概述
检索数据时的 2 个问题:
1) 不浪费内存:当 Hibernate 从数据库中加载 Customer 对象时, 如果同时加载所有关联的 Order 对象, 而程序实际上仅仅需要访问 Customer 对象, 那么这些关联的 Order 对象就白白浪费了许多内存.
2) 更高的查询效率:发送尽可能少的 SQL 语句
模型

1. 域模型
package org.rabbitx.hibernate4.searchstrategy;
public class Order {
private Integer id;
private Integer no;
//在many端添加one端的引用来构造many-to-one关联关系
private Customer customer;
setter,getter...
}
package org.rabbitx.hibernate4.searchstrategy;
import java.util.HashSet;
import java.util.Set;
public class Customer {
private Integer id;
private String name;
//在one端添加many端的集合类型来构造one-to-many关联关系
//1. 声明集合类型时, 需使用接口类型, 因为 hibernate 在获取集合类型时, 返回的是 Hibernate 内置的集合类型, 而不是 JavaSE 一个标准的集合实现.
//2.需要把集合进行初始化,防止发生空指针异常
private Set<Order> orders = new HashSet<>();
setter,getter...
}
2. 映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.rabbitx.hibernate4.searchstrategy">
<class name="Order" table="TBL_SEARCH_STRATEGY_ORDER">
<id name="id" type="java.lang.Integer">
<column name="ID" />
<generator class="native" />
</id>
<property name="no" type="java.lang.Integer">
<column name="NO" />
</property>
<!--
使用 many-to-one 来映射多对一的关联关系
name: many端类中关联one端的属性的名字,此值与many端中属性名一致
class: many端类中关联one端的属性的类型,此值与many端中属性类型一致
column: many端数据表中关联one端的外键的名字,此值自定义
-->
<many-to-one name="customer" class="Customer" column="customer_id"></many-to-one>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.rabbitx.hibernate4.searchstrategy">
<class name="Customer" table="TBL_SEARCH_STRATEGY_CUSTOMER" lazy="true">
<id name="id" type="java.lang.Integer">
<column name="ID" />
<generator class="native" />
</id>
<property name="name" type="java.lang.String">
<column name="NAME" />
</property>
<!--
使用 one-to-many 来映射一对多的关联关系
set: 映射 set 类型的属性
table: set 中的元素对应的记录放在哪一个数据表中. 该值需要和多对一的多的那个表的名字一致
inverse: 指定由哪一方来维护关联关系. 通常设置为 true, 以指定由多的一端来维护关联关系
cascade 设定级联操作. 开发时不建议设定该属性. 建议使用手工的方式来处理
order-by 在查询时对集合中的元素进行排序, order-by 中使用的是表的字段名, 而不是持久化类的属性名
-->
<set name="orders" table="TBL_SEARCH_STRATEGY_ORDER" inverse="true">
<!--
many端表的外键列名
即Order.hbm.xml文件中:<many-to-one name="customer" class="Customer" column="customer_id"></many-to-one> 节点column的值
-->
<key column="customer_id"></key>
<!-- 指定映射类型:因为在many-to-many中也使用到set类型,需要此设置来区分。 -->
<one-to-many class="Order"/>
</set>
</class>
</hibernate-mapping>
3. hibernate配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 配置连接数据库的基本信息 -->
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://192.168.1.105:3306/hibernate4</property>
<!-- 配置hibernate基本信息 -->
<!-- 配置数据库方言 -->
<property name="dialect">org.hibernate.dialect.MySQLInnoDBDialect</property>
<!-- 执行操作时是否在控制台打印 SQL -->
<property name="show_sql">true</property>
<!-- 是否对 SQL 进行格式化 -->
<property name="format_sql">true</property>
<!-- 指定自动生成数据表的策略 -->
<property name="hbm2ddl.auto">update</property>
<!-- 设置隔离级别 :1. READ UNCOMMITED 2. READ COMMITED 4. REPEATABLE READ 8. SERIALIZEABLE-->
<property name="hibernate.connection.isolation">4</property>
<!-- 配置c3p0数据源 -->
<!-- 数据库连接池的最大连接数 -->
<property name="hibernate.c3p0.max_size">100</property>
<!-- 数据库连接池的最小连接数 -->
<property name="hibernate.c3p0.min_size">10</property>
<!-- 当数据库连接池中的连接耗尽时, 同一时刻获取多少个数据库连接-->
<property name="hibernate.c3p0.acquire_increment">10</property>
<!-- 数据库连接池中连接对象在多长时间没有使用过后,就应该被销毁 -->
<property name="hibernate.c3p0.timeout">1800</property>
<!--
表示连接池检测线程多长时间检测一次池内的所有链接对象是否超时.
