: 特殊模式,仅在awk命令的program运行之前(BEGIN)或运行之后(END)执行一次;
(5) Empty:空模式,匹配任意行;
9.常用的action
(1) Expressions
(2) Control statements
(3) Compound statements
(4) input statements
(5) output statements
10.控制语句
10.1if-else
格式:if (condition) {thenbody} else {else body}
# awk -F: '{if ($3>=500) {print$1,"is a common user"} else {print $1, "is an admin or systemuser"}}' /etc/passwd
# awk '{if (NF>=8) {print}}'/etc/inittab
10.2while
格式:while(condition) {while body}
# awk '{i=1; while (i<=NF){printf"%s ",$i;i+=2};print ""}' /etc/inittab
# awk '{i=1; while (i<=NF){if(length($i)>=6) {print $i}; i++}}' /etc/inittab
length()函数:取字符串的长度
10.3do-while循环
格式:do {do-while body} while (condition)
10.4for循环
格式:for(variable assignment; condition; iteration process) {for body}
# awk '{for (i=1;i<=NF;i+=2){printf"%s ",$i};print ""}' /etc/inittab
# awk '{for (i=1;i<=NF;i++){if (length($i)>=6)print $i}}' /etc/inittab
for循环可用来遍历数组元素:语法:for (iin array) {for body}
10.5case语句
语法:switch (expression){case VALUE or /RGEEXP/: statement1;... default: stementN}
10.6循环控制
Break continue
10.7next
提前结束对本行的处理进而提前进入下一行的处理;
# awk -F: '{if($3%2==0) next;print $1,$3}'/etc/passwd
# awk -F: '{if(NR%2==0) next; print NR,$1}'/etc/passwd
10.数组
传统数组:Index编号从1开始;
10.1 array[index-expression]
index-expression: 可以使用任意字符串; 如果某数组元素事先不存在,那么在引用时,awk会自动创建此元素并将其初始化为空串;因此,要判断某数组是否存在某元素,必须使用“index in array”这种格式;
A[first]="hello awk" print A[second]
10.2要遍历数组中的每一个元素,需要使用如下特殊结构:
for (var in array) {for body}
其var会遍历array的索引;
state[LISTEN]++
state[ESTABLISHED]++
# netstat -tan | awk'/^tcp/{++state[$NF]}END{for (s in state) {print s,state[s]}}'
# awk '{ip[$1]++}END{for (i in ip) {printi,ip[i]}}' /var/log/httpd/access_log
10.3删除数组元素:
delete array[index]
11.awk的内置函数
11.1 split(string,array[,fieldsep[,seps]]):
功能:将string表示的字符串以fieldsep为分隔符进行切片,并切片后的结果保存至array为名的数组中;数组下标从1开始;
root:x:0:0::/root:/bin/bash user[1]="root", user[2]
此函数有返回值,返回值为切片后的元素的个数
# netstat -tn | awk'/^tcp/{lens=split($5,client,":");ip[client[1]]++}END{for (i in ip)print i,ip[i]}'
11.2 length(string)
功能:返回给定字串的长度
11.3 substr(string,start[,length])
功能:从string中取子串,从start为起始位置为取length长度的子串;
示例:把/etc/passwd按:切片
[root@localhost ~]# awk -F: '{print$1,$NF}' /etc/passwd
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync