第2章
delete /path
Deletes the znode /path
exists /path
Checks whether /path exists
setData /path data
Sets the data of znode /path to data
getData /path
Returns the data in /path
getChildren /path
Returns the list of children under /path
![]()
![]()
![]()
简介
ZK提供了一些简单的操作原语,对于具体的案例实现,需要自己实现,比如分布式锁。这里的案例称为recipe
ZK的数据以tree来展示,每个节点成为znode
ZK提供的操作原语:
create /path data
Creates a znode named with /path and containing data
Creates a znode named with /path and containing data
delete /path
Deletes the znode /path
exists /path
Checks whether /path exists
setData /path data
Sets the data of znode /path to data
getData /path
Returns the data in /path
getChildren /path
Returns the list of children under /path
后续会关注对应的watcher
znode的类型
1. 持久
只能通过delete api去删除
2. 临时
session过期 或者 关闭,临时节点会删除。
临时节点只能是叶子节点。
[zk: localhost:2181(CONNECTED) 0] create -e /master ""
Created /master
[zk: localhost:2181(CONNECTED) 1] create -e /master/hahah ""
Ephemerals cannot have children: /master/hahah
Created /master
[zk: localhost:2181(CONNECTED) 1] create -e /master/hahah ""
Ephemerals cannot have children: /master/hahah
3. 持久+顺序
4. 临时+顺序
Watch 和 Notification
轮询的坏处:
1. 延迟性不好控制
2. 服务端的压力
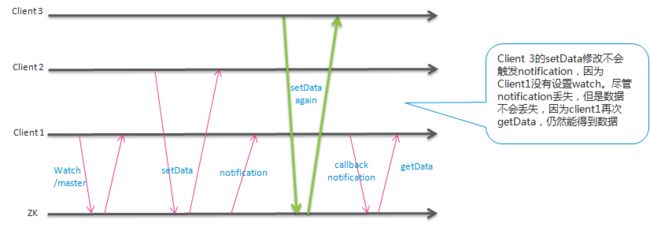
客户端设置watch,在watch对象满足条件时,客户端可以接收到notification,而一次watch只能接受到一次notification,如果要继续监控,需要重新设置wath。(one shot operation)
因为one shot的原因,客户端接到一次notification,到 再次watch之间,可能zk上再次发生了节点变化,这时候,客户端是不会感知到的。
除非客户端重新发起 操作,比如getData,才能获取到新的数据。 模式变为:
notification code:
case OK:
String data = getData("/master", true); // sets the watch
-- 此处被notified,但是在这个过程中,可能/master节点又发生了变化,会丢失变化通知,但是数据不会丢失,因为我们会调用getData获取数据
画了示意图:
这里提到一点: ZK会保证一点, notification如果触发,会先通知给客户端,然后才会进行同一个节点后续的更改,即使2次更改是连续的
另外,在重连的情况下,watch是会被重新携带到新的zk service的, 此时如果 zk servic发生过相应的改变,则立刻触发notification;如果未变化,则自动注册上watch进行监听。
通过代码可以看到, 在重连时,会携带客户端的watch 到zk service:
if (!disableAutoWatchReset) {
List<String> dataWatches = zooKeeper.getDataWatches();
List<String> existWatches = zooKeeper.getExistWatches();
List<String> childWatches = zooKeeper.getChildWatches();
if (!dataWatches.isEmpty()
|| !existWatches.isEmpty() || !childWatches.isEmpty()) {
SetWatches sw = new SetWatches(lastZxid,
prependChroot(dataWatches),
prependChroot(existWatches),
prependChroot(childWatches));
RequestHeader h = new RequestHeader();
h.setType(ZooDefs.OpCode.setWatches);
h.setXid(-8);
Packet packet = new Packet(h, new ReplyHeader(), sw, null, null);
outgoingQueue.addFirst(packet);
}
}
List<String> dataWatches = zooKeeper.getDataWatches();
List<String> existWatches = zooKeeper.getExistWatches();
List<String> childWatches = zooKeeper.getChildWatches();
if (!dataWatches.isEmpty()
|| !existWatches.isEmpty() || !childWatches.isEmpty()) {
SetWatches sw = new SetWatches(lastZxid,
prependChroot(dataWatches),
prependChroot(existWatches),
prependChroot(childWatches));
RequestHeader h = new RequestHeader();
h.setType(ZooDefs.OpCode.setWatches);
h.setXid(-8);
Packet packet = new Packet(h, new ReplyHeader(), sw, null, null);
outgoingQueue.addFirst(packet);
}
}
Version
每个节点都有version的属性,更新都会提高版本。
ZK的API的操作,都有基于version的条件操作,这可以作为一种并发数据的修改方法。
ZK Quorums
先说ZK集群
假设ZK集群中有5台机器
1. 客户端发送一个数据写请求(包括create、delete和setData)等,什么时候应该返回给客户端,ZK集群已经存储成功?
如果等ZK集群的5台所有机器都存储成功,会导致客户端等待的时间过长。 这里只要ZK Quorums的机器存储成功,即可返回。
2. ZK Quorums是什么
姑且就认为是为了解决脑裂问题引入的吧, 防止数据不丢失,为集群能正常工作的最小ZK数量,一般为 N/2+1,其中N为集群数
Session演示
其实与一般的会话建立是一样的过程:
1. 建立TCP连接
2. 建立会话
如果会话成功,客户端会收到
SyncConnected的通知
zkCli.sh:
2016-01-06 18:16:08,263 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@67ad77a7
Welcome to ZooKeeper!