连接池本身不会把自己从连接池中移除,而是专门有一个线程按照一定的时间间隔来做这件事,
这个线程通过比较连接对象最后一次被使用时间和当前时间的时间差来和 timeout 做对比,进而决定是否销毁这个连接对象。
-->
<property name="hibernate.c3p0.idle_test_period">1800</property>
<!-- 缓存 Statement 对象的数量 -->
<property name="hibernate.c3p0.max_statements">10</property>
<!-- 设定 JDBC 的 Statement 读取数据的时候每次从数据库中取出的记录条数 -->
<property name="hibernate.jdbc.fetch_size">100</property>
<!-- 设定对数据库进行批量删除,批量更新和批量插入的时候的批次大小 -->
<property name="jdbc.batch_size">30</property>
<!-- 指定关联的 .hbm.xml 文件 -->
<mapping resource="org/rabbitx/hibernate4/searchstrategy/Customer.hbm.xml"/>
<mapping resource="org/rabbitx/hibernate4/searchstrategy/Order.hbm.xml"/>
</session-factory>
</hibernate-configuration>
4. 添加数据
package org.rabbitx.hibernate4.searchstrategy;
import java.util.List;
import org.hibernate.Query;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import org.hibernate.service.ServiceRegistry;
import org.hibernate.service.ServiceRegistryBuilder;
import org.junit.After;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
/**
*
* @author RabbitX
*/
public class SearchStrategyJUnitTest {
private static SessionFactory sessionFactory;
private static Session session;
private static Transaction transaction;
@BeforeClass
public static void beforeClass()
{
String cfgPath = "org/rabbitx/hibernate4/searchstrategy/hibernate.cfg.xml";
Configuration cfg = new Configuration().configure(cfgPath);
ServiceRegistry serviceRegistry = new ServiceRegistryBuilder().applySettings(cfg.getProperties()).buildServiceRegistry();
sessionFactory = cfg.buildSessionFactory(serviceRegistry);
session = sessionFactory.openSession();
}
@AfterClass
public static void afterClass()
{
sessionFactory.close();
}
@Before
public void before()
{
session = sessionFactory.openSession();
transaction = session.beginTransaction();
}
@After
public void after()
{
if(session.isOpen())
{
transaction.commit();
session.close();
}
}
/**
* 准备需要的数据
*/
@Test
public void testPrepareData()
{
Customer customer = new Customer("BluceLi");
Order order1 = new Order(100090001);
Order order2 = new Order(100090002);
Order order3 = new Order(100090003);
Order order4 = new Order(100090004);
Order order5 = new Order(100090005);
Order order6 = new Order(100090006);
Order order7 = new Order(100090007);
Order order8 = new Order(100090008);
Order order9 = new Order(100090009);
//设定关联关系
order1.setCustomer(customer);
order2.setCustomer(customer);
order3.setCustomer(customer);
order4.setCustomer(customer);
order5.setCustomer(customer);
order6.setCustomer(customer);
order7.setCustomer(customer);
order8.setCustomer(customer);
order9.setCustomer(customer);
customer.getOrders().add(order1);
customer.getOrders().add(order2);
customer.getOrders().add(order3);
customer.getOrders().add(order4);
customer.getOrders().add(order5);
customer.getOrders().add(order6);
customer.getOrders().add(order7);
customer.getOrders().add(order8);
customer.getOrders().add(order9);
session.save(customer);
session.save(order1);
session.save(order2);
session.save(order3);
session.save(order4);
session.save(order5);
session.save(order6);
session.save(order7);
session.save(order8);
session.save(order9);
}
}
类级别的检索策略
类级别可选的检索策略包括立即检索和延迟检索, 默认为延迟检索
-立即检索: 立即加载检索方法指定的对象
-延迟检索: 延迟加载检索方法指定的对象。在使用具体的属性时,再进行加载
类级别的检索策略可以通过 <class> 元素的 lazy 属性进行设置
如果程序加载一个对象的目的是为了访问它的属性, 可以采取立即检索.
