前端面试题:高效地随机选取数组中的元素
有前端题目大概是这样的:考虑到性能问题,如何快速从一个巨大的数组中随机获取部分元素。
比如有个数组有100K个元素,从中不重复随机选取10K个元素。
为了演示方便我们将数据简化,先给出方案最后再用大点的数据来测试性能的对比。
常规解法
常规做法倒也不难,生成一个0到数组长度减1的随机数,这个数也就是被选中元素在原数组中的下标,获得该元素后将值保存到另一个数组同时通过数组的splice方法将该元素从原数组中删除,以保证下次不会重复取到。
按以上思路,代码大概就是这样的:
//元素总数,为了方便演示这里取个小一点的数目比如5,表示总共5个元素
var TOTAL_NUM = 5,
//要取得的个数,表示我们要从原数组中随机取3个元素
COUNT = 3,
//用随机字符串初始化原数组
arr = new Array(TOTAL_NUM + 1).join('0').split('').map(function() {
return Math.random().toString(36).substr(2);
}),
//保存结果的数组
result = [];
console.log('原数组:', arr);
//开始我们的选取过程
for (var i = COUNT - 1; i >= 0; i--) {
//从原数组中随机取一个元素出来
var index = Math.floor(Math.random() * arr.length);
//压入结果数组
result.push(arr[index]);
//将该元素从原数组中删除
arr.splice(index, 1);
};
console.log('结果数组:', result);
运行结果如下图:
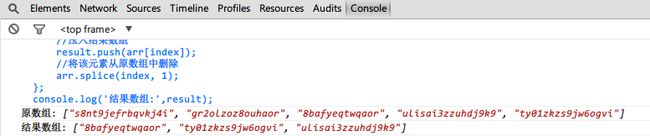
当然上面例子中为了便于演示,将题目要求的100 000 大数目简化为总数为5,同时只取3个。
由测试结果看这种做法是完全可行的。
但存在一个问题:为了下次随机时不重复选取已经选择过的元素,我们将选择过的元素从原数组中通过splice方法进行删除,但这个splice方法操作的过程本身就是数组重新维护其元素索引的过程,这意味着被选择的元素之后的所有元素需要前移一个位置来重新生成一个紧凑的数组,可以想象如果我们取走了原数组中的第1个元素,那么之后的99 999个元素都需要发生变动来完成重组数组的操作,无疑有点耗时。
利用洗牌算法
另一个思路可以是这样的,既然要随机选取,那我可以先把数组的元素打乱先,然后要多少就从开始取多少就行了。一提到随机,自然想到洗牌算法,而关于洗牌算法已经有一个非常经典且高效的Fisher-Yates算法了,这个算法我之前有写过一篇博客介绍过。
这个想法较之前的方法有点逆行的感觉,前面着重点是随机,所以每次都产生一个随机下标到原数组去取,现在是先将数组元素随机打乱,再去正常取。由于洗牌算法非常高效且省去了数组的重组,较之前性能应该有所提升。
照这个思路最后实现的代码大概就是这个样子的:
//元素总数,为了方便演示这里取个小一点的数目比如5,表示总共5个元素
var TOTAL_NUM = 5,
//要取得的个数,表示我们要从原数组中随机取3个元素
COUNT = 3,
//用随机字符串初始化原数组
arr = new Array(TOTAL_NUM + 1).join('0').split('').map(function() {
return Math.random().toString(36).substr(2);
}),
//保存结果的数组
result = [];
console.log('原数组:', arr);
//随机化原数组
arr = shuffle(arr);
//选取元素
result = arr.slice(0, COUNT);
console.log('结果数组:', result);
function shuffle(array) {
var m = array.length,
t, i;
// 如果还剩有元素…
while (m) {
// 随机选取一个元素…
i = Math.floor(Math.random() * m--);
// 与当前元素进行交换
t = array[m];
array[m] = array[i];
array[i] = t;
}
return array;
}
上面代码中包含了经典的洗牌算法Fisher-Yates Shuffle算法,即shuffle函数。具体可参见我的另一篇博客。
运行结果:

从结果来看,此种方法也是可行的。
细想还是存在问题,对于一个比较大的数组来说,不管你的洗牌算法多么高效(即使上面Fisher-Yates算法时间复杂度为O(n)),要随机整个数组也还是很庞大的工程的吧。
所以对于这个题目的探索还没有完。当我在stackoverflow上面发问后,虽然没得到什么惊人的回答,但有个回答却提醒我可以将上面的方法再次改进。
只取所需
那就是我们没有必要随机掉整个数组,在我们取完需要数量的元素后,可以将Fisher-Yates乱序方法中止掉!
思路是非常明显的了, 这样可以省下不少无意义的操作。
所以最后的实现大概成了这样子:
//元素总数,为了方便演示这里取个小一点的数目比如5,表示总共5个元素
var TOTAL_NUM = 5,
//要取得的个数,表示我们要从原数组中随机取3个元素
COUNT = 3,
//用随机字符串初始化原数组
arr = new Array(TOTAL_NUM + 1).join('0').split('').map(function() {
return Math.random().toString(36).substr(2);
}),
//保存结果的数组
result = [];
console.log('原数组:', arr);
//此段代码由Fisher-Yates shuflle算法更改而来
var m = arr.length,
t, i;
while (m && result.length < COUNT) {
// 随机选取一个元素…
i = Math.floor(Math.random() * m--);
t = arr[m];
arr[m] = arr[i];
arr[i] = t;
result.push(arr[m]);
}
console.log('结果数组:', result);
上面代码将Fisher-Yates算法略做修改,在取得满足要求的元素之后便停止了,所以较前面的做法更加科学。
运行结果:

性能比较
最后给出上面三个方法耗时的比较,这里将需要操作的数组元素个数回归到题目中要求的100 000来。
下图是jsperf上运行测试的结果,详情可点测试页面重新运行。数值越大越好。由上到下依次是本文中介绍的三种方法。

总结
目前PO主只能想到这些,更优的做法还有待进一步探究。
REFERNCE
由乱序播放说开了去-数组的打乱算法Fisher–Yates Shuffle http://www.cnblogs.com/Wayou/p/fisher_yates_shuffle.html