SSTable 介绍(二)
作者:Jack47
上一篇SSTable 介绍(一)介绍了SSTable的适用场景和leveldb中SSTable的设计。本篇介绍SSTable文件的结构组成。
SSTable的特点
首先明确一下上文中提到的SSTable特点:
- 需要存储的<键,值>格式的字节数据
- 键可以重复,键值对不需要对齐,即可以是任意长度的
- 需要支持高效的随机读取操作
读者们不妨想一想,如果让你设计一种数据结构来支持上述的设计目标,你会怎么设计呢?
SSTable文件的结构
一些辅助的类和结构体
在去看leveldb/table/table.cc文件内容时,经常会看到以下的几个类或者结构体,他们是对SSTable文件底层内容的抽象,它们使用起来像积木一样方便,能够帮助上层调用者关注底层的抽象,而且类型的名称取的也很到位,让代码阅读者很容易理解其用途。
BlockHandle:
BlockHandle的结构如下图所示:

BlockHandle的结构和其指向的文件数据
BlockHandle是指向文件中一部分连续数据的指针,顾名思义,可以指向一个数据块[data block]或者元信息块[meta block]。其实就是存储了两个成员变量:代表文件偏移的uint64_t offset_和代表数据长度的uint64_t size_。这样有了数据的起始地址和数据的长度,就可以定位到这片数据了。从其BlockHandle.Encode函数的实现可以知道总共需要占用16个字节就可以存储它序列化后的数据。
Slice:
Slice的结构如下图所示:
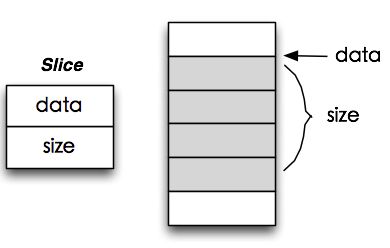
Slice和其指向的数据空间
Slice是一个简单的类,但是发挥的作用十分强大,可以用它来方便地指向一片连续存储的数据,可以认为指向的就是一个数组。它存储了指向的数据的起始地址和数据的字节长度。想想这样操作数据是不是就十分简洁了,再也不需要配套的两个变量来表示数据的起始地址和数据的大小了,使用 slice.data()拿到数组首地址,使用slice.size()拿到数组的长度,还有 slice.empty()来判断数组是否为空。需要注意的是这个类只是引用了一个数组,数组的存储空间由调用者管理,调用者必须保证在引用的数据被释放后,对应的slice对象不再使用。
BlockContents:
代表从文件中读取到的每一块[block]的数据的信息,包含实际的数据[Slice data],是否可以缓存[cachable]和是否是在堆上新申请的[heap_allocated]这三个属性。
SSTable存储到磁盘上的数据是支持压缩的,如果磁盘上的数据是经过压缩之后的,那就需要在从磁盘上读取的时候解压缩,此时BlockContents存储的是解压缩之后的数据,是在读取块数据时从堆上新申请的。heap_allocated就是用来标示这种情况,这片内存需要调用者负责最终释放。
SSTable文件的布局
从leveldb/doc/table_format.txt中可以看到,一个SSTable文件的内部数据的布局如下图所示:
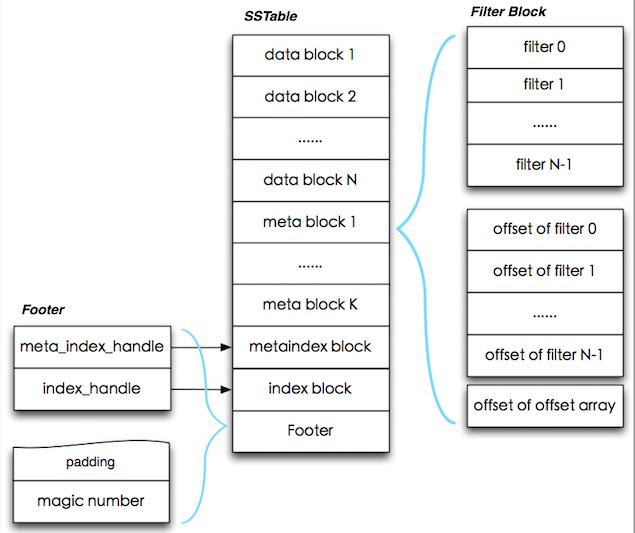
SSTable文件的布局示意图
下文中提到的这些块数据是根据block_builder.cc中的代码来生成的。
- 数据块[data block]
文件中键值对key/value是有序存储的,被划分成一系列的数据块[data block]。这些块在文件的开头一块紧挨一块地存储起来。可以选择开启压缩选项来压缩数据之后再存储到数据块里。
可见数据块的存储方式就跟数组一样,是连续存储
- 元信息块[meta block]
在数据块之后,存储的是一些元信息块。每个元信息块数据也是由block_builder.cc中的代码生成的,也是支持压缩选项。可见元信息块的存储方式也跟数据块类似。
