字符集
字符是各类文字,符号的总称,包括各国家文字,标点符号,图形符号,数字,非打印控制字符等。字符集就是字符的集合,不同字符集包含的字符范围是不一样的,所以不同字符集对字符的表达能力是有差异的。常见的字符集有ASCII,GBx,Big5,Unicode。
字符编码
计算机以二进制序列传输/存储数据,在字符保存之前需要先建立字符到数值的映射关系,这一过程叫做字符编码。比如ASCII约定字符 ’a’ = 0x61,当保存 ‘a’ 时,先从编码表得到数值0x61,然后再做相应保存,解码时也需要使用同一编码规则,否则就有可能因为编码规则不一致,导致解码失败(乱码)。
举例:新建一个文本文件,输入字符’a’,另存为ANSI格式(Windows简体中文系统下就是GBK),使用类似EditPlus工具查看十六进制序列(Hx),就可以发现实际保存的就是 0x61。
ASCII
早期较有名气的编码方式是摩斯编码(无间道里用的就是摩斯密码),通过定义图形符号到字母的映射在打字机(Electrical_telegraph/1816年)上传输,这需要电报员熟记编码表,是人工编码的时期。后来人们发现可以使用多个可开合的晶体管组成不同的状态,不同状态码代表不同的字母,一个状态单位就是bit,一组完整状态单位就是byte,先后产生了Baudot code(5 bits),TeleTypeSetter (TTS) code(6 bits) ,ASCII(7 bits), ISO 8859-n(8 bits)等不同长度的编码方式。下图为摩斯编码表:

ASCII颁布于1963年,使用7bit表示一个字符,可表示的数值范围是0-127,共128个字符,其中32-126为可打印字符,其余的是控制字符。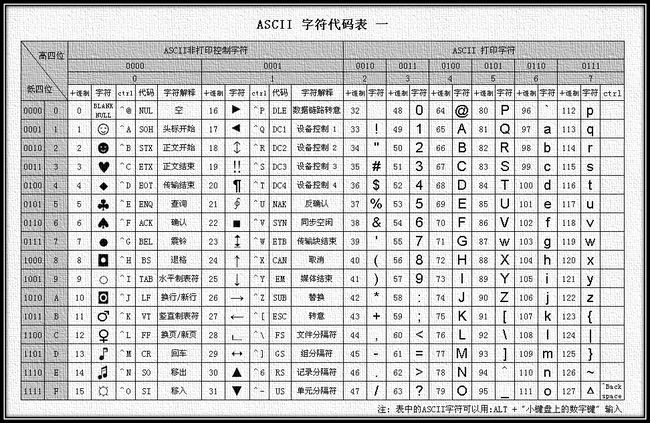
后来人们发现,ASCII对字符的表达能力非常有限,为了能描述更多的字符(如外来语,重音词,特殊拉丁符号等),启用8 bits 描述一个字符,使字符表达范围从128扩展到256个,称之为扩展ASCII(EASCII)。对高八位的启用ISO制定了标准号为ISO8859-n的一系列标准,广为流传的就是ISO8859-1(Latin 1)。
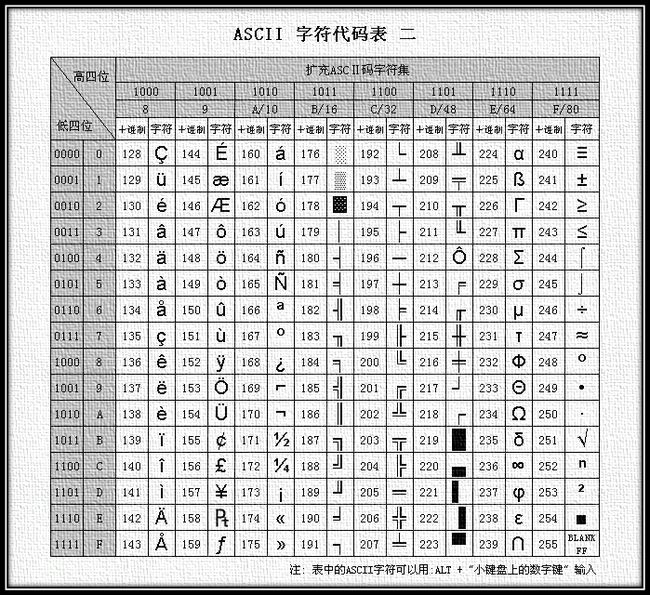
ANSI
ANSI(ANSI code pages),官方叫Windows code pages,是微软定义的一系列编码页(code pages),在1980-1990年广泛应用于Windows操作系统,制定这些编码页是为了解决地域语言处理问题,比如Code_page_936(简体中文),Code_page_950(繁体中文),可以把ANSI看成是Windows本地化编码,在简体中文中对应GBK,繁体中文系统代表Big5,日文系统代表Shift_JIS。
在简体中文的Windows操作系统里,ANSI用的是Code_page_936(CP936),页表随着国内标准升级而变化,早期兼容GB2312,后来支持GBK,严格来说CP936并不是完全兼容GBK的,但由于差异很小,所以大家都习惯在Windows下将ANSI(CP936)等同于GBK。
GB2312
计算机走进中国时,由于ASCII表示范围太窄,无法满足复杂的中文用语环境,于是在1980年颁布了GB2312-1980编码标准。GB2312收录6763个汉字,682个图形符号,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
