正则表达式在性能测试中的应用
小明终于用性能测试工具录制完成一个脚本,兴冲冲的点下回放按钮,结果满屏红字,整个人都不好了。
找到资深玩家强哥询问,答曰:“没做关联(注一)”。
接着发过来一篇正则表达式(注二)的入门页面说:“先自学吧”。
“啥?关联和正则表达式都是什么鬼?”
求此时小明同学此刻心里阴影面积。
开篇故事是每个初入性能测试行当的人都可能遇到的一个比较挠头的问题。作为IT行当的基本功之一,正则表达式广泛应用于数据提取,模式匹配等多个方面。性能测试过程中的数据关联自然也逃脱不了。每当遇到,驱动Google(呃,还是百度吧,你懂的)一搜,问题解决,下一个。然而前人问题答案不一定完美匹配当下问题,还是得自己动手,丰衣足食。此篇文章便是来八一八这类问题。
正则表达式基本语义:
正则表达式起步一般都从. * ?三兄弟开讲,一般还要把+小弟算上凑成四大金刚。话说 . * ?三兄弟在DOS(九零后同学又问了:DOS又是啥玩意?呃,这个还是改日再说。八零后的兄弟姐妹们至少有所耳闻吧?说起来都是梗,有空再来八)环境下的模式匹配也曾是解决了不少问题的,当时也没听说过什么正则呀?到底模式匹配和正则是好基友还是相爱相杀?这个感情戏还是给那些写手去编吧,咱们后面就只讲干货了。还是一个一个的分头讲,这样能清楚点:
.
在DOS(呃,还是说命令提示符吧,好歹还能在开始菜单找到)下就是匹配 . 这个符号的,其他啥都不是。(在那个8.3还要区分主文件名和扩展名的时代……呃,还是不多说了。)
在正则表达式环境中,.可以匹配任意一个字符,可以是数字123,也可以是英文字符abc,还可以是特殊字符+-*一类。总之只要是能敲到显示器上能占位置的字符它都能匹配。
*
在命令行(命令行又是什么鬼?自己悟吧!)下,它才是用来匹配任意一个字符的东西。和正则表达式中的.的作用基本一样。
在正则表达式中,它是用来限定前一个字符的出现次数的,表示前一个字符出现0次到任意次。现学现卖:.*表示匹配任意长度的字符串,可以是什么都没有的空字符串,也可以是3.141592653589793……这样的数字,也可以是 蒸羊羔,蒸熊掌,蒸鹿尾儿......(说着说着都饿了。好了,下不为例)这样的字符串,无论有多长都可以匹配。
?
在命令行中它是用来表示出现次数0次到1次的一个字符。举个例子,一个目录下有这么几个文件: a.xls a.xlsx a.xlsm a.xlsmx。命令行下敲 dir a.xls? 可以显示出a.xls a.xlsx a.xlsm 但是a.xlsmx就不能匹配了,因为后面多出来了两个字符,超出?的匹配范围了。
在正则表达式中和命令行有点类似但不完全一样。它是表示前一个字符或者准确的说前一个子表达式出现0次到一次,如果要像命令行中那么用,得写成a\.xls.?(前一个.就精确匹配一个点,所以要转义,若不转义,则能匹配到abxls这样的字符串)。比命令行下的略复杂一点,但可以控制是哪些特定字符出现零次到一次。
+
在命令行的模式匹配中+就是加号的意思,没有任何特殊的含义。
在正则表达式中,+也是是用来限定前一个字符的出现次数的,表示前一个字符出现至少一次到任意次。也就是说被它限定过的不能是空串,至少得有点东西。.+是除了空字符串匹配不上外,剩下的.*能匹配的,它都能匹配。
