mule in action翻译9 : 2.1 流
2.1 流
流是mule配置中最重要的元素。
一般流的起点是一个消息源,随后是一系列消息处理器。这些处理器以流元素的形式串联起来。
向流中添加处理器时,没有处理器的类型的限制,也没有顺序的限制。
来看1.4.2中的产品注册的流。
清单2.1中 稍微修改了这个流,添加了个logger元素。
Listing 2.1 The product registration flow, now with logging
<flow name="product-registration"> <http:inbound-endpoint address="http://api.prancingdonkey.com/products" method="POST" /> <byte-array-to-string-transformer /> <logger level="INFO" category="products.registration" /> <jms:outbound-endpoint queue="products" /> </flow>
Mule Studio中的流 如图2.1。

那个是消息源?哪些是消息处理器?看图2,2
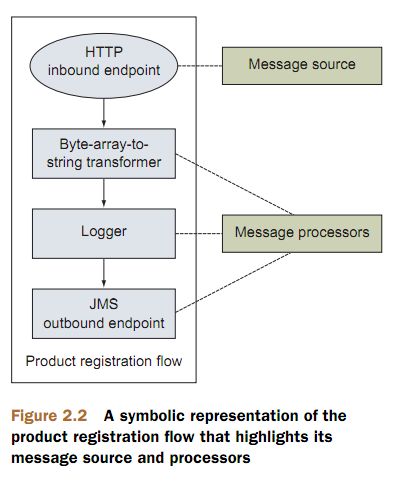
图2.2中采用椭圆表示消息源,矩形表示消息处理器,本书其余部分示图遵此惯例。
在流中 ,消息源生成消息然后以从上到下的顺序被消息处理器处理。
顺着上图箭头很容易的看明白,消息是一步步被处理的。
在稍后章节你会明白消息路线是可以被一些消息处理器改变的,
比如路由消息处理器允许你控制消息执行路线。
若流中的一个消息处理器返回了null ,处理将立即终止。
一般的转换器和组件不会返回null,只是可能返回nul的payload,这不会影响执行流程。
mule提供了特殊的流元素,叫 配置方式,6.2节详解。
到此为止我们只考虑了流的一个方向:自上而下。这是消息进入mule并被处理的路线。
但返回的路呢?来看流如何处理响应。
2.1.1 响应阶段
理解mule的响应阶段非常重要。
首先要明白响应阶段是隐含的;它总会出现,默认是由请求阶段的终点生成的回应消息构成。
尽管不明显但listing 2.2 中的流是有响应阶段的
Listing 2.2 A flow with an implicit response phase
<flow name="accountService">
<http:inbound-endpoint exchange-pattern="request-response"
host="localhost"
port="8080"
path="services" />
<jersey:resources>
<component class="com.prancingdonkey.resource.Accounts" />
</jersey:resources>
</flow>
Mule Studio展示的响应阶段表明显。见图2.3
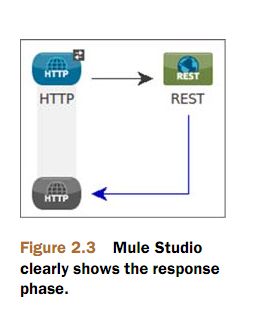
底部向左的箭头表示响应阶段。
用来组成响应的 payload和属性,来自于流终点处理后的mule消息。
当流包含分支时 可能包含多个终点,这时是在某分支的终点生成响应。
通过一个特殊的配置元素“response”,可以控制响应阶段。它是只在
响应阶段才被调用的消息处理器。
需要注意的是这些“response”信息处理器是按照相反的顺序被调用的--从下往上,
或者更精确的说是从流的终点向起点的顺序。
看listing 2.3 的配置,如果我发出一个payload内容是“hello”的消息,最后反会的将是什么结果?
Listing 2.3 A flow with elements explicitly in the response phase
<flow name="explicitResponse">
<vm:inbound-endpoint path="input" exchange-pattern="request-response">
<response>
<append-string-transformer message=" web" />
</response>
</vm:inbound-endpoint>
<response>
<append-string-transformer message=" wide" />
</response>
<append-string-transformer message=" world" />
</flow>
答案是 “hello world wide web” 。
string appender 按照下面顺序被调用:请求阶段追加了“world”,响应阶段追加了“wide”和“web”。
注意我们是如何在主flow 和 endpoint中添加response元素的。
response元素运行你执行所有必要的处理,以保证返回给流的调用者想要的结果。
为了处理有组件或outbound endpoint产生的payload,你已经在响应阶段执行了
具有代表性的消息转换器。
最后,如果 响应是由reply-to路由返回的,则响应阶段会被忽略。这种情况下,请求阶段的
终点的消息状态作为响应返回。消息处理器会被执行,但他们的处理结果将被丢弃。
2.1.2 子流
复制粘贴是软件开发的祸根。
如果你发现你的流有很多共同的东西 ,你应该提取出这些 共同的消息处理器片段,以实现重用。
子流,就是因此产生的。
子流的行为和标准的流一样,只是它没有消息源。当显示的调用“ flow-ref”元素时 ,它才进行消息处理。
你可以把 子流看成一个包含了一组预定义的消息处理器的“宏”,你可以随时调用它。
当一个流调用子流时,整个mule 消息和上下文消息都会传递为子流。子流的处理结果的整个的上下文消息也会传递给
主流。实际上子流的消息处理器的处理方式和主流中的一样。
另外注意,调用线程去执行子流。
一个有名字的链 一个子流是一个处理器链,它有自己的名字,可以独立存在于主流之外, 可以被任意流调用。
它和你的办公套件中的 “宏“非常的类似。
listing 2.4 展示了Prancing Donkey 公司是如何使用子流作为通用的转换器链。列表中你看到他们是如何在子流、
