Keepalived+Nginx 实现双机热备
一.拓扑图:
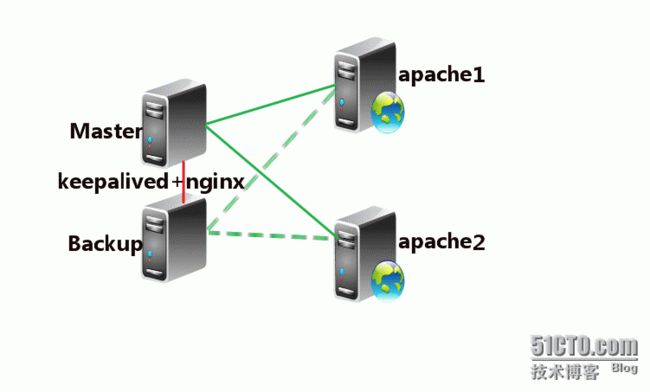
二.拓扑图的规划:

三.此架构考虑的问题:
1)、Master没挂,则Master占有vip且nginx运行在Master上
2)、Master挂了,则Backup抢占vip且在Backup上运行nginx服务
3)、如果Master服务器上的nginx服务挂了,则vip资源转移到Backup服务器上
4)、检测后端服务器的健康状态
Master和Backup两边都开启nginx服务,无论Master还是Backup,当其中的一个keepalived服务停止后,vip都会漂移到keepalived服务还在的节点上。
如果要想使nginx服务挂了,vip也漂移到另一个节点,则必须用脚本或者在配置文件里面用shell命令来控制。
首先必须明确后端服务器(apache)的健康状态检测keepalived在这种架构上是无法检测的,后端服务器的健康状态检测是有nginx来判断的,但是nginx 的检测机制有一定的缺陷,后端服务器某一个宕机之后,nginx还是会分发请求给它,在一定的时间内后端服务响应不了,nginx则会发给另外一个服务 器,然后当客户的请求来了,nginx会一段时间内不会把请求分发给已经宕机的服务器,但是过一段时间后,nginx还是会把分发请求发给宕机的服务器 上。
四.实验环境:
Master:
OS :CentOS 6.3
RIP :172.16.11.14
Software :
keepalived-1.2.12
nginx-1.8.0
ipvsadm
Backup:
OS :CentOS 6.3
RIP :172.16.11.15
Software :
keepalived-1.2.12
nginx-1.8.0
ipvsadm
VIP :172.16.11.16
五. 配置文件:
Master 的 nginx.conf 部分:
..........
upstream localhost {
server 172.16.11.11:80;
server 172.16.11.12:80;
}
server {
listen 8080;
server_name 172.16.11.14;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_set_header Host $host:8080;
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://localhost;
}
}
...........
Backup 的 nginx.conf 部分:
........
upstream localhost {
server 172.16.11.11:80;
server 172.16.11.12:80;
}
server {
listen 8080;
server_name 172.16.11.15;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_set_header Host $host:8080;
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://localhost;
}
}
........