不知道上面的几个重点理解了多少,现在再说点正则表达式中简单点的东西,综合起来举例说明也就清楚了:
\ :用来对后面的具有特殊含义的字符进行转义,比如前文出现的\.就是匹配单个.而不是任意字符。要匹配\本身的话,则要写两个\\。
[]:用来枚举所有可能出现的字符集合只要是在[]里面出现的就都能匹配,不出现的则不能匹配,[+-*/]就是用来匹配加减乘除任意一个的。但不能匹配%。
{m,n}:m和n都表示数字。用来限定前一个字符或表达式出现次数的下限和上限。{,n}下限忽略表示最少零次,{m,}上限忽略表示任意多次,{m}只写一个的话表示次数精确限定。例如.{3,5}就是用来匹配3到5个任意字符的字符串。
():用来划范围的,有时后面会跟之前讲到的*?+一类的修饰符,表示这一组出现多少次,而不是之前那种只对单个字符限定出现多少次。举例说明:(abc)?就表示abc要么一起出现一次,要么都不出现,如果写成abc?就成了匹配ab或abc这种的了。还有一种用法是在后续还要引用的时候会用到(),后面遇到了再说。
0-9:用来匹配单个数字字符,因为是范围集合,所以要写成[0-9],如果要匹配不为零的数字则写成[1-9],只匹配4到7的话就是[4-7]。1到9但不匹配5的话就是[1-46-9]。这里需要再强调一下,本示例下都只能匹配一位数字,若要匹配多位数字的话,就得在后面加上+*一类的修饰符,比如匹配所有大于零的整数就写作[1-9][0-9]*。
a-z:用来匹配单个小写字母,也因为是范围集合,所以写成[a-z],同理只匹配a到h的话,就写成[a-h]。
A-Z:大写字母同理,不再赘述。
^:写在正则表达式最前面时,表示字符串开始或行开始;写在[]里面一开始时,表示取反的意思。举例说明^[^0-9]表示字符串以非数字字符开始。如果不是正则表达式中的第一个字符则没有行首的含义了,只是一个普通字符,[]内部若不是第一个字符,也没有了取反的含义,成为一个普通字符。
$:和^正好相反,写在正则表达式最后面时,表示字符串或行的结束,写在其他位置则成为一个普通字符,包括在[]内部。例如:匹配行首是$字符,行尾是^,中间是非双引号的任意字符时,就可以写作^$[^"]*^$。第一个^表示行首,首次出现的$因为不在正则表达式的结尾,所以只是普通的$符号,[^"]*表示不含有"的任意字符串可以是空,可以是abc,可以是123,但不能是"abc"(有双引号出现,所以不能匹配),接下来的^$因为^没出现在行首和方括号内部的第一个字符,所以就是一个普通字符,最后$表示^应为行尾的最后一个字符。
知道了上面这些,性能测试中的关联匹配基本就能玩的转了。
实战热身:
1、匹配一个32位的GUID:[0-9a-hA-H]{32}
说明:GUID一般为32位的十六进制数0-9a-hA-H是所有可能出现的字符类型{32}表示前面的这个匹配项正好匹配32次。
2、匹配一个国内手机号码如13800000000:1[3578][0-9]{9}
说明:第一位为1,第二位为3578中的一个,后面九位数字任意(为了简单举例,此处没有考虑后续位与第二位的关联情况,如一些没有开放的号段也能通过该正则表达式匹配上)。