中使用一组转换器并在其它两个不用的流中进行重用的。流经这两个流的消息都会被这组转换器转换,看起来
他们好像是直接配置在这两个流中的。
Listing 2.4 Using a subflow to share a common set of transformers
<sub-flow name="legacyAdapterSubFlow">
<mulexml:xslt-transformer xsl-file="v1_to_v2.xsl" />
<mulexml:xml-to-object-transformer />
</sub-flow>
<flow name="mainFlow1">
<http:inbound-endpoint host="localhost" port="8080" path="v1/email" />
<flow-ref name="legacyAdapterSubFlow" />
<component class="com.prancingdonkey.service.v2.EmailGateway" />
</flow>
<flow name="mainFlow2">
<jms:inbound-endpoint queue="v1.email" />
<flow-ref name="legacyAdapterSubFlow" />
<component class="com.prancingdonkey.service.v2.EmailGateway" />
</flow>
图2.4 是对上面代码的 表示
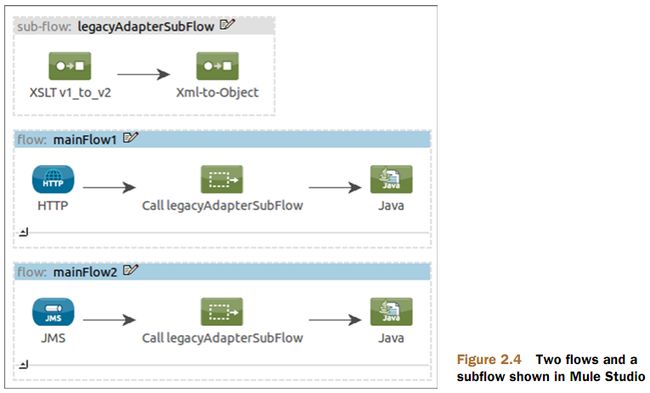
这是非常简单的。
你经常会遇到需要重用的情况,但是又不能清晰的抽取出一组处理器来重用。
请记住流变量(invocation-scoped message properties)可以帮助重用,因为它们可以作为流控制变量。
举例说明,请看 listing 2.5的子流。
流变量”valid“决定了如何选择下一步。每个父流程都必须基于正确的规则来设置好这些消息属性,以使能正确路由。
Listing 2.5 Flow variables can be used to parameterize a subflow.
<sub-flow name="requestDispatcher">
<choice>
<when expression="#[valid]">
<vm:outbound-endpoint path="valid.request.handler" exchange-pattern="request-response" />
</when>
<otherwise>
<vm:outbound-endpoint path="invalid.request.handler" exchange-pattern="request-response" />
</otherwise>
</choice>
</sub-flow>
如果你有使用mule 3之前版本的经验,你必定会使用很多VM endpoints 把services捆起来。
一直使用子流或者 使用VM endpoints把流集中起来 ,这样做正确吗?
两种方式一个很大的区别是子流程会传递所有的消息属性,
而VM endpoint 只交换作用域内的需要复制的属性。
另一方面,使用VM队列去连接流降低了耦合度,这在某种情况下是很有用的。
mule提供另外一种共享流的方式叫做 私有流。来看子流和私有流有什么不同。
2.1.3 私有流
私有流是另一种类型的可重复使用的流量,非常类似于子流,但它在线程和异常方面处理不同。
使用私有流而非子流的主要原因 需要设置与调用流不用的异常处理。另外一个原因是,
子流在运行时不是具体化的,没有特定的统计数据或调试属性不能进行独立的控制和监控。
而私有流提供了这些东西。
如上一节所言,调用一个子流时,执行的行为好像就在这些处理器就在”调用流程“
(--这里相对于被调用而言)之中一样。这种解耦导致私有流可以定义自己的消息处理和错误处理。
那么,一个私人流是什么样子?基本上它只是一个普通的流,但没有任何消息来源。
为了说明这一点,让我们重新使用Prancing Donkey公司的子流 把消息从旧格式转换
到一个新格式(见清单2.6)。
消息的一小部分转换失败,然后他们决定配置本地的异常行策略,以便把失败的消息发送
到JMS队列中供以后分析和再加工。
Listing 2.6 Using a private flow to define a local exception strategy
<flow name="legacyAdapterPrivateFlow" processingStrategy="synchronous">
<mulexml:xslt-transformer xsl-file="v1_to_v2.xsl" />
<mulexml:xml-to-object-transformer />
<catch-exception-strategy>
<jms:outbound-endpoint queue="legacyAdapter.failures" />
</catch-exception-strategy>
</flow>
处理策略 上例中我们在一个私有流中配置了一个属性叫”processingStrategy“ ,这不是必须的,
但我们强烈建议在你所有的私有流进行这个配置。设置成synchronous还是asynchronous,要取决于
调用流。(若调用流希望私有流生成响应配置成synchronous)
如果你没有指定处理策略,mule将根据流入事件的同步性来选择一个。one-way endpoints产生的事件
将按照异步来执行,即使 调用流希望私有流返回响应。第11章深入讨论处理策略。
同样 ,我们强烈建议使用 flow-ref 封装进行异步处理私有流的 <async> 。
在Mule Studio中 需要注意的一点是私有流和子流的区别是私有流名字前的”灰色“的标签,
就是图2.5显示 flow字样的部分。

到目前为止我们只是关注流和控制,这使我们大致了解mule内部消息的传输。
现在我们来看mule支持的和消息交互的细节及相关的一些概念。