Moosefs小结
mfs分布式文件系统
软件可能的瓶颈:
1mfs系统master存在.单点故障(HA可以解决)
2.体系架构存储文件总数的可遇见的上限。(mfs把文件系统的结构缓存到 master的内存中,文件越多,master的内存消耗越大,8g对应 2500w 的文件数,2亿文件就得 64GB 内存)。master服务器 CPU负载取决于操作的次数,内存的使用取决于文件和文件夹的个数。
MFS文件系统结构:
4种角色:
管理服务器managing server (master):负责各个数据存储服务器的管理,文件读写调度,文件 空间回收以及恢复.多节点拷贝。
元数据日志服务器Metalogger server(Metalogger) : 负责备份 master服务器的变化日志文件, 文件类型为changelog_ml.*.mfs,以便于在master server 出问题的时候接替其进行工作。
数据存储服务器data servers (chunkservers):负责连接管理服务器,听从管理服务器调度,提供 存储空间,并为客户提供数据传输。
客户机挂载使用client computers :通过fuse内核接口挂接远程管理服务器上所管理的数据 存储服务器,看起来共享的文件系统和本地unix 文件系 统使用一样的效果。
chunkserver,Metalogger,client两个服务和客户端都要连接master。
MFS部署
主机环境:RHEL6.5selinux and iptables disabled
主控服务器Master:192.168.2.1
存储块服务器Chunkserver: 192.168.2.10 192.168.2.47
客户端Client: 192.168.2.254
下载包mfs-1.6.27.tar.gz
生成 rpm,便于部署:
yum install gcc make rpm-build fuse-devel zlib-devel -y
rpmbuild -tb mfs-1.6.27.tar.gz
ls ~/rpmbuild/RPMS/x86_64
mfs-cgi-1.6.27-2.x86_64.rpm mfs-client-1.6.27-2.x86_64.rpm
mfs-cgiserv-1.6.27-2.x86_64.rpm mfs-master-1.6.27-2.x86_64.rpm
mfs-chunkserver-1.6.27-2.x86_64.rpm mfs-metalogger-1.6.27-2.x86_64.rpm
主控服务器 Master server 安装:
rpm -ivh mfs-cgi-1.6.27-2.x86_64.rpm mfs-master-1.6.27-2.x86_64.rpm mfs-cgiserv-1.6.27-2.x86_64.rpm
cd /etc /mfs
cp mfsexports.cfg.dist mfsexports.cfg
cp mfstopology.cfg.dist mfstopology.cfg
cp mfsmaster.cfg.dist mfsmaster.cfg #主配置文件
此文件中凡是用#注释掉的变量均使用其默认值,基本不需要就可以工作:
#WORKING_USER和 WORKING_GROUP:是运行master server 的用户和组,nobody;
#SYSLOG_IDENT:是master server 在 syslog中的标识;
#LOCK_MEMORY:是否执行mlockall()以避免mfsmaster 进程溢出(默认为0);
#NICE_LEVE:运行的优先级(如果可以默认是-19; 注意:进程必须是用 root启动);
#EXPORTS_FILENAME:被挂接目录及其权限控制文件的存放位置
#TOPOLOGY_FILENAME : 定义 MFS 网络拓扑结构的文件位置
#DATA_PATH:数据存放路径,/var/lib/mfs此目录下大致有三类文件,changelog,sessions和 stats;
#BACK_LOGS:metadata的改变 log 文件数目(默认是50);
#BACK_META_KEEP_PREVIOUS:保存以前mfs 元数据的文件数,默认值是1;
#REPLICATIONS_DELAY_INIT:延迟复制的时间(默认是300s);
#REPLICATIONS_DELAY_DISCONNECT:chunkserver断开的复制延迟(默认是3600);
# MATOML_LISTEN_HOST:metalogger 监听的 IP地址(默认是*,代表任何IP);
# MATOML_LISTEN_PORT:metalogger 监听的端口地址(默认是9419);
# MATOCS_LISTEN_HOST:用于 chunkserver连接的 IP 地址(默认是*,代表任何IP);
# MATOCS_LISTEN_PORT:用于 chunkserver连接的端口地址(默认是9420);
# MATOCU_LISTEN_HOST/MATOCL_LISTEN_HOST:用于客户端挂接连接的IP 地址(默认是*,
代表任何 IP);
# MATOCU_LISTEN_PORT/MATOCL_LISTEN_PORT:用于客户端挂接连接的端口地址(默认
是 9421);
#CHUNKS_LOOP_CPS:chunks的回环每秒检查的块最大值,默认100000;
# CHUNKS_LOOP_TIME :chunks 的回环频率(默认是:300秒);
# CHUNKS_SOFT_DEL_LIMIT :一个 chunkserver中可以删除 chunks的最大数,软限(默认:
10)
#CHUNKS_HARD_DEL_LIMIT:一个chunkserver 中可以删除chunks 的最大数,硬限(默认:
25)
# REPLICATIONS_DELAY_DISCONNECT:chunkserver 断开后的复制延时(默认:3600秒)
# CHUNKS_WRITE_REP_LIMIT:在一个循环里复制到一个chunkserver 的最大chunk 数目(默
认是 2)
# CHUNKS_READ_REP_LIMIT :在一个循环里从一个 chunkserver复制的最大 chunk 数目(默
认是 10)
# REJECT_OLD_CLIENTS:弹出低于 1.6.0的客户端挂接(0 或1,默认是 0)
# deprecated:
# CHUNKS_DEL_LIMIT - use CHUNKS_SOFT_DEL_LIMIT instead
# LOCK_FILE - lock system has been changed, and this option is used only to search for old
lockfile
cd /var/lib/mfs/ #数据存放路径
cp metadata.mfs.empty metadata.mfs
chown -R nobody .
