目录
1 solr概述
1.1 solr的简介
1.2 solr的特点
2 Solr安装
2.1 安装JDK
2.2 安装Tomcat
2.3 安装solr
2.4 目录结构说明
2.5 SOLR HOME说明
3 Solr配置
3.1 Solr.XML说明
3.2 配置SolrConfig.xml
3.3 配置schema.xml
3.4 配置中文分词
3.5 多实例部署
4 solr使用
4.1 添加索引
4.2 更新索引
4.3 删除索引
4.4 提交和优化
4.5 查询索引
5 扩展到SolrCloud
5.1 Zookeeper安装
5.2 启动SolrCloud
5.3 术语及注意事项
6 SolrJ的使用
6.1 部署号码黄页的SolrCloud
6.2 SolrJ操作SolrCloud
7 Solr管理
1 solr概述
1.1 solr的简介
solr是一个基于lucene的全文检索引擎。他包括了全文检索,命中高亮,准实时搜索,富文本检索等特性. Solr是用Java编写的,并作为一个独立的全文搜索服务器,比如tomcat容器内运行。Solr的全文索引和搜索其核心使用了Lucene Java搜索库,并具有类似REST的HTTP / XML和JSON的API,可以很容易地从几乎任何编程语言使用.
什么是全文检索?
全文检索是将存储于数据库中整本书、整篇文章中的任意内容信息查找出来的检索。它可以根据需要获得全文中有关章、节、段、句、词等信息,也就是说类似于给整本书的每个字词添加一个标签,也可以进行各种统计和分析。
对于全文检索来说,倒排索引是最常用的一种技术。倒排索引用来存储某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
然后再我们检索的时候。系统会将我们需要查询的文本转化为检索词。然后去映射表中查询其对应的文档,然后做文档归并既可以获取到我们希望得到的结果。
Why solr?
既然Solr是基于lucene的,那为什么我们不直接使用Lucene呢?
Lucene是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎 。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.
Lucene的涉及目标决定了lucene在扩展和管理索引上比较困难。但是solr提供了一个管理页面,并且可以动态的添加和删除索引节点。可以做索引之间的互备,而这些使用lucene则很难实现
1.2 solr的特点
- 基于标准的开放接口:Solr支持XML,JSON和HTTP的调用形式,所以虽然solr是用java写成,但是我们依然可以使用别的语言来调用solr
- 先进的全文检索技术:在Solr中,我们不仅可以使用词来作为检索条件,还可以使用时间范围,数字范围等作为检索条件,也可以进行模糊搜索。
- 线性可扩展性:可以在线的扩展索引节点,自动索引复制,自动故障切换和恢复。
- 近实时索引:数据添加到索引后,可以很快的被检索到。
- 管理界面:可以很方便的管理各个节点,包括索引统计信息以及各个节点的状态。
2 Solr安装
Solr的运行环境非常简单。只需要JDK和一个WEB容器。这里以Tomcat为例介绍Solr的安装。
2.1安装JDK
下载JDK:
http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-javase6-419409.html#jdk-6u45-oth-JPR
设置权限:[root@localhost solrTest]# chmod 777 ./jdk-6u45-linux-i586.bin
安装:[root@localhost solrTest]# ./jdk-6u45-linux-i586.bin
设置环境变量,在/ect/profile中添加并export
[root@localhost solrTest]# vim /etc/profile
在文件的最后加上下面三句话,并在控制台内也执行这四句话
JAVA_HOME=/usr/local/solrTest/jdk1.6.0_45
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
确定已经安装成功
在控制台执行
[root@localhost ~]# java –version
返回
java version "1.6.0_45"
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
Java HotSpot(TM) Client VM (build 20.45-b01, mixed mode, sharing)
2.2安装Tomcat
下载TOMCAT http://tomcat.apache.org/download-60.cgi
解压缩 [root@localhost solrTest]# tar -zxvf apache-tomcat-6.0.37.tar.gz
启动Tomcat
[root@localhost apache-tomcat-6.0.37]# cd /usr/local/solrTest/apache-tomcat-6.0.37/bin/
[root@localhost bin]# ./catalina.sh start
访问页面测试下http://192.168.39.250:8080/ (虚拟主机的IP)
看到这个页面说明Tomcat运行正常
2.3安装solr
下载solr http://lucene.apache.org/solr/downloads.html
解压缩 [root@localhost solrTest]# tar zxvf solr-4.4.0.tgz
Solr解压后会有一个example目录,这个目录下是Solr自带的一个示例。这个示例下有一个已经编译好的Solr.War.我们后续的操作可以使用这个已经编译好的war包
将war包拷到Tomcat目录下:
[root@localhost solrTest]# cp solr-4.4.0/example/webapps/solr.war /usr/local/solrTest/apache-tomcat-6.0.37/webapps/solr.war
创建一个集合的文件夹并配置
[root@localhost solrTest]# mkdir testData
[root@localhost solrTest]# cp -a solr-4.4.0/example/solr/* testData/
设置solr home
[root@localhost solrTest]# vi apache-tomcat-6.0.37/conf/Catalina/localhost/solr.xml
<?xml version="1.0" encoding="utf-8"?>
<Context docBase="/usr/local/solrTest/apache-tomcat-6.0.37/webapps/solr.war" debug="0" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="/usr/local/solrTest/testData" override="true"/>
</Context>
启动一下Tomcat
(/usr/local/solrTest/apache-tomcat-6.0.37/bin/startup.sh)
这时http://192.168.39.250:8080/solr 应该是无法访问的,主要是因为缺少配置文件
关闭tomcat (/usr/local/solrTest/apache-tomcat-6.0.37/bin/shutdown.sh)
拷贝一下文件:
[root@localhost solrTest]# cp solr-4.4.0/example/lib/ext/* apache-tomcat-6.0.37/webapps/solr/WEB-INF/lib/
[root@localhost solrTest]# cp solr-4.4.0/example/resources/log4j.properties apache-tomcat-6.0.37/lib/
再次启动 Tomcat (/usr/local/solrTest/apache-tomcat-6.0.37/bin/startup.sh)
再次访问 http://192.168.39.250:8080/solr

可以看到 Solr已经可以正常的运行,现在 我们来看一下Solr的目录结构
2.4目录结构说明
我们下载的Solr包后,进入Solr所在的目录,我们可以看到以下几个目录:contrib、dist、docs、example、licenses。下面分别对其进行介绍。
-
1) Contrib:Solr的一些扩展包,包括分词器,聚类,语言识别,数据导入处理,非结构化内容分析等.
-
2) dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。我们之前使用的solr.war实际上就是这个文件夹下的solr-4.40.war
-
3) example:这个目录实际上是Tomcat的安装目录。其中包含了一些样例数据和一些Solr的配置。第一次使用solr的时候可以直接启动这个目录下的start.jar来启动solr,以便对solr有个比较直观的了解
其中一些子目录也比较重要,这里也对它们稍作介绍。
- example/multicore:该目录是一个包含了多实例配置信息的Solr的home目录。
- example/solr:该目录是一个包含了默认配置信息的Solr的home目录。
- example/webapps:tomcat的webapps目录,该目录通常用来放置Java的Web应用程序。在Solr中,前面提到的solr.war文件就部署在这里。
其余的2个目录docs和licenses则分别是本地的文档以及权限介绍.
2.5 SOLR HOME说明
Solr home目录实际上是一个运行的Solr实例所对应的配置和数据(Lucene索引)。就example来说,合法的solrhome目录有2个,一个是example/solr目录,另一个是example/multicore目录,他们的区别就是multicore是多实例的。
example/solr目录下主要有以下一些目录和文件:
- solr.xml solr的主要配置文件,在solr启动的时候被加载,solr的配置信息包括端口号,连接时间,超时时间等.
- collection1/conf/ schema.xml 该文件是索引的schema,包含了域类型的定义
- collection1/conf/ solrconfig.xml 该文件是Solr的主配置文件,solr的版本,数据存放位置,定义扩展功能的使用等.
3 Solr配置
Solr的配置主要是以下三个主要的文件solr.xml, solrconfig.xml, schema.xml,在solr启动的时候,会首先检查solr.xml,这个文件时solr的全局的配置信息.告诉solr在哪里可以找到solr的实例.在solr.xml加载后,solr会去每个实例内查找solrconfig.xml. solrconfig.xml指向其他的配置文件.除非修改solrconfig.xml,否则将以schema.xml配置文件来决定Solr的字段
3.1 Solr.XML说明
Solr.xml的配置通常是不用修改的,配置文件可以修改的栏目如下:
<solr>
<str name="adminHandler">${adminHandler:org.apache.solr.handler.admin.CoreAdminHandler}</str>
<int name="coreLoadThreads">${coreLoadThreads:3}</int>
<str name="coreRootDirectory">${coreRootDirectory:}</str> <!-- usually solrHome -->
<str name="managementPath">${managementPath:}</str>
<str name="sharedLib">${sharedLib:}</str>
<str name="shareSchema">${shareSchema:false}</str>
<int name="transientCacheSize">${transientCacheSize:Integer.MAX_VALUE}</int> <!-- ignored unless cores are defined with transient=true -->
<solrcloud>
<int name="distribUpdateConnTimeout">${distribUpdTimeout:}</int>
<int name="distribUpdateSoTimeout">${distribUpdateTimeout:}</int>
<int name="leaderVoteWait">${leaderVoteWait:}</int>
<str name="host">${host:}</str>
<str name="hostContext">${hostContext:solr}</str>
<int name="hostPort">${jetty.port:8983}</int>
<int name="zkClientTimeout">${zkClientTimeout:15000}</int>
<str name="zkHost">${zkHost:}</str>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
<logging>
<str name="class">${loggingClass:}</str>
<str name="enabled">${loggingEnabled:}</str>
<watcher>
<int name="size">${loggingSize:}</int>
<int name="threshold">${loggingThreshold:}</int>
</watcher>
</logging>
<shardHandlerFactory name="shardHandlerFactory" class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:}</int>
<int name="connTimeout">${socketTimeout:}</int>
</shardHandlerFactory>
</solr>
Solr.xml在加载以后,会去根目录下的每个目录进行搜索,直到遇到一个名为core.properties的文件. 发现core.properties文件的目录被当成一个sorlr的实例. core.properties可以设置的项目包括:
- name 实例名字.
- config 实例的配置文件名,默认为solrconfig.xml
- dataDir 数据存储路径,默认为当前路径.
- ulogDir 事物日志的存储路径,默认为当前路径
- schema 域字段的配置文件,默认为schema.xml
- shard 实例的 ID.
- roles SolrCloud 中的角色定义是什么
- loadOnStartup 是否是在solr启动的时候加载,默认为Ture.
- coreNodeName solr核心节点名字
3.2 配置SolrConfig.xml
solrconfig.xml文件包含了大部分的参数用来配置Solr本身的。solrconfig.xml文件不仅指定了 Solr 如何处理索引、突出显示、分类、搜索以及其他请求,还指定了用于指定缓存的处理方法的属性,以及用于指定Lucene 管理索引的方法的属性。
3.2.1 插件加载
Solr的允许你加载自定义代码来执行各种任务,首先将你的solr的插件打成一个jar,然后以类似下面的方式配置solr,以便让solr知道如何加载他们
如果我们有多个实例,并且希望所有的实例都可以共享插件.可以在solr.xml中启动sharedLib属性.
如果只希望在某些实例中使用插件.则可以使用如下的方式来配置插件.
<lib dir=”../../../contrib./extractor/lib” regex=”.*\.jar” />
<lib path=”../a-jar-that-does-not-exist.jar”>
注意 在默认情况下访问http://192.168.39.250:8080/solr/#/~logging页面应该会出现如下异常:

修改solrconfig.xml文件内的lib加载路径后,重新tomcat.再次访问.正常
< lib dir="/usr/local/solrTest/solr-4.4.0/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="/usr/local/solrTest/solr-4.4.0/dist/" regex="solr-velocity-\d.*\.jar" />
3.2.2 dataDir
默认情况下索引文件时在实例的./data的目录下,但是我们也可以使用来修改默认目录.
