Logstash+ElasticSearch+Kibana日志分析系统
线上需求:
处理nginx的访问access日志和商城的搜索历史记录。(由于访问量不大、没有用到redis或者其他消息队列)。
之前做的一个版本使用solrcloud做电商搜索引擎、elasticsearch做实时日志系统。
参考文档资料:
http://elasticsearch.cn/ medcl的中文社区
http://kibana.logstash.es/ELK stack 中文指南
https://www.elastic.co/downloads/elasticsearch elasticsearch官网
准备好这logstash、elasticsearch、kibana的最新安装包。。最好去官网下载。安装jdk7+
Elasticsearch
elasticsearch VS solr
Elasticsearch相对于solr来讲,更加的适合大数据实时性处理。相对于solr:
一:ES 对实时索引的情况下,es的效率远远高于solr的效率。当实时建立索引时solr会产生IO 堵塞
二: 随着数据量的增长。ES 的效率高于solr
三: ES 用动态mapping来取代 solr的 schema.xml,更加容易提供动态结构化
基于此。用es来更加适合处理大数据实时性处理。
当然 solr对于ES来讲:
solr有着一个庞大的用户群,成熟稳定。
Solr 是传统搜索应用的有力解决方案,特别是电商等传统搜索领域 (lucene的VSM算法,加上Solr的edismax的 bf函
数)。但 Elasticsearch 更适用于新兴的实时大数据搜索应用。
安装elasticsearch:
解压后得到如图。
![]()
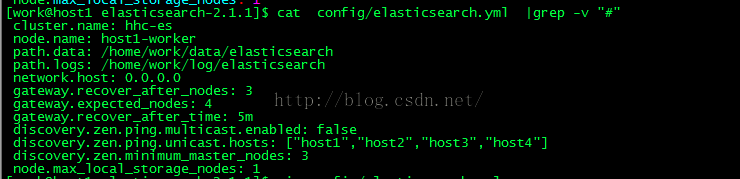
开发环境准备了4台机器 。分别 host1、
host2、host3、host4。修改config 下面的elasticsearch.yml
我采取的配置为
之后4台机器分别启动es
bin/elasticsearch -d
测试:
对应lucene版本 5.3.1
准备好线上环境的nginx及其日志
先配置nginx的日志输出格式log_format 为json的输出格式。如果kibana有大的访问业务需求。 把kibana也配置到nginx中去
log_format json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"agent":"$http_user_agent",'
'"status":"$status"}';
Logstash
logstash作用

-结构化日志内容
-标准化日志时间
解压logstash
unzip logstash-2.1.1.zip
在 logstash安装目录下面新建conf目录, 新建logstash_nginx.conf 。
input{
file{
type=>"nginx_access"
path=>["/home/work/log/nginx/*.access.log"]
exclude=>"*.gz"
codec => json
}
}
filter {
mutate {
split => [ "upstreamtime", "," ]
}
mutate {
convert => [ "upstreamtime", "float" ]
}
}
output{
elasticsearch{
hosts=>[
"host1:9200",
"host2:9200",
"host3:9200",
"host4:9200"
]
index=>"access-%{+YYYY.MM.dd}"
}
}
input 的type对应elasticsearch的type
output 的type对应elasticsearch的index 名称
先执行测试一下logstash读取的配置文件语法是否正常解析,如果看到configuraion ok 说明正常解析
bin/logstash -t -f conf/logstash_nginx.conf
生产环境下你可以通过 以下命令 命令来统一存储日志。
bin/logstash -l ~/log/logstash/logstash.log
开始后台 执行logstash 处理nginx日志
nohup bin/logstash -l ~/log/logstash/logstash.log -f conf/*.conf &
在启动客户端中 用jobs 命令可以查看后台进程。或者采用查看
ps -ef |grep logstash
kibana
这玩意 是基于elasticsearch的可视化工具,采用html5实现,效果相当绚。同样 也不需要安装直接解压用
tar -zxvf kibana-4.3.1-linux-x64.tar.gz
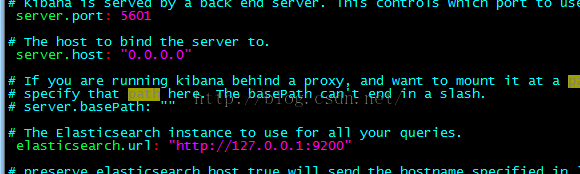
vi config/kibana.yml
简单关联配置elasticsearch
启动
nohup bin/kibana &就可以在 访问其界面了