GB2312共划分为94个区,每个区有94位,每一位对应一个字符,因此可以使用区位号对汉字进行编码,称为区位码。另外,GB2312还把原ASCII中的符号重编了,与ASCII重叠的符号就叫全角,原127号以下的称为半角。下图是GB2312部分编码表:
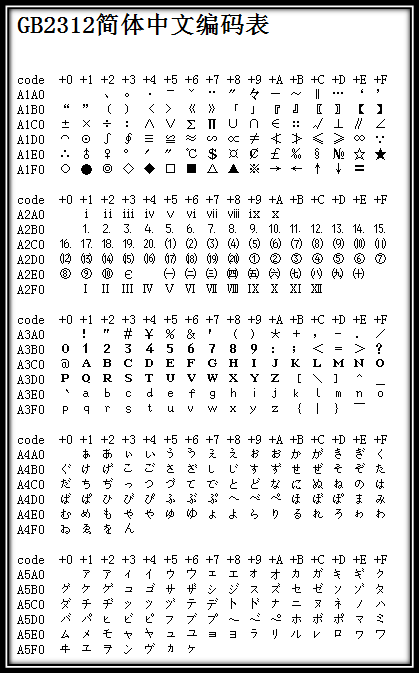
01-09区为特殊符号。
16-55区为一级汉字,按拼音排序。
56-87区为二级汉字,按部首/笔画排序。
10-15区及88-94区则未有编码。
GB2312对小于127的字节使用单字节表示,保持与ASCII一致,用两个大于127的字节表示一个汉字或符号,第一个字节称为高位字节(区字节0xA1-0xF7),第二个字节称为低位字节(位字节0xA1-0xFE)。
编码表规定了字符到编码点的映射,但并没有对传输序列做出要求,面向传输依赖具体的编码规则实现。通常使用EUC-CN编码规则实现从编码点(code point)到字节序列的映射,比如中文“啊”是表中第一个中文,位于16区,1位号,则高位字节是0xA0+16 = 0xB0,低位字节0xA0+1=0xA1,所以“啊”在EUC-CN的字节序列是 0xB0A1。
相对UTF-8而言,GB2312(EUC-CN)不需要使用预留位描述字符长度,所以就普通简体中文系统而言,传输/存储性能更好,国际化兼容性较差。
GBK
由于中文汉字非常庞大,GB2312对部分人名,罕见字依然无法处理,于是在1995年颁布了《汉字内码扩展规范》,即GBK。GBK使用了GB2312未使用的编码区,并将高位字节从0xA1-0xF7扩展为0x81-0xFE,低位字节从0xA1-0xFE扩展为0x40-0xFE(不包括0x7F):
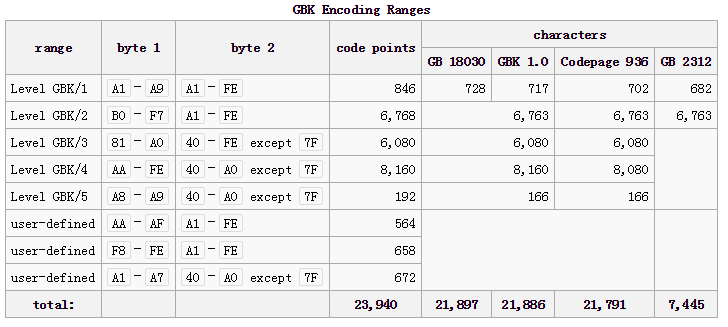

GB18030
GBK已经可以满足绝大部分中文语言环境了,但它对古籍,少数民族等文字还是无法表示,从GBK编码图中可以看到,双字节可用编码空间已经非常有限,所以在2000年发布了四字节编码方案 GB18030。
GB18030采用单字节,双字节,四字节对字符编码,编码范围如下:
单字节:0x00-0x7F,与ASCII一致
双字节:高位字节0x81-0xFE,低位字节0x40-0xFE(不包括0x7F),与GBK一致
四字节:
第一字节0x81-0xFE,第二字节0x30-0x39
第三字节0x81-0xFE,第四字节0x30-0x39
可见GB18030编码空间为126×10×126×10 = 1 587 600,为解决人名、地名用字问题提供了方案,为汉字研究、古籍整理等领域提供了统一的信息平台基础。
Unicode
在计算机发展历程中,各地区都在制定自己的编码规则以适应自身发展,相互之间却互不兼容,USC(Universal Coded Character Set)就希望一统天下,结束百家争鸣的局面。USC主要由ISO和Unicode Consortium两个组织开发实现,双方在位长,编码点,编码空间等问题上是存在分歧的, 各自的标准一直都在融合中,目前对USC这一概念的实现产品普遍称为Unicode。
Unicode于1990年开始研发,1994年正式公布。实现思路是为世界上任意一个字符都设定唯一的编码,编码空间从0x0000-0x10FFFF,共1 114 112个码位。通常Unicode表示为”U+”形式,后面跟着十六进制数值。