<dataDir>/var/data/solr</dataDir>
3.2.3 更新配置
<updateHandler class="solr.DirectUpdateHandler2">
<maxPendingDeletes>100000</maxPendingDeletes>
<autoCommit>
<maxDocs>10000</maxDocs>
<maxTime>15000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
…
这个更新处理器主要涉及底层的关于如何更新处理内部的信息。(这个参数不同于来自客户端的手动更新)。
- maxPendingDeletes 最大的缓冲项目
- maxDocs 内存中最多的文档数
- maxTime 触发自动提交的最大等待时间,单位是ms
- openSearcher 在值为false的时候,在启动硬盘搜索的时候不会打开新的实例,导致内存内的信息可以被检索到
3.2.4 查询配置
<maxBooleanClauses>1024</maxBooleanClauses>
查询子句的最大的数量.这里的默认值为1024.修改这个值可以传入更多的条件.
3.2.5 缓存配置
<queryResultCache
class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="256"/>
<documentCache
class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
这里也基本不需要修改,目前支持的缓存算法有LRU(近期最少使用算法),FastLRU,LFU(最近最不常用) FastLRUCache比LRU有更快的读取速度以及更慢的插入速度,而且有可能大小没有限制.
size是最大情况下缓存的条目(注意,不是内存大小)。Init是初始容量
filterCache存储了filter queries(“fq”参数)得到的document id集合结果。Solr中的query参数有两种,即q和fq。如果fq存在,Solr是先查询fq(因为fq可以多个,所以多个fq查询是个取结果交集的过程),之后将fq结果和q结果取并。在这一过程中,filterCache就是key为单个fq(类型为Query),value为document id集合(类型为DocSet)的cache。对于fq为range query来说,filterCache表现出其有价值的一面。
queryResultCache是对查询结果的缓存,documentCache用来保存<doc_id,document>对的
myUserCache是用户自定义的一个cache,如果开启了自定义的缓存。则不使用Solr自带的缓存。
3.3 配置schema.xml
schema.xml文件主要用来配置数据类型和字段信息.这些字段被用来建立索引和查询.
3.3.1 数据类型
数据类型可以在标签内用 标签来定义.定义fieldtype时,最少应该包含name,class这个两个属性. name就是这个FieldType的名称,class指向类所在的位置.在fieldtype定义的时候,一般还会定义类型的analyser(分词器), similarity(评分器)等
<types>
<fieldType name="text_dfr" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.standard.StandardAnalyzer"/>
<similarity class="solr.DFRSimilarityFactory">
<str name="basicModel">I(F)</str>
<str name="afterEffect">B</str>
<str name="normalization">H2</str>
</similarity>
</fieldType>
<fieldType name="text_ib" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
<similarity class="org.apache.lucene.search.similarities.DefaultSimilarity"/>
</fieldType>
...
</types>
<similarity class="solr.SchemaSimilarityFactory"/>
analyzer,包括分词和过滤. 在index的analyzer中使用 solr.WhitespaceTokenizerFactory这个分词包,就是空格分词,然后使用 solr.StopFilterFactory这几个过滤器。在向索引库中添加text类型的索引的时候,Solr会首先用空格进行分词,然后把分词结果依次使用指定的过滤器进行过滤,最后剩下的结果才会加入到索引库中以备查询。Solr的analysis包中默认并不包括中文的分词包.
Similarity 是计算相似性的组件,相似性用于计算搜索命中后的得分,得分最后影响排序,Solr默认的评分器是基于TF-IDF的计算方法来实现的.通常这个是不用修改的.但是Solr4中支持分别为每个字段定义相似性计算的类以及全局的计算类.
3.3.2 字段
接下来的工作就是在fields结点内定义具体的字段(类似数据库中的字段),就是filed,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等等。
<fields>
<field name="id" type="integer" indexed="true" stored="true" required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="summary" type="text" indexed="true" stored="true" />
<field name="keyword" type="text" indexed="true" stored="false" multiValued="true" />
...
</ fields >
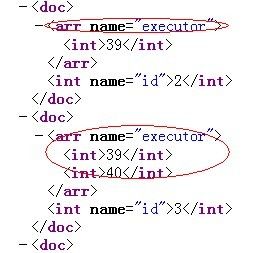
field的定义相当重要,有几个技巧需注意一下,对可能存在多值得字段尽量设置 multiValued属性为true,避免建索引是抛出错误;如果不需要存储相应字段值,尽量将stored属性设为false。 所谓multValued就是一个field有多个值,如下:
3.3.3 唯一键
定义唯一键. id
3.3.4 拷贝字段
拷贝字段举例来说,就是查询的时候不用再输入:userName:张三 and userProfile:张三的个人简介。直接可以输入"张三"就可以将“名字”含“张三”或者“简介”中含“张三”的又或者“名字”和“简介”都含有“张三”的查询出来。他将需要查询的内容放在了一个字段中,并且查询该字段就行了
如建立了一个统一的查询字段all,并将name和summary拷贝到这个字段内:
< field name="all" type="text" indexed="true" stored="false" multiValued="true" />
并在拷贝字段结点处完成拷贝设置:
<copyField source="name" dest="all"/>
<copyField source="summary" dest="all" maxChars="300"/>
拷贝字段可以设置最大的字符长度
3.3.5 动态字段
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*i,定义它的type为text,那么在使用这个字段的时候,任何以i结尾的字段都被认为是符合这个定义的
如我们一开始定义字段的时候可能并没有考虑到有school这个字段,但是索引已经运行一段时间.并不方便再次修改索引的配置文件.这时就可以直接在添加索引的时候加上school_i这个字段而不需要修改配置文件就能生效.
3.4 配置中文分词
如上文所说,目前Solr中默认是不支持中文分词的.如果需要支持中文.则必须自己扩展分词组件.目前国内比较有名的分词组件有IK,庖丁, ICTCLAS, 盘古分词, mmseg4j等.就业内评测结果来说, ICTCLAS分词效果最好,而且包含词性识别.但是ICTCLAS分为商用版和免费版两种,免费版的测试结果欠佳.
如: 工信处女干事每月经过机房时都会检查二十四口交换机
结果为: 工/n 信/n 处女/n 干事/n 每月/r 经过/p 机房/n 时/ng 都/d 会/v 检查/v 二十四/m 口/q 交换机/n
就分词来说.主要需要考虑的要素为准确率和召回率.如
“世界杯”是一个词,用单字切分的话,查“世界”也可以命中这篇文档,而用中文分词就查不到了; 而中文分词的支持者们的反驳大概是: “参加过世界杯”,用单字切分的话,查“过世”也可以命中这篇文档,但事实上并没有人挂掉;
所以通常的做法是在建立索引阶段.使用全切分的算法对文本中所有的可能性词语进行切分,并在检索阶段竟可能的去准确的分析用户的意图.
IK在处理全切分时,速度较快,并且可以返回所有的可能结果.下面以IK为例,配置中文分词.
下载IK.
https://code.google.com/p/ik-analyzer/downloads/detail?name=IK%20Analyzer%202012FF_hf1.zip&can=2&q=
解压
[root@localhost IK]# unzip IK.zip
拷贝到solr的lib下
[root@localhost conf]# cp /usr/local/solrTest/IK/IKAnalyzer2012FF_u1.jar /usr/local/solrTest/testData/lib/IK.jar
配置solrconfig.xml.设置IK的加载路径.
<lib path="../lib/IK.jar" />
配置schma.xml(这时一个最简单的schema文件)
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="text" type="text_ik" indexed="true" stored="true"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
<uniqueKey>id</uniqueKey>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
</types>
</schema>
启动Tomcat.并访问http://192.168.39.250:8080/solr 看到正常的solr页面表示插件已经正常加载了. 如果遇到问题.需要分析appache的日志来定位问题并修正.
3.5 多实例部署
多核,官方说法,让你只用一个Solr实例,实现多配置多索引的功能,为不同的应用保留不同的配置。就是每个core都有独立的solrconfig.xml与schema.xml,却依然保留统一与方便的管理。每份索引都可以当做一个独立的应用来对待,甚至可以实现索引的热切换。比如说,为新闻、微博、论坛搜索各建立一个搜索系统。
由上文提到的
“Solr.xml在加载以后,会去根目录下的每个目录进行搜索,直到遇到一个名为core.properties的文件”
Solr4中不在需要对多核心做特殊的配置,只需要创建新的collection文件夹就可以了.以下是一个简单的示例.
复制文件夹
[root@localhost testData]# cp -r collection1/ collection2/
修改core.properties文件
[root@localhost collection2]# vim core.properties
name=collection2
重新启动tomcat 既可以看到效果.
4 solr使用
Solr使用主要分为两个部分.一个是建立索引,一个是查询索引.建立索引的过程包括追加,删除,提交,优化(合并).Solr为了保证能够提供给其他语言接口.提供了REST接口(这里指可以使用HTTP协议和Solr进行交互).REST接口提供的格式有XML,JSON,CSV
下面介绍的时候.将先介绍REST的接口中的JSON的形式,再介绍Java的实现.其本质实际上是一样的.
4.1 添加索引
首先编辑我们需要上传的JSON文件(这个文件以上文中创建的solr实例collection1为例).
[
{
"id" : "978-0641723445",
"text" : "Solr in Action"
},
{
"id" : "978-1423103349",
"text" : "Solr测试"
},
{
"id" : "978-1857995879",
"text" : "工信处女干事"
}
]
文件命名为simpleTest.json
执行(HTML-POST)
[root@localhost testREST]# curl 'http://192.168.39.250:8080/solr/collection1/update/json?commit=true' --data-binary @simpleTest.json -H 'Content-type:application/json'
访问: http://192.168.39.250:8080/solr/collection1/select?q=%3A&wt=json&indent=true (q=: 即查询所有记录)

返回结果如上图.可以看到已经添加成功
4.2 更新索引
以下个JSON为例说明如何使用JSON来进行更新
[
"add": {
"commitWithin": 5000,
"overwrite": true,
"boost": 3.45,
"doc": {
"id": "978-1857995879",
"text": "工信处女干事每月经过机房时都会检查二十四口交换机"
"text": "工信处女干事每月经过机房时都会检查二十四口交换机"
}
}
]
访问页面.可以看到刚才的信息已经被更新
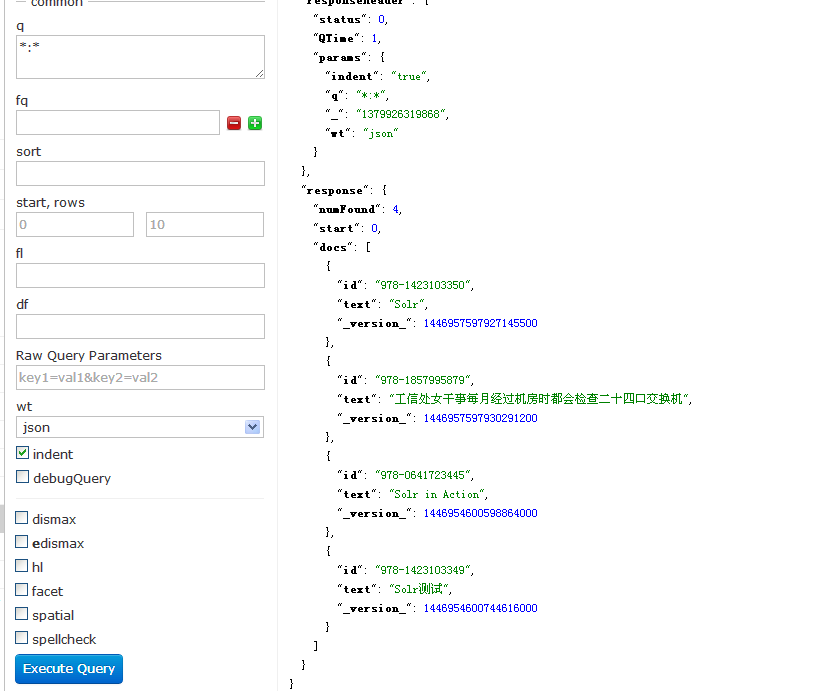
4.3 删除索引
为了演示删除这里又多加了一条数据 ID:978-1423103350,删除的代码很简单.
[
"delete": { "id":"978-1423103350" }
]
可以看到, ID:978-1423103350的记录已经被删除了
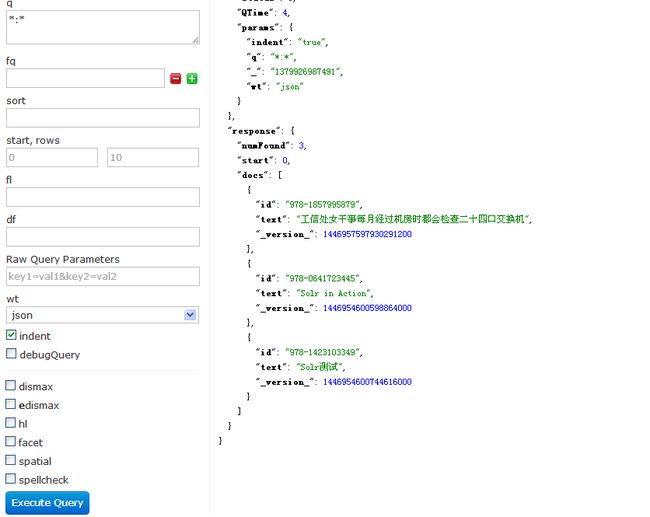
4.4 提交和优化
commit 告诉 Solr,应该使上次提交以来所做的所有更改都可以搜索到。默认情况下索引内容是在内存中,当显式的调用commit的时候.Solr就会把这部分内容写到硬盘.
optimize 重构 Lucene 的文件以改进搜索性能。索引完成后执行一下优化通常比较好。如果更新比较频繁,则应该在使用率较低的时候安排优化。一个索引无需优化也可以正常地运行。优化是一个耗时较多的过程。优化的主要作用是合并lucene文件,以减少IO操作.
在JSON中使用commit和optimize很简单.只要如下即可.
[
"commit": {},
"optimize":{}
]
Optimize有参数maxSegments .值是数值,表示优化后的段文件数目(默认为1)
4.5 查询索引
添加文档后,就可以搜索这些文档了。Solr 接受 HTTP GET 和 HTTP POST 查询消息。收到的查询由相应的 SolrRequestHandler 进行处理。
Solr部署才成功后.先进入http://192.168.39.250:8080/solr页面,然后选择solr的实例.再点击Query即可进入Solr的查询页面. Solr查询页面主要是提供了一个方面的查询接口.不用自己去拼接URL即可完成复杂的查询.如果需要最终的URL.可以在Solr查询页面的上面获取到拼接后的地址.

[Solr的检索运算符]
1. “:” 指定字段查指定值,如返回所有值*:*
2. “?” 表示单个任意字符的通配
3. “*” 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
4. “~” 表示模糊检索,如示例中分词结果不存在二四.所以直接用二四查询会不存在结果.但是如果是”二四~” 则可以命中记录
5. 邻近检索,如查询text:”solr action”~0 没有结果而”solr action”~1 命中
6. “^” 控制相关度检索,如检索jakarta apache,同时希望去让”jakarta”的相关度更加好,那么在其后加上”^”符号和增量值,即jakarta^4 apache
7. 布尔操作符AND、OR、&&、||、+、<空格>
8. 布尔操作符NOT、!、- (排除操作符不能单独与项使用构成查询)
9. “+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在
10. ( ) 用于构成子查询 如 +text:((Solr && 测试) 处女)
11. [] 包含范围检索,如检索某时间段记录,包含头尾,date:[200707 TO 200710]
12. {} 不包含范围检索,如检索某时间段记录,不包含头尾date:{200707 TO 200710}
13. \ 转义操作符,特殊字符包括+ - && || ! ( ) { } [ ] ^ ” ~ * ? : \
Solr查询参数说明
•q - 查询字符串,查询的语法需要符合上述的检索运算符规则。
•fq -过滤语句,默认包含才会返回查询结果.如q=text:solr fq=text:in 则结果命中Solr in Action 如果q=text:solr fq=-text:in 则命中Solr测试
•fl - 指定返回那些字段内容,用逗号或空格分隔多个。如指定text 则不再返回id的值
•start - 返回第一条记录在完整找到结果中的偏移位置,0开始,一般分页用。
•rows - 指定返回结果最多有多少条记录,配合start来实现分页。
•sort - 排序,格式:sort=<field name><空格><desc|asc>[,<field name><空格><desc|asc>]… 。
示例:(id asc,text desc)表示先 “id” 升序, 再 “text” 降序,默认是相关性降序。
•wt - (writer type)指定输出格式,可以有 xml, json, php, python,ruby等。
•df - 默认的查询字段,一般默认指定
•qt - (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
•indent - 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
•hl - 检索结果高亮 hl.fl用于设置需要高亮的字段.hl.simple.pre和hl.simple.post用于设置高亮的标签
•facet - 类似于字段统计.显示所有已经索引的字段以及他的数目.
5 扩展到SolrCloud
在Solr的早期版本中,分布式的索引是基于索引的复制分发,主节点负责建索引,建好之后定期复制分发到从节点,从节点负责查询;支持从URL指定从节点响应查询请求.这种情况下,根本就不能算作真正的分布式索引。而且对节点的管理,扩充,负载均衡等都只能依靠自己来实现。所以在Solr4中。引入了SolrCloud的技术方案。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正Solr4X的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。借助Zookeeper.Solr4实现了集中式的配置信息,自动容错以及查询时自动负载均衡
5.1 Zookeeper安装
下载: http://www.apache.org/dyn/closer.cgi/zookeeper/
解压Zookeeper [root@localhost solrTest]# tar zxvf zookeeper-3.3.5.tar.gz
编辑对应的zookeeper配置文件,复制zookeeperconf下zoo_sample.cfg为zoo.cfg
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg
[root@localhost conf]# vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/usr/local/solrTest/zookeeper/
# the port at which the clients will connect
clientPort=2181
- tickTime:心跳时间,为了确保连接存在的,以毫秒为单位,最小超时时间为两个心跳时间
- initLimit:多少个心跳时间内,允许其他server连接并初始化数据,如果ZooKeeper管理的数据较大,则应相应增大这个值
- clientPort:服务的监听端口
- dataDir:用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里(注意:一个配置文件只能包含一个dataDir字样,即使它被注释掉了。)
- syncLimit:多少个tickTime内,允许follower同步,如果follower落后太多,则会被丢弃。
由于这里主要是使用SolrCloud 所以只配置一个Zookeeper来管理所有的Solr节点.在实际环境中可以按Zookeeper集群的方式来部署.
创建数据文件夹 [root@localhost bin]# mkdir /usr/local/solrTest/zookeeper
启动 [root@localhost bin]# ./zkServer.sh start
[root@localhost bin]# ./zkCli.sh 测试是否可以连接到Zookeeper服务器.如下则为正常
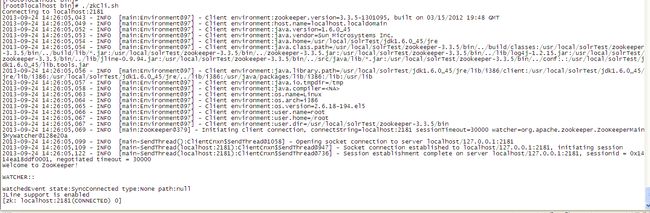
5.2 启动SolrCloud
编辑Tomcat的catalina.sh文件 在启动Tomcat的时候初始化Zookeeper的配置文件及SolrCloud的环境变量
[root@localhost bin]# vi catalina.sh
JAVA_OPTS="$JAVA_OPTS -Dbootstrap_confdir=/usr/local/solrTest/testData/collection1/conf -Dcollection.configName=myconf4test -DnumShards=1 -DzkHost=192.168.39.250:2181 -Dj
etty.port=8080"
- -DzkRun参数是启动一个嵌入式的Zookeeper服务器,它会作为solr服务器的一部分,这里是外部zookeeper,就不需要此参数
- -Dbootstrap_confdir参数是上传本地的配置文件上传到zookeeper中去,作为整个集群共用的配置文件,
- -DnumShards指定了集群的逻辑分组数目,数据会分散在里面,最小单位为doc。
- Djetty.port也可用于tomcat,指定对外服务的端口号
测试SolrCloud是否已经成功启动
[root@localhost bin]# ./catalina.sh start
访问页面
http://192.168.39.250:8080/solr/#/~cloud

添加节点
主节点配置完成后,再添加节点就变得比较容易.只需要在别的机器节点的Solr启动的时候,指定Zookeeper的host所在的机器即可.如在39.251上配置一个solr环境,保证实例的字段和主节点的一致 修改tomcat的文件
[root@localhost bin]# vi catalina.sh
JAVA_OPTS="-DzkHost=192.168.39.250:2181 -Djetty.port=8080"
启动节点 一会可以看到

SolrCloud的查询在任意一个节点上都可以使用.
在查询的时候.会整合所有的shard的结果后再返回.所以只要指定collection.在任意一个存货节点上查询数据都是可以的.使用REST的时候只要先问ZK要存货节点就OK了
5.3 术语及注意事项
- Collection 数据的集合,多个Collection就组成了Cluster(集群).同一个群集必须使用同一套schema和solrconfig
- Shard 分片 就是把Collection内的数据分成几份,分的越多 负载也就越小.shard内的数据不会互相备份.
- Leader 每个分片至少有一个shard
- Replication 对leader的备份 可以为0-n
注意:
-
1 JAVAOPTS的位置.在测试的时候. JAVAOPTS放在文件的最后不起作用.最后是放在
JAVA_OPTS (Optional) Java runtime options used when the "start"
-
2 主节点的选取时间 在solrCloud运行的时候,如果一个节点挂掉或者是重新启动.其他的节点就进入了等待选取leader节点的状态.这时solrCloud也无法进行访问.这个选取leader的时间需要3分钟.我们可以通过配置文件来缩短这个等待时间.
在solr.xml上添加配置:leaderVoteWait="${leaderVoteWait:20000}"就可以将选取等待时间减少
<solrcloud> <str name="host">${host:}</str> <int name="hostPort">${jetty.port:8983}</int> <str name="hostContext">${hostContext:solr}</str> <int name="zkClientTimeout">${zkClientTimeout:15000}</int> <int name="leaderVoteWait">${leaderVoteWait:20000}</int> <bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool> </solrcloud> -
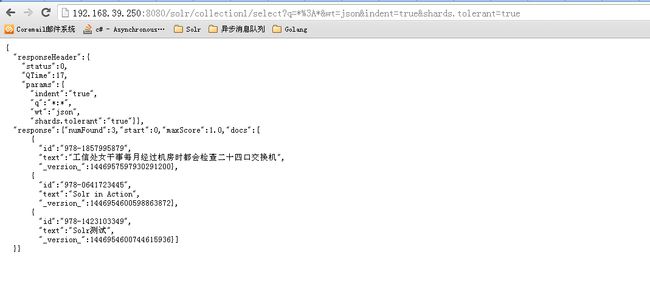
3 默认情况下.有任意一个shard挂掉.将无法返回结果.可以在查询URL的后面加上shards.tolerant=true来忽略失效的shard
举例:
现在设置3个节点.250,251,252.251和252一个shard,251一个shard,停掉251,并查询

加上shards.tolerant=true后
6 SolrJ的使用
现在,Solr的安装部署,Solr云的部署都已经有了介绍.下面以号码黄页为例,介绍SolrJ的使用,在配置索引的使用,保留SolrCloud下的collection1 另建立一份collection,顺便介绍solrcloud下的多实例的部署.