如果程序加载一个持久化对象的目的是仅仅为了获得它的引用, 可以采用延迟检索。注意出现懒加载异常!
无论 <class> 元素的 lazy 属性是 true 还是 false, Session 的 get() 方法及 Query 的 list() 方法在类级别总是使用立即检索策略
若 <class> 元素的 lazy 属性为 true 或取默认值, Session 的 load() 方法不会执行查询数据表的 SELECT 语句, 仅返回代理类对象的实例, 该代理类实例有如下特征:
由 Hibernate 在运行时采用 CGLIB 工具动态生成
Hibernate 创建代理类实例时, 仅初始化其 OID 属性
在应用程序第一次访问代理类实例的非 OID 属性时, Hibernate 会初始化代理类实例
示例
/**
* 在Customer.hbm.xml文件中class节点不设置lazy属性时,默认值为true。
* <class name="Customer" table="TBL_SEARCH_STRATEGY_CUSTOMER" lazy="true">
* 在此设置下使用load方法检索数据时为延迟检索。
* 执行结果:
* 不发送SQL;
* 返回一个hibernate创建的代理对象(org.rabbitx.hibernate4.searchstrategy.Customer_$$_javassist_0);
*/
@Test
public void testClassLazy001()
{
Customer customer = (Customer) session.load(Customer.class, 1);
//返回结果:org.rabbitx.hibernate4.searchstrategy.Customer_$$_javassist_0
System.out.println(customer.getClass().getName());
System.out.println(customer.getId());
}
/**
* 配置:<class name="Customer" table="TBL_SEARCH_STRATEGY_CUSTOMER">
* 延迟检索情况下,在应用程序第一次访问代理类实例的非 OID 属性时, Hibernate 会初始化代理类实例
*/
@Test
public void testClassLazy002()
{
Customer customer = (Customer) session.load(Customer.class, 1);
System.out.println(customer.getName());
System.out.println(customer.getClass().getName());
}
/**
* 配置:<class name="Customer" table="TBL_SEARCH_STRATEGY_CUSTOMER" lazy="false">
* 立即检索情况下,立即检索数据,hibernate不再创建代理对象。
* 执行结果:
* 发送SQL;
* 返回原对象(org.rabbitx.hibernate4.searchstrategy.Customer);
*/
@Test
public void testClassLazy003()
{
Customer customer = (Customer) session.load(Customer.class, 1);
System.out.println(customer.getId());
//返回结果:org.rabbitx.hibernate4.searchstrategy.Customer
System.out.println(customer.getClass().getName());
}
/**
* 配置:<class name="Customer" table="TBL_SEARCH_STRATEGY_CUSTOMER">
* 使用get方法检索数据
* 执行结果:
* 发送SQL;
* 返回原对象(org.rabbitx.hibernate4.searchstrategy.Customer);
*/
@Test
public void testClassLazy004()
{
Customer customer = (Customer) session.get(Customer.class, 1);
System.out.println(customer.getId());
//返回结果:org.rabbitx.hibernate4.searchstrategy.Customer
System.out.println(customer.getClass().getName());
}
/**
* 配置:<class name="Customer" table="TBL_SEARCH_STRATEGY_CUSTOMER">
* 使用Query 的 list() 方法检索数据
* 执行结果:
* 发送SQL;
* 返回原对象(org.rabbitx.hibernate4.searchstrategy.Customer);
*/
@Test
@SuppressWarnings("unchecked")
public void testClassLazy005()
{
Query query = session.createQuery("from Customer");
List<Customer> customers = query.list();
System.out.println(customers);
}
一对多和多对多的检索策略
在映射文件中, 用 <set> 元素来配置一对多关联及多对多关联关系. <set> 元素有 lazy 和 fetch 属性
-lazy: 主要决定 orders 集合被初始化的时机. 即是在加载 Customer 对象时就被初始化, 还是在程序访问 ------orders 集合时被初始化
-fetch: 取值为 “select” 或 “subselect” 时, 决定初始化 orders 的查询语句的形式; 若取值为”join”, 则决定 orders 集合被初始化的时机
若把 fetch 设置为 “join”, lazy 属性将被忽略
-<set> 元素的 batch-size 属性:用来为延迟检索策略或立即检索策略设定批量检索的数量. 批量检索能减少 SELECT 语句的数目, 提高延迟检索或立即检索的运行性能.