vim /etc/hosts
192.168.2.1 mfsmaster #添加解析
mfsmaster #开启mfsmaster
mfsmaster stop #关闭mfsmaster
netstat -antlp
此时进入/var/lib/mfs可以查看隐藏文件,看到 moosefs所产生的数据:
.mfsmaster.lock 文件记录正在运行的 mfsmaster的主进程metadata.mfs, metadata.mfs.back MooseFS 文件系统的元数据 metadata的镜像changelog.*.mfs 是MooseFS 文件系统元数据的改变日志(每一个小时合并到metadata.mfs中一次)
Metadata文件的大小是取决于文件数的多少(而不是他们的大小)。changelog日志的大小是取决
于每小时操作的数目,但是这个时间长度(默认是按小时)是可配置的。
cd /usr/share/mfscgi/
chmod +x *.cgi
mfscgiserv #启动CGI 监控服务
在浏览器地址栏输入http://192.168.2.1:9425 即可查看master 的运行情况
存储块服务器 Chunk servers 安装:
192.168.2.10上:
yum localinstall -y mfs-chunkserver-1.6.26-1.x86_64.rpm
cd /etc/mfs/
cp mfschunkserver.cfg.dist mfschunkserver.cfg
cp mfshdd.cfg.dist mfshdd.cfg
mkdir /var/lib/mfs
在/var/lib/mfs目录中可以看到从 master上复制来的元数据changelog_ml.*.mfs是 MooseFS 文件系统的元数据的changelog 日志(备份的Master 的 Master的 changelog 日志)
metadata_ml.mfs.back是从 Master 主机上下载的最新的完整metadata.mfs.back 的拷贝
sessions.ml.mfs是从 master 下载的最新的sessions.mfs 文件拷贝。
mkdir /mnt/chunk1
chown nobody /mnt/chunk1/ /var/lib/mfs
vim /etc/hosts #要添加解析
192.168.2.1 mfsmaster
vim mfshdd.cfg #定义 mfs共享点
/mnt/chunk1
# vi mfsexports.cfg
* / rw,alldirs,maproot=0
mfschunkserver #开启服务
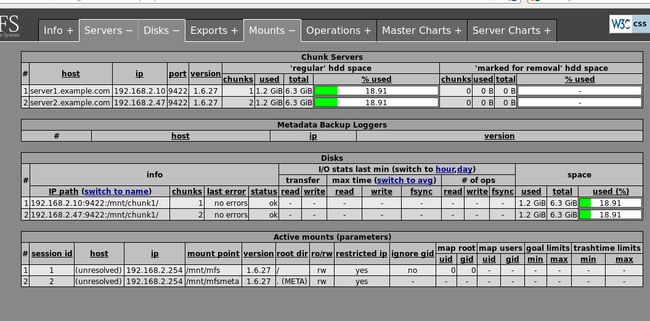
刷新网页:现在再通过浏览器访问http://192.168.2.1:9425/ 应该可以看见这个MooseFS 系统的全部信息,包括主控 master 和存储服务chunkserver 。
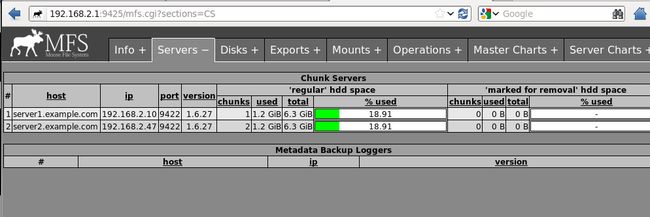
客户端 client安装:
yum localinstall -y mfs-client-1.6.26-1.x86_64.rpm
cd /etc/mfs/
cp mfsmount.cfg.dist mfsmount.cfg
vim mfsmount.cfg #定义客户端默认挂载
/mnt/mfs
mkdir /mnt/mfs
vim /etc/hosts #添加解析
192.168.2.1 mfsmaster
mfsmount #开启挂载服务
df #可看到已挂载上
MFS测试:
在 MFS挂载点下创建两个目录,并设置其文件存储份数:
cd /mnt/mfs
mkdir dir1 dir2
mfsdirinfo dir1/
mfsgetgoal dir1/
mfssetgoal -r 2 dir2/ #设置在 dir2中文件存储份数为两个,默认是一个
dir2/:
inodes with goal changed: 1
