字符编码总结
编码字符集、字符编码
编码字符集:表示某种编码所涉及到字符的集合。例如ASCII字符集、GB2312字符集。仅表示集合,集合元素(即字符)按照某种顺序排放,并编上序号。如Unicode。
字符编码:把字符集中的字符编码为二进制,用来表示字符集中的字符,是字符集的实现方式。如UTF-8,UTF-16,UTF-32就是Unicode的实现。
一、欧美编码
发展关系
ASCII -> EASCII -> ISO 8859
ASCII
最初的ASCII只有七位(用于36位计算机),由ANSI协会于1963年公布首版标准。只能支持基础拉丁字符。
记得ANSI C标准吗?就是这个协会发布的。
注:我们现在通常说到ANSI编码,通常指的是平台的默认编码,例如英文操作系统中是ISO-8859-1,中文系统是GBK。
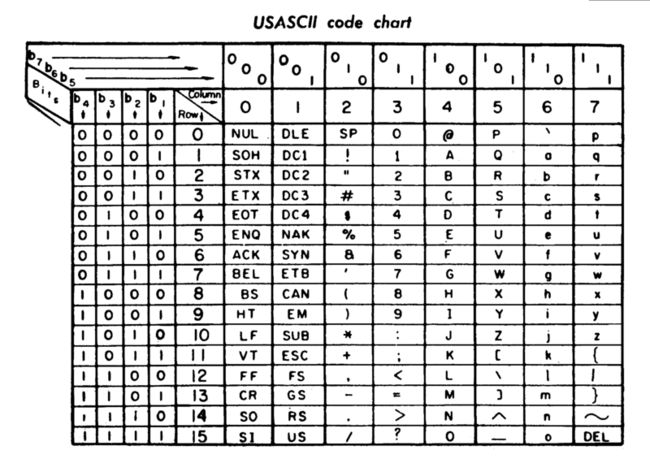
图片来自:https://en.wikipedia.org/wiki/ASCII
wikipedia:Eventually, as 8-, 16- and 32-bit (and later 64-bit) computers began to replace 18- and 36-bit computers as the norm, it became common to use an 8-bit byte to store each character in memory, providing an opportunity for extended, 8-bit, relatives of ASCII.
而随着8位、16位、32位开始替代18位和36位计算机,此时ASCII可以从7位扩展到8位,扩展后的ASCII称为EASCII。
EASCII(Extended ASCII)
EASCII兼容ASCII,在其前面扩展一位。它解决了部份西欧语言的显示问题。此外还扩充了符号,包括制表符、计算符号、希腊字母和特殊的拉丁符号。
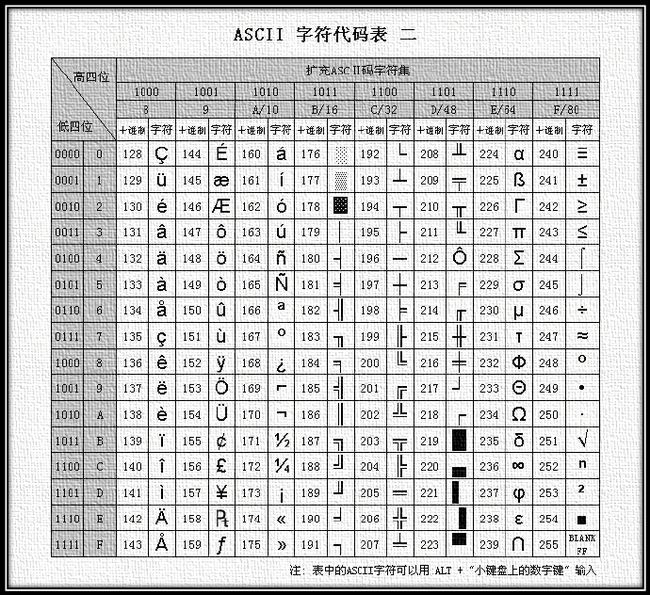
图片来自:http://blog.jobbole.com/86813/
虽然它解决了西欧字符的编码问题,但是对于欧洲其他地方却没有办法。于是出现了ISO 8859。
ISO 8859
ISO 8859是单字节编码,兼容ASCII。主要用于欧洲。
它本身不是一个标准,而是一系列标准,由15个字符集所组成。表示为ISO 8850-n (n = 1,2,3 ...11,13...16,没有12)。ISO 8859-1 有个别名:Latin-1,是西欧常用字符,包括德法两国的字母。
其00000000(0×00)-01111111(0x7F)范围段与ASCII保持一致,
而10000000(0×80)-11111111(0xFF)范围段被扩展用到不同的字符集。
二、中文编码
兼容关系
GB2312 -> GBK -> GB18030-2000 -> GB18030-2005GB2312与BIG5有冲突
GB2312有6763个汉字,GBK有21003个汉字,GB18030-2000有27533个汉字,GB18030-2005有70244个汉字。
GB 2312-1980
又简称为GB 2312或GB 2312-80。1980为该字符集发布年份。GB为国标(国家标准)拼音首字母。
GB 2312将ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符。
GBK
GBK中英文都用两个字节来表示,兼容GB2312,加入对繁体字的支持。K为扩展的Kuo首字母。