Master 的 keepalived.conf:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL_1
}
vrrp_script chk_http_port {
script "</dev/tcp/127.0.0.1/8080" #用shell命令检查nginx服务是否运行
interval 1 #时间间隔为1秒检测一次
weight -2 #当nginx的服务不存在了,就把当前的权重-2
fall 2 #测试失败的次数
rise 1 #测试成功的次数
}
vrrp_instance VI_1 {
state MASTER #只有 MASTER 和 BACKUP 两种状态
interface eth0 #进行通信的端口
virtual_router_id 51 #同一个vrrp实例的唯一标识。即同一个vrrp_stance,MASTER和BACKUP的virtual_router_id是一致的。在整个vrrp内也唯一。
priority 101 #权重,数值越大,权重越大。MASTER大于SLAVE
advert_int 1 #MASTER和SLAVE负载均衡器之间同步检查的时间间隔。单位是:秒
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.11.16
}
track_script {
chk_http_port #引用上面的vrrp_script定义的脚本名称
}
}
virtual_server 172.16.11.16 8080 {
delay_loop 6
lb_algo wlc #负载均衡调度算法rr|wrr|lc|wlc|sh|dh|lblc
lb_kind DR #负载均衡转发规则NAT|DR|TUN
nat_mask 255.255.255.0
#persistence_timeout 60
protocol TCP
sorry_server 127.0.0.1 80
real_server 172.16.11.14 8080 {
weight 1 #权重,数值越大,权重越高。分发的可能越大
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
Backup 的 keepalived.conf:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL_2
}
vrrp_script chk_http_port {
script "</dev/tcp/127.0.0.1/8080"
interval 1
weight -2
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.11.16
}
track_script {
chk_http_port
}
}
virtual_server 172.16.11.16 8080 {
delay_loop 6
lb_algo wlc
lb_kind DR
nat_mask 255.255.255.0
#persistence_timeout 50
protocol TCP
sorry_server 127.0.0.1 80
real_server 172.16.11.15 8080 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
注意:
state : 都是MASTER(不是一个MASTER,一个BACKUP)
priority : Master 的 > Backup 的
virtual_router_id: 参数值要一样
为什么主备的参数state都是MASTER,state都设置成MASTER后,会根据priority的值大小竞争来决定谁是真正的MASTER,脚本检测也是在失败的时候会把权重减去相应的值(-2),比如原来 Master(14) 的priority=101,如果脚本检测到端口8080无法连接,就会 priority-2=99,小于 Backup(15) 的priority(100),此时 Backup 将竞争成为MASTER,这样就实现了Nginx应用的热备
验证:
# ip addr
# ipvsadm -L -n
如果想知道当前测试机(159.226.240.63)的访问请求被转发到那个服务器去了,可以在ipvsadm 命令后带一个选项,其完整形式为:ipvsadm –lcn | grep 159.226.240.63
[root@hld081028-mk ~]# ipvsadm -lcn | grep 159.226.240.63
TCP 14:56 ESTABLISHED 159.226.240.63:39783 172.16.11.16:8080 172.16.11.14:8080
六.测试场景
1.服务器层的双机热备
1)其中一个服务器宕机
2)其中一个服务器上的Keepalived宕掉
3)其中一个服务器网络不通
2.应用层的双机热备
1)其中一个服务器上的Nginx进程被意外kill
2) 其中一个服务器上的应用端口(8080)不通
二.拓扑图的规划:
三.此架构考虑的问题:
1)、Master没挂,则Master占有vip且nginx运行在Master上
2)、Master挂了,则Backup抢占vip且在Backup上运行nginx服务
3)、如果Master服务器上的nginx服务挂了,则vip资源转移到Backup服务器上
4)、检测后端服务器的健康状态
Master和Backup两边都开启nginx服务,无论Master还是Backup,当其中的一个keepalived服务停止后,vip都会漂移到keepalived服务还在的节点上。
如果要想使nginx服务挂了,vip也漂移到另一个节点,则必须用脚本或者在配置文件里面用shell命令来控制。
首先必须明确后端服务器(apache)的健康状态检测keepalived在这种架构上是无法检测的,后端服务器的健康状态检测是有nginx来判断的,但是nginx 的检测机制有一定的缺陷,后端服务器某一个宕机之后,nginx还是会分发请求给它,在一定的时间内后端服务响应不了,nginx则会发给另外一个服务 器,然后当客户的请求来了,nginx会一段时间内不会把请求分发给已经宕机的服务器,但是过一段时间后,nginx还是会把分发请求发给宕机的服务器 上。
四.实验环境:
Master:
OS :CentOS 6.3
RIP :172.16.11.14
Software :
keepalived-1.2.12
nginx-1.8.0
ipvsadm
Backup:
OS :CentOS 6.3
RIP :172.16.11.15
Software :
keepalived-1.2.12
nginx-1.8.0
ipvsadm
VIP :172.16.11.16
五. 配置文件:
Master 的 nginx.conf 部分:
..........
upstream localhost {
server 172.16.11.11:80;
server 172.16.11.12:80;
}
server {
listen 8080;
server_name 172.16.11.14;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_set_header Host $host:8080;
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://localhost;
}
}
...........
