前端笔试面试题
前段时间去某公司(不是BAT)面试实习生~在这分享一下提及的知识点~还有笔试题目等~
一去到,先不计时的一份笔试题~写完跟他说就好了~貌似我大概用了差不多一个小时吧,12道题的样子,不过我已经全部记得了~我说说我记得的吧,顺便贴一下,我回来之后去找的答案~
1,谈谈前端性能的优化,分别说说CSS,JS有哪几种优化方式?
当时给我写的空间略小,我就简单写了一下比较常见的CSS置header,JS置body底部,优化图片的大小,有sprite图来减少HTTP请求,合并重复的CSS,JS代码等等,后来想想写的还挺少的~不过后来面试没问到~
然后我找到的答案是~说真的不少的赶脚~
对于为什么要尽量减少 HTTP 请求 ,其实我之前并不是很了解,刚刚找了一下发现前端乱炖有篇文章讲得挺详细的~
http://www.html-js.com/article/Number-of-requests-from-reduced-about-http
①CSS的优化
1. 把 CSS 放到代码页上端 (Put Stylesheets at the Top)
2. 避免 CSS 表达式 (Avoid CSS Expressions)
3. 从页面中剥离 JavaScript 与 CSS (Make JavaScript and CSS External
4. 精简 JavaScript 与 CSS (Minify JavaScript and CSS)
5. 使用 <link> 而不是@importChoose <link> over @import
6. 避免使用Filter (Avoid Filters)
①Javascript的优化
1. 脚本放到 HTML 代码页底部 (Put Scripts at the Bottom)
2. Make JavaScript and CSS External
3. 精简 JavaScript 与 CSS (Minify JavaScript and CSS)
4. 移除重复脚本 (Remove Duplicate Scripts)
5. 减少 DOM 访问 (Minimize DOM Access)
附上Yahoo前端优化性能规则
http://segmentfault.com/a/1190000000735395
最近翻博客的时候,有人提出前端优化应该不应忽视的HTML的优化~
http://www.infoq.com/cn/news/2010/05/baidu-html-optimize
2,盒子模型,标准模型(strict mode)和怪异模型(quirks mode)的区别
这个我直接给他两个图,两句解释一下完事~
IE盒子模型即怪异模型~
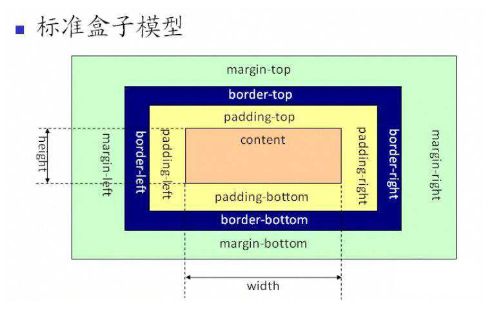
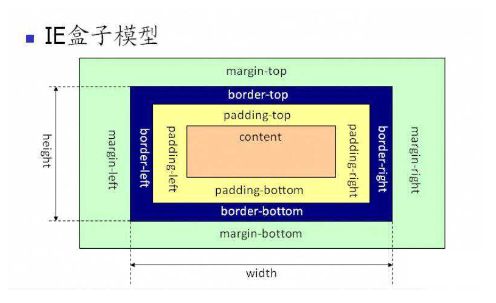
更多见:http://www.heshare.com/201308/419.html
3.谈谈语义化的理解
1,去掉或者丢失样式的时候能够让页面呈现出清晰的结构2,有利于SEO:和搜索引擎建立良好沟通,有助于爬虫抓取更多的有效信息:爬虫依赖于标签来确定上下文和各个关键字的权重;3,方便其他设备解析(如屏幕阅读器、盲人阅读器、移动设备)以意义的方式来渲染网页;4,便于团队开发和维护,语义化更具可读性,是下一步吧网页的重要动向,遵循W3C标准的团队都遵循这个标准,可以减少差异化。
4.什么是闭包,写一个简单的闭包~谈谈闭包的优缺点
之前看了很多解释都挺晕的~最近看了一篇感觉是我看过讲得最详细最好的~
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Closures
闭包优点1.希望一个变量长期驻扎在内存中2.避免全局变量的污染3.私有成员的存在
闭包缺点:过度使用闭包会导致性能的下降。函数里放匿名函数,则产生了闭包;产生内存泄露问题,由于IE的js对象和DOM对象使用不同的垃圾收集方法,因此闭包在IE中会导致内存泄露问题,也就是无法销毁驻留在内存中的元素
5.call() 和 .apply() 的区别和作用?
这两个方法的用途都是在特定的作用域中调用函数,实际上等于设置函数体内this对象的值。它们的区别仅在于接收参数的方式不同,apply()方法接收两个参数:一个是在其中运行函数的作用域,另一个是参数数组。其中,第二个参数可以是Array实例,也可以是argument对象。而在使用call()方法的时,传递函数的参数必须逐个列举出来。如下
Sum.apply(this, argument) 或 sum.apply(this, [num1,num2])
Sum.call(this, num1, num2)
更详细的解释可见:http://segmentfault.com/a/1190000000660786#articleHeader15
6.用两种方式进行数组去重
第一种是比较常规的方法思路:
1.构建一个新的数组存放结果
2.for循环中每次从原数组中取出一个元素,用indexOf查找新数组中是否有该元素
3.若没有,则存到结果数组中
Array.prototype.unique=function(){
var outArr=[];
for(var i=0;i<this.length;i++){
if(outArr.indexOf(this[i])==-1){
outArr.push(this[i]);
}
}
return outArr;
};
第二种方法比上面的方法效率要高
思路:
1.先将原数组进行排序
2.检查原数组中的第i个元素 与 结果数组中的最后一个元素是否相同,因为已经排序,所以重复元素会在相邻位置
3.如果不相同,则将该元素存入结果数组中
Array.prototype.unique2 = function(){ this.sort(); //先排序
var res = [this[0]];
for(var i = 1; i < this.length; i++){
if(this[i] !== res[res.length - 1]){
res.push(this[i]);
}
}
return res;
}
var arr = [1, 'a', 'a', 'b', 'd', 'e', 'e', 1, 0]
alert(arr.unique2());
第二种方法也会有一定的局限性,因为在去重前进行了排序,所以最后返回的去重结果也是排序后的。如果要求不改变数组的顺序去重,那这种方法便不可取了。
第三种方法(推荐使用)
思路:
1.创建一个新的数组存放结果
2.创建一个空对象
3.for循环时,每次取出一个元素与对象进行对比,如果这个元素不重复,则把它存放到结果数组中,同时把这个元素的内容作为对象的一个属性,并赋值为1,存入到第2步建立的对象中。
说明:至于如何对比,就是每次从原数组中取出一个元素,然后到对象中去访问这个属性,如果能访问到值,则说明重复。
Array.prototype.unique3 = function(){
var res = [];
var json = {};
for(var i = 0; i < this.length; i++){
if(!json[this[i]]){
res.push(this[i]); j
son[this[i]] = 1;
}
}
return res;
}
var arr = [112,112,34,'你好',112,112,34,'你好','str','str1'];
alert(arr.unique3());
除了上面那些,还经常被面试官要去现场用js手写一些简单的数据结构,例如二分法查找,排序等等~还有被问到几次的就是写一个闭包,用js写一个类的继承等等~
最后贴一下我之前看到算是比较全的前端面试题:
http://segmentfault.com/a/1190000002562454
希望以上对大家有用~在准备实习面试的期间,借这个机会真的学习到了很多~也算是在其中有所收获~谢谢~也希望对大家有用~