inodes with goal not changed: 0
inodes with permission denied: 0
对一个目录设定“goal”,此目录下的新创建文件和子目录均会继承此目录的设定,但不会改变已
经存在的文件及目录的 copy份数。但使用-r选项可以更改已经存在的 copy份数。
cp /etc/passwd dir1/
cp /etc/fstab dir2/
cd dir1/
mfsfileinfo passwd #查看文件信息
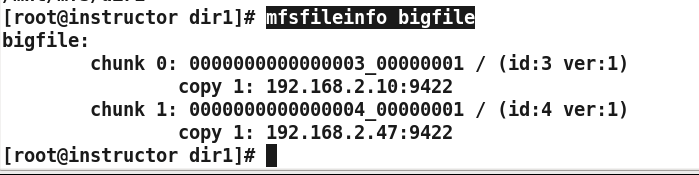
passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
copy 1: 192.168.2.47:9422
cd ../dir2
mfsfileinfo fstab
fstab:
chunk 0: 0000000000000002_00000001 / (id:2 ver:1)
copy 1: 192.168.2.10:9422
copy 2: 192.168.2.47:9422
若关闭chunkserver2,即关闭192.168.2.47的mfschunkserver
测试:
mfsfileinfo dir1/passwd
dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
no valid copies !!!
mfsfileinfo dir2/fstab
dir2/fstab:
chunk 0: 0000000000000002_00000001 / (id:2 ver:1)
copy 1: 192.168.2.10:9422
启动 mfschunkserver2后,文件恢复正常。
恢复误删文件
rm -f dir1/passwd
mfsgettrashtime dir1/
dir1/: 86400
文件删除后存放在“ 垃圾箱”中的时间称为隔离时间,这个时间可以用 mfsgettrashtime命令来查
看,用mfssettrashtime 命令来设置,单位为秒,默认为86400 秒。
mkdir /mnt/mfsmeta
mfsmount -m /mnt/mfsmeta/ -H mfsmaster
挂载 MFSMETA文件系统,它包含目录trash (包含仍然可以被还原的删除文件的信息)和
trash/undel (用于获取文件)。把删除的文件,移到/ trash/undel 下,就可以恢复此文件。
cd /mnt/mfsmeta/trash
mv 00000004\|dir1\|passwd undel/
到 dir1目录中可以看到 passwd文件恢复
在 MFSMETA的目录里,除了trash 和 trash/undel两个目录,还有第三个目录reserved,该目
录内有已经删除的文件,但却被其他用户一直打开着。在用户关闭了这些被打开的文件后,
reserved目录中的文件将被删除,文件的数据也将被立即删除。此目录不能进行操作。
为了安全停止 MooseFS集群,建议执行如下的步骤:
umount -l /mnt/mfs #客户端卸载 MooseFS文件系统
mfschunkserver stop #停止 chunk server 进程
mfsmetalogger stop #停止 metalogger进程
mfsmaster stop #停止主控 master server 进程
安全的启动 MooseFS集群:
mfsmaster start #启动 master进程
mfschunkserver start #启动 chunkserver进程
mfsmetalogger start #启动 metalogger进程
mfsmount #客户端挂载 MooseFS文件系统
实际上无论如何顺序启动或关闭,未见任何异常,master启动后,metalogger、chunker、client
三个元素都能自动与 master建立连接。
故障测试:
Client客户端断电、断网对 MFS的体系不产生影响.