windows用CP936来实现对GBK字符集的编解码。因此有些地方charset=windows-936就是指GBK。
GB 2312的代码页为:CP20936
GB 18030-2000
GBK的取代版本,在GBK基础上增加了CJK统一汉字扩充区A的汉字。
CJK: China Japan Korea,中日韩
GB 18030-2005
在GB 18030-2000的基础上加上了CJK统一汉字扩充区B的汉字,以及少数民族的文字。
GB 18030与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。
BIG5
与GB2312有冲突。繁体字符集。Big->大写。
BIG5是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。BIG5虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。
BIG5-2003
2003年,Big5被收录到CNS11643中文标准交换码的附录当中,取得了较正式的地位。这个最新版本被称为Big5-2003。
Unicode
尽管人们能够在一台计算机上查阅不同语言的文档,但是一份文档无法同时使用多种编码。特别是在网络上,各个国家互相访问的时候,会出现乱码。Unicode就是用来解决这个问题的。
Unicode基于通用字符集(Universal Character Set)的标准来发展,它几乎涵盖了各个国家语言可能出现的符号和文字,并为它们编号。
Unicode中文范围 4E00-9FBF:CJK 统一表意符号。
Unicode就是一开始提到的编码字符集,而UTF-8、UTF-16、UTF-32就是字符编码,即Unicode规则字库的实现形式。
Unicode使用4字节的数字来表达每个字母、符号,或者表意文字。但是这样有一个问题:如果直接采用4字节的编码,那么就会浪费大量空间。例如,一个存储器本来可以存储800份以ASCII编码的文档,现在用Unicode编码,只能存储200份,这样大量的存储空间就被浪费了。
UTF-8巧妙地解决了这个问题。
UTF-8
UTF-8使用可变长的编码,例如ASCII部分仍然使用一个字节,中文用两个字节……。也因为如此,它没有实现所有的Unicode的字符,它只实现了Unicode的Plane 0(Unicode共有16个Plane。Plane 0又称为BMP,Basic Multilingual Plane)。
UTF-8的最小编码单位为一个字节。一个字节的前1-3个bit为描述性部分,后面为实际序号部分。其编码规则如下:
- 如果字节以0开头,则代表当前字符为单字节字符。
- 如果字节以110开头,则代表当前字符为双字节字符。其第二个字节以10开头。
- 如果字节以1110开头,则代表当前字符为三字节字符。其第二、第三个字节以10开头。
- 如果字节以10开头(如上两条),则代表当前字节为多字节字符的第二或第三个字节。
UTF-8与中文:
GB13000.1-1993的字符集包含20902个汉字。Unicode 标准目前在基本平面上与GB 13000保持一致。采纳UTF-16方案作为未来实现01到0F共15个辅助平面的方式。其它方面与GB 13000基本一致。
UTF-8与GBK的互相转换,是通过查表来实现的。因为UTF-8只是Unicode的一种实现,当它要转码时,要转换成Unicode码,查Unicode表。关于查表,我看了一下表,只有该字符集编码和对应的中文,并没有其他编码的码值。这样也是没用的啊,计算机只能识别0和1。
