python学习笔记-Day12-- memcached / redis / rabbitMQ / sqlalchemy
memcache
安装
wget http://www.memcached.org/files/memcached-1.4.25.tar.gz
tar xf memcached-1.4.25.tar.gz
cd memcached-1.4.25
./configure && make && make test && sudo make install && echo ok
注意:
memcache依赖libevent 安装前需要先安装 libevent
yum install -y libevent-devel
或者
sudo apt-get install libevent-dev
运行
memcached
-
d
-
m
10
-
c
256
参数说明:
-
d 是启动一个守护进程
-
m 是分配给Memcache使用的内存数量,单位是MB
-
u 是运行Memcache的用户
-
l 是监听的服务器IP地址,默认为本地
-
p 是设置Memcache监听的端口,最好是
1024
以上的端口,默认是11211
-
c 选项是最大运行的并发连接数,默认是
1024
,按照你服务器的负载量来设定
-
P 是设置保存Memcache的pid文件
python-memcached模块安装:
pip install python-memcached
连接 memcache
import memcache
mc = memcache.Client(['127.0.0.1:11211'], debug=True)
mc.set("foo", "bar") #设置一个值 ,若此时键foo已存在和替换
mc.set_multi({'k1': 'v1', 'k2': 'v2'}) #设置多个值,若此时键foo已存在和替换
print mc.get('foo') #获得一个值
print mc.get_multi(["k1","k2"]) #获取多个值
mc.add('k1', 'v1') # 此时k1 已存在,这里会报异常
mc.replace('k1','999') #替换k1的值为999
mc.append('k1', 'after') # 修改指定key的值,在该值 后面 追加内容
mc.prepend('k1', 'before') #修改指定key的值,在该值 前面 插入内容
mc.incr('k1') #自增,将Memcached中的某一个值增加 N ( N默认为1 )
mc.incr('k1', 10)
mc.decr('k1') #自减,将Memcached中的某一个值减少 N ( N默认为1 )
mc.decr('k1', 10)
mc.delete('k0') #删除一个key
mc.delete_multi(['k1', 'key2']) #删除多个key
print mc.replace("foo2","123")
# for i in dir(memcache.Client):print(i)特殊的gets 和 cas
gets和cas 用于解决数据冲突问题,即:
商城商品剩余个数,假设改值保存在memcache中,product_count = 900
A用户刷新页面从memcache中读取到product_count = 900
B用户刷新页面从memcache中读取到product_count = 900
如果A、B用户均购买商品
A用户修改商品剩余个数 product_count=899
B用户修改商品剩余个数 product_count=899
如此一来缓存内的数据便不在正确,两个用户购买商品后,商品剩余还是 899
如果使用python的set和get来操作以上过程,那么程序就会如上述所示情况!
如果想要避免此情况的发生,只要使用 gets 和 cas 即可
本质上每次执行gets时,会从memcache中获取一个自增的数字,通过cas去修改gets的值时,会携带之前获取的自增值和memcache中的 自增值进行比较,如果相等,则可以提交,如果不想等,那表示在gets和cas执行之间,又有其他人执行了gets(获取了缓冲的指定值), 如此一来有可能出现非正常数据,则不允许修改。
python-memcached 支持集群操作,原理是在内存中维护一个集群列表,集群中主机的权重和主机在列表中出现的次数成正比
即:
主机 权重
1.1
.
1.1
1
1.1
.
1.2
2
1.1
.
1.3
1
那么在内存中主机列表为:
host_list
=
[
"1.1.1.1"
,
"1.1.1.2"
,
"1.1.1.2"
,
"1.1.1.3"
, ]
如果用户根据如果要在内存中创建一个键值对(如:k1 = "v1"),那么要执行一下步骤:
1.根据算法将 k1 转换成一个数字
2.将数字和主机列表长度求余数,得到一个值 N( 0 <= N < 列表长度 )
3.在主机列表中根据 第2步得到的值为索引获取主机,例如:host_list[N]
4. 连接 将第3步中获取的主机,将 k1 = "v1" 放置在该服务器的内存中
代码实现如下:
mc = memcache.Client([('1.1.1.1:12000', 1), ('1.1.1.2:12000', 2), ('1.1.1.3:12000', 1)], debug=True)
mc.set('k1', 'v1')
#################################################################
redis
安装
wget http://download.redis.io/releases/redis-3.0.0.tar.gz
cd /usr/local/
mv redis-3.0.0/ redis
cd redis/
make
make install
cd utils
./install_server.sh
welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379]
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf]
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log]
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379] /opt/redis/6379
Please select the redis executable path [/usr/local/bin/redis-server]
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /opt/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!
