6款优秀的免费OCR软件
OCR 是英文Optical Character Recognition的缩写,意思为光学字符识别,通称为文字识别,它的工作原理为通过扫描仪或数码相机等光学输入设备获取纸张上的文字图片信息,利用各种模式识别算法分析文字形态特征,判断出汉字的标准编码,并按通用格式存储在文本文件中,由此可以看出,OCR实际上是让计算机认字,实现文字自动输入。它是一种快捷、省力、高效的文字输入方法。
光学字符识别(OCR)软件,将所扫描的图像转换成PDF和Word等可编辑和可搜索的文档格式。在文档的转换过程中,OCR软件技术主要用来分析和比较带有数据库中所存字体的文档。虽然,OCR软件的识别准确率不可能达到100%,但是一些OCR软件包含拼写检查功能,可查出无法辨认的字。
本文对多款常用OCR软件的性能进行了多角度的对比,希望为用户在选择和使用OCR软件时候提供一些实用性参考。
OCR使用云脉Docs Matter
作为偶尔使用的基本的OCR 工作,云脉Docs Matter的光学字符识别功能可以节省不少时间。
你可能忽略了它…叫做从图片中复制文本
[img]

[/img]
·将一个扫描或者保存的图片拖拽到云脉Docs Matter。你也可以试用Docs Matter导入功能将图片导入到Docs Matter。
·点击工具栏上的OCR转换按钮,就完成图片文字提取步骤,你可以将文字文字识别结果粘帖到像Word或记事本之类的任何程序。
云脉Docs Matter很好用,而且识别速度快,但是对于手写字符甚至模糊的字符识别不太理想。不过对于快速的任务,我非常支持云脉Docs Matter的剪辑和粘帖。
SimpleOCR
我使用微软的工具进行手写体识别时遇到的困难,可以在 SimpleOCR 找到可能的解决方案。不过这款软件对于手写体的识别只提供14天的免费试用,尽管机器打印的识别没有任何限制。

• 这款软件可以设置直接从扫描仪读取或者通过添加页面(jpg、tiff、bmp 格式)。
• SimpleOCR 在转换过程提供一些控制,包括文本选择、图片选择和文本忽略等功能。
• 转换到文本时提供一个 确认阶段:用户可以使用一个内置的拼写检查工具对不符的地方进行更正。
• 转换后的文件可以保存为 doc 或 txt 格式。
SimpleOCR 对于通常的文本工作良好,但处理多个列的布局时会有所衰落。据我看来,微软的工具从精确度上来说要好于 SimpleOCR。
TopOCR
我正在说的才刚刚开始呢!TopOCR,与典型的 OCR 软件有所不同,是专为数码相机(至少300万像素)和带有摄像头的手机设计。就像 SimpleOCR,它有两个窗口界面--原始图像窗口和文本窗口。

左侧窗口中从相机或扫描仪获取的图片转换为右侧窗口里面的文本格式。文本编辑器的功能很像写字板程序,可以使用微软的 文本转换语音 引擎。
• 这款软件支持 JPEG、TIFF、GIF 和 BMP 格式。
• 对图片进行亮度、色彩、对比度、去斑点、锐化等设置,可以提高图片的可读性。
• 可以配置相机过滤设置来增强图片。
• 转换后的文件可以保存为多种格式 – PDF、RTF、HTML 和 TXT 。
• TopOCR 对于简单文本运行良好,不过对于多列文本通常会失效。
• 这款软件对于混合页面(文本加图片)识别良好,并且只处理文本部分。
• 这款软件可以处理11种语言。
如何使相机读取取得最好的效果请阅读 如何使用 TopOCR 获得最好的效果。
FreeOCR
这款免费的 OCR 软件使用 Tesseract OCR 引擎。 Tesseract OCR 代码于1985到1995年间由惠普实验室开发,现在输入 Google。它被认为是最精确的开源 OCR 引擎之一。FreeOCR 是其底层代码的一个简单 Windows 界面。

• 它支持多种图片格式和多页面 TIFF 文件。
• 它可以处理 PDF 格式,并且兼容 TWAIN 设备比如扫描仪。
• FreeOCR 也有熟悉额双窗口界面以及容易理解的设置项。
• 在开始一键转换过程之前,可以调整图片的对比度增强可读性。
FreeOCR (v.2.03) 需要.Net 2.0 framework 支持。软件兼容 Windows XP/Vista,大小为 4.38MB,也可以从备选站点下载。
免费的 OCR 工具有它们自己的局限性。扫描图片也有清晰度、对比度以及字体清除的问题。
从一个普通用户的角度来看,100% OCR 精确度仍然是白日做梦。
尽管这些免费的工具处理打印文本足够了,但却不能处理一般潦草的手写文本。我个人喜欢使
用上述两款微软的产品作为辅助的 OCR 工具。
OCR 使用微软 OneNote 2007
作为偶尔使用的基本的 OCR 工作,微软 OneNote 的光学字符识别功能可以节省不少时间。

