推荐技术简介
转载请标明出处:http://blackwing.iteye.com/blog/2231556
根据项亮《动态推荐系统关键技术研究》的分类方式,可以根据使用数据来把推荐技术分成以下两类:
1.按使用数据分类:
协同过滤
内容过滤
社会化过滤
基于人口信息的过滤
机遇地理信息的推荐
2.按模型分类:
领域模型
矩阵分解模型
图模型
受限于数据获得的难易程度,一般用户行为数据较为容易获取,所以也导致协同过滤相关推荐算法的流行。
项亮表示,凡是使用了用户行为数据进行运算的都可以归类为协同过滤算法,经典的有user-based协同过滤和item-based协同过滤。
亚马逊把item-based算法发扬光大,它优点是效果不错,而且可以做推荐解析。
但每一种推荐算法,都有其适用场合,所以目前成熟的推荐系统,几本都属于混合型推荐系统。混合型推荐系统的核心思想,是融合多种推荐算法,使其取长补短。
《Hybrid Recommender Systems Survey and Experiments》这篇论文对混合推荐系统做了研究,列出了推荐系统的混合方式:
Weighted 加权融合
Switching 开关切换融合
Mixed 混合融合
Cascade 串联融合
Feature combination 特征组合融合
Feature augmentation 特征增益融合
Meta-level
推荐系统的开发框架,以下摘自《推荐系统实践》
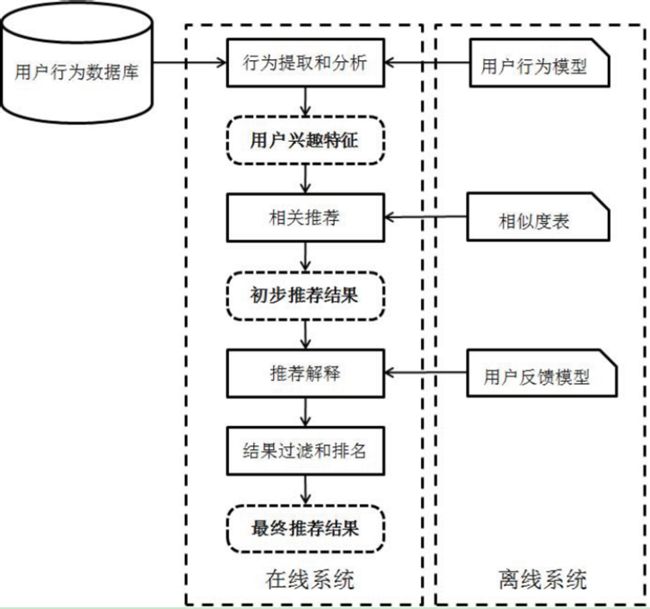
一个推荐系统,一般分为离线部分、在线部分。而其中的“推荐解释”模块,则并不是每个算法都适合,有些算法是做不了推荐解释的,例如基于矩阵分解的推荐算法。
以下是我们的推荐系统架构图
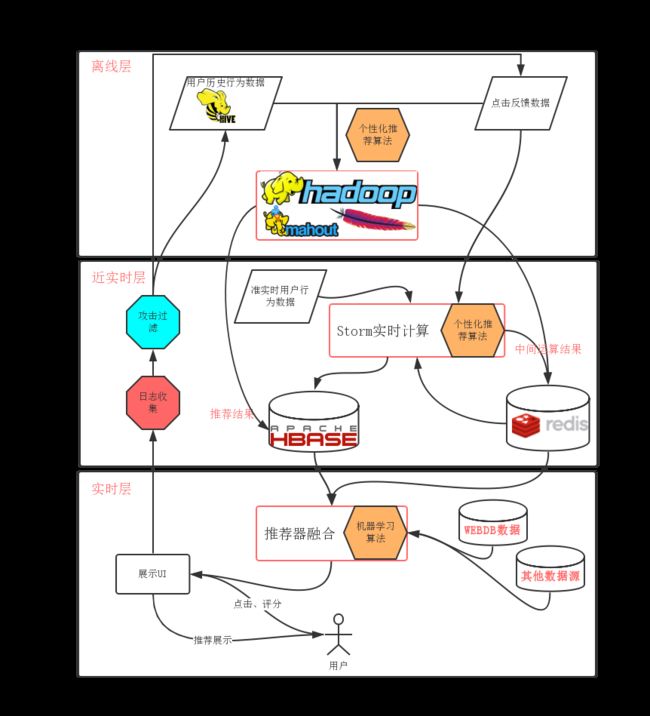
由离线层、半实时层、实时层构成。由于要处理大数据,一般使用的技术都是hadoop、spark、hbase、storm、redis、mahout等。
以item-based协同过滤为例,一般整个个性化推荐的流程如下:
1. 读取用户行为数据,进行抽取清理
2. 根据清理后的行为数据,算出任意两两item的相似度
3. 根据业务需要,截取N个与某item最相似的相关item,写入持久化存储,例如hbase
4. 上层web程序,根据user的历史观看记录,找出3中算好的与user历史记录中看过的item相似的item返回界面展示
简单说,就是根据用户历史行为,找其历史记录中相似的item。
根据项亮《动态推荐系统关键技术研究》的分类方式,可以根据使用数据来把推荐技术分成以下两类:
1.按使用数据分类:
协同过滤
内容过滤
社会化过滤
基于人口信息的过滤
机遇地理信息的推荐
2.按模型分类:
领域模型
矩阵分解模型
图模型
受限于数据获得的难易程度,一般用户行为数据较为容易获取,所以也导致协同过滤相关推荐算法的流行。
项亮表示,凡是使用了用户行为数据进行运算的都可以归类为协同过滤算法,经典的有user-based协同过滤和item-based协同过滤。
亚马逊把item-based算法发扬光大,它优点是效果不错,而且可以做推荐解析。
但每一种推荐算法,都有其适用场合,所以目前成熟的推荐系统,几本都属于混合型推荐系统。混合型推荐系统的核心思想,是融合多种推荐算法,使其取长补短。
《Hybrid Recommender Systems Survey and Experiments》这篇论文对混合推荐系统做了研究,列出了推荐系统的混合方式:
Weighted 加权融合
Switching 开关切换融合
Mixed 混合融合
Cascade 串联融合
Feature combination 特征组合融合
Feature augmentation 特征增益融合
Meta-level
推荐系统的开发框架,以下摘自《推荐系统实践》
一个推荐系统,一般分为离线部分、在线部分。而其中的“推荐解释”模块,则并不是每个算法都适合,有些算法是做不了推荐解释的,例如基于矩阵分解的推荐算法。
以下是我们的推荐系统架构图
由离线层、半实时层、实时层构成。由于要处理大数据,一般使用的技术都是hadoop、spark、hbase、storm、redis、mahout等。
以item-based协同过滤为例,一般整个个性化推荐的流程如下:
1. 读取用户行为数据,进行抽取清理
2. 根据清理后的行为数据,算出任意两两item的相似度
3. 根据业务需要,截取N个与某item最相似的相关item,写入持久化存储,例如hbase
4. 上层web程序,根据user的历史观看记录,找出3中算好的与user历史记录中看过的item相似的item返回界面展示
简单说,就是根据用户历史行为,找其历史记录中相似的item。