6.1 部署号码黄页的SolrCloud
从原有的集合中copy一份配置出来
[root@localhost testData]# cp -r collection1/ YellowPages/
修改实例的名称
[root@localhost YellowPages]# vi core.properties
name=YellowPages
修改黄页的资源实例.因为只DEMO的性质 所以这里就简单的设计下. 黄页内一个项目只包含 id ,name ,address,phone,其中phone可以为多个.则schema.xml为
[root@localhost YellowPages]# vi conf/schema.xml
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="text" indexed="true" stored="true"/>
<field name="address" type="text_ik" indexed="true" stored="true"/>
<field name="phone" type="text" indexed="true" stored="true" multiValued="true" />
<field name="all" type="text_ik" indexed="true" stored="false" />
<copyField source="name" dest="all"/>
<copyField source="address" dest="all" />
<copyField source="phone" dest="all" />
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
<uniqueKey>id</uniqueKey>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text" class="solr.TextField" />
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
</types>
</schema>
YellowPages的实例已经配置完成.现在开始配置多核的SolrCloud,在使用多核的SolrCloud的时候.我们不再使用编写tomcat的文件的方式来指定zookeeper来上传文件.而是指定Solr的工作目录即可.这里需要用到solr自带的工具.先用example自带的包来解压运行一下solr.以生成需要的配置文件
[root@localhost example]# java -jar start.jar
进入cloud-scripts目录
[root@localhost cloud-scripts]# ./zkcli.sh -zkhost 192.168.39.250:2281 -cmd bootstrap -solrhome /usr/local/solrTest/testData/
上传Solr的根目录 Solr在加载的时候会依据根目录内的多个集合的属性来初始化配置文件
修改Tomcat的文件,仅仅指定Shard的数量 ZK的机器以及服务的端口
[root@localhost bin]# vi catalina.sh
JAVA_OPTS="$JAVA_OPTS -DnumShards=2 -DzkHost=192.168.39.250:2281 -Djetty.port=8080"
将配置好的YellowPages的实例复制到其他的机器上.由于其他机器的catalina.sh没有变动.则不用修改
先后启动250,251,252 即可看到
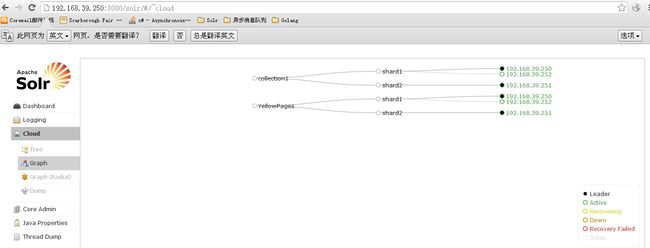
6.2 SolrJ操作SolrCloud
SolrJ操作Solr和操作SolrCould并没有太多的区别.这里就以SolrCould为例子来说明.SolrJ操作的时候和上面说的URL的方式也非常的类似.提供的功能也很相像,也就是索引方面的添加,删除,更新,提交和优化.但是默认情况下只要索引中有这条记录,就会覆盖原有的.标记是否存在索引记录的字段就是唯一字段,一般是(ID).
搭建环境.
新建一个项目,并且Copy必须的包到项目内.
solr-solrj-4.4.0.jar Solr对Java的接口类
solr-core-4.4.0.jar Solr的核心包
solrj-lib/zookeeper-3.4.5.jar zookeeper的工具包
//httpClient的组件,用于网络请求(HTTP POST GET)
solrj-lib/commons-io-2.1.jar
solrj-lib/httpclient-4.2.3.jar
solrj-lib/httpcore-4.2.2.jar
solrj-lib/httpmime-4.2.3.jar
//日志包
solrj-lib/jcl-over-slf4j-1.6.6.jar
solrj-lib/jul-to-slf4j-1.6.6.jar
solrj-lib/log4j-1.2.16.jar
solrj-lib/slf4j-api-1.6.6.jar
solrj-lib/slf4j-log4j12-1.6.6.jar
//杂项
solrj-lib/noggit-0.5.jar
solrj-lib/wstx-asl-3.2.7.jar
数据文件
京翰1对1辅导 中小学课外辅导专家
北京京翰英才教育科技有限公司
4008116268-2880
提高记忆力3-5倍,让学习更轻松、快乐、高效
新脑力教育
13965121806
合肥博强教育管理咨询有限公司
合肥刘博士数理化一对一、精品小班、艺术生文化课快速提分
4008806400
尚助教育辅导中心
合肥宁国路
13966662351
新脑力教育
合肥天鹅湖
13965121809
实例代码
IndexAPI.java
package com.iflytek.test.solr.core;
import java.io.IOException;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.CloudSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.apache.solr.common.params.ModifiableSolrParams;
import com.iflytek.test.solr.conf.Constent;
import com.iflytek.test.solr.data.ContactInfo;
public class IndexAPI {
private CloudSolrServer server = null;
/**
* 添加索引
* */
public boolean addIndex(ContactInfo info){
//如果不是SolrCloud 则类似下面的写法
//HttpSolrServer server = new HttpSolrServer("http://localhost:8983/solr");
try{
if(server==null){
server = new CloudSolrServer(Constent.ZKHOST);
server.setDefaultCollection(Constent.COLLECTION);
}
}catch(Exception e){
//日志
return false;
}
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", info.get_id());
doc.addField("name", info.getName());
doc.addField("address", info.getAddress());
doc.addField("phone", info.getPhone());
try {
server.add(doc);
server.commit();
//也可以选择不提交等后期一起提交
server.optimize();
//索引优化 也不是必须的
} catch (SolrServerException e) {
//日志
return false;
} catch (IOException e) {
//日志
return false;
}
return true;
}
/**
* 查询索引
* @param q 查询条件 具体的构建过程交给外部去做
* */
public SolrDocumentList searchIndex(String q){
//如果不是SolrCloud 则类似下面的写法
//HttpSolrServer server = new HttpSolrServer("http://localhost:8983/solr");
try{
if(server==null){
server = new CloudSolrServer(Constent.ZKHOST);
server.setDefaultCollection(Constent.COLLECTION);
}
}catch(Exception e){
//日志
return null;
}
ModifiableSolrParams params = new ModifiableSolrParams();
params.set("q", q);
params.set("start", 0);
params.set("row", 10);
//这里实际上就是请求的URL的拼接过程
QueryResponse response = null;
try {
response = server.query(params);
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
SolrDocumentList results = response.getResults();
return results;
}
/**
* 按查询结果删除索引.还支持按ID删除,批量删除等.