• 将一个扫描或者保存的图片拖拽到 OneNote。你也可以使用 OneNote 剪辑 部分屏幕或者图片到 OneNote。
• 右击插入的图片选择 从图片中复制文本 。复制下来的识别文本保存到剪切板中,你可以粘贴到像 Word 或记事本之类的任何程序。
OneNote 非常的建议。但是它对于手写字符或者甚至模糊的字符识别不太理想。不过对于快速的任务,我非常支持 OneNote 的剪辑和粘贴。
OCR使用微软Office Document Imaging
另一个微软Office 家族中不常用的工具。它就在 开始 - 所有程序 – Microsoft Office –Microsoft Office 工具 – Microsoft Office Document Imaging.

使用 document imaging 工具进行 OCR 识别很悠闲,因为它只接受 TIFF (或者 MDI ) 格式。不过那并不太麻烦,因为任何图形应用程序都可以将图片转换为 TIFF。在下面的截图中,我使用微软画图板程序将 JPEG 转换为 TIFF。
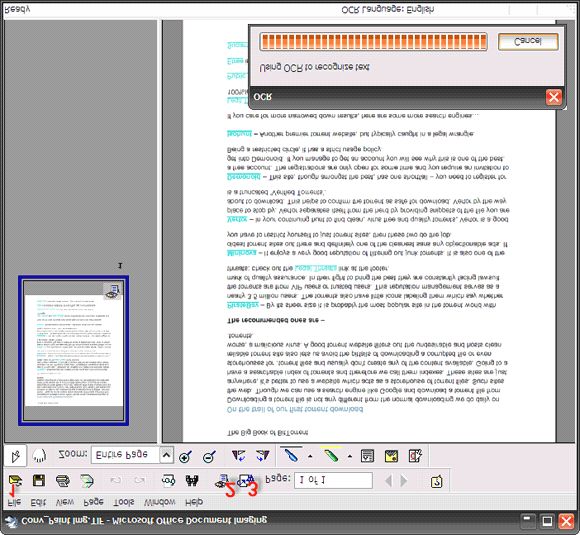
• 在程序中打开文件 Microsoft Office Document Imaging – 文件 – 打开 。
• 点击那个小眼睛图标 – 使用 OCR 识别文本 。
• 点击 MS Word 图标 – 将文本发送到 Word 。
• 自动打开一个含有可编辑转换文本的 MS Word 文件。
• 另外,你也可以使用画图板程序选择特定区域并复制到剪切板,打开 MS Office
Document Imaging – 选择页面 –粘贴页面并复制选择部分进行OCR识别。
再次,MODI 处理印刷文本很不错,不过我的手写文本却遇到了“OCR 已执行但不能识别提交的文本”。当然,你可以试试自己的手写体。
那么,现在让我们离开微软家族,看看3款免费的称自己为OCR的软件…
光学字符识别(OCR)软件,将所扫描的图像转换成PDF和Word等可编辑和可搜索的文档格式。在文档的转换过程中,OCR软件技术主要用来分析和比较带有数据库中所存字体的文档。虽然,OCR软件的识别准确率不可能达到100%,但是一些OCR软件包含拼写检查功能,可查出无法辨认的字。
本文对多款常用OCR软件的性能进行了多角度的对比,希望为用户在选择和使用OCR软件时候提供一些实用性参考。
OCR使用云脉Docs Matter
作为偶尔使用的基本的OCR 工作,云脉Docs Matter的光学字符识别功能可以节省不少时间。
你可能忽略了它…叫做从图片中复制文本
[img]
[/img]
·将一个扫描或者保存的图片拖拽到云脉Docs Matter。你也可以试用Docs Matter导入功能将图片导入到Docs Matter。
·点击工具栏上的OCR转换按钮,就完成图片文字提取步骤,你可以将文字文字识别结果粘帖到像Word或记事本之类的任何程序。
云脉Docs Matter很好用,而且识别速度快,但是对于手写字符甚至模糊的字符识别不太理想。不过对于快速的任务,我非常支持云脉Docs Matter的剪辑和粘帖。
SimpleOCR
我使用微软的工具进行手写体识别时遇到的困难,可以在 SimpleOCR 找到可能的解决方案。不过这款软件对于手写体的识别只提供14天的免费试用,尽管机器打印的识别没有任何限制。
• 这款软件可以设置直接从扫描仪读取或者通过添加页面(jpg、tiff、bmp 格式)。
• SimpleOCR 在转换过程提供一些控制,包括文本选择、图片选择和文本忽略等功能。
• 转换到文本时提供一个 确认阶段:用户可以使用一个内置的拼写检查工具对不符的地方进行更正。
• 转换后的文件可以保存为 doc 或 txt 格式。
SimpleOCR 对于通常的文本工作良好,但处理多个列的布局时会有所衰落。据我看来,微软的工具从精确度上来说要好于 SimpleOCR。
TopOCR