Unicode划分了17个平面,0号平面为基本平面(Basic Multilingual Plane BMP),1-16为辅助平面(Supplementary Planes),0号面用四个十六进制数值表示,范围0x0000-0xFFFF,其余平面用五到六个十六进制数值表示,范围0x10000-0x10FFFF。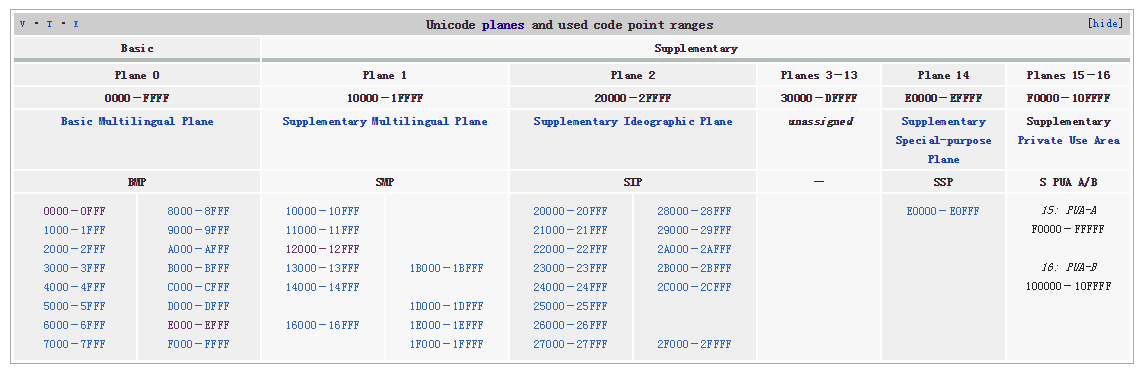
大家比较关心的字符分布情况大致是这样的(BMP):
3000-303F:CJK 符号和标点 (CJK Symbols and Punctuation)
4DC0-4DFF:易经六十四卦符号 (Yijing Hexagrams Symbols)
4E00-9FBB:CJK 统一表意符号 (CJK Unified Ideographs)
F900-FAFF:CJK 兼容象形文字 (CJK Compatibility Ideographs)
由于简体中文字符主要落在0x4E00-0x9FBB,所以在采用Unicode的编程语言里,网友们也会用这个区间判断输入是否为中文,尽管并不完全正确,但绝大多数情况下是不会有问题的。
Unicode对字符做了归类,大致分为Letter, Mark, Number, Punctuation, Symbol, Separator and Other,用来更清楚地表达该字符语义用途。Java字符的表现形式就是基于Unicode(UTF-16BE)实现的,在Character类中可以看到很多方法都与分类相关,比如:getType(int codePoint),isLetter(int codePoint),isDigit(int codePoint)。
UTF-8
Unicode对目前承认的字符都做了数值映射,但并没有对传输形式做出规定,这在数据传输上容易造成混乱,比如0x7F可以用一字节,二字节0x007F或三字节0x00007F传输。UTF(Unicode Transformation Formats)就是明确传输行为的产品,后缀8表示以8位为一个传输单元,UTF-16就是以16位做一个传输单元。

UTF-8对Unicode有1-4字节的传输标准:
U+0000 – U+007F:保持ASCII一致,使用单字节表示
U+0080 – U+07FF:使用双字节表示
U+0800 – U+FFFF:使用三字节表示
U+10000 – U+1FFFFF:使用四字节表示
简体中文主要落在U+4E00-U+9FBB区间,即需要3字节存储,少量CJK要4字节存储,就中文系统而言,UTF-8相对于GB系列编码,存储成本增加了。
为了能无歧义解码,首字节使用不一样的前缀位,比如:
单字节:0xxxxxxx
双字节:110xxxxx
三字节:1110xxxx
四字节:11110xxx
后面跟随的字节则以10打头,如10xxxxxx。
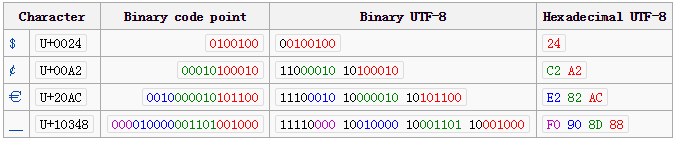
打比方,以欧元符号€为例
1. Unicode编码是 U+20AC
2. 从上表可以看到U+20AC落在U+0800 – U+FFFF,使用三字节表示
3. 0x20AC的二进制是 0010 0000 1010 1100
4. 因为用三字节表示,首字节就是 1110xxxx打头, 这里就应该是 1110 0010
5. 后面的字节全是以10xxxxxx打头,第二字节就是 1000 0010
