初始大数据处理--NoSQL之MongoDB
Ø 问题背景
UMC监控对计数器数据绘图,描绘曲线的走势。默认3秒钟获取一个样本,当跟踪时间拉长到1周时,计数器数据可能达到千万级别。要在有限的图表上描绘这么多节点,是不可能的,无法看清晰去曲线走势。
问题简化方案:
本质上是一个数学问题,不计较标准偏差,可以对数据二次加工,计算每5分钟的最大值、最小值、平均值,用5分钟一个样本描绘走势。
算法描述:
将原始时间Createtime和最小创建时间做差,精确到秒,DateDiff(minute,@minDate,Createtime),用差值除以需要的时间间隔取模,如间隔5分钟,这样5分钟内所有的数据被划分为一组,使用计数器分类、名称等相关信息和加工后的时间共同分组,计算Max值,即为5分钟一个样本。
SQL 实现:
Select max(value) from perflog group by [计数器名称], [分类], …. ,DATEADD(minute,DATEDIFF(minute,@minDate,createtime)/@Interval*@Interval,@minDate)
SQL 优化:
相关计数器分组的字段较多(~10个),我们将不变的部分构造成一个Bizkey,使用Bizkey+ DateADD分组,减少分组依据。SQL Server选择并行索引扫描,快速计算结果。优化后,执行时间从原始 2分钟提高到16秒。这里感叹下,简单统计SQL引擎确实很强,并行扫描极大的提高了计算时间,索引扫描又降低了IO读取,~800w数据分组排序,执行16秒基本已经达到了关系数据库的极限。
Ø NoSQL介绍
先了解下流行的NoSQL:
1. 文档数据库,典型代表:MongoDB
优势:
a) 文档数据库将集合按范围横向切片,假设TableA中10条数据,1~10,三个节点A、B、C,数据分布可能为3,3,4。当数据量增大时,数据会自动分布到多个节点,对应用透明。数据分布的均匀程度,决定了性能的高低。
b) 文档数据库更接近关系数据库,可以把相似结构文档放在一起,建立索引,支持类SQL查询。
c) MongoDB 2.2版本以上增加了Aggregate Framework,无需自己实现Map/Reduce,可以通过Json方式进行Max、Min、Group等多种查询。
d) 支持O/R Mapping。
e) 支持分布式集群Sharding。
劣势:
a) 非内存数据库,通过操作系统虚拟内存映射,实现缓存,内存换页效率波动较大。
b) 存储空间较大。
2. 列式存储数据库,典型代表:HBase
优势:
a) 列式存储,更适合稀疏数据,存储空间小。相关列可以定义列簇,同一列簇存储在同一物理块上,不同列簇可分不到不同节点,数据纵向切分。
b) 支持分布式集群HDFS。
c) 扩展性好,稳定,基于Hadoop,轻松实现Map/Reduce。
劣势:
a) 不支持类SQL。
b) 环境部署较复杂。因为HDFS分布式文件系统是其核心,对速度要求非常高,仅支持类Linux。插曲:之前为了部署一个Hadoop环境,用Windows+Cygwin+Hadoop+HBase,折腾了一周多,反编译Jar包、重编译、各种文件路径、权限错误,后来开源项目上发现有的版本声明不再解决由Cygwin引起的异常。遂放弃改用Ubuntu,很快搞定。
3. Key/value数据库,典型代表:Redis
优势:
a) 一个字,快。
b) 支持O/R Mapping。
c) 默认支持Hash、List、Key/Value、SortSet等多种存储方式,基于Json序列化/反序列化,效率较高。
d) 支持集群
劣势:
a) 更多用作缓存,数据统计工作依赖代码实现Map/Reduce。
简单认识了几个流行的NoSQL,我选择了MongoDB实现UMC的统计。原因只有一个:代码简单,合适的工作做适合的事情。
Ø MongoDB版代码实现
MongoDB有不少支持.NET的驱动,我选择了 官方驱动+MongoDB 2.4版本,(至于为什么选这个版本,后面再说) + Aggregate Framework(2.2版以上支持) + Json.NET + C# 实现。这样的实现方式最简化,代码见附件。
Ø 测试结果
很遗憾,测试结果45秒。执行过程中发现多核服务器只跑满了一个核。MongoDB的Aggregate Framework实际上就是Map/Reduce的默认实现,而当前Map/Reduce框架是单线程执行,MongoDB考虑后续版本引入多线程。So Cool! J
Ø MongoDB Sharding
既然做了,就干脆彻底!45秒还没有SQL快,是Mongo不行,还是我弱?呵呵,答案是肯定的,一定是我用法不好。
MongoDB并非内存数据库,它的优势在于横向扩展,这也是传统DB处理大数据时难以逾越的鸿沟。那么,接下来,引入Sharding集群。
部署环境:
Int6 16G内存,8核服务器。单台机器上部署三个节点,使用不同端口,8887,8888,8889。
优化后结果:
56秒!崩溃。。。。。哪出了问题??
再观察执行过程,开始几秒阶段,3个Mongo进程一同执行,仅仅几秒后,就一直是1个进程执行了。问题应该就在这里!察看三个节点上的数据分布:
Sharding 0000:12w数据
Sharding 0001:700w数据
Sharding 0002: 80w数据
靠,MongoDB号称的Auto-Sharding思想真的是理论上的巨人,实现上的鸡肋???
Auto-Sharding是Mongo 2.x版引起广大震撼的一个特性,它负责将数据均匀分布到多个节点,理论上类似细胞分裂,当一个Chunk的数据量达到一定规模,自动分裂成两个,然后Balancer进程负责把数据转移到其他节点。数据是否均匀,决定于ShardingKey的选择,但2.2版本中只有一种范围选择,可以指定某列做key,但是还要开发者对数据分布、Sharding机制充分了解,数据分布才能更均匀,我想,真的只有全职数据维护的人,才能作这个工作。阿里巴巴好像有专人定时手工Move数据。。。。。
Ø MongoDB Hashed Sharding
Mongo 2.4版本,实现了Hash key的Sharding机制。之前的伏笔揭开,这也是我后来选择2.4的原因。
启用hash sharding:
db.runCommand({shardcollection:"umcdb.umcperflog",key:{_id:"hashed"}})
查看数据分布:
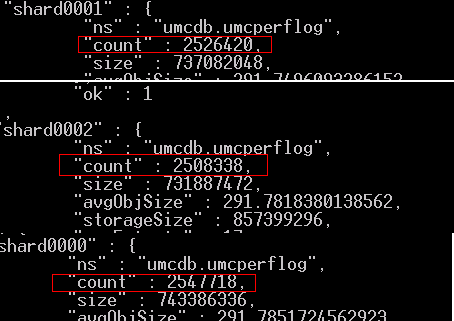
Sharding0000~0002三个节点上数据分布非常均匀,Good!
执行结果:
见证奇迹的时刻….14秒!!

整个过程中,3个进程协同工作,非常平稳,随着节点数量增加,海量数据的分析会更快!而我们呢,代码完全不同改动,受益于NoSQL的横向扩展,太cool!