lightning mdb 源代码分析(2)
本系列前一篇已经分析了lightningmdb的整体架构和主要的数据结构。本文将介绍一下MMAP原理以及lmdb中如何使用它。
1. Memory Map原理
内存映射文件与虚拟内存有些类似,通过内存映射文件可以保留一个地址空间的区域,同时将物理存储器提交给此区域,只是内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而非系统的页文件,而且在对该文件进行操作之前必须首先对文件进行映射,就如同将整个文件从磁盘加载到内存。由此可以看出,使用内存映射文件处理存储于磁盘上的文件时,将不需要由应用程序对文件执行I/O操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。另外,实际工程中的系统往往需要在多个进程之间共享数据,如果数据量小,处理方法是灵活多变的,如果共享数据容量巨大,那么就需要借助于内存映射文件来进行。实际上,内存映射文件正是解决本地多个进程间数据共享的最有效方法。
根据网友实测,mmap的操作效率是普通文件io操作的2-4倍。其原因主要就是避免了io操作过程中,内存申请、复制以及跨内核空间的转换。
2. windows与linux实现的方式
windows下通过内存映射文件(CreateFileMapping)系列函数完成,其公开的API架构如下图所示
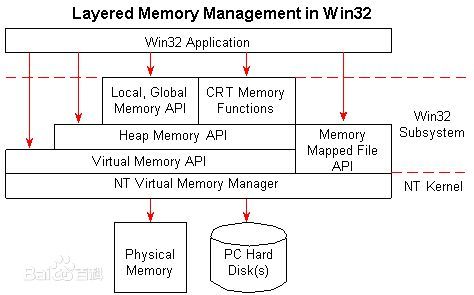
它是内存管理的一种方式,是进行进程间大数据共享的基本方式。
使用的基本方式是:
首先要通过CreateFile()函数来创建或打开一个文件内核对象,这个对象标识了磁盘上将要用作内存映射文件的文件。在用CreateFile()将文件映像在物理存储器的位置通告给操作系统后,只指定了映像文件的路径,映像的长度还没有指定。为了指定文件映射对象需要多大的物理存储空间还需要通过CreateFileMapping()函数来创建一个文件映射内核对象以告诉系统文件的尺寸以及访问文件的方式。在创建了文件映射对象后,还必须为文件数据保留一个地址空间区域,并把文件数据作为映射到该区域的物理存储器进行提交。由MapViewOfFile()函数负责通过系统的管理而将文件映射对象的全部或部分映射到进程地址空间。此时,对内存映射文件的使用和处理同通常加载到内存中的文件数据的处理方式基本一样,在完成了对内存映射文件的使用时,还要通过一系列的操作完成对其的清除和使用过资源的释放。这部分相对比较简单,可以通过UnmapViewOfFile()完成从进程的地址空间撤消文件数据的映像、通过CloseHandle()关闭前面创建的文件映射对象和文件对象。
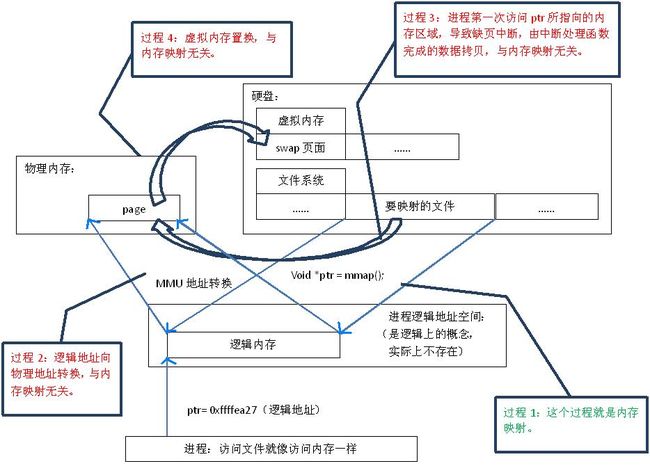
linux下通过mmap系列函数实现。基本过程如图所示:
一般的文件io操作方式如下图所示:
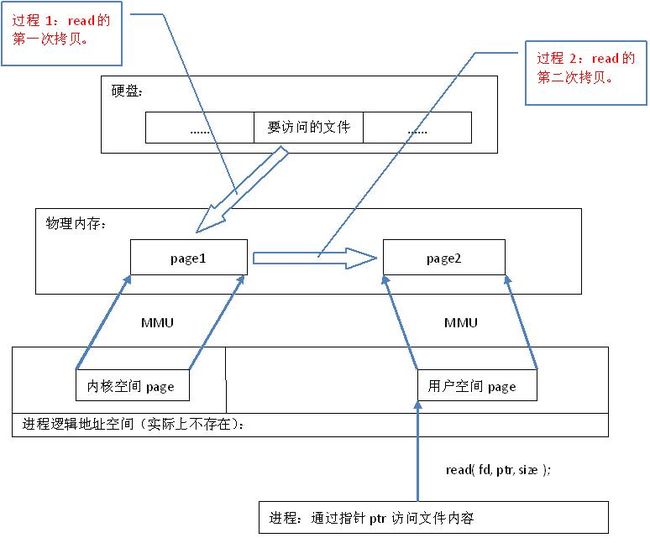
从以上两图比较可知,直接文件io将不可避免的进行多次内存复制。
基于以上的系统内存映射原理可知,内存映射是系统内核级的内存管理方式,其在不导致swap(因为物理内存不够)等附加磁盘io的前提下,
效率是很高的,因此其在数据库领域也有一定的适应性。基于内存映射的数据库系统,在实际的数据文件小于进程可用物理内存大小时,
效率远远高于一般的数据库系统,当数据文件比较大时,若应用访问的页面非常分散且数目巨大时,比如全表扫描时,这时内存映射将频繁
出发缺页异常,进而频繁进行swap,从而一次io变成2次io,效率反而下降。若应用访问基本为索引扫描,则以上情况可以避免,哪怕数据
文件远大于实际可用物理内存,则效率还是不错的。同时系统内存映射方式实现的数据库系统将大大简化内存管理、缓存管理、外存管理
等,因此其是一定规模和特定应用的首选实现方式,lmdb主要也是基于以上几点考虑使用内存映射。
3. lmdb使用方式
lmdb在创建环境(env对象)的时候首先检查文件头的相关信息,并获得文件大小,在打开的过程中通过系统函数对文件进行映射。
其他时刻都直接使用内存指针,通过系统级别的缺页异常获取对应的数据。页面内数据的获取和使用MDB_CURSOR_GET进行。
页面的获取和key查询通过mdb_page_get/mdb_page_search完成。
要理解为什么mmap映射的地址空间和指针对于lmdb代码是可用的,首先得理解lmdb的页面数据组织方式,以下示例以叶子页进行解释,
branch页面与其类似。
叶子页面的数据的组织方式如下所示:
| pgno | pad | flags | overflows① | nd_index1 | nd_index2 | nd_index3 | nd_index4 |