* @param q 要删除的查询语句
* */
public boolean delIndex(String q){
//如果不是SolrCloud 则类似下面的写法
//HttpSolrServer server = new HttpSolrServer("http://localhost:8983/solr");
try{
if(server==null){
server = new CloudSolrServer(Constent.ZKHOST);
server.setDefaultCollection(Constent.COLLECTION);
}
}catch(Exception e){
return false;
}
try {
server.deleteByQuery(q);
server.commit();
} catch (SolrServerException e) {
return false;
} catch (IOException e) {
return false;
}
return true;
}
}
CreateData.java
package com.iflytek.test.solr.core.test;
import gg.mine.tools.io.local.ReadFileByLine;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import com.iflytek.test.solr.core.IndexAPI;
import com.iflytek.test.solr.data.ContactInfo;
public class CreateData {
/**
* 读取文件并转换为联系人列表
* @param file 文件名
* @return 返回联系人的List
* */
private static List<ContactInfo> fileToDataList(String file){
ArrayList<String> lines = ReadFileByLine.getAllLine2Array(file);
List<ContactInfo> result = new LinkedList<ContactInfo>();
for(int index=0;index<lines.size();index=index+3){
ContactInfo instance = new ContactInfo();
instance.setName(lines.get(index));
instance.setAddress(lines.get(index+1));
instance.addPhone(lines.get(index+2));
result.add(instance);
}
return result;
}
public static void main(String []a){
List<ContactInfo> list = fileToDataList("data/ContactInfo");
if(list==null){
return;
}
IndexAPI indexer = new IndexAPI();
for(ContactInfo info:list){
if(indexer.addIndex(info)){
System.out.println("添加成功!");
}else{
System.err.println("添加失败!"+info.getName());
}
}
}
}
添加后访问 http://192.168.39.250:8080/solr/YellowPages/select?q=%3A&wt=json&indent=true 即可看到添加成功
SearchIndex.java
package com.iflytek.test.solr.core.test;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import com.iflytek.test.solr.core.IndexAPI;
public class SearchIndex {
private static void printDocument(String q,SolrDocumentList list){
System.out.println("查询语句: "+q+"\n\n");
if(list==null){
return;
}
for(SolrDocument cur:list){
System.out.println("名字 "+cur.getFieldValue("name"));
System.out.println("地址 "+cur.getFieldValue("address"));
System.out.println("电话 "+cur.getFieldValue("phone"));
System.out.println();
}
}
public static void main(String []a){
IndexAPI indexer = new IndexAPI();
String q = "all:合肥的数理化辅导班";
SolrDocumentList list = indexer.searchIndex(q);
printDocument(q,list);
q = "all:北京的辅导班";
list = indexer.searchIndex(q);
printDocument(q,list);
q = "all:13965121809是谁的电话";
list = indexer.searchIndex(q);
printDocument(q,list);
}
}
运行结果
查询语句: all:合肥的数理化辅导班
名字 合肥博强教育管理咨询有限公司
地址 合肥刘博士数理化一对一、精品小班、艺术生文化课快速提分
电话 [4008806400]
名字 尚助教育辅导中心
地址 合肥宁国路
电话 [13966662351]
名字 新脑力教育
地址 合肥天鹅湖
电话 [13965121809]
名字 京翰1对1辅导 中小学课外辅导专家
地址 北京京翰英才教育科技有限公司
电话 [4008116268-2880]
查询语句: all:北京的辅导班
名字 尚助教育辅导中心
地址 合肥宁国路
电话 [13966662351]
名字 京翰1对1辅导 中小学课外辅导专家
地址 北京京翰英才教育科技有限公司
电话 [4008116268-2880]
查询语句: all:13965121809是谁的电话
名字 新脑力教育
地址 合肥天鹅湖
电话 [13965121809]
package com.iflytek.test.solr.core.test;
import com.iflytek.test.solr.core.IndexAPI;
public class DelIndex {
public static void main(String []a){
IndexAPI indexer = new IndexAPI();
indexer.delIndex("id:2212087180485603235");
/**
*{
"id": "2212087180485603235",
"name": "提高记忆力3-5倍,让学习更轻松、快乐、高效",
"address": "新脑力教育",
"phone": [
"13965121806\t"
],
"_version_": 1447136747670470700
},
*
* */
}
}
注意:在真实环境中 没有必要每个请求都commit 和 optimize,这两个操作都是比较耗时的.具体可以依据生产环境来决定多长时间commit一次
7 Solr管理
Solr在搭建成功后会提供一个管理页面.也就是上面截图中看到的
包括
Dashboard 仪表盘,可以看到系统的运行状态,JVM参数等
Logging 系统日志.可以看到警告,提示信息.
Logging/Level 对日志级别的设置.即上面级别的日志可以被记录Log
Cloud /Graph 云监控平台,可以看到有哪些Collection部署在哪些机器上,及分片和主从的信息
Cloud/Tree 配置文件的树信息
Cloud/dump JSON格式返回服务器的状态信息
Core Admin 核心(Collection)的配置信息
JavaProperties Java的运行参数
Thread 线程的堆栈信息
集合页面
OverView 运行信息.可以在这个页面上优化索引
Analysis 分词界面.可以测试分词效果
Config 显示配置文件SolrConfig.xml
Document 追加/修改文档
plugins 显示加载的插件及插件状态
Query 查询页面
Replication 是否已经数据备份
Schema 字段信息schema.xml
SchemaBrowser 以UI查看字段和类型信息