Backup 的 nginx.conf 部分:
........
upstream localhost {
server 172.16.11.11:80;
server 172.16.11.12:80;
}
server {
listen 8080;
server_name 172.16.11.15;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_set_header Host $host:8080;
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://localhost;
}
}
........
Master 的 keepalived.conf:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL_1
}
vrrp_script chk_http_port {
script "</dev/tcp/127.0.0.1/8080" #用shell命令检查nginx服务是否运行
interval 1 #时间间隔为1秒检测一次
weight -2 #当nginx的服务不存在了,就把当前的权重-2
fall 2 #测试失败的次数
rise 1 #测试成功的次数
}
vrrp_instance VI_1 {
state MASTER #只有 MASTER 和 BACKUP 两种状态
interface eth0 #进行通信的端口
virtual_router_id 51 #同一个vrrp实例的唯一标识。即同一个vrrp_stance,MASTER和BACKUP的virtual_router_id是一致的。在整个vrrp内也唯一。
priority 101 #权重,数值越大,权重越大。MASTER大于SLAVE
advert_int 1 #MASTER和SLAVE负载均衡器之间同步检查的时间间隔。单位是:秒
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.11.16
}
track_script {
chk_http_port #引用上面的vrrp_script定义的脚本名称
}
}
virtual_server 172.16.11.16 8080 {
delay_loop 6
lb_algo wlc #负载均衡调度算法rr|wrr|lc|wlc|sh|dh|lblc
lb_kind DR #负载均衡转发规则NAT|DR|TUN
nat_mask 255.255.255.0
#persistence_timeout 60
protocol TCP
sorry_server 127.0.0.1 80
real_server 172.16.11.14 8080 {
weight 1 #权重,数值越大,权重越高。分发的可能越大
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
Backup 的 keepalived.conf:
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL_2
}
vrrp_script chk_http_port {
script "</dev/tcp/127.0.0.1/8080"
interval 1
weight -2
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.11.16
}
track_script {
chk_http_port
}
}
virtual_server 172.16.11.16 8080 {
delay_loop 6
lb_algo wlc
lb_kind DR
nat_mask 255.255.255.0
#persistence_timeout 50
protocol TCP
sorry_server 127.0.0.1 80
real_server 172.16.11.15 8080 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
注意:
state : 都是MASTER(不是一个MASTER,一个BACKUP)
priority : Master 的 > Backup 的
virtual_router_id: 参数值要一样
为什么主备的参数state都是MASTER,state都设置成MASTER后,会根据priority的值大小竞争来决定谁是真正的MASTER,脚本检测也是在失败的时候会把权重减去相应的值(-2),比如原来 Master(14) 的priority=101,如果脚本检测到端口8080无法连接,就会 priority-2=99,小于 Backup(15) 的priority(100),此时 Backup 将竞争成为MASTER,这样就实现了Nginx应用的热备
验证:
# ip addr
# ipvsadm -L -n
如果想知道当前测试机(159.226.240.63)的访问请求被转发到那个服务器去了,可以在ipvsadm 命令后带一个选项,其完整形式为:ipvsadm –lcn | grep 159.226.240.63
[root@hld081028-mk ~]# ipvsadm -lcn | grep 159.226.240.63
TCP 14:56 ESTABLISHED 159.226.240.63:39783 172.16.11.16:8080 172.16.11.14:8080
六.测试场景
1.服务器层的双机热备
1)其中一个服务器宕机
2)其中一个服务器上的Keepalived宕掉
3)其中一个服务器网络不通
2.应用层的双机热备
1)其中一个服务器上的Nginx进程被意外kill
2) 其中一个服务器上的应用端口(8080)不通