| node4[ | lo | hi② | flags | keysize | data(key) | data*(value) | ] |
| node3[ | lo | hi | flags | keysize | data(key) | data*(value) | ] |
| node2[ | lo | hi | flags | keysize | data(key) | data*(value) | ] |
| node1[ | lo | hi | flags | keysize | data(key) | data*(value) | ] |
①overflows是一个union对象,代表可用空间低、高地址或者overflow的页面数。
overflow页面是连续页面,data只需指向第一个页面即可,后续页面无需pgno也
不会导致其他pgno出错。
②节点大小由lo以及hi的低16位决定。
节点的key是可变大小,由keysize决定,具体内容包含在data中
节点的value占用内存比较大的,具体有环境指定最大节点大小。其data将指向overflow页面。
页面头部大小及内容是固定的,具体的含义代表根据flags决定,在头部之后紧接的是node,真正的key-value值对所在位置的索引,因此访问这些node时
通过指针计算即可得到对应的位置。在对页面进行检索式通过二分查找确定。
节点的索引部分,nd_index根据key的大小排序,即key[index2]一定大于或等于key[index1]。按照插入排序算法,进行节点插入,并且从page头向
page中间靠拢。
节点内容部分,按照插入顺序,从页面地址最高处向页面中间考虑。node内容部分保持无序状态,即加入key为1,2,3,4,插入顺序为1,4,3,2, 索引部分
为1,2,3,4,而数据部分则为1,4,3,2.
数据部分和索引部分都是直接存储数据(通过memcpy)而非存储指针,因此序列化之后再通过mmap进行映射时,数据是可用的。memcpy在此不可避免的
另一个原因是data是从应用程序传递过来的,不进行复制直接存储将导致再次访问时导致内存不可用异常(segment fault 错误)。
因此在lmdb中,最重要的是如何将页面给映射进进程地址空间。lmdb通过mdb_page_get函数以pageno为主要参数获得页面并返回页面指针。若仅仅是
只读事务且环境对象是以只读方式打开的,page的获取很简单,根据page=mapadress + pagno * pagesize获得。基于此方式可以工作的原因是前文提到的
在lmdb中B+Tree的是基于append-only B+Tree改造的。对于数据增加、修改、删除导致页面增加时,pageno也增加,当旧页面(数据旧版本)被重用时,
pageno保持不变,因此pageno保持了在数据文件中的顺序性,从而在获取页面时,只需要进行简单计算即可以。同时在创建env对象时,数据库已经被整个
映射进整个进程空间,因此系统在映射时,会给数据库文件保留全部地址空间,从而在根据上述算法获取真实数据库,系统触发缺页错误,进而从数据文件中
获取整个页面内容。此为最简单有效方式,否则不将全部数据映射进地址空间,对于未映射部分还需要在访问页面时判断是否已经被映射,未被映射时进行映射。
另注:lmdb对于脏页的刷新,采取可选方式,支持通过内存映射写入,也支持通过文件写入。默认支持为通过文件写入。应用程序在进行内存映射时以只读方式
进行打开,在需要时在通过文件方式写入。lmdb保证任意时刻只有一个写操作在进行,从而避免了并发时数据被破坏。
本文参考了其他网友的一些博文,在此谢谢他们的努力工作。
【1】http://blog.csdn.net/hongchangfirst/article/details/11599369
【2】http://blog.csdn.net/hustfoxy/article/details/8710307
【3】http://blog.csdn.net/joejames/article/details/37958017
【4】http://baike.baidu.com/link?url=8sD5zxtuTO2_wUwr5N4B6F-ZjnaedfnMjv3BOMQPatVfkO8E60Enq4_VayEwvdDuQOlLbyktGBe7S3Z9Zd5fjK
【5】http://baike.baidu.com/link?url=8sD5zxtuTO2_wUwr5N4B6F-ZjnaedfnMjv3BOMQPatVfkO8E60Enq4_VayEwvdDuQOlLbyktGBe7S3Z9Zd5fjK