JLine support is enabled
2016-01-06 18:16:08,348 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (java.lang.SecurityException: Unable to locate a login configuration)
2016-01-06 18:16:08,379 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2016-01-06 18:16:08,401 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x152172efbb90002, negotiated timeout = 20000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
Welcome to ZooKeeper!
JLine support is enabled
2016-01-06 18:16:08,348 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (java.lang.SecurityException: Unable to locate a login configuration)
2016-01-06 18:16:08,379 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2016-01-06 18:16:08,401 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x152172efbb90002, negotiated timeout = 20000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
zkServer.sh:
2016-01-06 18:16:08,369 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@197] - Accepted socket connection from /127.0.0.1:42870
2016-01-06 18:16:08,388 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@868] - Client attempting to establish new session at /127.0.0.1:42870
2016-01-06 18:16:08,395 [myid:] - INFO [SyncThread:0:ZooKeeperServer@617] - Established session 0x152172efbb90002 with negotiated timeout 20000 for client /127.0.0.1:428
2016-01-06 18:16:08,388 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@868] - Client attempting to establish new session at /127.0.0.1:42870
2016-01-06 18:16:08,395 [myid:] - INFO [SyncThread:0:ZooKeeperServer@617] - Established session 0x152172efbb90002 with negotiated timeout 20000 for client /127.0.0.1:428
Session的生命周期
先说明造成生命周期转换的几个事件:
这里截取zk client lib的代码注释:
/**
* Enumeration of states the ZooKeeper may be at the event
*/
public enum KeeperState
/** The client is in the connected state - it is connected
* to a server in the ensemble (one of the servers specified
* in the host connection parameter during ZooKeeper client
* creation). */
SyncConnected (3),
/** The client is in the disconnected state - it is not connected
* to any server in the ensemble. */
Disconnected (0),
/** The serving cluster has expired this session. The ZooKeeper
* client connection (the session) is no longer valid. You must
* create a new client connection (instantiate a new ZooKeeper
* instance) if you with to access the ensemble. */
Expired (-112);
* Enumeration of states the ZooKeeper may be at the event
*/
public enum KeeperState
/** The client is in the connected state - it is connected
* to a server in the ensemble (one of the servers specified
* in the host connection parameter during ZooKeeper client
* creation). */
SyncConnected (3),
/** The client is in the disconnected state - it is not connected
* to any server in the ensemble. */
Disconnected (0),
/** The serving cluster has expired this session. The ZooKeeper
* client connection (the session) is no longer valid. You must
* create a new client connection (instantiate a new ZooKeeper
* instance) if you with to access the ensemble. */
Expired (-112);
这几个事件会在ZooKeeper的watch中处理。
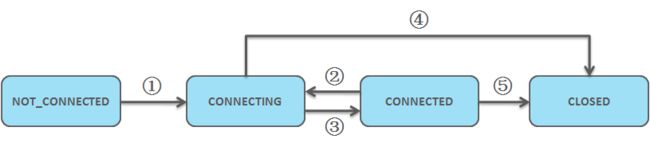
结合上图:
SyncConnected : 触发CONNECTED状态,对应3
Disconnected : 触发CONNECTING状态,对应2
Expired:触发CLOSED状态,对应5
这里要强调Expired事件: 这个事件只能由服务端触发,客户端无法触发。
也就是说:如果Session建立,服务端宕机,即使宕机半小时后启动成功,客户端的Session仍然是有效的,因为服务端并不认为Session过期。
We have this behavior because the ZooKeeper ensemble is the one responsible for declaring a session expired, not the client. Until the client hears that a ZooKeeper session has expired,
the client cannot declare the session expired. The client may
choose to close the session, however.
choose to close the session, however.
再演示Session过期的事件,是通过在eclipse中挂起所有线程的方式(如果运行时,可以通过HSDB等工具),来使得客户端不发送心跳,最终服务端会认为Session过期。
同样,如果把服务端挂起,客户段也会发现 会话问题, 会触发
Disconnected 事件
会话重连
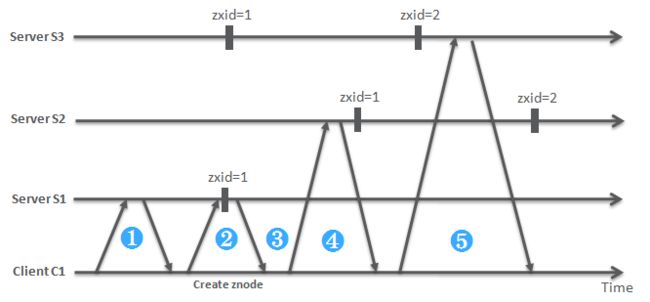
在集群模式下,如何选择重连的zookeeper service? 规则随意,但是有一点很重要。
因为集群之间的数据复制存在延迟,客户端在重连时,一定会选择一个zk zxid > client zxid的zk服务器
通过代码发现,客户端的zk库里,有一个: private volatile long lastZxid;
在发起会话时,会携带给服务端:
ConnectRequest conReq = new ConnectRequest(0, lastZxid,
sessionTimeout, sessId, sessionPasswd);
sessionTimeout, sessId, sessionPasswd);
其中lastZxid的声明: private long lastZxidSeen; 看见Seen了吧,意思很明显。
如示意图, 如果client C1 重连S2时,发现S2的zxid < 1,因此不会重连S2,而是再去连接S3