如果客户端误杀 killall -9 mfsmount 进程,需要先umount /mnt/mfs,然后再mfsmount。否则会
提示:/mnt/mfs: Transport endpoint is not connected
chunkserver端:
传输一个大文件,设置存储2 份。传输过程中,关掉chunker1,这样绝对会出现有部分块只存在
chunker2上;启动chunker1,关闭chunker2,这样绝对会有部分块只存在chunker1 上。
把 chunker2启动起来。整个过程中,客户端一直能够正常传输。使用mfsfileinfo 查看此文件,发
现有的块分布在 chunker1上,有的块分布在chunker2 上。使用mfssetgoal -r 1 后,所有块都修
改成 1块了,再mfssetgoal -r 2,所有块都修改成2 份了。
断网、杀掉 mfschunkserver程序对 MFS 系统无影响。
断电:
#无文件传输时,对两个chunker 都无影响;
#当有文件传输时,但是文件设置存储一份时,对文件的存储无影响。
#文件设置存储两份,数据传输过程中,关掉chunker1,等待数据传输完毕后,启动
chunker1.chunker1启动后,会自动从chunker2 复制数据块。整个过程中文件访问不受影响。
#文件设置存储两份,数据传输过程中,关掉chunker1,不等待数据传输完毕,开机启动
chunker1.chunker1启动后,client 端会向chunker1 传输数据,同时chunker1 也从 chunker2复
制缺失的块。
只要不是两个 chunker服务器同时挂掉的话,就不会影响文件的传输,也不会影响服务的使用。
master端:
断网、杀掉 MFS的 master 服务对MFS 系统无影响。
断电可能会出现以下的情况:
当没有文件传输时,可在服务器重启之后,运行mfsmetarestore –a 进行修复,之后执行
mfsmaster start 恢复 master 服务。
mfsmetarestore -a
mfsmaster热备:(HA解决单点故障)
解决方案:drbd+corosync+pacemaker
mfs启动脚本:
cd /etc/init.d/
vim mfs
#!/bin/bash
# Init file for the MooseFS master service
# chkconfig: - 92 84
# description: MooseFS master
# processname: mfsmaster
# Source function library.
# Source networking configuration.
. /etc/init.d/functions
. /etc/sysconfig/network
# Source initialization configuration.
# Check that networking is up.
[ "${NETWORKING}" == "no" ] && exit 0
[ -x "/usr/sbin/mfsmaster" ] || exit 1
[ -r "/etc/mfs/mfsmaster.cfg" ] || exit 1
[ -r "/etc/mfs/mfsexports.cfg" ] || exit 1
RETVAL=0
prog="mfsmaster"
datadir="/var/lib/mfs"
mfsbin="/usr/sbin/mfsmaster"
mfsrestore="/usr/sbin/mfsmetarestore"
start () {
echo -n $"Starting $prog: "
$mfsbin start >/dev/null 2>&1
if [ $? -ne 0 ];then
$mfsrestore -a >/dev/null 2>&1 && $mfsbin start >/dev/null 2>&1
fi
RETVAL=$?
echo
return $RETVAL
}
stop () {
echo -n $"Stopping $prog: "
$mfsbin -s >/dev/null 2>&1 || killall -9 $prog #>/dev/null 2>&1
RETVAL=$?
echo
return $RETVAL
}
restart () {
stop
start
}
reload () {
echo -n $"reload $prog: "
$mfsbin reload >/dev/null 2>&1
RETVAL=$?
echo
return $RETVAL
}
restore () {
echo -n $"restore $prog: "
$mfsrestore -a >/dev/null 2>&1
RETVAL=$?
echo
return $RETVAL
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
reload)
reload
;;
restore)
restore
;;
status)
status $prog
RETVAL=$?
