skiplist(跳表)算法实现
跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
下面来研究一下跳表的核心思想:
先从链表开始,如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。
![]()
如果是说链表是排序的,并且节点中还存储了指向前面第二个节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。

这基本上就是跳表的核心思想,其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
跳表的数据存储模型
我们定义:
如果一个基点存在k个向前的指针的话,那么陈该节点是k层的节点。
一个跳表的层MaxLevel义为跳表中所有节点中最大的层数。
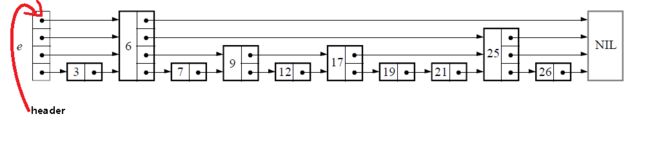
下面给出一个完整的跳表的图示:

那么我们该如何将该数据结构使用二进制存储呢?通过上面的跳表的很容易设计这样的数据结构:
定义每个节点类型:
//定义每个节点类型:
type nodeStructure struct {
key int // key值
value int // value值
forward []*nodeStructure
}
上面的每个结构体对应着图中的每个节点,如果一个节点是一层的节点的话(如7,12等节点),那么对应的forward将指向一个只含一个元素的数组,以此类推。
定义跳表数据类型:
// 定义跳表数据类型
type listStructure struct {
level int /* Maximum level of the list (1 more than the number of levels in the list) */
header *nodeStructure /* pointer to header */
}
跳表数据类型中包含了维护跳表的必要信息,level表明跳表的层数,header如下所示:
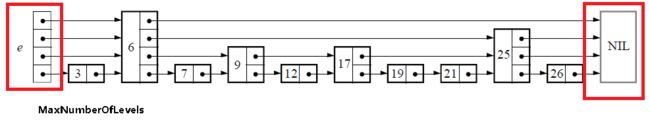
初始化的过程很简单,仅仅是生成下图中红线区域内的部分,也就是跳表的基础结构:
//跳表初始化
func newList() *listStructure {
var l *listStructure
var i int
// 申请list类型大小的内存
l = &listStructure{}
// 设置跳表的层level,初始的层为0层(数组从0开始)
l.level = 0
// 生成header部分
l.header = newNodeOfLevel(MaxNumberOfLevels)
// 将header的forward数组清空
for i = 0; i < MaxNumberOfLevels; i++ {
l.header.forward[i] = nil
}
return l
}
插入操作
由于跳表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳表的level变量。
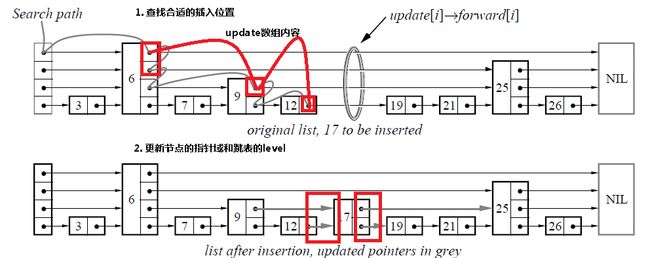
func insert(l *listStructure, key int, value int) bool {
var k int
// 使用了update数组
var update [MaxNumberOfLevels]*nodeStructure
var p, q *nodeStructure
p = l.header
k = l.level
fmt.Printf("list level: %v\n", k)
for ; k >= 0; k-- {
// 查找插入位置
q = p.forward[k]
for q != nil && q.key < key {
p = q
q = p.forward[k]
}
// 设置update数组
update[k] = p
} // 对于每一层进行遍历 一直到最低层
// 这里已经查找到了合适的位置,并且update数组已经
// 填充好了元素 貌似不插入重复元素
if q != nil && q.key == key {
q.value = value
return false
}
// 随机生成一个层数
k = randomLevel()
fmt.Printf("random Level: %v\n", k)
if k > l.level {
// 如果新生成的层数比跳表的层数大的话
// 增加整个跳表的层数
l.level++
k = l.level
// 在update数组中将新添加的层指向l->header
update[k] = l.header
}
// 生成层数个节点数目
q = newNodeOfLevel(k + 1)
q.key = key
q.value = value
// 每层插入节点
for ; k >= 0; k-- {
p = update[k]
q.forward[k] = p.forward[k]
p.forward[k] = q
}
// 如果程序运行到这里,程序已经插入了该节点
return true
}
删除某个节点
和插入是相同的,首先查找需要删除的节点,如果找到了该节点的话,那么只需要更新指针域,如果跳表的level需要更新的话,进行更新。
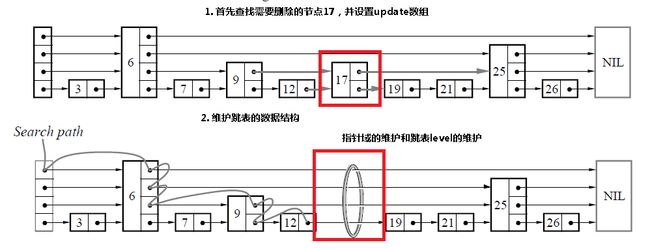
func delete(l *listStructure, key int) bool {
var k, m int
// 生成一个辅助数组update
var update [MaxNumberOfLevels]*nodeStructure
var p, q *nodeStructure
p = l.header
k = l.level
m = l.level
//指向该节点对应层的前驱节点 一直到最低层
for ; k >= 0; k-- {
q = p.forward[k]
for q != nil && q.key < key {
p = q
q = p.forward[k]
}
update[k] = p
}
// 如果找到了该节点,才进行删除的动作
if q != nil && q.key == key {
// 指针运算
for k = 0; k <= m && update[k].forward[k] == q; k++ {
// 这里可能修改l.header.forward数组的值的
p = update[k]
p.forward[k] = q.forward[k]
}
// 如果删除的是最大层的节点,那么需要重新维护跳表的
// 层数level
for l.header.forward[m] == nil && m > 0 {
m--
}
l.level = m
return true
} else {
return false
}
}
skiplist完整代码:
package main
import (
"fmt"
"math/rand"
"time"
)
//定义每个节点类型:
type nodeStructure struct {
key int // key值
value int // value值
forward []*nodeStructure
}
// 定义跳表数据类型
type listStructure struct {
level int /* Maximum level of the list (1 more than the number of levels in the list) */
header *nodeStructure /* pointer to header */
}
const (
MaxNumberOfLevels = 11
MaxLevel = 10
)
// newNodeOfLevel生成一个nodeStructure结构体,同时生成l个*nodeStructure数组指针
//#define newNodeOfLevel(l) (*nodeStructure)malloc(sizeof(struct nodeStructure)+(l)*sizeof(nodeStructure *))
func newNodeOfLevel(level int) *nodeStructure {
nodearr := make([]*nodeStructure, level) //new([level]*node)
return &nodeStructure{forward: nodearr}
}
//跳表初始化
func newList() *listStructure {
var l *listStructure
var i int
// 申请list类型大小的内存
l = &listStructure{}
// 设置跳表的层level,初始的层为0层(数组从0开始)
l.level = 0
// 生成header部分
l.header = newNodeOfLevel(MaxNumberOfLevels)
// 将header的forward数组清空
for i = 0; i < MaxNumberOfLevels; i++ {
l.header.forward[i] = nil
}
return l
}
func randomLevel() int {
r := rand.New(rand.NewSource(time.Now().UnixNano()))
return r.Intn(MaxLevel)
}
func insert(l *listStructure, key int, value int) bool {
var k int
// 使用了update数组
var update [MaxNumberOfLevels]*nodeStructure
var p, q *nodeStructure
p = l.header
k = l.level
for ; k >= 0; k-- {
// 查找插入位置
q = p.forward[k]
for q != nil && q.key < key {
p = q
q = p.forward[k]
}
// 设置update数组
update[k] = p
} // 对于每一层进行遍历 一直到最低层
// 这里已经查找到了合适的位置,并且update数组已经
// 填充好了元素 貌似不插入重复元素
if q != nil && q.key == key {
q.value = value
return false
}
// 随机生成一个层数
k = randomLevel()
if k > l.level {
// 如果新生成的层数比跳表的层数大的话
// 增加整个跳表的层数
l.level++
k = l.level
// 在update数组中将新添加的层指向l->header
update[k] = l.header
}
// 生成层数个节点数目
q = newNodeOfLevel(k + 1)
q.key = key
q.value = value
// 每层插入节点
for ; k >= 0; k-- {
p = update[k]
q.forward[k] = p.forward[k]
p.forward[k] = q
}
// 如果程序运行到这里,程序已经插入了该节点
return true
}
func delete(l *listStructure, key int) bool {
var k, m int
// 生成一个辅助数组update
var update [MaxNumberOfLevels]*nodeStructure
var p, q *nodeStructure
p = l.header
k = l.level
m = l.level
//指向该节点对应层的前驱节点 一直到最低层
for ; k >= 0; k-- {
q = p.forward[k]
for q != nil && q.key < key {
p = q
q = p.forward[k]
}
update[k] = p
}
// 如果找到了该节点,才进行删除的动作
if q != nil && q.key == key {
// 指针运算
for k = 0; k <= m && update[k].forward[k] == q; k++ {
// 这里可能修改l.header.forward数组的值的
p = update[k]
p.forward[k] = q.forward[k]
}
// 如果删除的是最大层的节点,那么需要重新维护跳表的
// 层数level
for l.header.forward[m] == nil && m > 0 {
m--
}
l.level = m
return true
} else {
return false
}
}
func search(l *listStructure, key int) int {
var k int
var p, q *nodeStructure
p = l.header
k = l.level
//指向该节点对应层的前驱节点 一直到最低层
for ; k >= 0; k-- {
q = p.forward[k]
for q != nil && q.key < key {
q = q.forward[k]
}
if q != nil && q.key == key {
return q.value
}
}
if q != nil && q.key == key {
return q.value
} else {
return -1
}
}
func main() {
l := newList()
insert(l, 3, 30)
insert(l, 6, 60)
insert(l, 7, 70)
insert(l, 9, 90)
delete(l, 9)
insert(l, 12, 120)
insert(l, 17, 170)
insert(l, 19, 190)
fmt.Printf("skiplist:%v\n", search(l, 12))
fmt.Printf("skiplist:%v\n", search(l, 9))
}
程序输出结果:
skiplist:120 skiplist:-1