<set> 元素的 lazy 和 fetch 属性
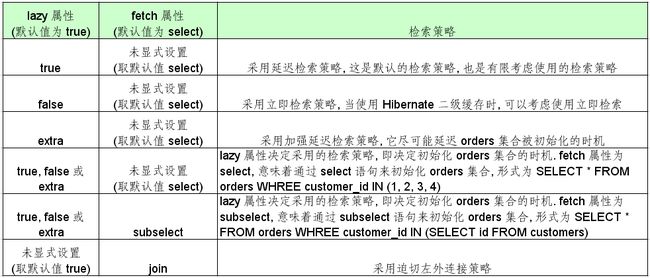
延迟检索和增强延迟检索
1) 在延迟检索(lazy 属性值为 true) 集合属性时, Hibernate 在以下情况下初始化集合代理类实例
-应用程序第一次访问集合属性: iterator(), size(), isEmpty(), contains() 等方法
-通过 Hibernate.initialize() 静态方法显式初始化
2) 增强延迟检索(lazy 属性为 extra): 与 lazy=“true” 类似. 主要区别是增强延迟检索策略能进一步延迟 Customer 对象的 orders 集合代理实例的初始化时机:
-当程序第一次访问 orders 属性的 iterator() 方法时, 会导致 orders 集合代理类实例的初始化
-当程序第一次访问 order 属性的 size(), contains() 和 isEmpty() 方法时, Hibernate 不会初始化 orders 集合类的实例, 仅通过特定的 select 语句查询必要的信息, 不会检索所有的 Order 对象
<set> 元素的 batch-size 属性
<set> 元素有一个 batch-size 属性, 用来为延迟检索策略或立即检索策略设定批量检索的数量. 批量检索能减少 SELECT 语句的数目, 提高延迟检索或立即检索的运行性能.
用带子查询的 select 语句整批量初始化 orders 集合(fetch 属性为 “subselect”)
1) <set> 元素的 fetch 属性: 取值为 “select” 或 “subselect” 时, 决定初始化 orders 的查询语句的形式; 若取值为”join”, 则决定 orders 集合被初始化的时机.默认值为 select
2) 当 fetch 属性为 “subselect” 时
-假定 Session 缓存中有 n 个 orders 集合代理类实例没有被初始化, Hibernate 能够通过带子查询的 select 语句, 来批量初始化 n 个 orders 集合代理类实例
-batch-size 属性将被忽略
-子查询中的 select 语句为查询 CUSTOMERS 表 OID 的 SELECT 语句
迫切左外连接检索(fetch 属性值设为 “join”)
当 fetch 属性为 “join” 时:
-检索 Customer 对象时, 会采用迫切左外连接(通过左外连接加载与检索指定的对象关联的对象)策略来检索所有关联的 Order 对象
-lazy 属性将被忽略
-Query 的list() 方法会忽略映射文件中配置的迫切左外连接检索策略, 而依旧采用延迟加载策略
多对一和一对一关联的检索策略
和 <set> 一样, <many-to-one> 元素也有一个 lazy 属性和 fetch 属性.

-若 fetch 属性设为 join, 那么 lazy 属性被忽略
-迫切左外连接检索策略的优点在于比立即检索策略使用的 SELECT 语句更少.
-无代理延迟检索需要增强持久化类的字节码才能实现
Query 的 list 方法会忽略映射文件配置的迫切左外连接检索策略, 而采用延迟检索策略
如果在关联级别使用了延迟加载或立即加载检索策略, 可以设定批量检索的大小, 以帮助提高延迟检索或立即检索的运行性能.
Hibernate 允许在应用程序中覆盖映射文件中设定的检索策略.
检索策略小结
类级别和关联级别可选的检索策略及默认的检索策略

3 种检索策略的运行机制

映射文件中用于设定检索策略的几个属性