启停
redis-server /etc/redis.conf #启动
redis-cli shutdown #停止
python的redis模块安装
sudo pip install redis
常用操作
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis
r= redis.Redis(host='127.0.0.1',port=6379)
r.set("k1","v1")
print r.get("k1")
2.redis模块的连接池
redis-模块使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数 Redis,这样就可以实现多个Redis实例共享一个连接池。
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
3 .redis模块的管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。和关系数据库中的事务类似.
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
r.set('name', 'alex')
r.set('role', 'sb')
pipe.execute()
4 发布和订阅
#!/usr/bin/env python # -*- coding:utf-8 -*- # filename : redisHelper.py import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='10.211.55.4') self.chan_sub = 'fm104.5' self.chan_pub = 'fm104.5' def public(self, msg): self.__conn.publish(self.chan_pub, msg) return True def subscribe(self): pub = self.__conn.pubsub() pub.subscribe(self.chan_sub) pub.parse_response() return pub
#!/usr/bin/env python # -*- coding:utf-8 -*- #filename : getInfo.py from monitor.RedisHelper import RedisHelper obj = RedisHelper() redis_sub = obj.subscribe() while True: msg= redis_sub.parse_response() print msg
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# filename : sendInfo.py
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
obj.public('hello')
####################################################
rabbitMQ
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、 JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等 方面表现不俗。
AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
安装
安装配置epel源
$ rpm
-
ivh http:
/
/
dl.fedoraproject.org
/
pub
/
epel
/
6
/
i386
/
epel
-
release
-
6
-
8.noarch
.rpm
安装erlang
$ yum
-
y install erlang
安装RabbitMQ
$ yum
-
y install rabbitmq
-
server
python通过pika模块来操作rabbitMQ
安装pika
sudo pip install pika
pika的使用
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
#!/usr/bin/env python
# filename : prod.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
#!/usr/bin/env python
#filename : cust.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
1、acknowledgment 消息不丢失
在消费者中 如果 no-ack = False,如果生产者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
2. durable 消息不丢失 (这里忘记咋回事了,回头在补一下)
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello', durable=True)
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent 'Hello World!'")
connection.close()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
3. 消息的获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
4、发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
5、关键字发送
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
6、模糊匹配
exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
# 表示可以匹配 0 个 或 多个 单词
* 表示只能匹配 一个 单词
发送者路由值 队列中
old.boy.python old.
*
-
-
不匹配
old.boy.python old.
# -- 匹配
#######################################################################
SQLAlchemy是Python编程语言下的一款ORM框架,提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
SQLAlchemy 的一个目标是提供能兼容众多数据库(如 SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird)的企业级持久性模型。
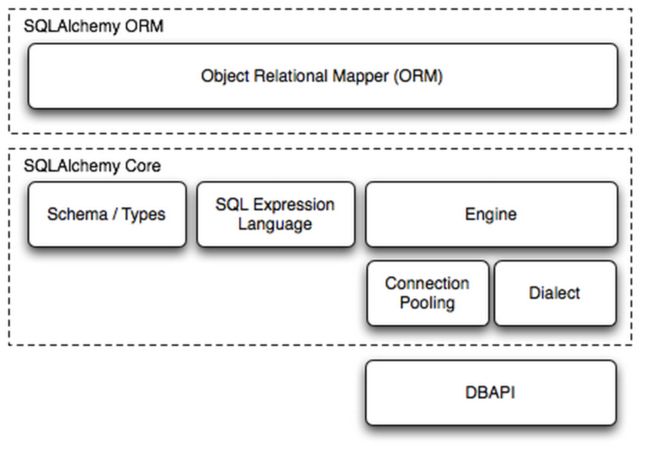
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL
-
Python
mysql
+
mysqldb:
/
/
<user>:<password>@<host>[:<port>]
/
<dbname>
pymysql
mysql
+
pymysql:
/
/
<username>:<password>@<host>
/
<dbname>[?<options>]
MySQL
-
Connector
mysql
+
mysqlconnector:
/
/
<user>:<password>@<host>[:<port>]
/
<dbname>
cx_Oracle
oracle
+
cx_oracle:
/
/
user:
pass
@host:port
/
dbname[?key
=
value&key
=
value...]