3、匹配网页tag标记之间的字符串:<tag>(.*)</tag>
说明:此处匹配了<tag>和</tag>之间的那种任意的字符串,后续引用中一般用$1(或者\1看正则引擎的具体语法)便可使用这个字符串。
性能测试实例解析:
以HyperPacer为例,下图为一个脚本回放时与录制时的快照比对:
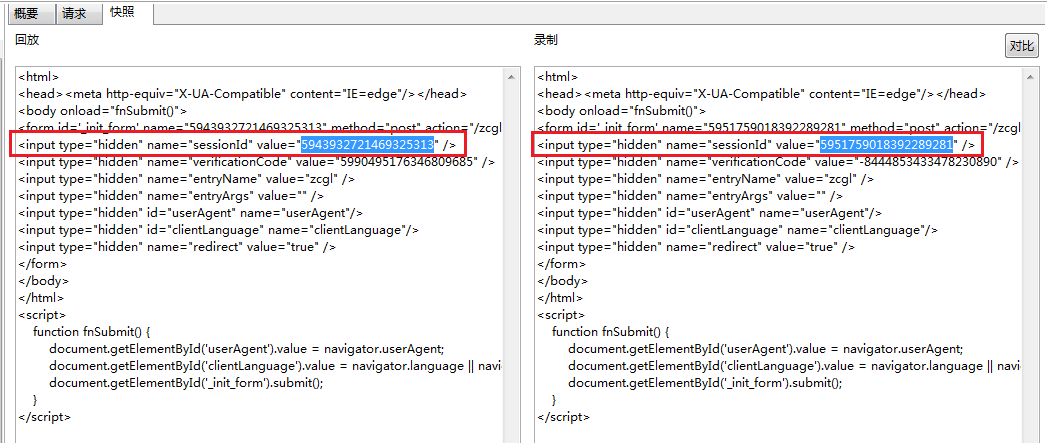
该请求的sessionId在回放的时候发生了变动,若要脚本正常运行,此处便要对其做关联操作。提取过程便需要添加正则表达式提取器,见下图:
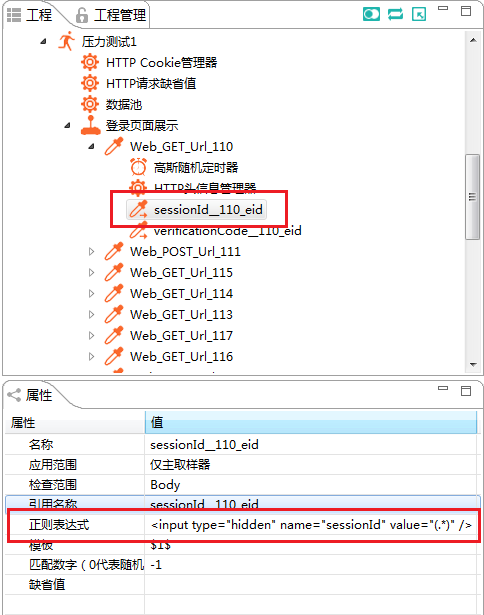
此处正则表达式需要提取sessionId的数值,故在数据产生行,将实际数值替换成(.*),将变量命名为sessionId__110_eid,多一句嘴:名字虽然可以任意起,但是最好起一个有意义的名字,方便脚本的查看调试。
其中的模板表示需要提取的分组$0$表示整个正则表达式匹配的字符串,1表示第一个圆括号包住的部分,2表示第二个圆括号包住的部分,以此类推。
匹配数字表示如果有多条数据匹配选哪一个,0就是从中随机选一个,如果写1就是取第一个匹配正则表达式的数据项,2就是取第二个匹配正则表达式的数据项,以此类推。
后面凡是原来sessionId数值出现的地方,均将其替换为${sessionId__110_eid_1_g1},便达到了关联的效果。这块解释一下:HyperPacer是基于JMeter进行的定制化开发,正则表达式体系采用了和JMeter一样的模式。_1_g1的后缀表示取出第一个符合正则的第一组数字。前一个1表示如果存在多个匹配项要取第几个的选项,组的概念是通过正则表达式中的()表示的。正则表达式中第N次出现的()分组,g后面就跟N。该实例中使用的是第一次匹配项中的第一分组。见下图:

替换完成后,可以再试跑一遍脚本看看替换是否达到预期,是否还有别的类似变量没有替换的,再逐一进行替换后,关联的工作基本就完成了。剩下就是驱动脚本撒丫子开跑让服务器压力山大了(中二病又犯了:P)。
全文完。
注一:简单说,关联就是把脚本录制下来的一些固定的数据替换成由服务器响应数据中动态提取的数据。举个例子:现在大多数服务器为确保和每个浏览器会话的一致性,通常会在首次发送响应数据时夹带一个唯一标识符,后续的交互都基于这个唯一标识符进行判断是不是同一个浏览器发来的。一般将该唯一标识符称作Session ID。每当有新的交互过程出现,都会生成新的Session ID。脚本直接回放失败的原因就是因为新的与服务器交互过程用了脚本录制中已经写死的旧Session ID,故而回放失败。
注二:正则表达式,英文全名regular expression(玩滑板的同学不要问我goofy expression,这个真没有。咱还是讨论讨论Ollie吧),英文简写regex、regexp或RE。中文部分文献中也译作正规表示式、正规表示法、常规表示法,其实都是一个意思。正则表达式是通过字符串来描述一类具有类似结构但又不完全相同字符串集合的句法规则,用于数据提取及模式匹配等诸多方面。