于是我推测了一下:编码字符集存储在数据库,在数据库中,对于一个字,同时存储了几种编码方式所对应的码。在A编码转换B编码的时候,在数据库中查找该字A编码的位置,接着读取其B编码。
UTF-8有其缺陷:在Plane 0外的字符,它是没办法的。而UTF-16可以应对这种情况。
UTF-16/UCS-2
UCS = Universal Character Set
UTF-16由UCS-2发展而来。UCS-2最初设计的时候只考虑到BMP(Plane 0)字符,因此使用固定2个字节长度,也就是说,它无法表示Unicode其他层面上的字符,而UTF-16为了解除这个限制,支持Unicode全字符集的编解码,采用了变长编码,最少使用2个字节,如果要编码BMP以外的字符,则需要4个字节结对。
UTF-8和UTF-16的变长是不一样的。UTF-8以一个字节为单位,扩展时,可以1-> 2-> 3字节;而UTF-16以两个字节为单位,扩展时只能2-> 4字节。
UTF-32/UCS-4
将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。在UCS-2的两个字节前加上两个零字节,就得到了UCS-4的BMP。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
本来UTF-32是UCS-4的一个子集。但现在它们几乎完全一样,不过UTF-32添加了额外的Unicode语义(可以编码更多的Unicode字符)。
UTF-8 with BOM
BOM的全称是Byte Order Mark,BOM是微软给UTF-8编码加上的,用于标识文件使用的是UTF-8编码,即在UTF-8编码的文件起始位置,加入三个字节“EF BB BF”。
这是微软特有的,Windows 的记事本(即新建文本文档,txt)就是用UTF-8 with BOM。UTF-8标准并不推荐包含BOM的方式。采用加BOM的UTF-8编码文件,对于一些只支持标准UTF-8编码的环境,可能导致问题。比如,网页第一行可能会显示一个“?”,明明正确的程序一编译就报语法错误,等等。
既然有如上缺点,为什么还要用BOM呢?因为计算机系统分为大端模式和小端模式。
- 简单说就是在处理多字节的时候,可能按照我们的逻辑,把数字大的部分放在地址大的部分,数字小的放在地址小的部分,叫做小端模式;也可能反着来,叫做大端模式。
- 例如对于内存中的数据:e6 84 6c 4e(从左到右地址增大)
大端模式读取:e6 84 6c 4e
小端模式读取:4e 6c 84 e6
- 详细请看:大小端模式-百度百科
如果同一篇文档,在大端模式下编写,传到小端模式的机器上,就会读取错误。然而只要在文档的开始,告诉计算机所要读取的文档是在大端模式还是小端模式上写的,就不怕读取顺序出错了。
参考:
- 十分钟搞清字符集和字符编码 - 伯乐在线
- 字符集和字符编码(Charset & Encoding) - 伯乐在线
- 字符编码常识及问题解析 - 伯乐在线
- 关于字符编码,你所需要知道的 - 伯乐在线
- 中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030 - 博客园
- ASCII - Wikipedia
- UTF-16 - Wikipedia
- UTF-32 - Wikipedia
- Byte order mark - Wikipedia
- 程序员趣味读物:谈谈Unicode编码
- 大小端模式-百度百科
- Unicode、GB2312、GBK和GB18030中的汉字
and so on……