步骤一:
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy import create_engine
engine = create_engine("mysql+mysqldb://root:[email protected]:3306/s11", max_overflow=5)
engine.execute(
"INSERT INTO ts_test (a, b) VALUES ('2', 'v1')"
)
engine.execute(
"INSERT INTO ts_test (a, b) VALUES (%s, %s)",
((555, "v1"),(666, "v1"),)
)
engine.execute(
"INSERT INTO ts_test (a, b) VALUES (%(id)s, %(name)s)",
id=999, name="v1"
)
result = engine.execute('select * from ts_test')
result.fetchall()
事务操作
from sqlalchemy import create_engine
engine = create_engine("mysql+mysqldb://root:[email protected]:3306/s11", max_overflow=5)
# 事务操作
with engine.begin() as conn:
conn.execute("insert into table (x, y, z) values (1, 2, 3)")
conn.execute("my_special_procedure(5)")
conn = engine.connect()
# 事务操作
with conn.begin():
conn.execute("some statement", {'x':5, 'y':10})
步骤二:
使用 Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 进行数据库操作。Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey
metadata = MetaData()
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(20)),
)
color = Table('color', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(20)),
)
engine = create_engine("mysql+mysqldb://root:[email protected]:3306/s11", max_overflow=5)
metadata.create_all(engine)
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey
metadata = MetaData()
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(20)),
)
color = Table('color', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(20)),
)
engine = create_engine("mysql+mysqldb://root:[email protected]:3306/s11", max_overflow=5)
conn = engine.connect()
# 创建SQL语句,INSERT INTO "user" (id, name) VALUES (:id, :name)
conn.execute(user.insert(),{'id':7,'name':'seven'})
conn.close()
# sql = user.insert().values(id=123, name='wu')
# conn.execute(sql)
# conn.close()
# sql = user.delete().where(user.c.id > 1)
# sql = user.update().values(fullname=user.c.name)
# sql = user.update().where(user.c.name == 'jack').values(name='ed')
# sql = select([user, ])
# sql = select([user.c.id, ])
# sql = select([user.c.name, color.c.name]).where(user.c.id==color.c.id)
# sql = select([user.c.name]).order_by(user.c.name)
# sql = select([user]).group_by(user.c.name)
# result = conn.execute(sql)
# print result.fetchall()
# conn.close()
注:SQLAlchemy无法修改表结构,如果需要可以使用SQLAlchemy开发者开源的另外一个软件Alembic来完成。
步骤三:
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
engine = create_engine("mysql+mysqldb://root:[email protected]:3306/s11", max_overflow=5)
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50))
# 寻找Base的所有子类,按照子类的结构在数据库中生成对应的数据表信息
# Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
# ########## 增 ##########
# u = User(id=2, name='sb')
# session.add(u)
# session.add_all([
# User(id=3, name='sb'),
# User(id=4, name='sb')
# ])
# session.commit()
# ########## 删除 ##########
# session.query(User).filter(User.id > 2).delete()
# session.commit()
# ########## 修改 ##########
# session.query(User).filter(User.id > 2).update({'cluster_id' : 0})
# session.commit()
# ########## 查 ##########
# ret = session.query(User).filter_by(name='sb').first()
# ret = session.query(User).filter_by(name='sb').all()
# print ret
# ret = session.query(User).filter(User.name.in_(['sb','bb'])).all()
# print ret
# ret = session.query(User.name.label('name_label')).all()
# print ret,type(ret)
# ret = session.query(User).order_by(User.id).all()
# print ret
# ret = session.query(User).order_by(User.id)[1:3]
# print ret
# session.commit()
所有的知识都在这里,你懂得:
http://www.cnblogs.com/wupeiqi/articles/5132791.html
这次写特地查了好多资料.昨天半夜突然发现之前写的内容全都不见了,也怪自己没保存草稿,...........