Intellj IDEA +SBT + Scala + Spark Sql读取HDFS数据
前提Spark集群已经搭建完毕,如果不知道怎么搭建,请参考这个链接:
http://qindongliang.iteye.com/blog/2224797
注意提交作业,需要使用sbt打包成一个jar,然后在主任务里面添加jar包的路径远程提交即可,无须到远程集群上执行测试,本次测试使用的是Spark的Standalone方式
sbt依赖如下:
demo1:使用Scala读取HDFS的数据:
demo2:使用Scala 在客户端造数据,测试Spark Sql:
Spark SQL 映射实体类的方式读取HDFS方式和字段,注意在Scala的Objcet最上面有个case 类定义,一定要放在
这里,不然会出问题:

demo2:使用Scala 远程读取HDFS文件,并映射成Spark表,以Spark Sql方式,读取top10:
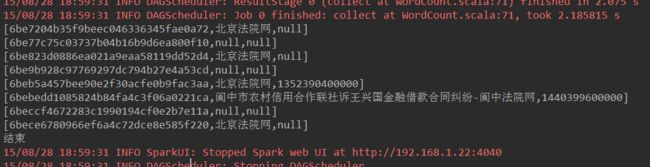
在IDEA的控制台,可以输出如下结果:
最后欢迎大家扫码关注微信公众号:我是攻城师(woshigcs),我们一起学习,进步和交流!(woshigcs)
本公众号的内容是有关搜索和大数据技术和互联网等方面内容的分享,也是一个温馨的技术互动交流的小家园,有什么问题随时都可以留言,欢迎大家来访!

http://qindongliang.iteye.com/blog/2224797
注意提交作业,需要使用sbt打包成一个jar,然后在主任务里面添加jar包的路径远程提交即可,无须到远程集群上执行测试,本次测试使用的是Spark的Standalone方式
sbt依赖如下:
name := "spark-hello"
version := "1.0"
scalaVersion := "2.11.7"
//使用公司的私服
resolvers += "Local Maven Repository" at "http://dev.bizbook-inc.com:8083/nexus/content/groups/public/"
//使用内部仓储
externalResolvers := Resolver.withDefaultResolvers(resolvers.value, mavenCentral = false)
//Hadoop的依赖
libraryDependencies += "org.apache.hadoop" % "hadoop-client" % "2.7.1"
//Spark的依赖
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "1.4.1"
//Spark SQL 依赖
libraryDependencies += "org.apache.spark" % "spark-sql_2.11" % "1.4.1"
//java servlet 依赖
libraryDependencies += "javax.servlet" % "javax.servlet-api" % "3.0.1"
demo1:使用Scala读取HDFS的数据:
/** *
* Spark读取来自HDFS的数据
*/
def readDataFromHDFS(): Unit ={
//以standalone方式运行,提交到远程的spark集群上面
val conf = new SparkConf().setMaster("spark://h1:7077").setAppName("load hdfs data")
conf.setJars(Seq(jarPaths));
//得到一个Sprak上下文
val sc = new SparkContext(conf)
val textFile=sc.textFile("hdfs://h1:8020/user/webmaster/crawldb/etl_monitor/part-m-00000")
//获取第一条数据
//val data=textFile.first()
// println(data)
//遍历打印
/**
* collect() 方法 游标方式迭代收集每行数据
* take(5) 取前topN条数据
* foreach() 迭代打印
* stop() 关闭链接
*/
textFile.collect().take(5).foreach( line => println(line) )
//关闭资源
sc.stop()
}
demo2:使用Scala 在客户端造数据,测试Spark Sql:
def mappingLocalSQL1() {
val conf = new SparkConf().setMaster("spark://h1:7077").setAppName("hdfs data count")
conf.setJars(Seq(jarPaths));
val sc = new SparkContext(conf)
val sqlContext=new SQLContext(sc);
//导入隐式sql的schema转换
import sqlContext.implicits._
val df = sc.parallelize((1 to 100).map(i => Record(i, s"val_$i"))).toDF()
df.registerTempTable("records")
println("Result of SELECT *:")
sqlContext.sql("SELECT * FROM records").collect().foreach(println)
//聚合查询
val count = sqlContext.sql("SELECT COUNT(*) FROM records").collect().head.getLong(0)
println(s"COUNT(*): $count")
sc.stop()
}
Spark SQL 映射实体类的方式读取HDFS方式和字段,注意在Scala的Objcet最上面有个case 类定义,一定要放在
这里,不然会出问题:
demo2:使用Scala 远程读取HDFS文件,并映射成Spark表,以Spark Sql方式,读取top10:
val jarPaths="target/scala-2.11/spark-hello_2.11-1.0.jar"
/**Spark SQL映射的到实体类的方式**/
def mapSQL2(): Unit ={
//使用一个类,参数都是可选类型,如果没有值,就默认为NULL
//SparkConf指定master和任务名
val conf = new SparkConf().setMaster("spark://h1:7077").setAppName("spark sql query hdfs file")
//设置上传需要jar包
conf.setJars(Seq(jarPaths));
//获取Spark上下文
val sc = new SparkContext(conf)
//得到SQL上下文
val sqlContext=new SQLContext(sc);
//必须导入此行代码,才能隐式转换成表格
import sqlContext.implicits._
//读取一个hdfs上的文件,并根据某个分隔符split成数组
//然后根据长度映射成对应字段值,并处理数组越界问题
val model=sc.textFile("hdfs://h1:8020/user/webmaster/crawldb/etl_monitor/part-m-00000").map(_.split("\1"))
.map( p => ( if (p.length==4) Model(Some(p(0)), Some(p(1)), Some(p(2)), Some(p(3).toLong))
else if (p.length==3) Model(Some(p(0)), Some(p(1)), Some(p(2)),None)
else if (p.length==2) Model(Some(p(0)), Some(p(1)),None,None)
else Model( Some(p(0)),None,None,None )
)).toDF()//转换成DF
//注册临时表
model.registerTempTable("monitor")
//执行sql查询
val it = sqlContext.sql("SELECT rowkey,title,dtime FROM monitor limit 10 ")
// val it = sqlContext.sql("SELECT rowkey,title,dtime FROM monitor WHERE title IS NULL AND dtime IS NOT NULL ")
println("开始")
it.collect().take(8).foreach(line => println(line))
println("结束")
sc.stop();
}
在IDEA的控制台,可以输出如下结果:
最后欢迎大家扫码关注微信公众号:我是攻城师(woshigcs),我们一起学习,进步和交流!(woshigcs)
本公众号的内容是有关搜索和大数据技术和互联网等方面内容的分享,也是一个温馨的技术互动交流的小家园,有什么问题随时都可以留言,欢迎大家来访!