- 元索引数据块[metaindex block]
为每个元信息块生成一条记录,记录的key是元信息块的名称,记录的值是指向元信息块的BlockHandle。
可见每个元信息块中存储的数据用途不一样,而且一个块大小就完全能够存储的下。否则需要多个块,那记录的key就不能取元信息块的名称了。由于元信息有好几类,所以需要在这里存储给各个元信息块建立的索引。
- 索引块[index block]
这个块包含了为每个数据块生成的索引记录,key是一个>=这数据块中最后一个key并小于后续数据块首个key的字符串,value是指向数据块的BlockHandle。
可以看到上述的每种类型的块数据,都可以用一个BlockHandle来表示。
- Footer
每个文件尾部都包含一个固定长度[40 Bytes]的Footer,它包含了指向元索引块[metaindex block]和索引块[index block]的两个BlockHandle,以及一个8字节的magicNumber。
默认块的大小是大概是未压缩的4KB字节的数据。块的大小可以根据应用程序使用SSTable数据的方式来调整,例如主要是对数据库内容进行批量扫描的应用,可以适当调大块的大小;对于大量读取小数据的应用,可以调小块的大小来看看效率是否提升。
第一次接触这种类型的文件布局,可能很难理解上述的各个组成部分,可以尝试这样去理解:
- 由于机械磁盘本身是物理分块的[固态硬盘除外],所以SSTable也参照磁盘分块大小来进行数据分块,能够尽量减少访问磁盘的开销,而且即使有数据毁坏,也会局限在几个块上,不会影响其他块数据的读取。
- 为这些数据/元信息块建立索引,就类似给书籍制作目录页一样,便于读取某个key时,可以快速定位key落在哪个数据块上,而不需要顺序遍历SSTable的每个块。
- Footer相当于是最高一级的索引,从这里开始,就能够获取到SSTable所有的信息。因此把它设计成固定大小,这样从磁盘上反序列化SSTable时,首先把Footer读取出来,然后按图索骥,就可以把其他的块也加载到内存里。
上面提到了meta block,目前支持的meta block有以下两种:
- "过滤“元信息块["filter" Meta Block]
当数据库创建的时候指定了“过滤策略”,那么每个SSTable会存储一个过滤块[filter block][过滤策略所需的数据不超过一个块的大小]。“元索引”块包含一条记录,映射了从"filter. "到指向过滤块的BlockHandle,这里" "是过滤策略的"Name()"函数返回的字符串。
过滤块存储了一系列过滤器,其中filter i 包含了对一个文件偏移落于范围[ibase ... (i+1)base-1]上的数据块所存储的所有key执行FilterPolicy::CreateFilter()后的输出。
目前,“base”是2KB。所以举个例子,当块X和Y起始于范围[0KB .. 2KB-1],所有的X和Y的key都会通过调用FilterPolicy::CreateFilter()来被转换到同一个过滤器里,同时这个过滤器会被存储为过滤块里的第一个过滤器。
由于过滤串的长度不一,所以需要存储每个过滤器的起始地址。过滤块的格式见上图。
- “统计”元信息["stats" Meta Block]
这一块包含了一些统计信息。key是统计数据的名称。值是统计数字。
记录了如下统计信息:
数据大小
索引大小
键大小(未压缩)
值大小(未压缩)
记录的数量
数据块的数量
剩下还有一些细节没有介绍,例如索引块、数据块内部的格式,数据块的读取操作等,留待SSTable介绍系列的第三篇,也是最后一篇来介绍。
回到本系列目录:leveldb源码学习系列