;;
*)
echo $"Usage: $0 {start|stop|restart|reload|restore|status}"
RETVAL=1
esac
exit $RETVAL
drbd配置:
DRBD单主模式下(一个集群内一个资源只有一个primary角色)实际上是一种常规的HA结构,具有故障转移功能的高可用集群方式。
双主模式下(对于一个资源有两个primary节点),并发访问就有可能,需使用共享集群文件系统。如GFS,OCFS2
复制数据传输模式,支持异步复制,同步复制。
HA1节点机:
下载包 drbd-8.4.3.tar.gz
tar zxf drbd-8.4.3.tar.gz
cd drbd-8.4.3
软件包依赖性:yum install -y flex kernel-devel
./configure --enable-spec –with-km #–with-km创建DRBD内核的安装目录,--enable-spec是创建RPM的spec文件。编译DRBD作为内核模块
生成rpm包:
rpmbuild -bb drbd.spec
cp ~/drbd-8.4.3.tar.gz /root/rpmbuild/SOURCES/
rpmbuild -bb drbd-km.spec
cd rpmbuild/RPMS/x86_64/
drbd-8.4.3-2.el6.x86_64.rpm drbd-bash-completion-8.4.3-2.el6.x86_64.rpm
drbd-debuginfo-8.4.3-2.el6.x86_64.rpm drbd-heartbeat-8.4.3-2.el6.x86_64.rpm
drbd-km-2.6.32_431.el6.x86_64-8.4.3-2.el6.x86_64.rpm
drbd-km-debuginfo-8.4.3-2.el6.x86_64.rpm
drbd-pacemaker-8.4.3-2.el6.x86_64.rpm drbd-udev-8.4.3-2.el6.x86_64.rpm
drbd-utils-8.4.3-2.el6.x86_64.rpm drbd-xen-8.4.3-2.el6.x86_64.rpm
rpm -ivh drbd-*
把drbd的rpm包发给HAnode2:
scp drbd-* 192.168.2.2:
node2上rpm -ivh drbd-*
cd /etc/drbd.d/
vim mfsdata.res #.res文件包含每个resource配置
resource mfsdata {
meta-disk internal;
device /dev/drbd1;
syncer {
verify-alg sha1;
}
on node1.example.com {
disk /dev/vdb1;
address 192.168.2.1:7789; #两个HA机的IP
}
on node2.example.com {
disk /dev/vdb1;
address 192.168.2.2:7789;
}
}
scp mfsdata.res 192.168.2.2:/etc/drbd.d/
两虚拟机node1 node2分别添加一块硬盘/dev/vdb
两机子上:
fdisk -l
fdisk -cu /dev/vdb 分区
drbdadm create-md mfsdata #创建drbd设备的元数据,这一步仅在初始化设备创建时完成。
drbdadm:它是DRBD程序套件中的高级管理工具,能从配置文件中获取DRBD的所有参数。
drbdsetup:配置DRBD模块载入到内核。
drbdmeta:该命令用于创建,存储,恢复,修改DRBD元数据结构。
/etc/init.d/drbd start #启动DRBD
ll /dev/drbd1
cat /proc/drbd #查看drbd的相关信息,如同步状态!
node1上:
drbdsetup primary /dev/drbd1 --force #在被选择为同步源的节点上执行。启动初始化完全同步。
cat /proc/drbd可查看同步的进展情况。
mkfs.ext4 /dev/drbd1 #格式化为ext4
mount /dev/drbd1 /mnt
cd /mnt
chown nobody .
umount /mnt
drbdadm secondary mfsdata #资源降级 设置为次
cat /proc/drbd
node2上:
drbdsetup primary /dev/drbd1 –force
mount /dev/drbd1 /mnt
若node1要挂载drbd设备,需先升级为主,再挂载;node2要查看的时候,node1先卸载,再降级,node2先升级,再挂载,查看。
drbd有主备要求,只有primary才会被挂载。DRBD服务启动时,要求节点的服务都要起来,因为节点间要同步,否则单节点的服务是起不来的。默认情况下,各节点启动时,都处于secondary,需要手工将其设置成primary.才能正常被挂载工作!
/dev/drbd1只能同时被一个节点挂载,如果同时挂载会报错。
在pacemaker里添加drbd:
先找一个虚拟IP,把//etc/hosts下mfamaster对应的解析都改成虚拟IP。
首先加载drbd资源,激活之后产生drbd设备,再把文件系统挂载到指定目录
pacemaker配置:
一个节点机配置:
crm(live)configure# primitive MFSDATA ocf:linbit:drbd params drbd_resource=mfsdata
primitiveMFSfs ocf:heartbeat:Filesystem params device=/dev/drbd1 directory=/var/lib/mfs fstype=ext4
crm(live)configure# commit
crm(live)configure# ms mfsdataclone MFSDATA meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true #设置主master
crm(live)configure# primitive mfsmaster lsb:mfs op monitor interval=30s # lsb标准二进制路径, ocf资源代理
crm(live)configure# group mfsgrp vip MFSfs mfsmaster #注意顺序,先找虚拟IP或者 MFSfs,再找mfsmaster
crm(live)configure# colocation mfs-with-drbd inf: mfsgrp mfsdataclone:Master
crm(live)configure# order mfs-after-drbd inf: mfsdataclone:promote mfsgrp:start #mfs在drbd之后
crm(live)configure# show
crm(live)configure# commit
另一节点机监控
crm_mon

当前master为node2,关掉corosync,会切换到node1.
另个数据存储器开启服务mfschunkserver
客户端挂载mfsmount
df查看

cd /mnt/mfs/dir1
mfsfileinfo bigfile
fence测试:
主机ifdown eth0,fence会重启,备机监控
测试成功后,设置开机自启动chkconfig corosync on