我正在说的才刚刚开始呢!TopOCR,与典型的 OCR 软件有所不同,是专为数码相机(至少300万像素)和带有摄像头的手机设计。就像 SimpleOCR,它有两个窗口界面--原始图像窗口和文本窗口。
左侧窗口中从相机或扫描仪获取的图片转换为右侧窗口里面的文本格式。文本编辑器的功能很像写字板程序,可以使用微软的 文本转换语音 引擎。
• 这款软件支持 JPEG、TIFF、GIF 和 BMP 格式。
• 对图片进行亮度、色彩、对比度、去斑点、锐化等设置,可以提高图片的可读性。
• 可以配置相机过滤设置来增强图片。
• 转换后的文件可以保存为多种格式 – PDF、RTF、HTML 和 TXT 。
• TopOCR 对于简单文本运行良好,不过对于多列文本通常会失效。
• 这款软件对于混合页面(文本加图片)识别良好,并且只处理文本部分。
• 这款软件可以处理11种语言。
如何使相机读取取得最好的效果请阅读 如何使用 TopOCR 获得最好的效果。
FreeOCR
这款免费的 OCR 软件使用 Tesseract OCR 引擎。 Tesseract OCR 代码于1985到1995年间由惠普实验室开发,现在输入 Google。它被认为是最精确的开源 OCR 引擎之一。FreeOCR 是其底层代码的一个简单 Windows 界面。
• 它支持多种图片格式和多页面 TIFF 文件。
• 它可以处理 PDF 格式,并且兼容 TWAIN 设备比如扫描仪。
• FreeOCR 也有熟悉额双窗口界面以及容易理解的设置项。
• 在开始一键转换过程之前,可以调整图片的对比度增强可读性。
FreeOCR (v.2.03) 需要.Net 2.0 framework 支持。软件兼容 Windows XP/Vista,大小为 4.38MB,也可以从备选站点下载。
免费的 OCR 工具有它们自己的局限性。扫描图片也有清晰度、对比度以及字体清除的问题。
从一个普通用户的角度来看,100% OCR 精确度仍然是白日做梦。
尽管这些免费的工具处理打印文本足够了,但却不能处理一般潦草的手写文本。我个人喜欢使
用上述两款微软的产品作为辅助的 OCR 工具。
OCR 使用微软 OneNote 2007
作为偶尔使用的基本的 OCR 工作,微软 OneNote 的光学字符识别功能可以节省不少时间。
• 将一个扫描或者保存的图片拖拽到 OneNote。你也可以使用 OneNote 剪辑 部分屏幕或者图片到 OneNote。
• 右击插入的图片选择 从图片中复制文本 。复制下来的识别文本保存到剪切板中,你可以粘贴到像 Word 或记事本之类的任何程序。
OneNote 非常的建议。但是它对于手写字符或者甚至模糊的字符识别不太理想。不过对于快速的任务,我非常支持 OneNote 的剪辑和粘贴。
OCR使用微软Office Document Imaging
另一个微软Office 家族中不常用的工具。它就在 开始 - 所有程序 – Microsoft Office –Microsoft Office 工具 – Microsoft Office Document Imaging.
使用 document imaging 工具进行 OCR 识别很悠闲,因为它只接受 TIFF (或者 MDI ) 格式。不过那并不太麻烦,因为任何图形应用程序都可以将图片转换为 TIFF。在下面的截图中,我使用微软画图板程序将 JPEG 转换为 TIFF。
• 在程序中打开文件 Microsoft Office Document Imaging – 文件 – 打开 。
• 点击那个小眼睛图标 – 使用 OCR 识别文本 。
• 点击 MS Word 图标 – 将文本发送到 Word 。
• 自动打开一个含有可编辑转换文本的 MS Word 文件。
• 另外,你也可以使用画图板程序选择特定区域并复制到剪切板,打开 MS Office
Document Imaging – 选择页面 –粘贴页面并复制选择部分进行OCR识别。
再次,MODI 处理印刷文本很不错,不过我的手写文本却遇到了“OCR 已执行但不能识别提交的文本”。当然,你可以试试自己的手写体。
那么,现在让我们离开微软家族,看看3款免费的称自己为OCR的软件…