6. 同理,第三字节就是 1010 1100
7. 综上U+20AC的UTF-8二进制序列是1110 0010 1000 0010 1010 1100, 即0xE282AC
下图展示了其它字节长度的编码转化:
UTF-16
UTF-16是ISO与Unicode Consortium在双字节(UCS-2),四字节(UCS-4)存储争议的折衷方案,约定以16位为一个传输单元,使用双字节,四字节的可变编码方式。
编码规则:
U+0000-U+D7FF与U+E000-U+FFFF:这是BMP编码点,使用一个16位的编码单元,即双字节表示。
U+10000 to U+10FFFF:辅助平面编码点,使用两个16位的编码单元,即四字节表示。以U+10437为例,换算规则如下:
1. 0x10437减去0x10000,得到0x00437,0000 0000 0100 0011 0111
2. 重组二进制序列为10位一组单元,0000000001 和 0000110111
3. 高位与0xD800相加,0xD800 + 0x0001 = 0xD801 (high surrogate: D800–DBFF)
4. 低位与0xDC00相加,0xDC00 + 0x0037 = 0xDC37 (low surrogate: DC00–DFFF)
5. 最终得到的十六进制是 0xD801DC37(BE)

项目乱码
在项目开发活动中,当编码与解码使用两套字符集时,就有可能出现乱码。
示例:
1. FooServlet.java负责接收/打印客户端参数
String arg = request.getParameter("arg");
System.out.println(arg);
2. index.jsp是表单发送文件,没有设置任何编码方式:
<form action="Foo" method="get"> <input type="text" name="arg" /> <input type="submit" value="get submit" /> </form>
3. 项目没有使用编码过滤器(filter),Tomcat也没有设置编码方式(URIEncoding)
4. 假设发送“啊”, 从字符集编码表可以查到“啊”字Unicode是U+554A,GBK是0xB0A1
客户端到服务端乱码:
主流浏览器都会自动对请求编码,设置浏览器编码方式为GBK,所以get请求的URI实际上是编码后的数据:?arg=%B0%A1,百分号是由URI Syntax规定的,即每一个character code前面都会带一个;另外Servlet规范规定在没有显式指定编码时将采用ISO8859-1编码,所以服务端会用ISO8859-1解析客户端GBK编码的数据,这时Java控制台会打印:°¡,这正是ISO8859-1中的0xB0(°)与0xA1(¡)字符。
知道原因后,解决方法就非常简单了:
String arg = new String(request.getParameter("arg").getBytes("ISO-8859-1"), "GBK");
可问题来了,万一客户端浏览器用的不是GBK编码,那依然会出现乱码。我们需要一致的客户端编码!
在JSP文件中强制约定客户端请求编码方式可以通过以下语句实现:
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
这时服务端就可以按照统一的编码方式拿数据了:
String arg = new String(request.getParameter("arg").getBytes("ISO-8859-1"), "GBK");
为了简化代码,可以通过自定义编码过滤器实现,另行参考http://blog.csdn.net/lidawei201/article/details/8506872,这样服务端使用request.getParameter("arg") 就能拿到正确数据了。
服务端到客户端乱码:
Server端正确获得数据(arg)后,使用以下语句向客户端浏览器打印结果时可能会出现乱码:
PrintWriter w = response.getWriter(); w.println(arg); w.close();
按照Servlet规范文档:
PrintWriter getWriter() throws IOException Returns a PrintWriter object that can send character text to the client. The PrintWriter uses the character encoding returned by getCharacterEncoding().If the response's character encoding has not been specified as described in getCharacterEncoding (i.e., the method just returns the default value ISO-8859-1), getWriter updates it to ISO-8859-1.
就是说如果没有设置response编码方式的话,缺省就用ISO-8859-1编码,可客户端浏览器只负责接收字节序列,如果服务端没有告诉它应该用什么方式解码的话,缺省就按浏览器默认编码方式解码,这同样会造成混乱。我们需要向客户端声明一致的解码方式!
response.setContentType("text/html; charset=GBK");
这样一来,客户端就会以GBK的方式解码识别了!
项目中还经常看到网友使用Javascript函数编码,Javscript早期是支持UCS-2,后来使用Unicode,方法encodeURI,encodeURIComponent就是使用UTF-8编码,所以如果这种情况下也要确保Server端使用一致的解码方式才行!
综上,不管是文件,网络,数据库乱码,原因只有一个:使用了不一致的解码方式!
参考资料
百度/维基百科
GB2312编码表:http://www.knowsky.com/resource/gb2312tbl.htm
GBK编码表:http://www.khngai.com/chinese/charmap/tblgbk.php?page=0
字符集与编码:http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
历史故事:http://blog.csdn.net/stilling2006/article/details/4129700
大小端序:https://en.wikipedia.org/wiki/Endianness
Tomcat CharacterEncoding : http://wiki.apache.org/tomcat/FAQ/CharacterEncoding