Hadoop CDH4.5 MapReduce YARN部署
前一篇文章部署了MRv1版本的MapReduce,现在我们尝试一下YARN版本的,节点服务部署信息如下:
IP Hostname HDFS YARN 192.168.1.10 U-1 Namenode ResourceManager、HistoryServer 192.168.1.20 U-2 Datanode NodeManager 192.168.1.30 U-3 Datanode NodeManager 192.168.1.40 U-4 Datanode NodeManager 192.168.1.50 U-5 Datanode NodeManager
1 在NameNode节点追加关于YARN的配置参数,/etc/hadoop/conf/mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>U-1:8021</value> </property> <property> <name>mapred.local.dir</name> <value>/mapred</value> </property> <property> <name>mapreduce.jobtracker.restart.recover</name> <value>true</value> </property> <!-- YARN --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
2 配置YARN守护进程
1 在NameNode(U-1)节点安装ResourceManager服务
apt-get install hadoop-yarn-resourcemanager hadoop-mapreduce hadoop-yarn2 在DataNode(U-2/3/4/5)节点安装 NodeManager 服务
apt-get install hadoop-yarn-nodemanager hadoop-yarn hadoop-mapreduce3 在NameNode(U-1)节点安装HistoryServer服务
apt-get install hadoop-mapreduce-historyserver
4 以下的配置参数你必须在/etc/hadoop/conf/yarn-site.xml配置文件中配置:
名称 配置默认值 解释 yarn.nodemanager.aux-services mapreduce.shuffle mapreduce应用需要的一项随机服务 yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler 随机服务的具体class的名称 yarn.resourcemanager.address U-1:8032 RM的应用管理接口 yarn.resourcemanager.scheduler.address U-1:8030 调度接口 yarn.resourcemanager.resource-tracker.address U-1:8031 资源跟踪接口 yarn.resourcemanager.admin.address U-1:8033 RM管理员接口 yarn.resourcemanager.webapp.address U-1:8088 RM的web接口
接下来,你需要创建相关的本地目录并赋予正确的权限,用来存储YARN进程的数据。
名称 解释 值 yarn.nodemanager.local-dirs 指定NM在哪里存储本地文件 /yarn/local yarn.nodemanager.log-dirs 指定NM在哪里存储log文件 /yarn/logs yarn.nodemanager.remote-app-log-dir 指定在哪个目录进行日志聚合
yarn-site.xml的配置如下:
<configuration>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>U-1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>U-1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>U-1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>U-1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>U-1:8088</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,
$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,
$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,
$YARN_HOME/*,$YARN_HOME/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/yarn/logs</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/var/log/hadoop-yarn/apps</value>
</property>
</configuration>
在你指定完yarn-site.xml文件后,需要创建相关的目录,并赋予正确的权限。在每个节点上(U-1/2/3/4/5)执行:
mkdir -p /yarn/local mkdir -p /yarn/logs chown -R yarn:yarn /yarn/local chown -R yarn:yarn /yarn/logs3 配置History Server服务
如果你打算在你的集群中运行YARN来代替MRv1,你也需要运行mapreduce JobHistory服务,在/etc/hadoop/conf/mapred-site.xml中追加设置如下:
<!--JobHistory --> <property> <name>mapreduce.jobhistory.address</name> <value>U-1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>U-1:19888</value> </property>4 配置Staging目录
YARN需要一个中转目录来存放jobs产生的临时文件。默认是创建在/tmp/hadoop-yarn/staging,在/etc/hadoop/conf/yarn-site.xml 中追加如下配置:
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
5 把U-1的/etc/hadoop/conf/目录下的yarn-site.xml和mapred-site.xml文件分发到集群的其他机器上(U-2/3/4/5),因为在上一章已经把hdfs-site.xml分发到集群中了,而这一章又没有做改变,所以不需要分发hdfs-site.xml
scp yarn-site.xml mapred-site.xml [email protected]:/etc/hadoop/conf/ scp yarn-site.xml mapred-site.xml [email protected]:/etc/hadoop/conf/ scp yarn-site.xml mapred-site.xml [email protected]:/etc/hadoop/conf/ scp yarn-site.xml mapred-site.xml [email protected]:/etc/hadoop/conf/
6 启动HDFS集群
1 在NameNode(U-1)上启动
service hadoop-hdfs-namenode2 在DataNode(U-2/3/4/5)上启动
service hadoop-hdfs-datanode start
注意:启动服务时使用service命令,不要使用/etc/init.d/命令,官方提醒很多次了。原因很简单.....
7 在HDFS中创建 /tmp目录
创建/tmp目录的原因和MRv1一样
sudo -u hdfs hadoop fs -mkdir /tmp sudo -u hdfs hadoop fs -chmod -R 1777 /tmp8 创建History目录并设置权限
sudo -u hdfs hadoop fs -mkdir /user/history sudo -u hdfs hadoop fs -chmod -R 1777 /user/history sudo -u hdfs hadoop fs -chown yarn /user/history9 创建log目录
sudo -u hdfs hadoop fs -mkdir /var/log/hadoop-yarn sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn10 检查HDFS的文件结构
hadoop fs -ls -R /11 启动YARN和MapReduce JobHistory服务
1 在NameNode(U-1)上执行
service hadoop-yarn-resourcemanager start service hadoop-mapreduce-historyserver start2 在DataNode(U-2/3/4/5)上执行
service hadoop-yarn-nodemanager start
12 在HDFS中为每个MapReduce用户创建家目录,在namenode上创建
sudo -u hdfs hadoop fs -mkdir /user/<user> sudo -u hdfs hadoop fs -chown <user> /user/<user><user>是你的linux系统用户
13 验证结果
1 在NameNode执行jps命令
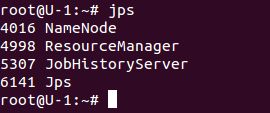
2 在DataNode执行jps命令
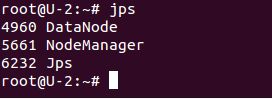
参考:官方文档
15 Tips and Guidelines
echo never > /sys/kernel/mm/transparent_hugepage/defrag sysctl -w vm.swappiness=0
16 MapReduce配置最佳实践(/etc/hadoop/conf/mapred-site.xml)
1 在task任务完成后迅速发送heartbeat信号(default:false)
<property> <name>mapreduce.tasktracker.outofband.heartbeat</name> <value>true</value> </property>2 在单节点系统中减少JobClient报告状态的时间 (default:1000 milliseconds)
<property> <name>jobclient.progress.monitor.poll.interval</name> <value>10</value> </property>3 JobTracker heartbeat的时间间隔
<property> <name>mapreduce.jobtracker.heartbeat.interval.min</name> <value>10</value> </property>4 开启MapReduce JVMs
<property> <name>mapred.reduce.slowstart.completed.maps</name> <value>0</value> </property>17 HDFS配置最佳实践(/etc/hadoop/conf/hdfs-site.xml)
<property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <property> <name> dfs.client.read.shortcircuit.streams.cache.size</name> <value>1000</value> </property> <property> <name> dfs.client.read.shortcircuit.streams.cache.size.expiry.ms</name> <value>1000</value> </property> <property> <name>dfs.domain.socket.path</name> <value>/var/run/hadoop-hdfs/dn._PORT</value> </property>